当前位置:网站首页>C语言习题---(数组)
C语言习题---(数组)
2022-07-02 11:41:00 【叶超凡】
题目汇总
第一题:
第二题:
第三题:
第四题:
第五题:
第一题解析:
我们首先来看看题目的意思是什么?就是说我们这里有一个数组,它里面有各种各样的数据,然后我们就输入一个值,然后他就会将这个数组里面所有的这个值全部都删除,并且将删除后的数组的值按照原来的数据的顺序全部打印出来,然后我们看一下下面的输入描述:他这里是采用的是变长数组的方式来进入输入,因为我使用的编译器是不支持c99标准的,所以我们这里就自己创建一个能够装10个元素的数组,然后将数组的值初始化为1,2,2,2,3,2,4,3,5,2,然后我们要将这个数组里面的2全部都删除并且打印出来,那么我们首先完成第一步数组的创建,那么代码如下:
#include<stdio.h>
int main()
{
int arr[10] = {
1,2,2,2,3,2,4,2,5,4 };
int a = 2;
return 0;
}
那么我们这里要将这个数组里面的2全部删除后的数组的元素全部打印出来,那么我们这里首先可以想到的一个问题就是我们这里真的有必要将这个是数组里面的值真的给删除掉吗?我们只用输出的结果是对的不就可以了吗?没必要真的删除吧,好那么看到这里我们就明白了一件事就是我们输出的结果是对的就可以了,没必要真的删除,那么这种情况我们就可以采用这样的方法,我们再创建一个大小为10个元素的数组,然后将原来的数组的元素赋值到这里面了,如果遇到了要删除的值,我们这里就不对这个值进行赋值,直接跳到下一个值不就够了吗?那么我们这里是不是就可以用for语句加if语句完成这件事,到了最后我们再将这个赋值结束之后的数组里面的元素全部打印出来不就可以了吗?我们来看看代码是如何实现的:
#include<stdio.h>
int main()
{
int arr[10] = {
1,2,2,2,3,2,4,2,5,2 };
int a = 2;
int arr1[10] = {
0 };
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
int j = 0;
for (i = 0; i < sz; i++)
{
if (arr[i] != a)
{
arr1[j] = arr[i];
j++;
}
}
for (i = 0; i < j; i++)
{
printf("%d", arr1[i]);
}
return 0;
}
我们来看看运行的结果如何:
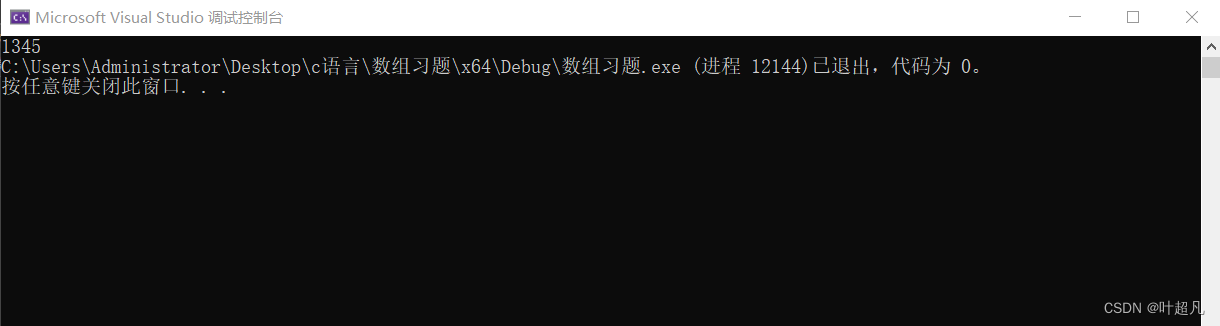
结果确实和我们想的一模一样,但是大家有没有想过这么一个问题就是我们这里是再创建一个数组来把原来的数组的值赋值过来了,但是我们这么做是不是就会照成了一种内存的浪费啊,我们这个数组的元素少,所以影响不会很大,但是要是我们的数组的元素很多呢?这是不是就会造成很多内存的浪费啊,那么我们有没有什么办法能够在不创建数组的情况下还能将这个删除元素后的数组打印出来呢?那么我们把思路换一下既然我们不能创建两个数组,那么我们能不能创建两个数组的下标呢?虽然是两个数组的下标但是这两个下标却是同一个数组的,如果一个我们一个下标用来进行判断,另外一个下标用来接收判断成功的值,那么我们这里就是i用来判断,j用来接收,那么这里大家得想明白一件事情就是如果我们这个数组里面有要删除的值,那么我们的i的值是一定要比我们的j的值增长的快的,为什么呢?我们来继续讲我们这个双坐标的原理,首先我们的i和j都是0表示的是都是从第一个坐标开始,如果我们的第一个坐标不是想要删除的数,那么我们这里就讲arr[i]的值赋值给arr[j]但是我们这两个值是同一个值是不会有影响的,所以我们就将i和j的值全部都加12,这样依次往后直到出现了一个我们想要删除的值,那么这时我们的i就会进行判断判断出这是我们要删除的值,所以他就不会将这个值赋值给arr[j],并且i的值还是会增长,但是我们j的值却会原地不动,那么下面再遇到一个想要的值的话,是不是还是会进行赋值啊,但是现在这个赋值就不一样了,arr[i]赋值给arr[j]的值会掩盖arr[]里面的数据,但是这是同一个数组啊,那么这里的意思就是arr会用后面的值来替代前面的值,但是这个掩盖只会照成一个结果就是我想要删除的数据会被掩盖,我数据原本的顺序也会得到一定的修改,比如说我的数组里面有一个4原来变的下标为6,但是经过修改后变成了3,但是我们的数组的长度不会发生改变,我们数据的最后几位可能是没有发生变化的,所以我们在打印数组内容的时候得根据j的值来进行打印,因为这个j来表示下标的话,就是表示的一个全新的数组,那么看到这里大家应该能够明白我的意思那么我们的代码如下:
#include<stdio.h>
int main()
{
int arr[10] = {
1,2,2,2,3,2,4,2,5,2 };
int a = 2;
int i = 0;
int j = 0;
for (i = 0; i < 10; i++)
{
if (arr[i] != a)
{
arr[j] = arr[i];
j++;
}
}
for (i = 0; i < j; i++)
{
printf("%d", arr[i]);
}
return 0;
}
这样子我们就不会再开辟新的空间而是原来的数组上面做文章。
第二题解析
我们来看看这个题,啊这个题就很简单嘛,毕竟我们之前是讲过类似的,我们这里是输入一个值如果是小写的,我们就将他转换成大写输出,如果是大写的那么我们就将他转化成小写进行输出,那么这个就很好办我们直接根据他输入的值的ascall值进行判断不就够了吗?我们根据ascall值来判断他是否是大写还是小写,然后再对ascall码值进行操作再来将他以大写或者小写的形式进行输出,那么根据我们之前的学习我们是直到将一个大写字母的ascall值加上32就可以得到对应的小写,那么小写的转化成大写的操作相反就可以了,那么我们的判断和输出的代码如下:
#include<stdio.h>
int main()
{
char ch = 0;
scanf("%c", &ch);
if (ch >= 'a' && ch <= 'z')
{
printf("%c\n", ch - 32);
}
else
{
printf("%c\n", ch + 32);
}
return 0;
}
那么根据题目的意思我们这里是可以连续的输入输出的那么这时有小伙伴们可能就说啊,我们直接将这个放到while循环里面,然后将while循环里面的判断改成1 不就可以实现循环了吗?那么如果说我们这样做的话,大家是否考虑这么一个问题就是我们这个代码如何停下来啊,我们是不是就陷入了一个死循环里面了啊,那么这里我们就可以告诉大家一点就是我们的这里的scanf函数他其实是有返回值的,当他读到了一个数据那么我们这个scanf函数他就会返回1,如果他没有读到数据的话他就会返回EOF,那么我们知道了这个情况的话,我们是不是将这个scanf函数放到我们的while循环里面啊,用来判断我们的scanf的值是否为1,这样的话当他的值为1的话就表示接收到了值,如果说没有接收到值我们这里的就会将这个循环停止,那么根据上面所述我们的代码如下:
#include<stdio.h>
int main()
{
char ch = 0;
while (scanf("%c", &ch)==1)
{
if (ch >= 'a' && ch <= 'z')
{
printf("%c\n", ch - 32);
}
else
{
printf("%c\n", ch + 32);
}
}
return 0;
}
那么我们运行一下看看这个代码的运行结果如何:

啊这时候我们就发现不对劲了,为什么这里会跟着出现星号(*)呢?那么这里我们就得来讲讲之前说过的输入缓存区这个概念,我们的scanf函数他每次拿走数据都是到空格或者\n停止的,那么我们这里在输入这个值的时候得通过按一下回车将这个值输入到我们的输入缓冲区里面,那么这样的话就会照成一个结果就是我们的输入缓存区里面不仅会有我们输入的字符还有一个\n,那么编译器在把我们输入的字符操作完后就会自动的对我们的\n进行操作而我们这里用的是if else 语句,所以我们这里的\n就会直接进行else里面的操作,我们可以通过监视看到\n对应的ascall码值是10,那么将10加上32那么对应的值就是42,而我们的*对应的值也恰好为42所以就会打印出*出来我们来看一下监视的图片:
确实跟我们想的一样,那我们如何来处理这个问题呢?那么这里我们就有两个个办法第一个就是在这个循环的最后加一个getchar()用来清空我们的输入缓冲区,这样每次循环之后我们的scanf就不会接收到\n了。
#include<stdio.h>
int main()
{
char ch = 0;
while (scanf("%c", &ch) == 1)
{
if (ch >= 'a' && ch <= 'z')
{
printf("%c\n", ch - 32);
}
else
{
printf("%c\n", ch + 32);
}
getchar();
}
return 0;
}
第二种就是既然我们的\n是第一个判断的条件不成立然后自动的进入了else下面的语句,那么我们这里直接把else改成if再在后面加一个判断的条件不就够了吗?我们来看看代码如何:
#include<stdio.h>
int main()
{
char ch = 0;
while (scanf("%c", &ch)==1)
{
if (ch >= 'a' && ch <= 'z')
{
printf("%c\n", ch - 32);
}
if(ch >= 'A' && ch <= 'Z')
{
printf("%c\n", ch + 32);
}
}
return 0;
}
第三题解析
第三题:
看了这题首先我们的第一步就是先通过我们的for循环将这5位数中的每一位数都表示出来,然后再进行判断,那么我们的代码如下:
#include<stdio.h>
int main()
{
int a = 0;
for (a = 10000; a < 100000; a++)
{
}
return 0;
}
好既然我们得到全部的5位数的整数,那么接下来我们再对其进行五位数的判断,我们通过观察题目可以看到这个水仙数的求法是有规律的,将这个五位数的第五位提出来然后乘以后四位组成的数,再加上第五位第四位组成的数据乘以后三位组成的数据,加上第五位第四位第三位组成的数据乘以后两位组成的数据,这样依次往后,那么看到这里大家应该想到了一个非常暴力的方法就是我直接把全部情况列出来不就够了吗,反正就5位数嘛,那么这样的话我们的代码就很好写了,我们的代码如下:
#include <stdio.h>
int main( )
{
int i=0;
for (i = 10000; i < 100000; i++)
{
if (i == ((i/10000)*(i%10000))+((i/1000)*(i%1000))+((i/100)*(i%100))+((i/10)*(i%10)))
printf("%d ", i);
}
return 0;
}
看到了这个代码想必大家应该发现一件事情就是我们这个代码太臃肿了,看起来十分的费劲,那么我们能不能对其进行修改呢?而且我们发现这个其实是十分有规律的,因为他/和%的数据都是一样的,并且每次/和%的数据都成规律性的增长每次都变大十倍,那么我们是不是就可以将他放到for循环里面并且运用函数pow用来得到10的k次方,然后创建一个sum变量用来储存相加的值,最后再进行判断并且打印,那么我们的代码如下:
#include <stdio.h>
#include<math.h>
int main()
{
int i = 0;
int j = 0;
for (i = 10000; i < 100000; i++)
{
int sum = 0;
for (j = 1; j < 5; j++)
{
int k = (int)pow(10, j);
sum = sum + (i % k) * (i / k);
}
if(i==sum)
{
printf("%d\n", i);
}
}
return 0;
}
第四题解析
首先我们看到这里要求我们输入一个字符串进去,那么我们首先得创建一个数组将这个数组的大小设为30,然后我们再通过scanf函数来输入一个字符串放到外面这个数组里面,我们的代码如下:
#include<stdio.h>
int main()
{
char arr[30] = {
'a' };
scanf("%s", &arr);
printf("%s", arr);
return 0;
}
那么我们接下来要做的工作就是要计算得到这个字符串里面的小写的a到z的个数,那么我们这里就得想一个问题就是我们是输入一个字符串进去,但是这个字符串是可以含有其他的字符,不一定全部得是小写的字符,所以我们这里得先判断他为小写的英语字符然后再对其进行分类,那么这里我们就可以在这一步添加一个if语句用来判断,既然判断的部分完成了,那么我们这里就这么想,我们再创建一个整型的数组arr1并且大小为26个,然后我们得到这个字符串中小写的字符的个数,就把这些个数存到我们这个整型的数组里面,比如说我们得出这个a的个数为10的话,我们就把这个10存到我们的arr1[0]里面,然后得出z的个数为5的话我们就把5存到arr1[25]里面,然后我们是怎么得到这个a的个数呢?我们可以这么想我们用一个for循环来对这个数组中的每个元素进行扫描,然后我们又知道这a到z的ascall值是连续的,所以我们将这些字母的ascall值减去97就可以对应到我们整型数组arr1的下标里面去,比如说我们字符串的第一个元素是a,那么我们就可以将这个a的字符减去97,然后将减去之后的值作为arr1的下标,然后将该下标的值加上1 ,等我们把这个字符串数组扫描完,我们的整型数组里面的内容就是我们想要的结果,再将其数组的下标对应的加上97就是各个小写的字符,那么这个下标对应的数组的值就是这个字符出现的次数,那么我们来看代码具体的实现:
#include<stdio.h>
#include<string.h>
int main()
{
char arr[30] = {
'a' };
scanf("%s", &arr);
int len = strlen(arr);
int arr1[30] = {
0 };
int i = 0;
for (i = 0; i < len; i++)
{
if (arr[i] >= 'a' && arr[i] <= 'z')
{
arr1[arr[i] - 97] += 1;
}
}
for (i = 0; i < 26; i++)
{
printf("%c出现的个数为%d\n", (i + 97), arr1[i]);
}
return 0;
}
我们可以看看输出的结果确实是跟题目的要求一样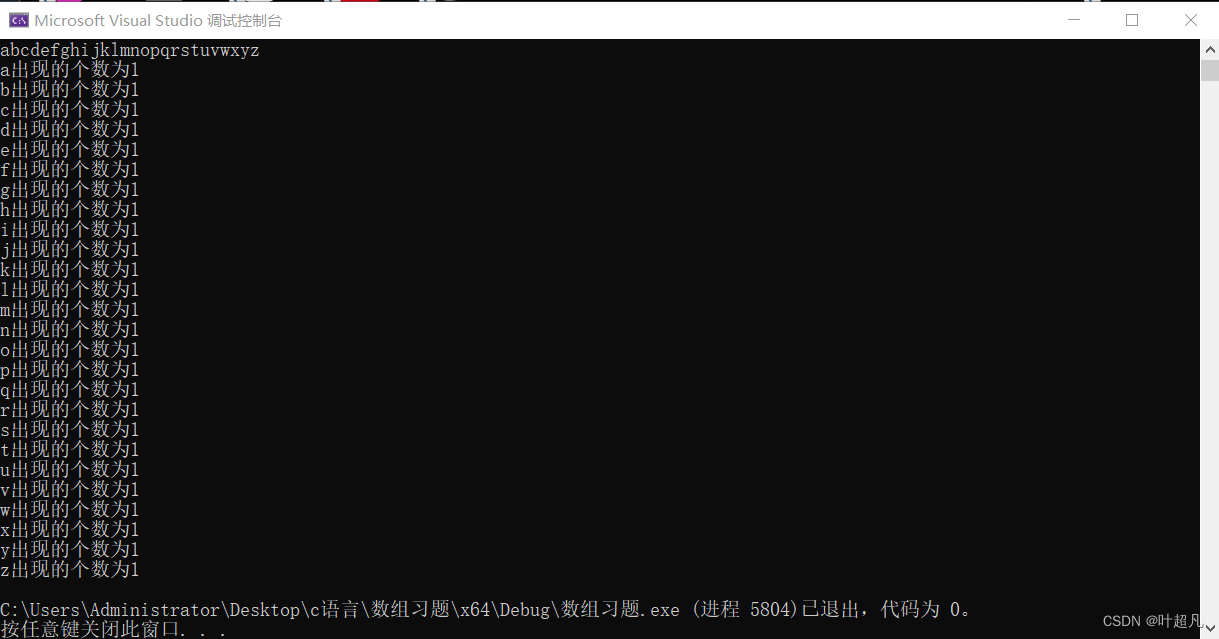
第五题解析
第五题:
首先这个题我们发现这个题目的意思跟我们交换两个变量的值有点类似,那么我们这里就可以试着采用交换两个变量的方法,来做这道题,那么首先我们得创建两个大小相同的数组arr1和arr2,再创建两个变量一个为i另一个为m,其中i是用来表示循环的,m就是用来表示我们想要移动的字符数目的,然后然后我们再通过scanf函数将我们想要的字符串输入到我们的arr1里面,再把我们想要移动的字符串的数目输入到m里面代码实现如下:
#include<stdio.h>
int main()
{
char arr1[80];
char arr2[80];
int i = 0;
int m = 0;
printf("请输入字符串:");
scanf("%s", &arr1);
printf("请输入平移量:");
scanf("%d", &m);;
return 0;
}
然后我们就得先完成第一步就是将我们的m个数据移动到数组arr2里面,那么这里我们就可以用for循环来实现:
for (i = 0; i < m; i++)//转移数组的元素
{
arr2[i] = arr1[i];
}
等我们字符串的转移实现了之后我们就可以将数组arr1下标为m即之后的数据向前面搬移,那么搬移的数据的数目就为(strlen(arr1) - m),那么我们这里用到了函数strlen所以我们这里就得引入头文件string.h,那么这里的移动我们就又要使用for循环代码如下:
for (i = 0; i < (strlen(arr1) - m); i++)//将数组的元素往前移动
{
arr1[i] = arr1[i + m];
}
最后一步就是将数组arr2里面的元素再移动到数组arr1后面,但是这里大家要注意的是我们这里的下标就得重(strlen(arr1) - m)开始了,那么我们的代码如下
for (i = 0; i < m; i++)
{
arr1[strlen(arr1) - m + i] = arr2[i];
}
但是这里大家要记住的一点就是我们得在数组的后面再加上一个\0来添加一个结束的标志,那么我们完整的代码如下:
#include<stdio.h>
#include<string.h>
int main()
{
char arr1[80];
char arr2[80];
int i = 0;
int m = 0;
printf("请输入字符串:");
scanf("%s", &arr1);
printf("请输入平移量:");
scanf("%d", &m);
for (i = 0; i < m; i++)//转移数组的元素
{
arr2[i] = arr1[i];
}
for (i = 0; i < (strlen(arr1) - m); i++)//将数组的元素往前移动
{
arr1[i] = arr1[i + m];
}
for (i = 0; i < m; i++)
{
arr1[strlen(arr1) - m + i] = arr2[i];
}
arr1[strlen(arr1)] = '\0';//防止越界访问
printf("%s", arr1);
return 0;
}
边栏推荐
- fatal: unsafe repository is owned by someone else 的解决方法
- 【无标题】LeetCode 2321. 拼接数组的最大分数
- [QNX Hypervisor 2.2用户手册]6.3 Guest与外部之间通信
- Introduction to mathjax (web display of mathematical formulas, vector)
- JMeter script parameterization
- Li Chuang EDA learning notes 15: draw border or import border (DXF file)
- STM32 standard firmware library function name (I)
- NLA natural language analysis realizes zero threshold of data analysis
- threejs的控制器 立方体空间 基本控制器+惯性控制+飞行控制
- Edit the formula with MathType, and set it to include only mathjax syntax when copying and pasting
猜你喜欢

Fundamentals of software testing

< schéma de développement de la machine d'exercice oral > machine d'exercice oral / trésor d'exercice oral / trésor de mathématiques pour enfants / lecteur LCD de calculatrice pour enfants IC - vk1621
![[development environment] StarUML tool (download software | StarUML installation | StarUML creation project)](/img/08/9f25515e600a3174340b2589c81b0e.jpg)
[development environment] StarUML tool (download software | StarUML installation | StarUML creation project)

什么是 eRDMA?丨科普漫画图解
Fabric. JS free draw circle

Error: NPM warn config global ` --global`, `--local` are deprecated Use `--location=global` instead.

Reuse and distribution
fatal: unsafe repository is owned by someone else 的解决方法

Makefile separates file names and suffixes

【NOI模拟赛】刮痧(动态规划)
随机推荐
使用mathtype编辑公式,复制粘贴时设置成仅包含mathjax语法的公式
3. Function pointers and pointer functions
电脑怎么设置扬声器播放麦克风的声音
天猫商品详情接口(APP,H5端)
fatal: unsafe repository is owned by someone else 的解决方法
测试框架TestNG的使用(二):testNG xml的使用
LeetCode_滑动窗口_中等_395.至少有 K 个重复字符的最长子串
threejs的控制器 立方體空間 基本控制器+慣性控制+飛行控制
geoserver离线地图服务搭建和图层发布
Large top heap, small top heap and heap sequencing
Thoroughly master prototype__ proto__、 Relationship before constructor (JS prototype, prototype chain)
obsidian安装第三方插件——无法加载插件
String matching problem
求轮廓最大内接圆
4、数组指针和指针数组
Fabric.js 上划线、中划线(删除线)、下划线
Tujia muniao meituan has a discount match in summer. Will it be fragrant if the threshold is low?
Available solution development oral arithmetic training machine / math treasure / children's oral arithmetic treasure / intelligent math treasure LCD LCD driver ic-vk1622 (lqfp64 package), original te
LeetCode 2320. 统计放置房子的方式数
buuctf-pwn write-ups (7)