当前位置:网站首页>VQA needs not only pictures, but also external knowledge! University of Washington & Microsoft proposed revive, using gpt-3 and wikidata to help answer questions
VQA needs not only pictures, but also external knowledge! University of Washington & Microsoft proposed revive, using gpt-3 and wikidata to help answer questions
2022-06-29 14:29:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
This article shares 『REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering』,VQA Not just pictures , External knowledge is also required ! University of Washington & Proposed by Microsoft REVIVE, use GPT-3 and Wikidata To help answer questions !
The details are as follows :

Thesis link :http://arxiv.org/abs/2206.01201[1]
01
Abstract
This paper re discusses the knowledge-based visual question answering (VQA) Visual representation in , It is proved that better use of region information can significantly improve performance . Although in the traditional VQA Visual representation has been extensively studied in , But in knowledge-based VQA The research on visual representation in is not deep enough , Although the two tasks share the same spirit , That is, rely on visual input to answer questions .
To be specific , The author observed , In most of the most advanced knowledge-based VQA In the method :1) Visual features are either extracted from the whole image , Or retrieve knowledge by sliding window , The object area is ignored / The important relationship between ;2) In the final answer model , Visual features are not well utilized , This is somewhat counter intuitive .
Based on these observations , The author puts forward a new knowledge-based VQA Method REVISE, This method is not only in the stage of knowledge retrieval , And in the answer model , Both try to take advantage of the explicit information of the object region . The key motivation of this paper is that the object region and internal relationship are important to knowledge-based VQA It's very important .
The author in the standard OK-VQA Extensive experiments have been carried out on the dataset , Achieved the latest performance , namely 58.0% The accuracy of , It is much more advanced than the previous methods (+3.6%). The author also makes a detailed analysis , It also shows that regional information is based on knowledge VQA Necessity in different framework components of .
02
Motivation
In everyday life , Many vision based decision-making processes go beyond perception and recognition . for example , If we see a salad in a deli , Our decision to buy it or not depends not only on what's in the salad , It also depends on the number of calories in each item . This motivates knowledge-based visual Q & A (VQA) Mission , This task extends the traditional VQA Mission , To solve more complex problems , That is, answering open domain questions requires common sense .
According to the definition , Knowledge based VQA Use three different sources of information to predict the answer : Enter visual information ( Images )、 Input questions and external knowledge . Although the existing knowledge-based VQA The research mainly focuses on improving the integration of external knowledge , But this paper focuses on improving the object - centered visual representation , A comprehensive empirical study is proposed to prove the importance of visual features in this task .

Intuitively speaking , Visual information should be well used for knowledge retrieval and final answer . However , The author found the most advanced (SOTA) Method does not make full use of it . One side , They simply use the entire image or a sliding window on the image to retrieve external knowledge . On the other hand , They only use visual information for knowledge retrieval , The visual information is ignored in the final answer model . let me put it another way , They only treat the retrieved knowledge and problems as pure natural language (NLP) Model fusion , To get the answer , Upper figure (b) A typical method is described in .
In this paper , The author revisits knowledge-based VQA Visual representation in , It is believed that the information of the target area and its relationship should be specially considered and used . Upper figure (a) Shows the underlying motivation , This shows that it is necessary to understand the object and its relationship . So , The author puts forward REVISE Make better use of regional visual representation for knowledge-based visual Q & A . It not only uses detailed regional information for better knowledge retrieval , It also integrates the regional visual representation into the final answer model . say concretely , The author first uses an object detector GLIP To locate objects , Then use the crop region proposal To retrieve different types of external knowledge . Last , The knowledge and regional visual features are integrated into a unified based on Transformer In the answer model , To generate the final answer .
The author in OK-VQA Extensive experiments have been carried out on the dataset , The proposed REVISE Realized 58.0% Of SOTA performance , Than before SOTA The result of the method is absolutely improved 3.6%.
The contributions of this paper are summarized as follows :
The author systematically discusses how to make better use of visual features to retrieve knowledge . Experimental results show that , Compared with the method based on full image and sliding window , The region based approach performs best .
The author represents the region visually 、 The retrieved external knowledge and implicit knowledge are integrated into Transformer In the question and answer model of , The model can effectively use these three information sources to solve knowledge-based problems VQA problem .
Proposed by the author REVISE stay OK-VQA State of the art performance on datasets , namely 58.0% The accuracy of , Much more than previous methods .
03
Method
Knowledge based VQA The task seeks to answer questions based on external knowledge other than images . say concretely , Will be based on knowledge VQA The data set is represented as , Where, respectively, denotes the i Input image of samples 、 Questions and answers ,N It's the total number of samples . Given data set , The goal is to train a parameter of θ Model of , Use input and generate answers .

The figure above shows REVISE An overview of the method . Firstly, the region detected in the input image is used to obtain the region feature centered on the object and retrieve the explicit knowledge , meanwhile , By area marking 、 The question and context are based on GPT-3 To retrieve implicit knowledge . then , The visual features of the area 、 The knowledge retrieved and marked by the region 、 The text prompt composed of question and context is integrated into the codec module # in , Generate answers .
3.1 Regional Feature Extraction Module
Given an image I, The author first uses a target detector to give the region proposal The location of :

among , yes bouding boxes Set ,M It was detected box Count ,D(·) It's a target detector . here , Adopted by the author Visual Grounding Model GLIP As D(·). The author uses text prompts “ testing : people 、 Bicycle 、 automobile 、…、 toothbrush ”, It includes MSCOCO All object categories of the dataset . such , The model can provide all bounding boxes associated with these categories .
In from GLIP Get the bounding box of the object of interest in B after , According to B Crop the image I, To get the area proposal. then , The author from proposal To extract object - centric visual features , Among them is the j individual proposal Visual embedding ,S It's embedded dimensions ,E(·) Represents an image encoder . Inspired by the powerful transfer ability of the recently contrast trained visual language model , Adopted by the author CLIP As an image encoder E(·), And use [CLS] token As the final embedding .
In order to understand the relationship between objects , The author found that the introduction of location information B And its regional visual features are also important . In addition to embedding , Get each area explicitly in text format proposal The description of is also helpful for knowledge retrieval . For the visual language model after comparative training , If the image and text align well , The training loss will obviously increase the inner product between image embedding and text embedding . therefore , Such a model can calculate the inner product , From a set of custom tags, select the tag that describes the image . take CLIP The language encoder of is expressed as T(·). Given a set of labels ,N1 Is the total number of tags , The author calculates the area proposal And all labels , And adopt the method with top-P The similarity label is used as the region proposal Description of .

Where is the inner product ,P Indicates the number of area labels obtained ,h Indicates the retrieved area label .
As a supplement to the local text description , Adopted by the author caption Model to clearly describe the relationship between the main objects , And provide more context :

among ,C(·) yes caption Model . for example , In the diagram above ,“Two brown dogs fighting over a red frisbee” Provides basic relationships between objects . here , Adopted by the author Vinvl As a Title Model C(·).
in general , Extract the regional visual and position information as and , The text description of the object and the relationship between the objects are and . These are external knowledge retrieved from regional information sources .
3.2 Object-Centric Knowledge Retrieval Module
In this paper , The author considers both explicit knowledge and tacit knowledge .
3.2.1 Explicit Knowledge
Due to knowledge-based VQA The questions raised are general and open , Therefore, the introduction of external knowledge is very important for the model to generate accurate answers by providing additional supplementary knowledge beyond the visual content of the input image .
External Knowledge Base
The author from Wikidata Build a subset , So as to build an external knowledge base Q. To be specific , The author extracted 8 There are four common categories , Role 、 Point of interest 、 Tools 、 vehicle 、 animal 、 clothing 、 company 、 motion , To form a subset Q.Q Each item in consists of an entity and a corresponding description , for example , An entity and its description can be “ Nailboard ” and “ Slab wall with fixed spacing holes , For inserting nails or hooks ”.
Regional Knowledge Retrieval
image CLIP Such a visual language model can select the most relevant text from a set of texts . The author puts the knowledge base Q The entries in are reformatted to “{entity} yes {description}”, And represent the reformatted text set as . Author retrieves all areas proposal The most relevant former K Knowledge items , As explicit knowledge :

among K Indicates the number of explicit knowledge samples retrieved .
3.2.2 Implicit Knowledge
Large language models , Such as GPT-3, Not only do you excel in many language tasks , Moreover, a large amount of common sense knowledge is memorized from its training corpus . therefore , The author uses GPT-3 As an implicit knowledge base , Rephrase the task as an open domain question and answer .
Context-Aware Prompt with Regional Descriptions
According to the question Q、 title c And area markers H Design text prompts . say concretely , The author uses a hint X by “context: {caption} + {tags}. question: {question}”. such , The language model also complements the regional visual information .
Implicit Knowledge Retrieval
Last , The author will rewrite the tips X Input to GPT-3 Model , And get the predicted answer . Because some questions may be ambiguous , The author adopts prompt tuning The process , Get the candidate answers . In addition to the answer prediction , The author also hopes to learn from GPT-3 Get corresponding explanation in the model , For more context information .
More specifically , Through to the GPT-3 Enter a text prompt in “{question} {answer candidate}. This is because”, The corresponding explanation can be obtained . Be careful ,{question} and {answer candidate} They are images I Input questions for Q and GPT-3 The answer . Finally, the retrieved implicit knowledge can be expressed as .
3.3 Encoder-Decoder Module
Once explicit and implicit knowledge and regional information are retrieved , using FiD The network structure encodes and decodes the retrieved knowledge and regional information .
Knowledge Encoder
For explicit knowledge , The author reformats the input text as “entity: {entity} description: {description}”, The entities and descriptions come from the entries in the retrieved explicit knowledge . The author represents this text as , among .
For tacit knowledge , Adopted by the author “candidate: {answer} evidence: {explanation}” Input format for , The answer is the retrieved answer , Explanation is . here ,, Where is GPT-3 Number of answers provided . Represent the input text as .
then , adopt FiD The encoder encodes knowledge in text format , The encoder is represented as :

among ,D Represents an embedded dimension
Visual Encoder
The author introduces a visual encoder for visual embedding and position coordinates . The author will and feed into two different full connection layers , Superimpose the output into a series of vectors , Then feed it into Transformer Encoder :

among , And are two different fully connected layers , Along the new dimension concat operation .
Context-aware Question Encoder
To make better use of contextual information , The author will enter questions Q Replace with context aware prompts X, Then use the same Transformer The encoder encodes it :

among , Represents the context aware problem of encoding .
Generative Decoder
Now you have the knowledge code 、 Visual coding and context aware problem coding . Be careful , As the output of the encoder , They are all vector sequences . then , The authors take these vectors along the first dimension concat get up , And enter them FiD The decoder of :

among y Represents the generated answer . The cross entropy loss function is used to train the model :

among ,L yes ground truth The length of the answer text , It's at the location ground truth Text ,θ Is the model parameter .
Model Ensemble
To generate more accurate answers , A very effective method is to use multiple trained models , Model integration . In the experiment , The author only trains three models with different initialization seeds , Then select the most frequent result from the results generated by the three models as the final answer prediction of each sample .
04
experiment

As shown in the table , You can see the previous work ( for example ,KRISP、Visual Retriever Reader and MAVEx) Achieved similar performance , The accuracy is about 38.4% to 39.4%.
lately ,PICa Is the first language model using pre training GPT-3 As a knowledge-based VQA Knowledge base of tasks , and KAT Further introduce Wikidata As an external knowledge resource , These two works have made remarkable achievements compared with previous works .REVISE Can be significantly superior to all existing methods .
To be specific , Even if you use the same knowledge resources ( namely Wikidata and GPT-3) Our single model can also achieve 56.6% The accuracy of , And the most advanced method before KAT The accuracy of is 53.1%. When using model integration , The method in this paper can achieve 58.0% The accuracy of , and KAT The accuracy of is 54.4%. These results prove the effectiveness of the proposed method .
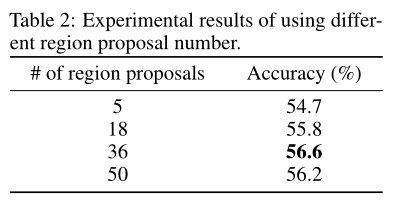
The authors conducted ablation studies , To understand the use of different areas proposal The effect of . The results are shown in the table above . Can be observed , Local area proposal The number of 36 when , The model achieves the best performance . Notice this speculation , Local area proposal When the quantity of is too large , There will be some meaningless and noisy areas proposal, And if the area proposal The quantity is too small , Many important object centric areas are ignored , This will affect the performance of the model .

The method of using visual representation to retrieve knowledge is based on knowledge VQA Plays an important role in . The above table shows the results of using three knowledge retrieval methods , It's image-based 、 Sliding window based and region based .

To introduce more semantics into the context , The author proposes adding a region aware description after a given context ( That is, the area mark ,regional tags). In the above table, the author reports on the text prompt X Results marked with different area markers . It turns out that , When the number of area labels is 30 when , This algorithm has the best performance . in fact , When the number of area markers is too large , Relatively unrelated object tags will be retrieved , Thus sacrificing the performance of the model .

Except for areas that will be object centric proposal The visual representation of is incorporated outside the model , The author also uses location information ( Position coordinates ). The results of using position coordinates are reported in the above table . Introducing area coordinates can improve performance 0.8 percentage .

To better show REVISE The effect of each ingredient , The author reports the experimental results in the above table . Please note that , The author chooses a region based approach to retrieve different categories of knowledge . Can be observed , The introduced components can continuously improve the performance of the model .

The successful cases of this method are shown in the figure above . Can be observed , This method can accurately retrieve the implicit and explicit knowledge corresponding to the detected object region , And handle the relationship between these object areas .

The above figure shows an example of a failure . As shown in the left example , Even if the forecast results Cabin Not in ground truth In the answer , The answers generated by this method are still reasonable for this situation .
05
summary
In this paper , The author proposes a method called REVIVE Methods , This approach reexamines knowledge-based VQA Visual representation of the task area . To be specific , The author conducted a comprehensive experiment , To show the effect of different components in the proposed method , This can prove the effectiveness of the proposed region based knowledge retrieval method . Besides ,REVISE The object-centered visual features and two kinds of knowledge , Implicit knowledge and explicit knowledge , Integrated into the predicted answer generation model . The method of this paper is in OK-VQA State of the art performance on datasets .
Reference material
[1]http://arxiv.org/abs/2206.01201

END
Welcome to join 「 Video Q & A 」 Exchange group notes :VQA

边栏推荐
- [high concurrency] 28000 words' summary of callable and future interview knowledge points. After reading it, I went directly to ByteDance. Forgive me for being a little drifting (middle)
- Stable currency risk profile: are usdt and usdc safe?
- 留给比亚迪的时间还有三年
- 【黑马早报】中公教育市值蒸发逾2000亿;新东方直播粉丝破2000万;HM关闭中国首店;万科郁亮称房地产已触底;微信上线“大爆炸”功能...
- 节点数据采集和标签信息的远程洪泛传输
- GWD:基于高斯Wasserstein距离的旋转目标检测 | ICML 2021
- 嵌入式开发:硬件在环测试
- win11怎么看cpu几核几线程? win11查看cpu是几核几线程的教程
- Redis master-slave replication principle
- Redis的数据过期清除策略 与 内存淘汰策略
猜你喜欢

靠代理,靠买断,国产端游的蛮荒时代等待下一个《永劫无间》

vmware虚拟机的作用
VQA不只需要图片,还需要外部知识!华盛顿大学&微软提出提出REVIVE,用GPT-3和Wikidata来辅助回答问题!...

Wechat applet: install B artifact and P diagram, modify wechat traffic main applet source code, Download funny joke diagram, make server free domain name

现场快递柜状态采集与控制系统

leetcode:226. Flip binary tree

【jenkins】pipeline控制多job顺序执行,进行定时持续集成

Unity SplashImage 缩放问题

Analysis of istio -- observability
![[important notice] the 2022 series of awards and recommendations of China graphics society were launched](/img/ae/2fe0cf9964e5fd3b18e5f295638d8b.png)
[important notice] the 2022 series of awards and recommendations of China graphics society were launched
随机推荐
Industry analysis - quick intercom, building intercom
Kubernetes Pod 排错指南
如何优雅的写 Controller 层代码?
By proxy, by buyout, the wild era of domestic end-to-end travel is waiting for the next "eternal robbery"
MySQL数据库:存储引擎
Redis' data expiration clearing strategy and memory obsolescence strategy
布隆过滤器Bloom Filter简介
【shell】jenkins shell实现自动部署
《canvas》之第8章 像素操作
Crazy digital collections, the next myth of making wealth?
BYD has three years left
.NET程序配置文件操作(ini,cfg,config)
Redis为什么这么快?Redis是单线程还是多线程?
单端口RAM实现FIFO
Transport layer user datagram protocol (UDP)
内网穿透(nc)
c语言入门教程–-6循环语句
How goby exports scan results
golang代码规范整理
关于MongoDB报错:connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb