当前位置:网站首页>Multimodal learning toolkit paddlemm based on propeller
Multimodal learning toolkit paddlemm based on propeller
2022-06-11 19:26:00 【Paddlepaddle】


With computer vision 、 natural language processing 、 The rapid development of speech recognition and other technologies , The existing artificial intelligence technology has achieved remarkable results in processing single-mode data . However , in real life , Data is presented in a variety of forms , For example, the words we read 、 The sound heard 、 Watched videos, etc , These multi-source heterogeneous information is called multimodal data , In the field of machine learning, a class of algorithms for mining and analyzing multimodal data are classified as multimodal learning methods . In order to make artificial intelligence better understand the real environment , Multimodal learning has attracted extensive attention of researchers in recent years , Great progress has been made in relevant application fields .
Divide from task objectives , Multimodal learning can be divided into modal joint learning 、 Cross modal learning and multi task pre training framework :
Modal joint learning : Focus on the comprehensive use of different modal information to learn the consistency goal , Such as multimodal classification and regression ;
Cross modal learning : It focuses on the correlation information between modes , Such as cross modal retrieval 、 Graphic generation ;
Multi task pre training framework : be based on Transformer Conduct unsupervised pre training , You can fine tune on a variety of downstream tasks .
Project introduction

Xiaobian will send you the project address
Click to read the original text GET
https://github.com/njustkmg/PaddleMM
Multimodal learning toolkit PaddleMM Based on Baidu PaddlePaddle , Provide modal joint learning and cross modal learning algorithm model base , It provides an efficient solution for processing multimodal data such as pictures and texts , Help the application of multimodal learning fall to the ground :
Mission scenarios : The toolkit provides multimodal fusion 、 Cross modal Retrieval 、 Image and text generation and other multimodal learning task algorithm model library ;
The application case : Toolkit based algorithms have been applied to the ground , Such as the authenticity identification of sneakers 、 Image caption generation 、 Public opinion monitoring, etc .
Multimodal model library
At present ,PaddleMM Provides a multimodal algorithm model library for image and text modes ( Updating ), Including multimodal classification 、 Cross modal Retrieval 、 There are four modules of graphic generation and pre training framework .
Multimodal classification
Multimodal classification algorithms are mainly divided into model independent algorithms ( As early as possible / Late fusion ) And model-based algorithms ( Such as CMML、LMF、TMC), As follows :
Early fusion / Late fusion : The information of different modes is fused from the feature level and prediction level respectively , So as to carry out classification tasks ;
CMML[1]: A robust multi-modal classification is achieved by adaptive weighted fusion for modal inconsistent scenes ;
LMF[2]: Low rank multimodal fusion classification based on modal specific factor ;
TMC[3]: A multimodal fusion strategy for credible prediction .
Cross modal Retrieval
The task of image and text retrieval is to extract features for the two modes and map them to the unified space , Learn the matching and scoring of pictures and texts in the shared semantic space , In the process of model training , Score the matched positive samples and the constructed mismatched negative samples respectively , The training model learns the difference between positive and negative image and text sample pairs . The toolkit implements a typical cross modal retrieval algorithm based on different graduation values , As follows :
VSE++[4]: Extract global features for images and text , Calculate matching scores based on global features ;
SCAN[5]: Learn from image area and text word to match and score ;
IMRAM[6]: The iterative cumulative similarity is introduced to improve the image text alignment information ;
SGRAF[7]: Join graph (Graph) Association similarity is used to measure image and text matching .
Graphic generation
The graphic generation task is to generate description information for images , Generally based on encoder - Decoder architecture , Use the encoder to extract features from the image , Based on the image information, words are generated in turn , Realize text decoding . The toolkit implements two different algorithms :
ShowAttendTell[8]: Use VGG Encoded image information is obtained feature map, utilize LSTM decode , In the decoding process, attention mechanism is introduced to select specific image context information to guide the word generation in the current stage ;
AoANet[9]: Use similar Transformer Structure construction encoder and decoder , And expand the original self attention attention on attention(AOA) modular .
The pre training framework
The multimodal pre training framework is based on Transformer Model of , First, a self supervised task is used for pre training on large-scale unlabeled multimodal data , Then, on the downstream task, it realizes the supervised fine-tuning according to the specific tag . The toolkit currently provides ViLBert[10] Algorithm , This method constructs the image and text respectively Transformer, The interaction of modal information in the process of self attention calculation .
Tool kit description
PaddleMM It is divided into data processing 、 model base 、 The trainer has three modules . among , The data module includes different processing forms for images and texts , Such as the global features of the image 、 Local feature processing , Statistics of text 、 participle 、BERT Handle ; The model base covers multimodal classification 、 Cross modal Retrieval 、 Different tasks such as text generation ; The trainer gives different training procedures for different tasks , Provide different training strategies in model training , A variety of test indicators for different tasks are included .
As shown in the figure below , stay PaddleMM in call , The model configuration file needs to be defined 、 Data directory and experiment record address are three variables , We store the super parameters of all models in configs In the folder , The configuration file of the model will include two types of super parameters , The first category is toolkit related hyperparameters , Such as task type , Text and image processing formats are required , In the experiment, the toolkit will select the corresponding data reading method according to these information 、 Trainers and test indicators , Another type of parameter in the configuration file is the specific model super parameter , That is, the optimal super parameter recommended by the model in use .

The toolkit generally includes the following steps in actual use : Set super parameters -> Toolkit initialization -> model training -> Indicator test , Here's an example :
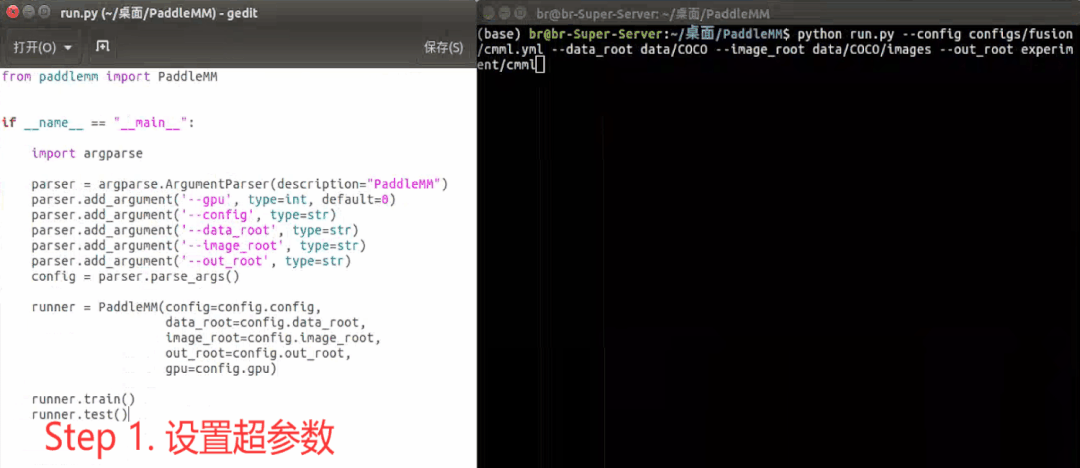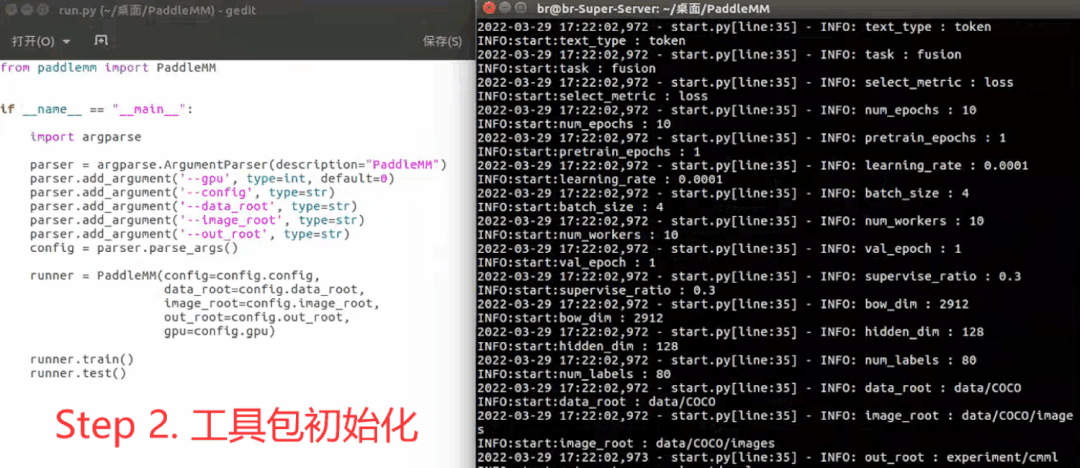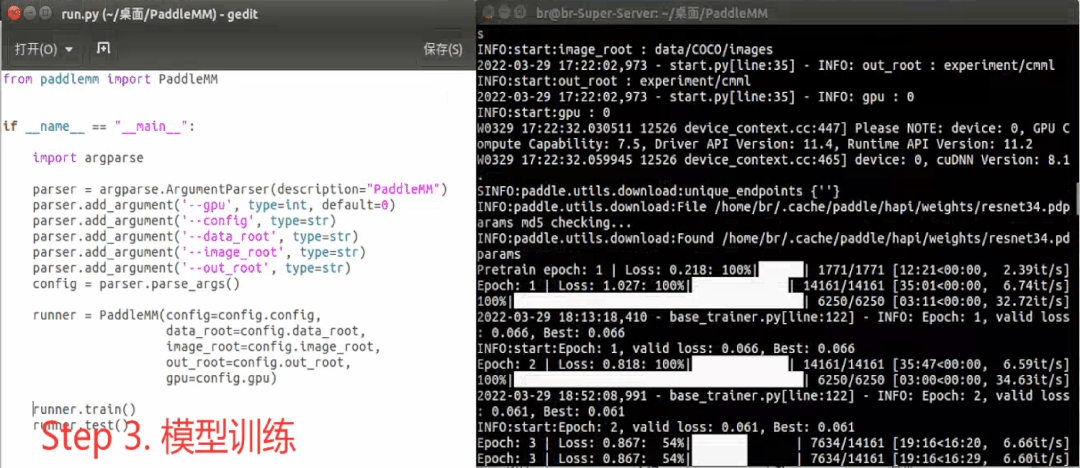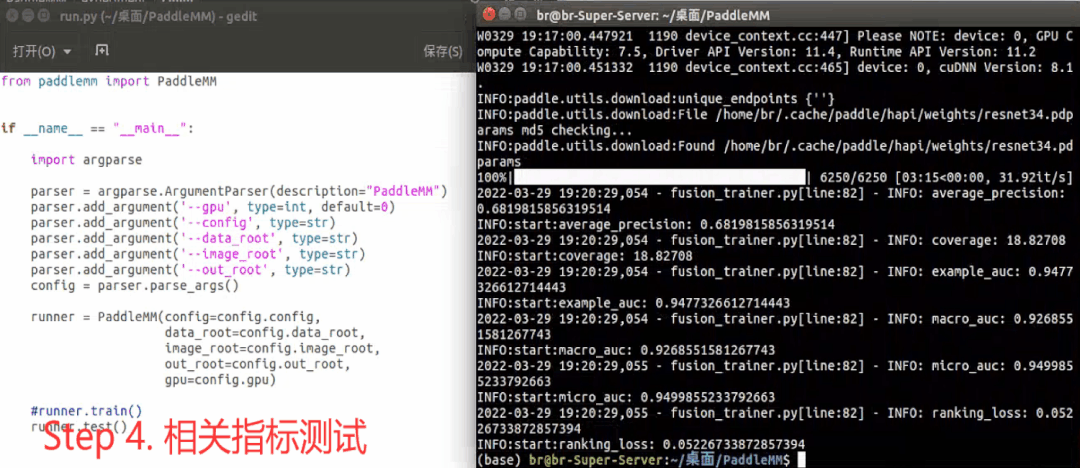
Model development
We use CMML[1] Algorithm as an example , See how to develop a multimodal learning model on the propeller platform .CMML, Mainly for classification tasks , For scenarios with inconsistent modal information , Adaptive weighted fusion of predictions from different modes , The following figure shows the overall structure :

say concretely ,CMML Tagged and unlabeled multimodal data entered , Single mode prediction is calculated by text prediction network and image prediction network respectively , Then calculate the following optimization objectives :
Adequacy measures : The modal attention learning network is used to calculate the weights of single-mode prediction with labeled data, and the weights are adaptively fused , Calculate the cross entropy loss function with the real marker ;
Measurement of difference : Calculate the difference between different modal predictions with marked data , The purpose of this part is to maximize the difference between different modal predictions and highlight the modal strength , Improve the model generalization ability ;
Robust consistency : Different modal prediction calculations for unlabeled data Huber Loss , The purpose of this section is to eliminate the interference of inconsistent samples , To achieve the robustness constraints on the model .
Final ,CMML Three optimization objectives are used to obtain the model loss , The gradient descent method is used to optimize the model .
AI Studio Project address :
https://aistudio.baidu.com/aistudio/projectdetail/2423256
Data loading
CMML Extract word bag feature from text data , Training based on global image data , meanwhile CMML It is a semi supervised learning model . therefore , We need to prepare word bag features of supervised and unsupervised texts in the data section 、 The original matrix features of the image , And label information with supervision data .
Model development
CMML The main model consists of three parts :
Text prediction network
self.txt_hidden = nn.Sequential(
nn.Linear(input_dim, hidden_dim*2),
nn.ReLU(),
nn.Linear(hidden_dim*2, hidden_dim),
nn.ReLU()
)
self.txt_predict = nn.Linear(hidden_dim, num_labels)Image prediction network
self.resnet = models.resnet34(pretrained=True)
self.resnet = nn.Sequential(*list(self.resnet.children())[:-1])
self.img_hidden = nn.Linear(512, hidden_dim)
self.img_predict = nn.Linear(hidden_dim, num_labels)Modal attention learning network
self.attn_mlp = nn.Linear(hidden_dim, 1)
self.attn_mlp = nn.Sequential(
nn.Linear(hidden_dim, int(hidden_dim/2)),
nn.ReLU(),
nn.Linear(int(hidden_dim/2), 1)
) In training ,CMML The following three optimization objectives need to be calculated :
Adequacy measures
supervised_txt_hidden = self.txt_hidden(supervised_txt)
supervised_txt_predict = self.txt_predict(supervised_txt_hidden)
supervised_txt_predict = self.sigmoid(supervised_txt_predict)
supervised_img_hidden = self.resnet(supervised_img)
supervised_img_hidden = paddle.reshape(supervised_img_hidden, shape=[supervised_img_hidden.shape[0], 512])
supervised_img_hidden = self.img_hidden(supervised_img_hidden)
supervised_img_predict = self.img_predict(supervised_img_hidden)
supervised_img_predict = self.sigmoid(supervised_img_predict)
attn_txt = self.attn_mlp(supervised_txt_hidden)
attn_img = self.attn_mlp(supervised_img_hidden)
attn_modality = paddle.concat([attn_txt, attn_img], axis=1)
attn_modality = self.softmax(attn_modality)
attn_img = paddle.zeros(shape=[1, len(label)])
attn_img[0] = attn_modality[:, 0]
attn_img = paddle.t(attn_img)
attn_txt = paddle.zeros(shape=[1, len(label)])
attn_txt[0] = attn_modality[:, 1]
attn_txt = paddle.t(attn_txt)
supervised_hidden = attn_txt * supervised_txt_hidden + attn_img * supervised_img_hidden
supervised_predict = self.modality_predict(supervised_hidden)
supervised_predict = self.sigmoid(supervised_predict)
mm_loss = self.criterion(supervised_predict, label)Measurement of difference
similar = paddle.bmm(supervised_img_predict.unsqueeze(1), supervised_txt_predict.unsqueeze(2))
similar = paddle.reshape(similar, shape=[supervised_img_predict.shape[0]])
norm_matrix_img = paddle.norm(supervised_img_predict, p=2, axis=1)
norm_matrix_text = paddle.norm(supervised_txt_predict, p=2, axis=1)
div = paddle.mean(similar / (norm_matrix_img * norm_matrix_text))Robust consistency
unsimilar = paddle.bmm(unsupervised_img_predict.unsqueeze(1), unsupervised_txt_predict.unsqueeze(2))
unsimilar = paddle.reshape(unsimilar, shape=[unsupervised_img_predict.shape[0]])
unnorm_matrix_img = paddle.norm(unsupervised_img_predict, p=2, axis=1)
unnorm_matrix_text = paddle.norm(unsupervised_txt_predict, p=2, axis=1)
dis = 2 - unsimilar / (unnorm_matrix_img * unnorm_matrix_text)
mask_1 = paddle.abs(dis) < self.cita
tensor1 = paddle.masked_select(dis, mask_1)
mask_2 = paddle.abs(dis) >= self.cita
tensor2 = paddle.masked_select(dis, mask_2)
tensor1loss = paddle.sum(tensor1 * tensor1 / 2)
tensor2loss = paddle.sum(self.cita * (paddle.abs(tensor2) - 1 / 2 * self.cita))
unsupervised_loss = (tensor1loss + tensor2loss) / unsupervised_img.shape[0]model training
stay CMML In training , The model reads the image and text features in the data loader , And input it into the model , By calculating three different optimization objectives , And it is combined to calculate the loss optimization model .
summary
PaddleMM The model and application tools of multimodal learning are provided , Here we introduce the algorithm overview and instructions of the toolkit , Finally, the multimodal classification algorithm is demonstrated CMML Model development process based on propeller platform , I hope I can do a little work on the landing application of multimodal learning on the propeller platform , Welcome to exchange and star!
Related links
Multimodal learning materials :
https://github.com/njustkmg/Multi-Modal-Learning
CMML Reappear AI Studio Project address :
https://aistudio.baidu.com/aistudio/projectdetail/2423256
Thanks to Baidu talent think tank TIC Department and Baidu PaddlePaddle platform support for toolkit development :
NJUST-KMG team :
http://www.njustkmg.cn/
Baidu talent think tank TIC department :
https://ai.baidu.com/solution/recruitment
Baidu PaddlePaddle platform :
https://www.paddlepaddle.org.cn/
reference
[1] Yang Y, Wang K T, Zhan D C, et al. Comprehensive semi-supervised multi-modal learning. IJCAI. 2019.
[2] Faghri F, Fleet D J, Kiros J R, et al. Vse++: Improving visual-semantic embeddings with hard negatives. BMVC. 2018.
[3] Liu Z, Shen Y, Lakshminarasimhan V B, et al. Efficient low-rank multimodal fusion with modality-specific factors. ACL. 2018.
[4] Han Z, Zhang C, Fu H, et al. Trusted multi-view classification. ICLR. 2021.
[5] Lee K H, Chen X, Hua G, et al. Stacked cross attention for image-text matching. ECCV. 2018.
[6] Chen H, Ding G, et al. Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval. CVPR. 2020.
[7] Diao H, Zhang Y, Ma L, et al. Similarity reasoning and filtration for image-text matching. AAAI. 2021.
[8] Xu K, Ba J, Kiros R, et al. Show, attend and tell: Neural image caption generation with visual attention. PMLR. 2015.
[9] Huang L, Wang W, Chen J, et al. Attention on attention for image captioning. CVPR. 2019.
[10] Lu J, Batra D, et al. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. NeurIPS. 2019.

Focus on 【 Flying propeller PaddlePaddle】 official account
Get more technical content ~
边栏推荐
- 关于我的 “二进制部署 kubernetes 集群” 的体验
- Key contents that wwdc22 developers need to pay attention to
- collect.stream().collect()方法的使用
- 视觉SLAM十四讲笔记-10-2
- CMU 15-445 數據庫課程第五課文字版 - 緩沖池
- Performance of MOS transistor 25n120 of asemi in different application scenarios
- Cf:c. restoring the duration of tasks
- Introduction to ieda bottom menu
- 求数据库设计毕业信息管理
- SLAM APP
猜你喜欢

cf:D. Black and White Stripe【连续k个中最少的个数 + 滑动窗口】
![Cf:g. count the trains [sortedset + bisect + simulation maintaining strict decreasing sequence]](/img/0b/1d3cd06e3d593a997a993a4d96e441.png)
Cf:g. count the trains [sortedset + bisect + simulation maintaining strict decreasing sequence]

Visual slam lecture notes-10-2

Key contents that wwdc22 developers need to pay attention to

CMU 15-445 database course lesson 5 text version - buffer pool
![[untitled]](/img/02/49d333ba80bc6a3e699047c0c07632.png)
[untitled]

Flash ckeditor rich text compiler can upload and echo images of articles and solve the problem of path errors

Introduction to go language (VI) -- loop statement

Performance of MOS transistor 25n120 of asemi in different application scenarios

【Multisim仿真】利用运算放大器产生方波、三角波发生器
随机推荐
Programmers have changed dramatically in 10 years. Everything has changed, but it seems that nothing has changed
2022 coming of age ceremony, to every college entrance examination student
Detailed explanation of iSCSI (IV) -- actual configuration of iSCSI server
Flash ckeditor rich text compiler can upload and echo images of articles and solve the problem of path errors
WWDC22 开发者需要关注的重点内容
cf:F. Shifting String【字符串按指定顺序重排 + 分组成环(切割联通分量) + 各组最小相同移动周期 + 最小公倍数】
对‘g2o::VertexSE3::VertexSE3()’未定义的引用
使用图像处理技术和卷积神经网络(CNN)的作物病害检测
CMU 15-445 database course lesson 5 text version - buffer pool
7-3 组合问题(*)
WinCC flexible 2008项目移植到博途WinCC的具体方法
Kubernetes binary installation (v1.20.15) (IX) closeout: deploy several dashboards
01. Telecommunications_ Field business experience
leetcode:926. Flip the string to monotonically increasing [prefix and + analog analysis]
The 2023 MBA (Part-time) of Beijing University of Posts and telecommunications has been launched
BottomSheetDialog 使用详解,设置圆角、固定高度、默认全屏等
Automated test requirements analysis
cf:B. Array Decrements【模拟】
cf:C. Restoring the Duration of Tasks【找规律】
7-3 combinatorial problems (*)