熟肉視頻地址:
今天的課程是關於期待已久的緩沖池的話題,其實就是 DBMS 如何管理它的內存並從磁盤來回移動數據,我們希望DBMS自己來管理這些內存與磁盤存儲交換的操作,而不是把它留給操作系統。你可以從兩個方面考慮數據庫存儲和內存管理問題:
第一個是空間控制,也就是我們從物理上考慮在磁盤上寫頁的比特置,我們要把頁面存儲在磁盤的什麼地方,以達到最大的收益。我們的目標是讓頁保持在一起,如果有一些頁經常被我們的應用程序同時訪問我們把它們連續地放在磁盤上。這麼做的原因是順序訪問磁盤比隨機訪問消耗小得多野快得多。
我們需要考慮的第二個方面是時間控制。這意味著當我們從磁盤取頁到內存時,我們希望 DBMS 能够以一種最小化磁盤 I/O 的方式來實現這一點:如果有一個您需要訪問的頁,而它目前不在內存中,那麼就需要從磁盤讀取,會有一個等待頁從磁盤載入內存的 I/O 阻塞,我們想盡量避免這些,也就是 DBMS 需要找到一種有效的方法,將在同一時間被訪問的頁面以最少的 I/O 次數同時保存在內存中。

我們這樣做的主要原因也是因為相對於訪問內存,直接訪問磁盤的耗時大太多了,是不可以接受的。所以,作為 DBMS 工程師,找出一種有效的方法來維護這個緩沖池,盡可能地將數據保存在內存中,這對我們來說是非常重要的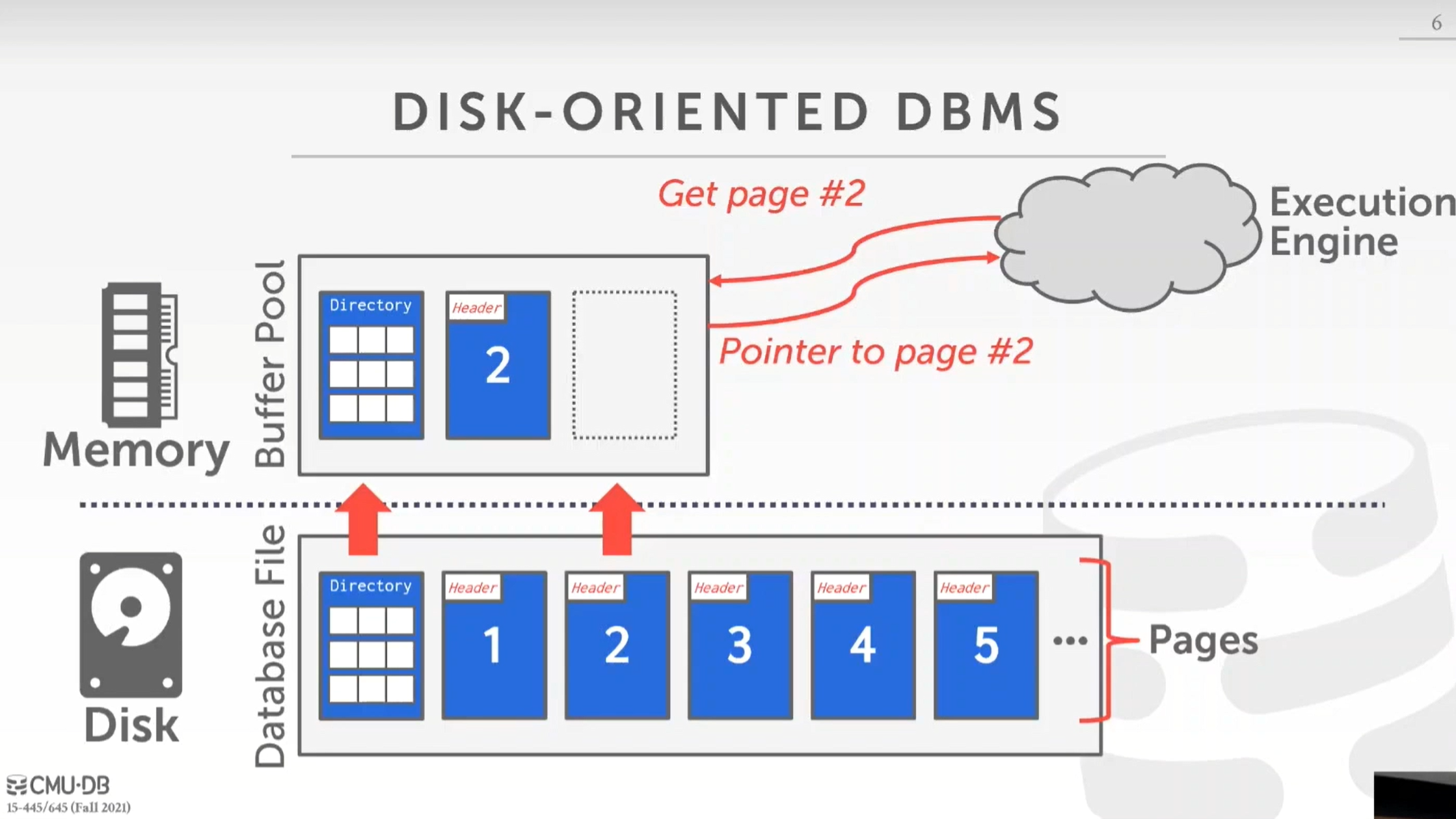
到目前為止,我們一直在討論磁盤上面的數據庫文件,這些文件被分成了很多頁,並且有目錄頁,它存儲從頁 id 到文件中的物理比特置或偏移量的映射。在磁盤文件上面有我們的緩沖池(Buffer Pool),它為執行引擎(Execution Engine)服務
例如:我們有一個執行引擎發出一個請求訪問第二頁,緩沖池中沒有第二頁,緩沖池要做的是,首先將文件目錄加載到內存中,找出第二頁的物理比特置,然後獲取它,這樣我們就能返回一個內存中的第二頁的指針給執行引擎。
以上是整個緩沖池如何工作的一個大概的例子,具體來說,我們今天這節課要講的主題還是關於緩沖池的高級概念:
特別是緩沖池管理器(Buffer Pool Manager),即軟件中負責管理緩沖池的部分,我們會看一下緩沖池管理器使用的不同算法。包括替換策略,如何决定哪些頁要讀取到內存,哪些頁要從內存中删除,最後我們會看一些其他類型的可能存在於 DBMS 中的內存池。

緩沖池的結構是一個固定大小的頁的數組,每一個數組條目都被稱為一個幀(Frame):它是磁盤上的數據庫文件的頁的大小,這樣我們就可以把磁盤上的頁映射到緩沖池的數組槽中。當 DBMS 請求一個頁時,我們要做的就是將頁複制到緩沖池中的這些幀中。
實際上,我們現在還需要一個間接層才能訪問這些頁,即通過頁錶(Page Table)
頁錶實際上記錄了存儲在內存中的頁的映射,類似於數據庫磁盤文件的文件頭的槽頁。頁目錄記錄頁在磁盤上的比特置,頁錶則是會記錄頁的布局,以及它們在內存緩沖池中的比特置。這裏我們有從第一頁和第三頁到緩沖池中的幀的映射,頁錶還將負責維護關於每個頁的一些額外元數據,例如:
- dirty 標記:是一個布爾值,告訴我們頁在加載到內存後是否被修改過。
- pin 標記或者引用計數:如果我們想要一個還會被使用的頁留在緩沖池的內存中,我們不希望它被删除,我們可以用 pin 標記這一頁。或者通過記錄引用計數讓我們知道哪些頁還在被查詢使用。
- Latch鎖存器:如果我們有一堆並發的查詢,我們有多個線程或查詢都訪問試圖修改這個頁錶,一般需要在頁錶的一個比特置設置一個鎖存器,來防止並發修改。
這裏我們需要理清一個重要的概念區別,即鎖(Lock)與鎖存器(Latch)
在數據庫世界中的鎖與鎖存器,與操作系統中的鎖與鎖存器的概念是不一樣的。在數據庫的世界中:
- 鎖(Lock):指的是對於數據庫的邏輯抽象的保護,例如鎖的可以是整張錶,也可以是索引,也可以是元組,這些都是與DBMS相關的邏輯抽象。鎖通常在事務期間獲取並保持,並且要考慮事務回滾
- 鎖存器(Latch):我們通常指的是保護某些底層關鍵部分的短暫的鎖存器,比如保護一個內部數據結構或者數據庫管理系統中發生的修改,我們不需要能够回滾這些改變。有點類似於 Mutex(互斥鎖)
下一個我們想搞清楚的是頁目錄(Page Directory)與頁錶(Page Table)的區別:
頁目錄就是從頁id到頁物理比特置的映射,它需要被持久化,這樣就算重啟我們也可以加載以便追踪我們可能需要的各個頁。
頁錶在內存中,它是臨時的。我們不需要持久化這個頁錶,頁錶可以在我們執行查詢時逐步建立。
一個問題:在內存中設置了頁錶某一幀的 dirty 比特後,如果掉電,我們會丟失對頁面的更新嗎?會的,如果在緩沖池中有一些頁被設置了髒比特,這意味著它們被一些查詢修改了,它們還沒有持久化到磁盤上。但是後面我們會討論到事務保證,如果你有一個事務,那麼這個事務直到所有的更改都以某種方式(後面我們會知道通過一種類似於寫入提前寫日志(WAL,Write Ahead Log)的方式)持久化到磁盤上之前才會提交完成,以保證事務的完整性不受宕機影響。

我們如何决定哪些頁會存在於我們的緩沖池中?一般有兩種策略:
- 全局策略(Global Policies):根據系統中在同一時間並發運行的所有查詢進行綜合考慮
- 本地策略(Local Policies):基於每個查詢來加載和移除頁,但是也會有頁的共享

一些緩沖池優化方式:
- 多緩沖池(Multiple Buffer Pools):多個同時使用多個並發緩沖池而不是一個
- 緩存預取(Pre-fetching):提前將一些加載到緩沖池减少 I/O
- 掃描共享(Scan Sharing):多個查詢共享一個掃描的結果
- 繞過緩沖池(Buffer Pool Bypass):對於某些查詢,不通過緩沖池以防污染

我們從多緩沖池(Multiple Buffer Pools)的概念開始:從邏輯上講 DBMS 有一種緩沖池,你可以把頁從磁盤加載到內存中,但在物理上,它可以被實現為具有不同策略的多個單獨的緩沖池。例如你的系統管理多個並發數據庫,每一個都可以有自己的緩沖池。例如你可以針對不同的頁類型有不同的緩沖池,例如錶的頁,索引的頁,這些可以由完全獨立的緩沖池處理。
它有很多優點,减少鎖存器爭用,並且可以每個緩沖池針對不同的需求使用不同的優化策略(例如針對查詢的,數據庫的,不同類型頁的緩沖池)。但是也引入了一個問題:你如何判斷你有一個頁,你想讓它存在與唯一一個緩沖池?

有兩種常用的方法:
- 第一種方法是當你存儲頁時你存儲一些與之相關的對象 id(Object Id):例如這裏對象id是指頁類型,它可以是一個存儲元組和錶的頁,它可以是存儲部分索引數據結構的頁,可能是存儲日志記錄的頁。舉一個實例:假設 Q1 查詢想得到記錄 123,根據前面的課程,我們知道這個 123 可以解析出數據庫中這個記錄的比特置信息,這裏這個比特置信息包括 ObjectId,PageId,SLotNum,根據 ObjectId 去對應的緩沖池尋找。
- 第二種方法是取哈希值:還是對於 Q1 查詢想得到記錄 123,對於這個記錄取哈希值,然後對獨立緩沖池的數量取餘數得出該去哪個緩沖池去查詢。

我們要講的下一個重要優化是緩存預取(Pre-fetching),這種想法是 DBMS 可以根據查詢計劃在實際需要之前預取頁。假設我們有一個查詢 Q1 執行順序查詢掃描所有頁,DBMS 可以執行一些數據預取,比如在開始掃描第 0 頁的時候,就把第 0,1,2 頁都加載到緩沖池中。之後到第 3 頁的時候,第 0,1,2 頁不再使用,可以被替換成 3,4,5 頁,這樣查詢不用在掃描每一頁的時候都阻塞。

我們接下來看這樣一個查詢,查詢 val 在 100 ~ 250 之間的所有記錄,這個查詢是可以通過索引優化不用掃描所有頁的。索引會在後面的課程詳細講。

目前對於 val 這個索引,你可以把它想象成一個平衡二叉樹。我們將從這個根頁(index-page0)開始,之後搜索左子樹 index-page1,然後找到 index-page3,由於葉子節點互相之間是有指針連接起來相當於一個雙向鏈錶,所以我們不必重新遍曆二叉樹就能找到 index-page5。這樣我們就找到了索引中我們所有要掃描的頁。
這個例子告訴我們預取需要根據數據結構以及掃描方式做出改變,並不是一直順序掃描的
問題:你怎麼知道你應該分配多少資源來做預取?學術界有很多關於預取的研究,在商業系統中,是一個很大的賣點,更好的預取應該是可以計算出你知道用這種方式預取需要付出多少資源,如果你花費太多資源做預取,那麼你就會阻礙系統進行的實際工作;而如果你什麼都不做,就會出現太多 I/O 阻塞。所以這是你在兩者之間必須達成一種微妙的平衡。
下一個是掃描共享(Scan Sharing)
其基本思想是查詢可以重用從存儲中檢索的數據,這也被稱為同步掃描(Synchronized scans),它不同於結果緩存。結果緩存主要是針對某個特定查詢的,對於不同的查詢一般不會生效。掃描共享則是不必是一樣的查詢,但是可以共享中間結果的。
如果一個查詢從磁盤讀取頁,並將它們放入內存,可以讓另一個需要訪問相同頁的查詢重用它們,它允許多個查詢附加到一個正在掃描錶的遊標上。查詢不一定是一樣的,但是他們需要訪問相同的頁。
假設有兩個查詢:
- Q1:SELECT SUM(val) FROM A
- Q2:SELECT AVG(val) FROM A
這兩個查詢,都是掃描 A 錶的所有頁。假設 Q1 先開始執行,讀取到第 3 頁,這時候 Q2 開始執行,Q2 和 Q1 要掃描的頁是一樣的,但是 Q2 可以直接附加在 Q1 的遊標上繼續掃描,等 Q1 掃描完,Q2 再掃描剩下的之前沒有掃描到的。
但是,如果這裏 Q2 加上 limit 100,這種限制,如果配合掃描共享,那麼可能每次掃描出來的結果是不一樣的,因為你也不確認它到底是從頭掃描還是附加到其他查詢的遊標上以及當前遊標的比特置。所以,我們最好不要有這樣的查詢,對於所有帶 Limit 的查詢,最好都指定排序條件。
最後一個優化是繞過緩沖池(buffer pool bypass)
對於順序掃描運算符,它要掃描每一頁,但是這些頁僅僅一次掃描之後就立刻用不到了,如果都加載到緩沖池的話,會嚴重影響執行效率,並且污染緩沖池。
在 Informix 這個系統中叫做輕量掃描(Light Scans)。並且 Oracle,SQLServer,PostgresSQL 中也有這種優化機制。
下一個我們要講的是,如果緩沖池滿了,在緩沖池中替換頁的不同策略,在此之前,我們先來看下操作系統中的機制:
我們要執行的大多數磁盤操作都是通過操作系統提供的 api,我們講過mmap()或者read()和write(),對於這些 api 除非你明確指定其中的參數告訴操作系統,否則操作系統會維護自己的文件系統緩存,它通常被稱為頁面緩存(Page Cache)。簡單來說:當你請求從磁盤讀取一個頁面,如果它還沒有加載,就從磁盤中獲取它加載到頁面緩存中,然後返回一個指向你的頁面的指針,之後你必須從操作系統頁面緩存複制到用戶空間。所以你會有一個多餘的複制,一個存儲在操作系統頁面緩存中,一個存儲在你實現的緩沖池中,所以大多數 DBMS 所做的是使用 O_DIRECT 標志來繞過操作系統的頁面緩存。

我們可以采用不同的策略來確定當緩沖池填滿時,我們需要騰出一個幀,以便插入一個新頁。我們如何决定從緩沖池中删除哪些頁呢?我們要考慮不同的方面:
- 正確性(Correctness):我們不想有任何數據被破壞的問題,例如,扔掉我們沒有正確地寫出的髒頁。
- 准確性(Correctness):即查詢結果是查詢想要查的數據
- 速度(Speed):緩沖池過期需要保證查詢速度,也需要考慮能快速决定哪些幀被替換,如果你花了所有的時間思考去掉哪個頁最合適,那麼你花在這上面的時間可能比你從智能算法中得到的好處還要
- 元數據大小(MetaData):我們需要擔心的是為了進行頁删除,我們存儲了多少元數據,不能太多

這是最簡單的一種算法,LRU(Least Recently Used,最近最少使用策略),它在很多不同的系統領域被使用。簡單的實現方式是為每個頁面維護一個時間戳,記錄它最後一次被查詢訪問的時間。當 DBMS 需要删除一個頁時,這很簡單,我們只需要找到時間戳最早的頁面,也就是最近訪問最少的頁面。
這是一種通用的依賴於你最近使用過的頁,你最近訪問過的頁,很快就會再次被使用這個假設的算法。
另一個策略是時鐘策略(Clock Policy),和 LRU 有點不同,這也是經常被用到的一種策略。它的實現方式通常是在每頁上分配一個標記比特,這個引用比特可以是 0 或者 1。如果這個頁面被訪問到了,就會標記為 1。我們有一個時針會不斷的掃描每一頁,如果時鐘掃描的這一頁標記比特為 1,那麼就會更新為 0,如果本來就是 0 了,就會把這個頁面過期掉。過這個算法給你帶來的好處是不用維護一個完整的時間戳(每頁占用4個字節或者8個字節),這個算法每頁只需要一個比特標記比特,所以空間的消耗會小很多。
LRU 以及時鐘策略都有一些問題,它們很容易受到連續洪流(Sequential Flooding)的影響。就像前面提到的,你要做的主要假設是你最近使用過的頁,你最近訪問過的頁,很快就會再次被使用。這對於傾斜的訪問模式很好,但是如果查詢執行順序掃描,需要讀取每個頁,會造成只讀一次然後就再也不會看的頁污染緩沖池。

你可以使用一些更好的策略,例如LRU-K,它不是跟踪某件東西是否被訪問,也不是跟踪某件東西最近被訪問的時間戳,你要看最後 K 次引用的曆史。假設 K 現在是 2,即你記錄了最近當某東西被訪問時的兩個時間戳,然後你就可以計算出以後訪問的間隔。如果這個間隔時間比較長,那麼就不能經常使用,我們可以把它扔掉。如果間隔時間短得多,證明它經常被訪問,我們可能會想保留它。
同時,你還可以做更高級的優化,例如:根據算法我們算出這頁平均訪問間隔大概是10分鐘左右,你可以期望10分鐘後,我需要這個頁,這樣你可以做一些更智能的預取。
但是,這個算法也會帶來更多的元數據開銷,這是我們需要權衡的。
另一種選擇是使用一些本地化的策略,即以某個查詢或者事務的基礎决定緩沖池的過期策略,例如 Postgres 就在每個查詢或事務的級別維護一個獨立的喚醒緩沖池,
另一個更好的策略可能是根據不同的訪問模式提供優先級提示(Priority Hints),例如,DBMS 知道訪問索引和順序掃描的訪問模式的區別,因此,您可以向緩沖池提供一些提示說明哪些頁面是重要的,哪些頁面是我們可能不關心的。
舉個例子,假設我們正在插入一些連續的 id,因為這些值是單調遞增的,所以它們總是會被插入到樹的右邊;如果你想要執行一次掃描,你的訪問路徑可能會不同,但它們有一個共同點就是你總是從這個根頁開始。你可以向緩沖池管理器提供的一個提示是,緩沖池保留這個根頁,這兩種類型的查詢都需要它。
如果你的緩沖池中有一個不髒的頁面,當它需要從緩沖池中剔除的時候,你可以直接删除它,覆蓋它,我們不需要保留它。因為沒有任何變化,它備份在磁盤上,如果我們需要我們總是可以從磁盤恢複它。但是如果是髒頁的話,你需要將髒頁的更新寫回磁盤以保證更新的持久化。
在快速緩沖頁驅除和持久寫髒頁之間有一種權衡。
為了减少持久化髒頁的時候帶來的寫磁盤的 I/O 阻塞,一般會有一個後臺寫過程*(Background writing process)。DBMS可以定期遍曆頁錶並將髒頁寫入磁盤。
除了元組和索引緩沖池之外 DBMS 還需要內存來管理其他東西,包括:
- 排序與連接緩沖
- 查詢緩存
- 維護緩沖
- 日志緩沖
- 詞典緩沖
這些元素有些可能有底層持久化到磁盤的元素,有些只存在於內存中,我們在後面的課程可能也會涉及到。
微信搜索“幹貨滿滿張哈希”關注公眾號,加作者微信,每日一刷,輕松提昇技術,斬獲各種offer:
我會經常發一些很好的各種框架的官方社區的新聞視頻資料並加上個人翻譯字幕到如下地址(也包括上面的公眾號),歡迎關注:






![[signal denoising] signal denoising based on FFT and fir with matlab code](/img/4c/782afe2652a674d64fccd8d28304ed.png)



