当前位置:网站首页>21_ Redis_ Analysis of redis cache penetration and avalanche
21_ Redis_ Analysis of redis cache penetration and avalanche
2022-07-02 15:13:00 【Listen to the rain】
Why understand cache penetration and avalanche : Ensure high availability of services
Redis The use of caching , Greatly improve the performance and efficiency of the application , Especially in data query . But at the same time , It also brings some problems . among , The most important question , It's data consistency , Strictly speaking , There is no solution to this problem . If there is a high requirement for data consistency , Then you can't use caching .
Other typical problems are , Cache penetration 、 Cache avalanche and cache breakdown . at present , There are also popular solutions in the industry .
Cache penetration ( We can't find it )
The concept of cache penetration is simple , The user wants to query a data , Find out redis Memory databases don't have , That is, cache miss , So query the persistence layer database . There is no , So this query failed . When there are a lot of users , No cache hits , So they all requested the persistence layer database, which will put a lot of pressure on the persistence layer database , This is equivalent to cache penetration .
Solution
The bloon filter
A bloom filter is a data structure , For all possible query parameters, use hash stored , Check at the control level first , If not, discard , Thus, the query pressure on the underlying storage system is avoided ;
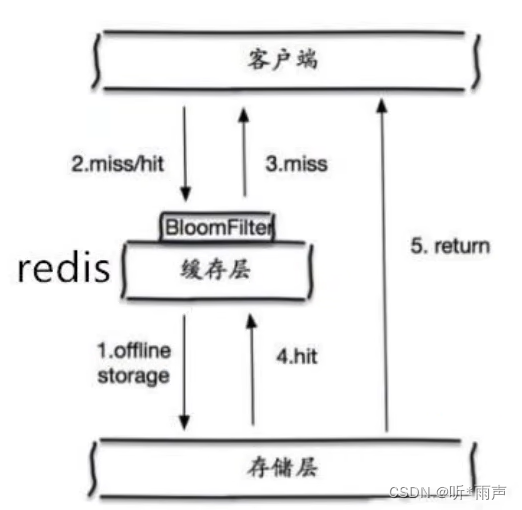
Caching empty objects
When the storage tier misses , Even empty objects returned are cached , At the same time, an expiration time will be set , Then accessing this data will get from the cache , Protected back-end data sources ﹔
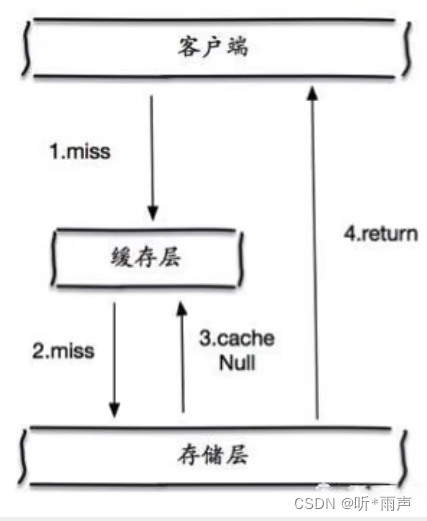
But there are two problems with this approach ︰
- 1、 If null values can be cached , This means that the cache needs more space to store more keys , Because there may be a lot of empty keys ;
- 2、 Even if expiration time is set for null value , There will be some inconsistency between the data of cache layer and storage layer for a period of time , This has an impact on businesses that need to be consistent .
Cache breakdown ( Too much )
Visit one key, You can find... In the cache , But the number of visits is too large , When the cache expires , All access requests hit the persistence server
example : Microblog server down ( Hot search : A hot news ( One location ) short time , High concurrency ))
Note the difference between and cache penetration , Cache breakdown , It means a key Very hot , Constantly carrying big concurrency , Large concurrent centralized access to this point , When this key At the moment of failure , Continuous large concurrency breaks through the cache , Direct request database , It's like cutting a hole in a barrier .
When a key At the moment of expiration , There are a lot of requests for concurrent access , This kind of data is generally hot data , Due to cache expiration , Will access the database at the same time to query the latest data , And write back to the cache , Will cause the database transient pressure is too large .
Solution
Never expired data settings
At the cache level , Expiration time is not set , So there will be no hot spots key Problems after expiration .
shortcoming :redis There are memory limitations , When the critical value is exceeded, the rewriting mechanism is triggered , Will delete and integrate some expired key, If one key If it is set to not expire, it will affect many later mechanisms
Add mutex lock
Distributed lock ∶ Using distributed locks , Guarantee for each key At the same time, there is only one thread to query the back-end service , Other threads do not have access to distributed locks , So just wait . In this way, the pressure of high concurrency is transferred to distributed locks , So the test of distributed locks is great .
Cache avalanche
Cache avalanche , At a certain time , Expiration in cache set . Or down ( power failure )
One of the reasons for the avalanche , For example, to double 11 o'clock , There will soon be a rush , This wave of commodity time is put into the cache , Suppose you cache for an hour . Then at one o'clock in the morning , The cache of this batch of goods has expired . And the access to this batch of products , It's all in the database , For databases , There will be periodic pressure peaks . So all the requests will reach the storage layer , The number of calls to the storage layer will skyrocket , Cause the storage layer to hang up .
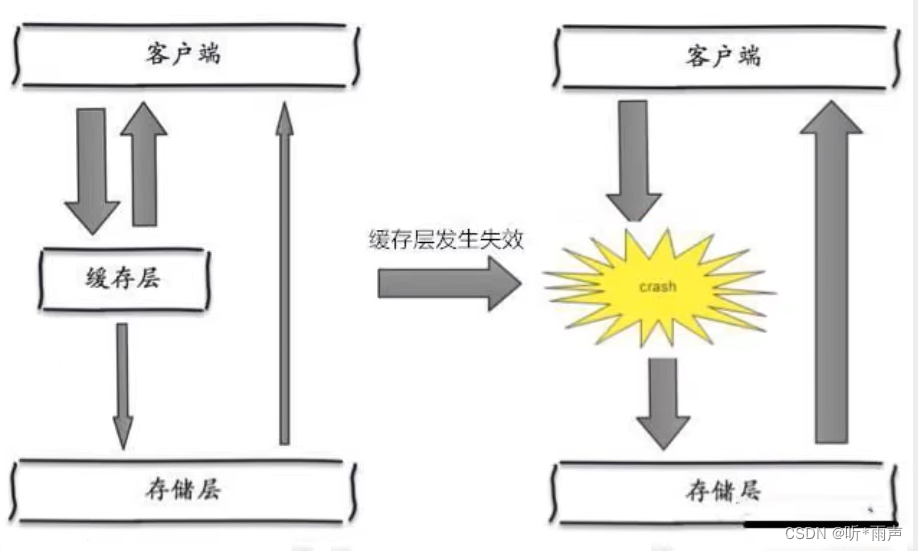
Actually, the concentration is overdue , It's not very deadly , More deadly cache avalanche , It means that a node of the cache server is down or disconnected . Because of the cache avalanche formed naturally , Cache must be created in a certain time period , This is the time , The database can also withstand the pressure . It's just periodic pressure on the database . The cache service node is down , The pressure on the database server is unpredictable , It's likely to crush the database in an instant .
A double tenth : Shut down some services ,( Ensure that the main services are available !)
For example, if you want to refund on the day of double 11, you can't refund , It is mainly to ensure the normal progress and high availability of purchase services
Solution
redis High availability
The meaning of this idea is , since redis It's possible to hang up , I'll add more redis, After this one goes down, others can continue to work , In fact, it's a cluster built .
Current limiting the drop
The idea of this solution is , After cache failure , Control the number of threads that read the database write cache by locking or queuing . For example, to some key Only one thread is allowed to query data and write cache , Other threads wait .
Data preheating
Data heating means before deployment , I'll go through the possible data first , In this way, some of the data that may be accessed in large amounts will be loaded into the cache . Manually trigger loading cache before large concurrent access occurs key, Set different expiration times , Make the cache failure time as uniform as possible .
边栏推荐
- Advanced C language (learn malloc & calloc & realloc & free in simple dynamic memory management)
- IE 浏览器正式退休
- 数据分析思维分析方法和业务知识——业务指标
- C code audit practice + pre knowledge
- TiDB 软件和硬件环境建议配置
- C thread transfer parameters
- 【无标题】LeetCode 2321. 拼接数组的最大分数
- SQL 后计算的利器 SPL
- 解决el-radio-group 回显后不能编辑问题
- info [email protected]: The platform “win32“ is incompatible with this module.
猜你喜欢
02_线性表_顺序表
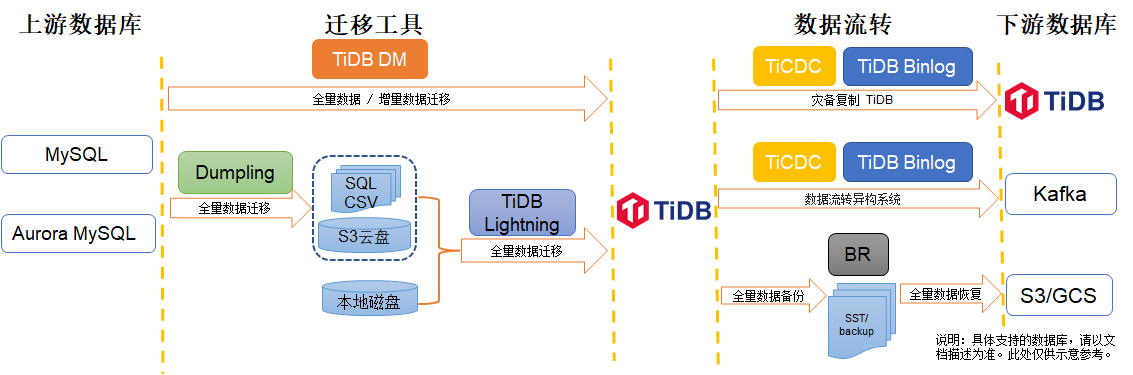
TiDB数据迁移工具概览
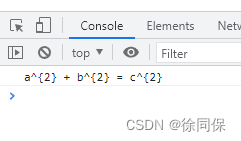
MathML to latex

【NOI模拟赛】刮痧(动态规划)

Fundamentals of software testing
Mavn 搭建 Nexus 私服
 [email protected] : The platform “win32“ is incompatible with this module."/>
[email protected] : The platform “win32“ is incompatible with this module."/>info [email protected] : The platform “win32“ is incompatible with this module.
C code audit practice + pre knowledge

geoserver离线地图服务搭建和图层发布

Table responsive layout tips
随机推荐
【NOI模拟赛】伊莉斯elis(贪心,模拟)
IE 浏览器正式退休
[Space & single cellomics] phase 1: single cell binding space transcriptome research PDAC tumor microenvironment
[QNX hypervisor 2.2 user manual]6.3 communication between guest and external
可视化搭建页面工具的前世今生
How does CTO help the business?
GeoServer offline map service construction and layer Publishing
Fundamentals of software testing
MFC CString to char*
Base64 编码原来还可以这么理解
08_ 串
数据分析思维分析方法和业务知识——业务指标
.NET Core 日志系统
CodeCraft-22 and Codeforces Round #795 (Div. 2)D,E
CodeCraft-22 and Codeforces Round #795 (Div. 2)D,E
c语言入门--数组
传感器数据怎么写入电脑数据库
N皇后问题的解决
AtCoder Beginner Contest 254
实用调试技巧