当前位置:网站首页>Pytorch学习笔记(三)模型的使用、修改、训练(CPU/GPU)及验证
Pytorch学习笔记(三)模型的使用、修改、训练(CPU/GPU)及验证
2022-07-26 13:29:00 【小胡今天有变强吗】
现有模型的使用和修改
import torchvision
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
运行代码:
下载的数据集的存放地址:

在原有模型的基础上加线性层;
import torchvision
from torch import nn
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10('../data', transform=torchvision.transforms.ToTensor(), download=True)
# 添加
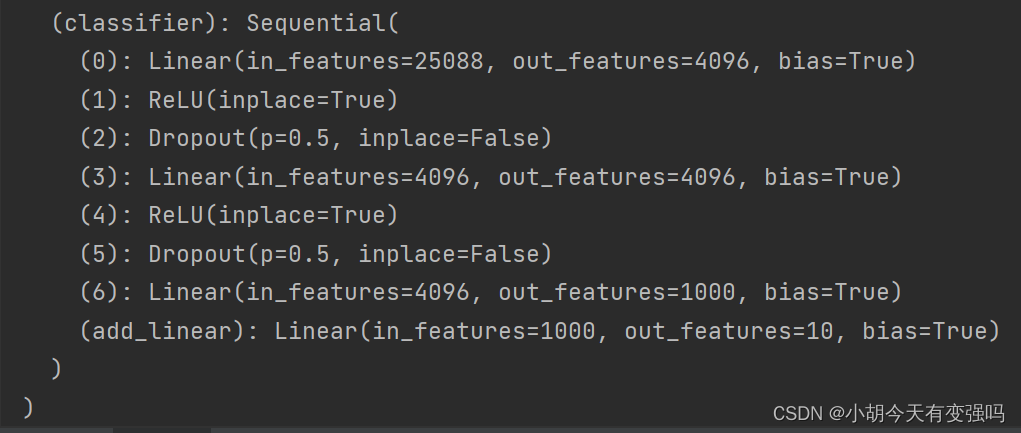
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
# 修改
vgg16_true.classifier[6] = nn.Linear(4096, 10)
print(vgg16_true)
网络模型的保存和读取
import torch
import torchvision
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1,模型结构+模型参数
torch.save(vgg16, "vgg16_method1.path")
# 保存方式2,模型参数(官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.path")
import torch
import torchvision
# 方式1》保存方式1,加载模型
# model = torch.load("vgg16_method1.path")
# print(model)
# 方式1》保存方式2,加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.path"))
# model = torch.load("vgg16_method2.path")
print(vgg16)
完整的模型训练套路
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# length
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用DataLoader来加载数据
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("--------第{}轮训练开始-------".format(i + 1))
#训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
total_test = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()

利用GPU进行训练
1.第一种方式
网络模型 数据(输入,标注) 损失函数 找到前面三个参数,调用.cuda()返回
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
from model import *
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# length
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用DataLoader来加载数据
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64 * 4 *4, 64),
Linear(64, 10)
)
def forward(self, x):
x =self.model(x)
return x
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
start_time = time.time()
for i in range(epoch):
print("--------第{}轮训练开始-------".format(i + 1))
#训练步骤开始
tudui.train()
for data in train_dataloader:
if torch.cuda.is_available():
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
if torch.cuda.is_available():
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
GPU训练:
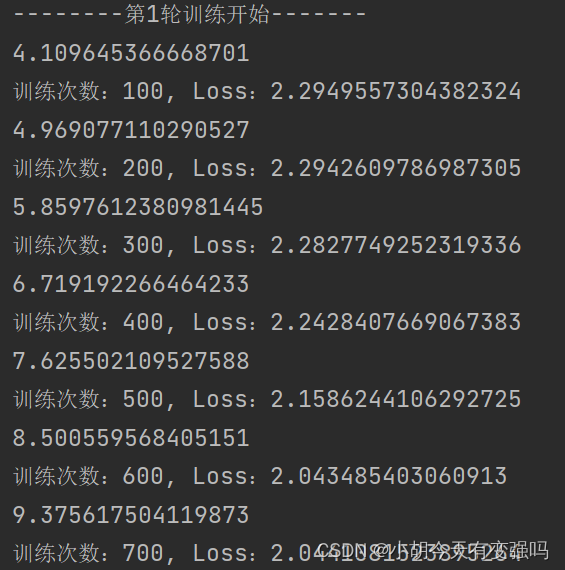
CPU训练:

本机配置CPU为 AMD Ryzen 7 5800H with Radeon Graphics 八核 ,GPU为
Nvidia GeForce RTX 3060 Laptop GPU ( 6 GB / 联想 ),可以看出用显卡跑还是要快不少的。
如果电脑没有GPU,可以使用谷歌。
登录 https://colab.research.google.com/ ,要注册谷歌账号并登录才能使用,选择文件,新建笔记本。

可以看到GPU是不能用的:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5wD1ii0y-1658804427176)(C:\Users\Husheng\Desktop\学习笔记\image-20220725170218869.png)]](/img/08/02bcb39c9784c15d67155f9d094c85.png)
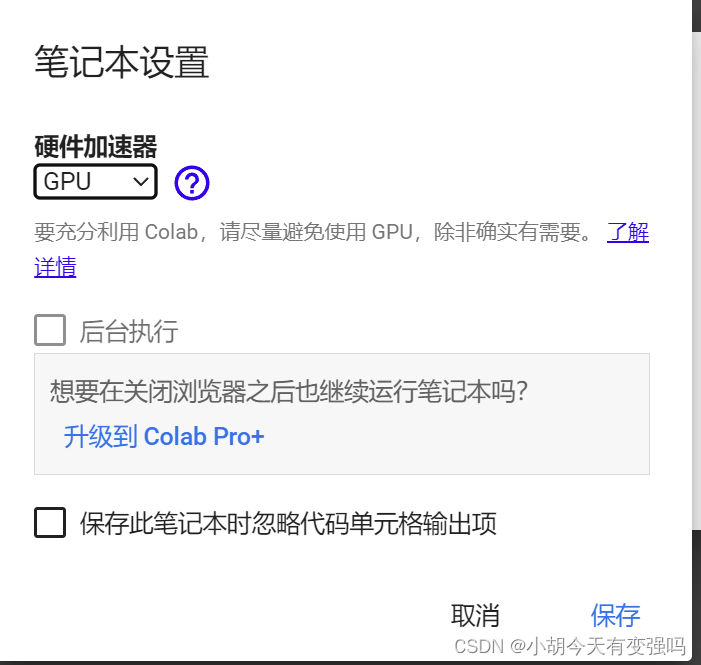
如果想使用可以修改如下设置:
点击 修改 —> 笔记本设置,将硬件加速器选为GPU,点击保存:
此时再进行测试,GPU就可以使用了:
将上面gpu版本的代码复制进去,运行
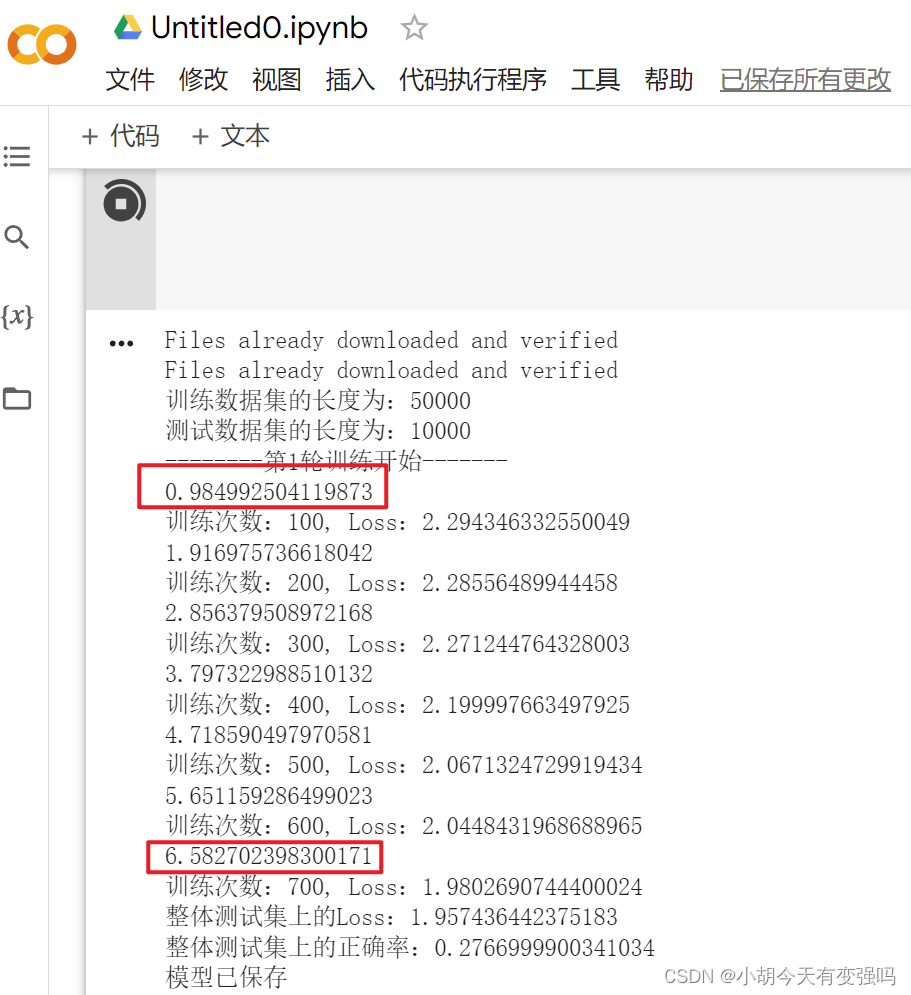
也是可以正常运行的,且速度很快,比我笔记本的3060要快好多,就离谱!!!
2.第二种方式:
.to(device)
Device = torch.device(“cpu”)
Torch.device(“cuda”)
Torch.device(“cuda.0”)
Torch.device(“cuda.1”)
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
from model import *
# 定义训练的设备
device = torch.device("cuda")
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# length
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用DataLoader来加载数据
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64 * 4 *4, 64),
Linear(64, 10)
)
def forward(self, x):
x =self.model(x)
return x
tudui = Tudui()
tudui = tudui.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
start_time = time.time()
for i in range(epoch):
print("--------第{}轮训练开始-------".format(i + 1))
#训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
完成的模型验证套路
完整的模型验证(测试,demo)套路:利用训练好的模型,然后给它提供输入。
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
image_path = "../imgs/airplane.png"
image = Image.open(image_path)
print(image)
# image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64 * 4 * 4, 64),
Linear(64, 10)
)
def forward(self, x):
x =self.model(x)
return x
model = torch.load("tudui_0.pth")
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
image = image.cuda()
output = model(image)
print(output)
print(output.argmax(1))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0smcLlpD-1658804427178)(C:\Users\Husheng\Desktop\学习笔记\image-20220725203146266.png)]](/img/f9/e44708f5160436365ed2cac7c6b9e7.png)
参考资料
边栏推荐
- 解决远程主机无法连接mysql数据库的问题
- Detailed relation extraction model casrel
- [collection of topics that C language learners must know 1] consolidate the foundation and steadily improve
- LeetCode 217. 存在重复元素
- .NET WebAPI 使用 GroupName 对 Controller 分组呈现 Swagger UI
- Codeforces Round #810 (Div. 2)【比赛记录】
- How to realize the reality of temporary graphic elements
- Leetcode 263. ugly number
- B+ tree index uses (7) matching column prefix, matching value range (19)
- [beauty of open source] nanomsg (2): req/rep mode
猜你喜欢

One stroke problem (Chinese postman problem)

Implementation of SAP ABAP daemon

Team research and development from ants' foraging process (Reprint)

Target detection network r-cnn series
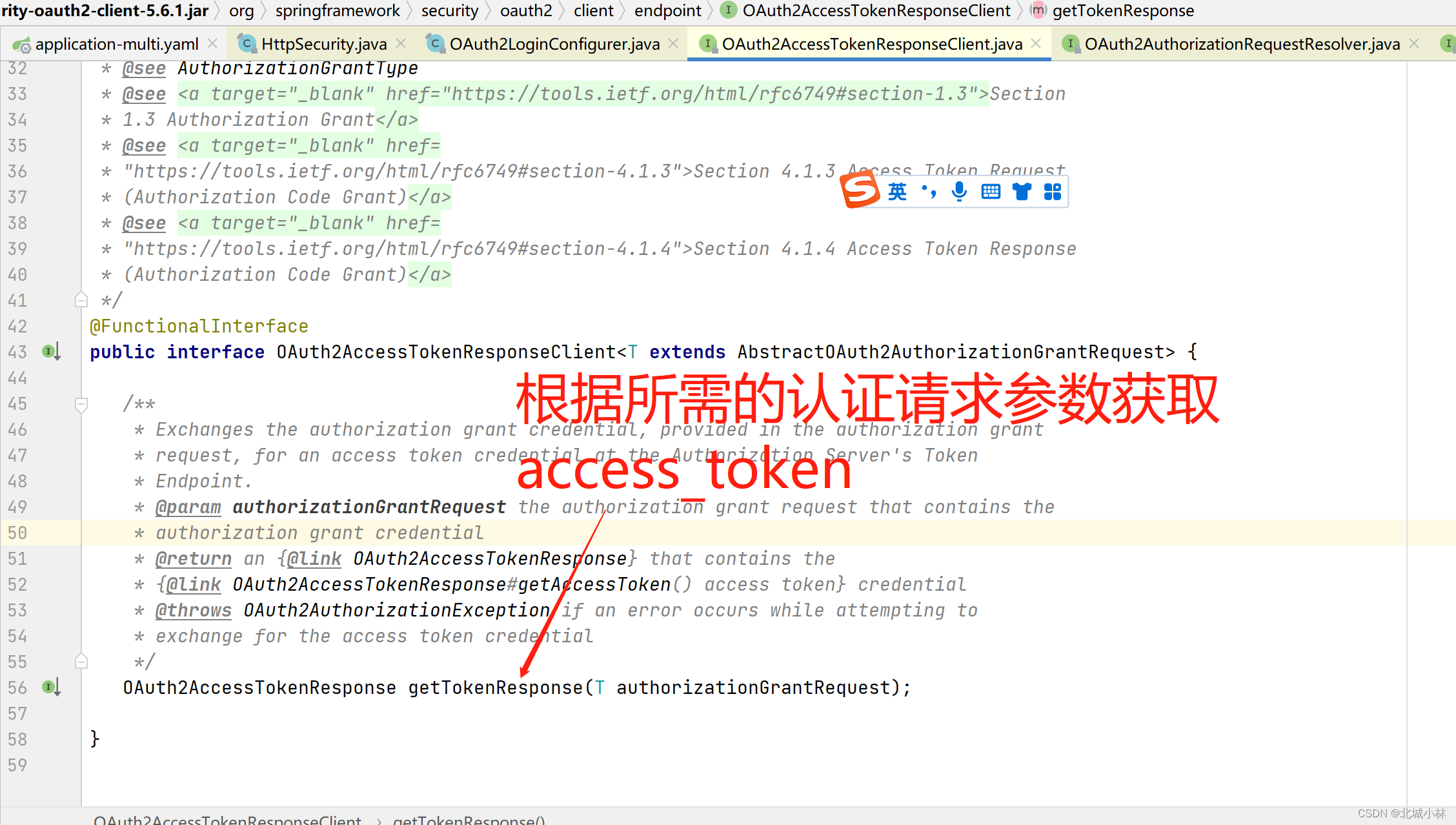
【OAuth2】八、OAuth2登录的配置逻辑-OAuth2LoginConfigurer和OAuth2ClientConfigurer

Unicode文件解析方法及存在问题

《Kotlin系列》之MVVM架构封装(kotlin+mvvm)

1312_ Apply 7z command for compression and decompression

How to write the introduction of GIS method journals and papers?

JSON数据传递参数&日期型参数传递
随机推荐
Detailed explanation of factory mode
Huawei computer test ~ offset realizes string encryption
Basic sentence structure of English ----- origin
【Oauth2】五、OAuth2LoginAuthenticationFilter
Control the probability of random winning [C | random]
1312_ Apply 7z command for compression and decompression
LeetCode 217. 存在重复元素
Thoughts on the compilation of Dr. Shuo's opening report
JS object assignment problem
带你熟悉云网络的“电话簿”:DNS
Uncover the secret of white hat: 100 billion black products on the Internet scare musk away
Exploration on cache design optimization of community like business
Sword finger offer (IX): abnormal jumping steps
HCIP第十一天比较(BGP的配置、发布)
Activity. Onstop() delay 10 seconds? Wonderful investigation process
Extra (5) - MySQL execution plan (51)
我们被一个 kong 的性能 bug 折腾了一个通宵
PostgreSQL official website download error
Feixin, which lasted 15 years and had 500million users, was completely dead
Solve the problem that the remote host cannot connect to the MySQL database