当前位置:网站首页>2022cuda summer training camp Day6 practice
2022cuda summer training camp Day6 practice
2022-07-29 10:27:00 【Hua Weiyun】

2022CUDA Summer training camp Day1 practice https://bbs.huaweicloud.com/blogs/364478
2022CUDA Summer training camp Day2 practice https://bbs.huaweicloud.com/blogs/364479
2022CUDA Summer training camp Day3 practice https://bbs.huaweicloud.com/blogs/364480
2022CUDA Summer training camp Day4 Unified memory of practice https://bbs.huaweicloud.com/blogs/364481
2022CUDA Summer training camp Day4 Atomic operation of practice https://bbs.huaweicloud.com/blogs/364482
2022CUDA Summer training camp Day5 practice https://bbs.huaweicloud.com/blogs/364483
“ utilize GPU Calculation TOP10” It doesn't have to be a kernel function , You can also use Thrust Of CUDA Acceleration tool library :
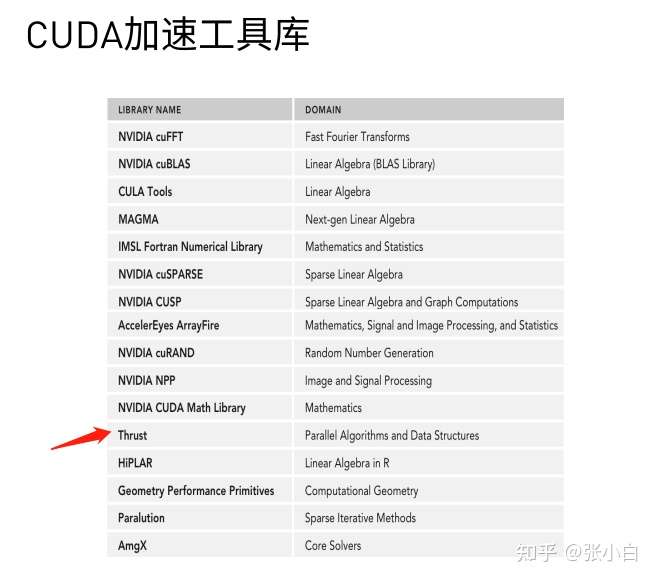
cub and Thrust In fact, it is also a good way to sort !
CUDA Thrust The information of is here :https://docs.nvidia.com/cuda/thrust/index.html
Let's try sorting first .
First , Zhang Xiaobai found this :https://blog.csdn.net/qq_23123181/article/details/122116099
There's an example , So Zhang Xiaobai used his Nano Upper Juputer Made an attempt :
This is the use of cmake Compilation of , There are the following documents :
CMakeLists.txt
CMAKE_MINIMUM_REQUIRED(VERSION 3.5)PROJECT(thrust_examples)set(CMAKE_BUILD_TYPE Release)find_package(CUDA)include_directories(${CUDA_INCLUDE_DIRS})message(STATUS "${CUDA_INCLUDE_DIRS}")message(STATUS "${CUDA_LIBRARIES}")cuda_add_executable(thrust_examples sort.cu)sort.cu
This Zhang Xiaobai added a little print information , In this way, you can see clearly :
#include <thrust/host_vector.h>#include <thrust/device_vector.h>#include <thrust/generate.h>#include <thrust/sort.h>#include <thrust/copy.h>#include <algorithm>#include <vector>#include <time.h>#define TOPK 20 int main(void){ thrust::host_vector<int> h_vec(10000*1000); std::generate(h_vec.begin(), h_vec.end(), rand); std::cout<< "size()=" << h_vec.size() <<std::endl; std::vector<int> vec(h_vec.size()); // h_vec->vec thrust::copy(h_vec.begin(), h_vec.end(), vec.begin()); // h_vec->d_vec thrust::device_vector<int> d_vec=h_vec; clock_t time1,time2; //sort d_vec //std::cout<< "d_vec.size()=" << d_vec.size() <<std::endl; std::cout<< "before sort d_vec..." <<std::endl; for(int i = 0; i < TOPK; ++i) { std::cout << d_vec[i] << " "; } std::cout << std::endl; std::cout << std::endl; time1 = clock(); thrust::sort(d_vec.begin(), d_vec.end()); time2 = clock(); std::cout<<(double)(time2-time1)/CLOCKS_PER_SEC*1000<< " ms"<<std::endl; std::cout << std::endl; std::cout<< "after sort d_vec..." <<std::endl; for(int i = 0; i < TOPK; ++i) { std::cout << d_vec[i] << " "; } std::cout << std::endl; std::cout << std::endl; //sort vec //std::cout<< "vec.size()=" << vec.size() <<std::endl; std::cout<< "before sort vec..." <<std::endl; for(int i = 0; i < TOPK; ++i) { std::cout << vec[i] << " "; } std::cout << std::endl; std::cout << std::endl; time1 = clock(); std::sort(vec.begin(),vec.end()); time2 = clock(); std::cout<<(double)(time2-time1)/CLOCKS_PER_SEC*1000<< " ms"<<std::endl; std::cout << std::endl; std::cout<< "after sort vec..." <<std::endl; for(int i = 0; i < TOPK; ++i) { std::cout << vec[i] << " "; } std::cout << std::endl; std::cout << std::endl; //sort h_vec //std::cout<< "h_vec.size()=" << h_vec.size() <<std::endl; std::cout<< "before sort h_vec..." <<std::endl; for(int i = 0; i < TOPK; ++i) { std::cout << h_vec[i] << " "; } std::cout << std::endl; std::cout << std::endl; time1 = clock(); thrust::sort(h_vec.begin(), h_vec.end()); time2 = clock(); std::cout<<(double)(time2-time1)/CLOCKS_PER_SEC*1000<< " ms"<<std::endl; std::cout << std::endl; std::cout<< "after sort h_vec..." <<std::endl; for(int i = 0; i < TOPK; ++i) { std::cout << h_vec[i] << " "; } std::cout << std::endl; return 0;}The three types are sorted respectively :
1.host_vector(thrust Of )
2.vector(STL Of )
3.device_vector(thrust Of )
Let's start with , Look at the effect :
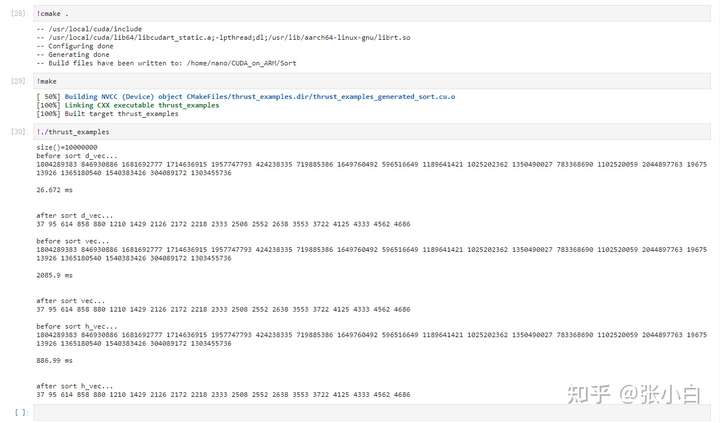
Read about the :
This code applies for a host_vector Type of h_vec, And randomly generated 1000 Ten thousand records .
Then they applied for vector Type of vec and device_vector Type of d_vec, And assign the value to follow h_vec Exactly the same .
Then use... Separately
thrust::sort(d_vec.begin(), d_vec.end());
std::sort(vec.begin(),vec.end());
thrust::sort(h_vec.begin(), h_vec.end());
Give these three respectively 1000 10000 random numbers ( Currently in ascending order )
And print out the smallest 10 Number ( And TOP10 Corresponding , Maybe it should be called BOTTOM10 Well ? Zhang Xiaobai thinks so ...)
The second one sort Is not thrust Library . The first and the third sort It's using thrust library .
It can also be seen from the final calculated time result :
Standard library sort Longest time ——2085.9ms
HOST Upper thrust sort Longer time consuming ——886.99ms
DEVICE Upper thrust sort It takes the shortest time ——26.672ms.
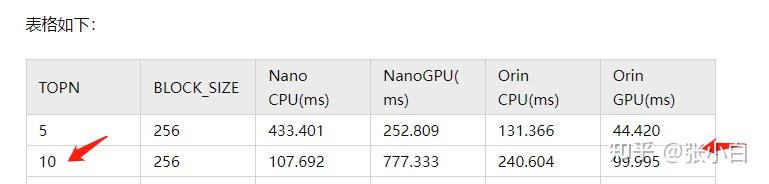
It looks like this , It seems to be better than all the tests in yesterday's homework .
yesterday TOP10 The data of is here :( Zhang Xiaobai :2022CUDA Summer training camp Day5 Practice top10 )
Let's implement the code :
Let's do it !
The original code is as follows :
sort2.cu
#include <stdio.h>#include <stdlib.h>#include <time.h> #include "error.cuh"#define BLOCK_SIZE 256#define N 1000000#define GRID_SIZE ((N + BLOCK_SIZE - 1) / BLOCK_SIZE) #define topk 10__managed__ int source_array[N];__managed__ int _1pass_results[topk * GRID_SIZE];__managed__ int final_results[topk];__device__ __host__ void insert_value(int* array, int k, int data){ for (int i = 0; i < k; i++) { if (array[i] == data) { return; } } if (data < array[k - 1]) return; for (int i = k - 2; i >= 0; i--) { if (data > array[i]) array[i + 1] = array[i]; else { array[i + 1] = data; return; } } array[0] = data;}__global__ void top_k(int* input, int length, int* output, int k){ }void cpu_result_topk(int* input, int count, int* output){ /*for (int i = 0; i < topk; i++) { output[i] = INT_MIN; }*/ for (int i = 0; i < count; i++) { insert_value(output, topk, input[i]); }}void _init(int* ptr, int count){ srand((unsigned)time(NULL)); for (int i = 0; i < count; i++) ptr[i] = rand();}int main(int argc, char const* argv[]){ int cpu_result[topk] = { 0 }; cudaEvent_t start, stop; CHECK(cudaEventCreate(&start)); CHECK(cudaEventCreate(&stop)); //Fill input data buffer _init(source_array, N); printf("\n***********GPU RUN**************\n"); CHECK(cudaEventRecord(start)); top_k << <GRID_SIZE, BLOCK_SIZE >> > (source_array, N, _1pass_results, topk); CHECK(cudaGetLastError()); top_k << <1, BLOCK_SIZE >> > (_1pass_results, topk * GRID_SIZE, final_results, topk); CHECK(cudaGetLastError()); CHECK(cudaDeviceSynchronize()); CHECK(cudaEventRecord(stop)); CHECK(cudaEventSynchronize(stop)); float elapsed_time; CHECK(cudaEventElapsedTime(&elapsed_time, start, stop)); printf("Time = %g ms.\n", elapsed_time); CHECK(cudaEventDestroy(start)); CHECK(cudaEventDestroy(stop)); cpu_result_topk(source_array, N, cpu_result); int ok = 1; for (int i = 0; i < topk; ++i) { printf("cpu top%d: %d; gpu top%d: %d \n", i + 1, cpu_result[i], i + 1, final_results[i]); if (fabs(cpu_result[i] - final_results[i]) > (1.0e-10)) { ok = 0; } } if (ok) { printf("Pass!!!\n"); } else { printf("Error!!!\n"); } return 0;}First migrate the code framework to cmake On compiler :
CMakeLists.txt
CMAKE_MINIMUM_REQUIRED(VERSION 3.5)PROJECT(thrust_examples)set(CMAKE_BUILD_TYPE Release)find_package(CUDA)include_directories(${CUDA_INCLUDE_DIRS})message(STATUS "${CUDA_INCLUDE_DIRS}")message(STATUS "${CUDA_LIBRARIES}")cuda_add_executable(thrust_examples sort2.cu)It's very simple , take sort.cu Change it to sort2.cu that will do .
And then to sort2.cu add sort.cu The header file :
#include <stdio.h>#include <stdlib.h>#include <time.h> #include "error.cuh"#include <thrust/host_vector.h>#include <thrust/device_vector.h>#include <thrust/generate.h>#include <thrust/sort.h>#include <thrust/copy.h>#include <algorithm>#include <vector>And comment out GPU RUN That part of the code .
And in GPU RUN Where to join thrust Related code .
printf("\n***********GPU RUN**************\n"); CHECK(cudaEventRecord(start)); // Definition host_vector thrust::host_vector<int> h_vec; // Traverse source_array, And assign it to host_vector for(int i= 0; i< N; i++) { h_vec.push_back(source_array[i]); } printf("h_vec push ok!\n"); // Definition device_vector, take host_vector Copied to the device_vector thrust::device_vector<int> d_vec=h_vec; printf("d_vec init ok!\n"); CHECK(cudaGetLastError()); // to device_vector Sort thrust::sort(d_vec.begin(), d_vec.end()); printf("d_vec sort ok!\n"); for (int i = 0; i < topk ; i++) { final_results[i] = d_vec[vec.size()-1-i]; } printf("vec sort ok!\n");The following is the same as the original code , It's printing CPU TOP10, as well as cudaEvent_t By calculation GPU Time .
Let's show it all :
sort2.cu
#include <stdio.h>#include <stdlib.h>#include <time.h> #include "error.cuh"#include <thrust/host_vector.h>#include <thrust/device_vector.h>#include <thrust/generate.h>#include <thrust/sort.h>#include <thrust/copy.h>#include <algorithm>#include <vector>#define BLOCK_SIZE 256#define N 10000000#define GRID_SIZE ((N + BLOCK_SIZE - 1) / BLOCK_SIZE) #define topk 10__managed__ int source_array[N];__managed__ int _1pass_results[topk * GRID_SIZE];__managed__ int final_results[topk];__device__ __host__ void insert_value(int* array, int k, int data){ for (int i = 0; i < k; i++) { if (array[i] == data) { return; } } if (data < array[k - 1]) return; for (int i = k - 2; i >= 0; i--) { if (data > array[i]) array[i + 1] = array[i]; else { array[i + 1] = data; return; } } array[0] = data;}__global__ void top_k(int* input, int length, int* output, int k){ }void cpu_result_topk(int* input, int count, int* output){ /*for (int i = 0; i < topk; i++) { output[i] = INT_MIN; }*/ for (int i = 0; i < count; i++) { insert_value(output, topk, input[i]); }}void _init(int* ptr, int count){ srand((unsigned)time(NULL)); for (int i = 0; i < count; i++) ptr[i] = rand();}int main(int argc, char const* argv[]){ int cpu_result[topk] = { 0 }; cudaEvent_t start, stop; CHECK(cudaEventCreate(&start)); CHECK(cudaEventCreate(&stop)); //Fill input data buffer _init(source_array, N); printf("\n***********GPU RUN**************\n"); CHECK(cudaEventRecord(start)); // Definition host_vector thrust::host_vector<int> h_vec; // Traverse source_array, And assign it to host_vector for(int i= 0; i< N; i++) { h_vec.push_back(source_array[i]); } printf("h_vec push ok!\n"); // Definition device_vector, take host_vector Copied to the device_vector thrust::device_vector<int> d_vec=h_vec; printf("d_vec init ok!\n"); CHECK(cudaGetLastError()); // to device_vector Sort thrust::sort(d_vec.begin(), d_vec.end()); printf("d_vec sort ok!\n"); // Take out the inverted 10 Bits are deposited in final_results Array for (int i = 0; i < topk ; i++) { final_results[i] = d_vec[d_vec.size()-1-i]; } printf("final_results set ok!\n"); /* top_k << <GRID_SIZE, BLOCK_SIZE >> > (source_array, N, _1pass_results, topk); top_k << <1, BLOCK_SIZE >> > (_1pass_results, topk * GRID_SIZE, final_results, topk); CHECK(cudaGetLastError()); */ //CHECK(cudaDeviceSynchronize()); CHECK(cudaEventRecord(stop)); CHECK(cudaEventSynchronize(stop)); float elapsed_time; CHECK(cudaEventElapsedTime(&elapsed_time, start, stop)); CHECK(cudaEventDestroy(start)); CHECK(cudaEventDestroy(stop)); cpu_result_topk(source_array, N, cpu_result); int ok = 1; for (int i = 0; i < topk; ++i) { printf("cpu top%d: %d; gpu top%d: %d \n", i + 1, cpu_result[i], i + 1, final_results[i]); if (fabs(cpu_result[i] - final_results[i]) > (1.0e-10)) { ok = 0; } } if (ok) { printf("Pass!!!\n"); } else { printf("Error!!!\n"); } printf("GPU Time = %g ms.\n", elapsed_time); return 0;}Compile implementation :
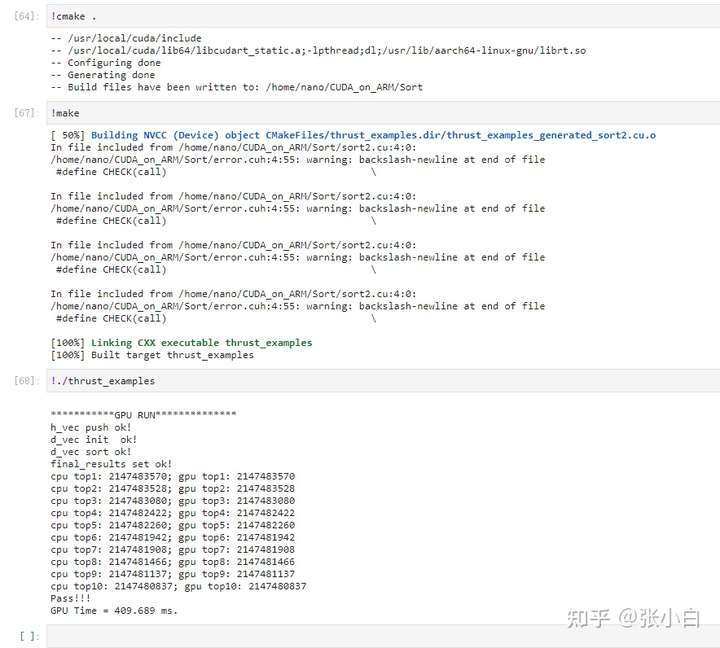
There's no problem with execution .
It's just , It seems to be a little time-consuming . Mainly from the code source_array Copy the array to host_vector Of h_vec, Again from host_vector Of h_vec copy to device_vector Of d_vec, Then sort .
Let's print out the specific time carefully :
printf("\n***********GPU RUN**************\n"); CHECK(cudaEventRecord(start)); // Definition host_vector thrust::host_vector<int> h_vec; // Traverse source_array, And assign it to host_vector for(int i= 0; i< N; i++) { h_vec.push_back(source_array[i]); } printf("h_vec push ok!\n"); CHECK(cudaGetLastError()); CHECK(cudaEventRecord(stop1)); CHECK(cudaEventSynchronize(stop1)); float elapsed_time; CHECK(cudaEventElapsedTime(&elapsed_time, start, stop1)); printf("h_vec push Time = %g ms.\n", elapsed_time); // Definition device_vector, take host_vector Copied to the device_vector thrust::device_vector<int> d_vec=h_vec; printf("d_vec init ok!\n"); CHECK(cudaGetLastError()); CHECK(cudaEventRecord(stop2)); CHECK(cudaEventSynchronize(stop2)); CHECK(cudaEventElapsedTime(&elapsed_time, stop1, stop2)); printf("d_vec init Time = %g ms.\n", elapsed_time); // to device_vector Sort thrust::sort(d_vec.begin(), d_vec.end()); printf("d_vec sort ok!\n"); CHECK(cudaGetLastError()); CHECK(cudaEventRecord(stop3)); CHECK(cudaEventSynchronize(stop3)); CHECK(cudaEventElapsedTime(&elapsed_time, stop2, stop3)); printf("d_vec sort Time = %g ms.\n", elapsed_time); // Take out the inverted 10 Bits are deposited in final_results Array for (int i = 0; i < topk ; i++) { final_results[i] = d_vec[d_vec.size()-1-i]; } printf("final_results set ok!\n"); CHECK(cudaGetLastError()); CHECK(cudaEventRecord(stop4)); CHECK(cudaEventSynchronize(stop4)); CHECK(cudaEventElapsedTime(&elapsed_time, stop3, stop4)); printf("final_results set Time = %g ms.\n", elapsed_time); CHECK(cudaEventDestroy(start)); CHECK(cudaEventDestroy(stop1)); CHECK(cudaEventDestroy(stop2)); CHECK(cudaEventDestroy(stop3)); CHECK(cudaEventDestroy(stop4));Recompile execution :
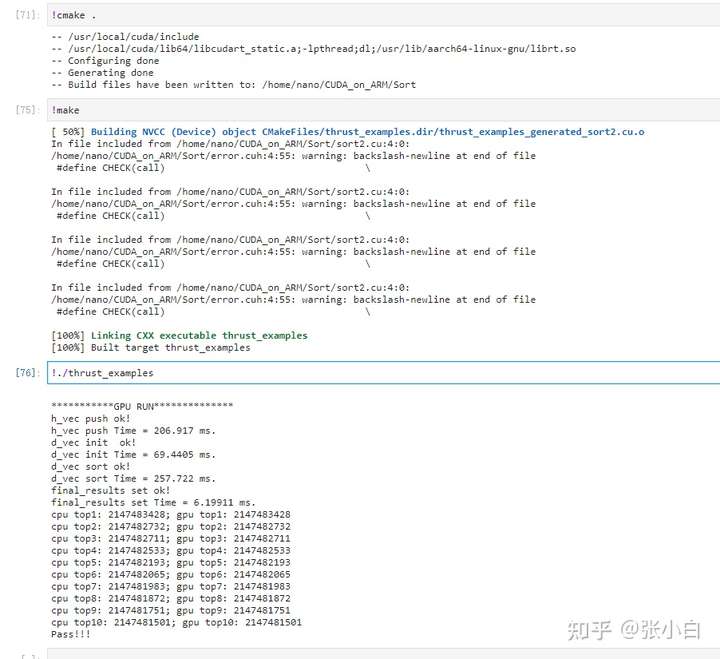
The specific time is :
- from source_array Copy the array to host_vector:206ms
- from host_vector copy to device_vector:89ms
- device_vector Sort :257ms
- Copy results to final_results:6ms
( There is a possibility of jitter in the above data )
But Zhang Xiaobai tried to source_array The array is copied directly to device_vector, But it didn't work .
For example, write the code like this :
float elapsed_time; printf("\n***********GPU RUN**************\n"); CHECK(cudaEventRecord(start)); // Definition host_vector /* thrust::host_vector<int> h_vec; // Traverse source_array, And assign it to host_vector for(int i= 0; i< N; i++) { h_vec.push_back(source_array[i]); } printf("h_vec push ok!\n"); CHECK(cudaGetLastError()); CHECK(cudaEventRecord(stop1)); CHECK(cudaEventSynchronize(stop1)); CHECK(cudaEventElapsedTime(&elapsed_time, start, stop1)); printf("h_vec push Time = %g ms.\n", elapsed_time); */ // Definition device_vector, take host_vector Copied to the device_vector //thrust::device_vector<int> d_vec=h_vec; thrust::device_vector<int> d_vec; // Traverse source_array, And assign it to device_vector for(int i= 0; i< N; i++) { d_vec.push_back(source_array[i]); } printf("d_vec init ok!\n"); CHECK(cudaGetLastError()); CHECK(cudaEventRecord(stop2)); CHECK(cudaEventSynchronize(stop2)); //CHECK(cudaEventElapsedTime(&elapsed_time, stop1, stop2)); CHECK(cudaEventElapsedTime(&elapsed_time, start, stop2)); printf("d_vec init Time = %g ms.\n", elapsed_time); // to device_vector Sort thrust::sort(d_vec.begin(), d_vec.end()); printf("d_vec sort ok!\n"); CHECK(cudaGetLastError()); CHECK(cudaEventRecord(stop3)); CHECK(cudaEventSynchronize(stop3)); CHECK(cudaEventElapsedTime(&elapsed_time, stop2, stop3)); printf("d_vec sort Time = %g ms.\n", elapsed_time); // Take out the inverted 10 Bits are deposited in final_results Array for (int i = 0; i < topk ; i++) { final_results[i] = d_vec[d_vec.size()-1-i]; } printf("final_results set ok!\n"); CHECK(cudaGetLastError()); CHECK(cudaEventRecord(stop4)); CHECK(cudaEventSynchronize(stop4)); CHECK(cudaEventElapsedTime(&elapsed_time, stop3, stop4)); printf("final_results set Time = %g ms.\n", elapsed_time); CHECK(cudaEventDestroy(start)); CHECK(cudaEventDestroy(stop1)); CHECK(cudaEventDestroy(stop2)); CHECK(cudaEventDestroy(stop3)); CHECK(cudaEventDestroy(stop4));It gets stuck directly when running , I don't know why :
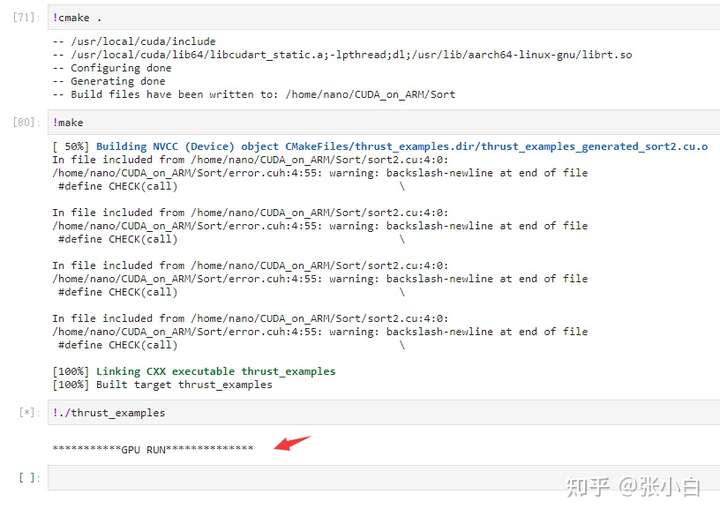
Maybe some great Xia knows , Can you tell me .
( The full text after , Thank you for reading )
边栏推荐
- Tips of Day1 practice in 2022cuda summer training camp
- 通俗易懂讲解梯度下降法!
- What happens when MySQL tables change from compressed tables to ordinary tables
- Only simple function test? One article takes you to advanced interface automatic testing technology in 6 steps
- Intel joins hands with datawhale to launch learning projects!
- Solve problems intelligently
- Oracle advanced (XIV) explanation of escape characters
- What is "enterprise level" low code? Five abilities that must be possessed to become enterprise level low code
- Print out the "hourglass" and the remaining number according to the given number of characters and characters
- DW: optimize the training process of target detection and more comprehensive calculation of positive and negative weights | CVPR 2022
猜你喜欢
Tell you from my accident: Mastering asynchrony is key

Comprehensive and detailed SQL learning guide (MySQL direction)

Attachment of text of chenjie Report

Summary of window system operation skills

Function - (C travel notes)

Does neural network sound tall? Take you to train a network from scratch (based on MNIST)

This developer, who has been on the list for four consecutive weeks, has lived like a contemporary college student

跟着田老师学实用英语语法(持续更新)
敏捷开发如何消减协作中的认知偏差?| 敏捷之道

【论文阅读】I-BERT: Integer-only BERT Quantization
随机推荐
Where are those test / development programmers in their 30s? a man should be independent at the age of thirty......
Performance optimization analysis tool | perf
Research on Android multithreading (4) -- from an interview question
二次握手??三次挥手??
Docker installation, redis configuration and remote connection
Static resource mapping
[wechat applet] interface generates customized homepage QR code
The server
高效能7个习惯学习笔记
【论文阅读】Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
【黑马早报】每日优鲜回应解散,多地已无法下单;李斌称蔚来将每年出一部手机;李嘉诚欲抄底恒大香港总部大楼;今年国庆休7天上7天...
leetcode刷题——排序
Soft exam summary
Skiasharp's WPF self drawn bouncing ball (case version)
[untitled]
全面、详细的SQL学习指南(MySQL方向)
JS temporary dead zone_ Temporary
Leetcode question brushing - sorting
remap_ Use of table in impdp
可线性渐变的环形进度条的实现探究