当前位置:网站首页>[image segmentation] 2021 segformer neurips
[image segmentation] 2021 segformer neurips
2022-07-01 22:50:00 【Talk about it】
List of articles
【 Image segmentation 】2021-SegFormer NeurIPS
Thesis title : SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
Address of thesis :https://arxiv.org/abs/2105.15203v3
Code address : https://github.com/NVlabs/SegFormer
Paper team : The university of Hong Kong , Nanjing University , NVIDIA, Caltech
SegFormer Detailed explanation of the paper ,2021CVPR Included , take Transformer Works combined with semantic segmentation ,
1. brief introduction
1.1 brief introduction
- 2021 It can be said that the year of the outbreak of segmentation algorithm , First
ViTBy introducing transform take ADE20K mIOU The accuracy is brushed to 50%, More than beforeHRnet+OCReffect , - And then... Again
SwinTu Bang's major visual tasks , In the classification , Semantic segmentation and instance segmentation have been achieved SOTA, Capture ICCV2021 Of bset paper, - then Segformer There is something to rely on transform Further optimization , On the basis of getting higher accuracy, it also greatly improves the real-time performance of the model .
The motivation sources are :SETR Use in VIT As backbone The extracted features are relatively single ,PE Limit the diversity of forecasts , Tradition CNN Of Decoder To restore features is a complex process . Mainly propose multi-level Transformer-Encoder and MLP-Decoder, The performance reaches SOTA.
1.2 Problem solved
SegFormer It is a will. transformer And lightweight multilayer perceptron (MLP) Semantic segmentation framework unified by decoder .SegFormer The advantage is that :
- SegFormer A novel hierarchical structure is designed transformer Encoder , Output multiscale features . It doesn't need a location code , Thus, the interpolation of position coding is avoided ( When the test resolution is different from the training resolution , Can cause performance degradation ).
- SegFormer Avoid complex decoder . Proposed MLP The decoder aggregates information from different layers , This combines local and global concerns to present a powerful representation . The author shows that this simple and lightweight design is effective transformer The key to .
2. The Internet
2.1 framework
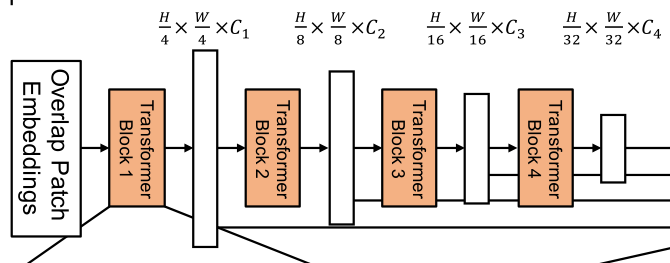
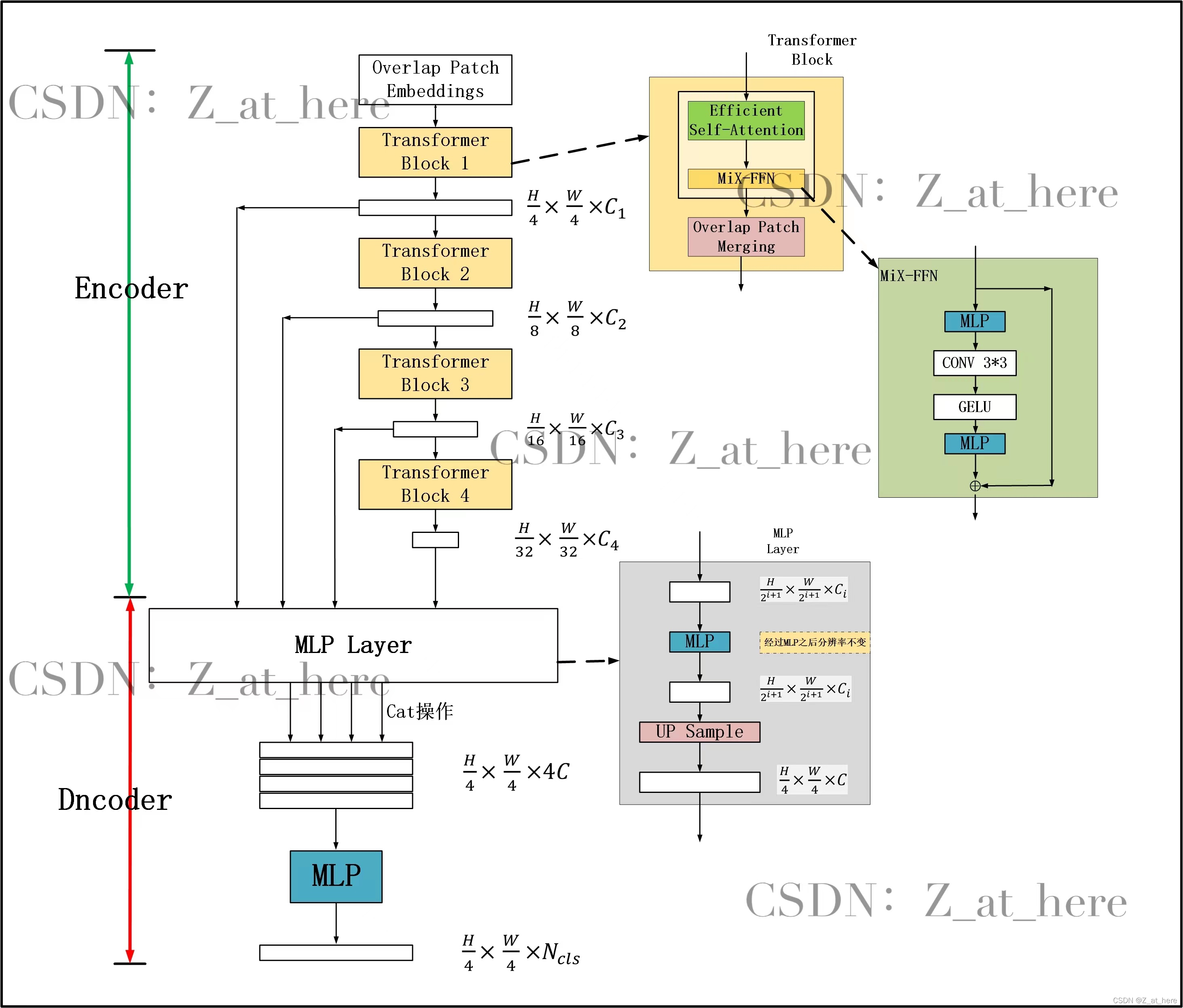
1) The overall structure

This architecture is similar to ResNet,Swin-Transformer. After a period ,
Encoder : A layered Transformer Encoder , It is used to generate high-resolution coarse features and low-resolution fine features
from Transformer blocks*N Form a separate stage (stage).
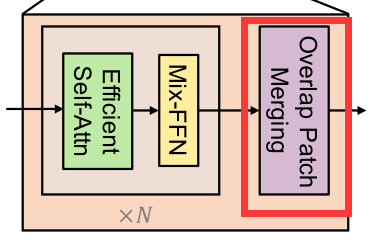
One Transformer block from 3 Component composition
- Overlap Patch Merging
- Mix-FFN
- Effcient Self-Atten
decoder : A lightweight All-MLP decoder , Integrate these multilevel features , Generate the final semantic segmentation mask .
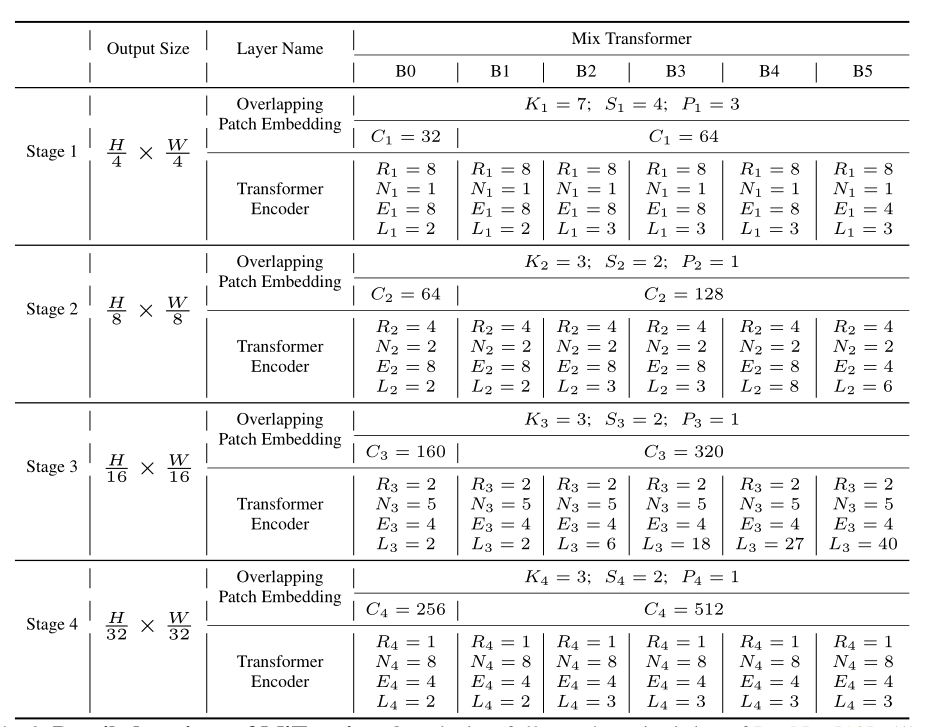
2) Encoder configuration
Here is SegFormer The encoder Specific configuration of
3) Hierarchical structure
And can only generate single resolution feature map ViT Different , The goal of this module is to generate similar cnn Multi level features of . These features provide high-resolution coarse features and low-resolution fine-grained features , It can usually improve the performance of semantic segmentation .
More precisely , Given a resolution of H × W × 3 H\times W\times 3 H×W×3. We carry out patch Merge , Get a resolution of ( H 2 i + 1 × W 2 i + 1 × C ) (\frac{H}{2^{i+1}}\times \frac{W}{2^{i+1}}\times C) (2i+1H×2i+1W×C) Hierarchical characteristic diagram of F i F_i Fi, among i ∈ { 1 , 2 , 3 , 4 } i\in\{1,2,3,4\} i∈{ 1,2,3,4}.
for instance , After a period F 1 = ( H 4 × W 4 × C ) → F 2 = ( H 8 × W 8 × C ) F_1=(\frac{H}{4}\times \frac{W}{4}\times C) \to F_2=(\frac{H}{8}\times \frac{W}{8}\times C) F1=(4H×4W×C)→F2=(8H×8W×C)
2.2 A layered Transformer decoder
Encoder by 3 Component composition , First of all , Down sampling module
1) Overlap Patch Merging
For an image patch,ViT Used in patch The merge process will be a N × N × 3 N\times N\times 3 N×N×3 The images of are unified into 1 × 1 × C 1\times 1\times C 1×1×C vector . This can be easily extended to a 2 × 2 × C i 2\times 2\times C_i 2×2×Ci Feature paths are unified into one 1 × 1 × C i + 1 1\times 1\times C_{i+1} 1×1×Ci+1 Vector , To obtain hierarchical feature mapping .
Use this method , Hierarchy properties can be changed from F 1 = ( H 4 × W 4 × C ) → F 2 = ( H 8 × W 8 × C ) F_1=(\frac{H}{4}\times \frac{W}{4}\times C) \to F_2=(\frac{H}{8}\times \frac{W}{8}\times C) F1=(4H×4W×C)→F2=(8H×8W×C). Then iterate over any other property mappings in the hierarchy . This process was originally designed to combine non overlapping images or feature blocks . therefore , It cannot maintain local continuity around these patches . contrary , We use overlapping patch merging process . therefore , The author of the paper sets K,S,P by (7,4,3)(3,2,1) To overlap Patch merging. among ,K by kernel,S by Stride,P by padding.
It's so fancy , In fact, the function is
and MaxPooling equally, Play aDown samplingThe effect of . Make the feature map original 1 2 \frac{1}{2} 21
2) Efficient Self-Attention
The main computing bottleneck of the encoder is the self - attention layer . In the original multi head self attention process , Every head K , Q , V K,Q,V K,Q,V All have the same dimension N × C N\times C N×C, among N = H × W N=H\times W N=H×W Is the length of the sequence , It is estimated that self attention is :
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d h e a d ) V Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_{head}}})V Attention(Q,K,V)=Softmax(dheadQKT)V
The computational complexity of this process is O ( N 2 ) O(N^2) O(N2), This is huge for large resolution images .
The author of the paper thinks that , The amount of computation of the network is mainly reflected in the self attention mechanism layer . In order to reduce the computational complexity of the whole network , Based on the mechanism of self attention , Scale factor added R R R, To reduce the computational complexity of each self attention mechanism module .
K ^ = R e s h a p e ( N R , C ⋅ R ) ( K ) K = L i n e a r ( C ⋅ R , C ) ( K ^ ) \begin{aligned} \hat{K}&=Reshape(\frac{N}{R},C\cdot R)(K) \\ K&=Linear(C\cdot R,C)(\hat{K}) \end{aligned} K^K=Reshape(RN,C⋅R)(K)=Linear(C⋅R,C)(K^)
The first step is K K K The shape of is made up of N × C N\times C N×C Turn into N R × ( C ⋅ R ) \frac{N}{R}\times(C\cdot R) RN×(C⋅R),
The second step will be K K K The shape of is made up of N R × ( C ⋅ R ) \frac{N}{R}\times(C\cdot R) RN×(C⋅R) Turn into N R × C \frac{N}{R}\times C RN×C. therefore , The computational complexity is determined by O ( N 2 ) O(N^2) O(N2) Down to O ( N 2 R ) O(\frac{N^2}{R}) O(RN2). Among the parameters given by the author , Stage 1 To the stage 4 Of R R R Respectively [ 64 , 16 , 4 , 1 ] [64,16,4,1] [64,16,4,1]
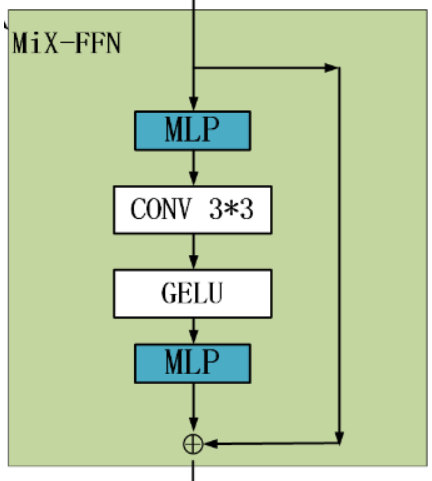
3) Mix-FFN
VIT Use location coding PE(Position Encoder) To insert location information , But the inserted PE The resolution is fixed , This leads to different resolutions between the training image and the test image , Need to be right PE Perform interpolation , This will lead to a decrease in accuracy .
To solve this problem CPVT(Conditional positional encodings for vision transformers. arXiv, 2021) Used 3X3 Convolution sum of PE Together we have achieved data-driver PE.
Introduced a Mix-FFN, Considering padding Impact on location information , Directly in FFN (feed-forward network) Use in One 3x3 Convolution of ,MiX-FFN It can be expressed as follows :
X o u t = M L P ( G E L U ( C o n v 3 × 3 ( M L P ( X i n ) ) ) ) + X i n X_{out}=MLP(GELU(Conv_{3\times3}(MLP(X_{in}))))+X_{in} Xout=MLP(GELU(Conv3×3(MLP(Xin))))+Xin
among X i n X_{in} Xin It's from self-attention The output of the feature.Mix-FFN Mixed with a 3 ∗ 3 3*3 3∗3 Convolution sum of MLP In every one of them FFN in . According to the above formula, we can know MiX-FFN The order is : Input through MLP, Reuse C o n v 3 × 3 Conv_{3\times3} Conv3×3 operation , Passing through a GELU Activation function , Re pass MLP operation , Finally, the output and the original input value are superimposed , As MiX-FFN The total output of .
In the experiment, the author shows 3 ∗ 3 3*3 3∗3 The convolution of can be transformer Provide PE. The author still uses depth to separate convolution and improve efficiency , Reduce parameters .
2.3 Lightweight MLP decoder
SegFormer Integrated with a lightweight decoder , Contains only MLP layer . The key to implementing this simple decoder is ,SegFormer Grade of Transformer Encoder is better than traditional CNN The encoder has a larger effective acceptance domain (ERF).
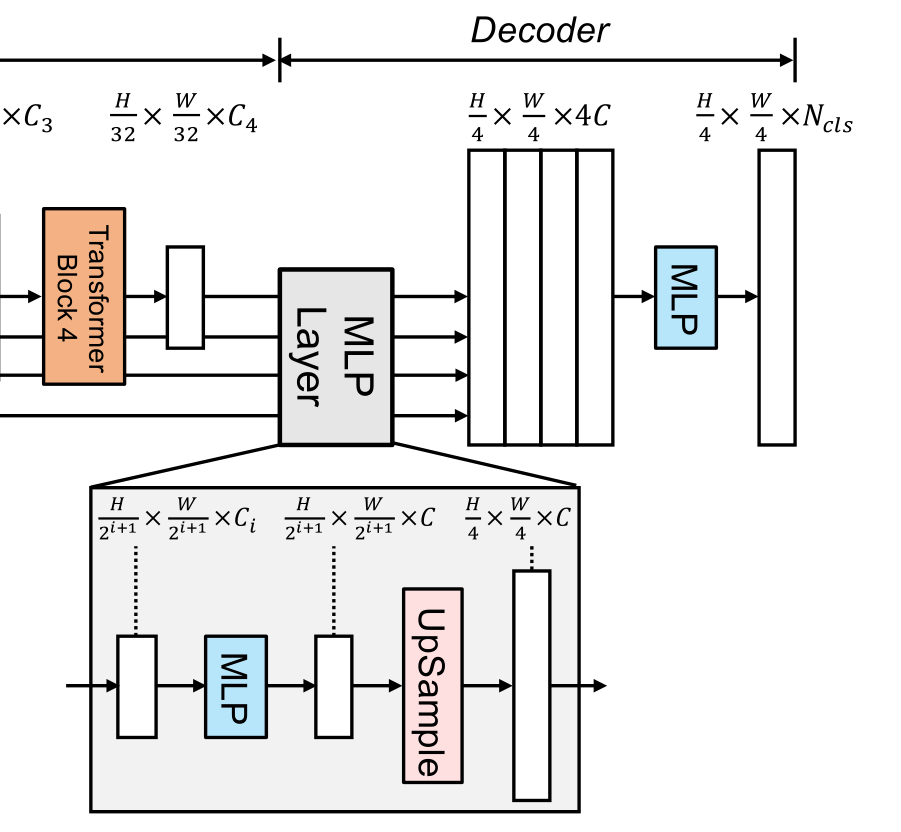
SegFormer All proposed mlp The decoder consists of four main steps .
- come from MiT The multilevel characteristics of the encoder pass MLP Layer to unify the channel dimension .
- Features are upsampled to 1/4 And connected together .
- use MLP Layer fusion cascade feature F F F
- the other one MLP The layer adopts fused H 4 × W 4 × N c l s \frac{H}{4}\times \frac{W}{4}\times N_{cls} 4H×4W×Ncls Resolution feature to predict segmentation mask M M M, Where represents the number of categories
The decoder can be expressed as :
F ^ i = L i n e a r ( C i , C ) ( F i ) , ∀ i F ^ i = U p s a m p l e ( W 4 × W 4 ) ( F ^ i ) , ∀ i F = L i n e a r ( 4 C , C ) ( C o n c a t ( F ^ i ) ) , ∀ i M = L i n e a r ( C , N c l s ) ( F ) \begin{aligned} \hat{F}_i&=Linear(C_i,C)(F_i),\forall i \\ \hat{F}_i&=Upsample(\frac{W}{4}\times \frac{W}{4})(\hat{F}_i),\forall i \\ F&=Linear(4C,C)(Concat(\hat{F}_i)),\forall i \\ M&=Linear(C,N_{cls})(F) \end{aligned} F^iF^iFM=Linear(Ci,C)(Fi),∀i=Upsample(4W×4W)(F^i),∀i=Linear(4C,C)(Concat(F^i)),∀i=Linear(C,Ncls)(F)
2.4 Effective acceptance of vision (ERF)
This part is To prove The decoder is very effective
For semantic segmentation , Maintaining a large acceptance domain to contain context information has always been a central issue .SegFormer Use a valid accepted domain (ERF) As a tool package to visualize and explain why All-MLP The decoder is designed in TransFormer So effective in . Visualized in the figure below DeepLabv3+ and SegFormer Four encoder stages and decoder head ERF:
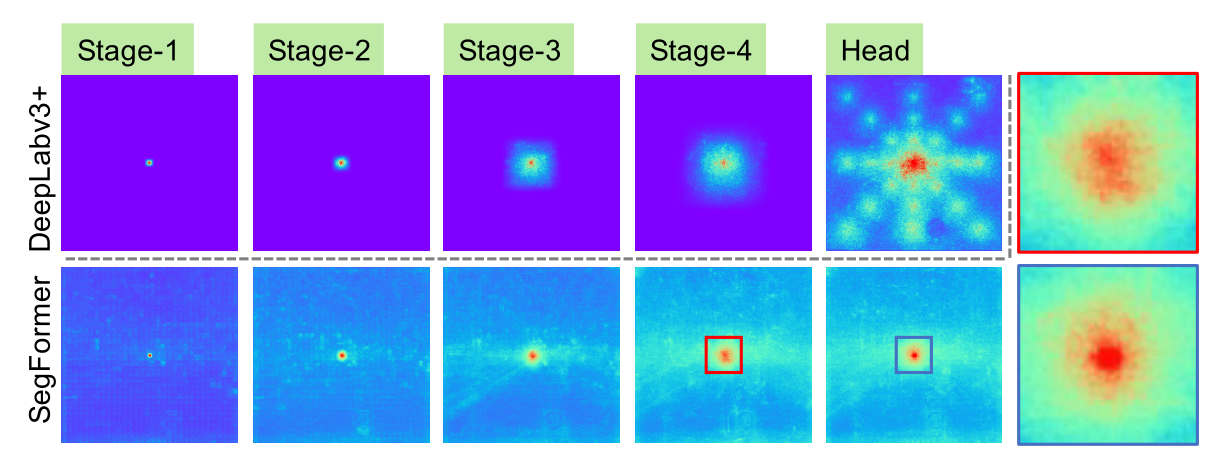
As you can see from the picture above :
- DeepLabv3+ Of ERF Even in the deepest Stage4 It's also relatively small .
- SegFormer The encoder naturally produces local attention , Similar to the convolution of the lower stage , At the same time, it can output highly nonlocal attention , Capture effectively Stage4 The context of .
- If enlarge Patch Shown ,MLP The head of the ERF( Blue frame ) And Stage4( Red box ) Different , Its non local attention and local attention are significantly enhanced .
CNN The acceptance domain of is limited , We need to expand the acceptance domain with the help of context module , But it inevitably complicates the network .All-MLP The decoder design benefits from transformer Nonlocal attention in , And lead to a larger acceptance domain without complexity . However , The same decoder is designed in CNN It doesn't work well on the trunk , Because the whole acceptance domain is in Stage4 The upper bound of a finite field .
what's more ,All-MLP The decoder design essentially utilizes Transformer Induced properties , Generate high local and nonlocal attention at the same time . By unifying them ,All-MLP The decoder presents a complementary and powerful representation by adding some parameters . This is another key reason that drives our design .
3. Code
What's shown below SegFormer Of Bo edition . Other versions , You can adjust it yourself
from math import sqrt
from functools import partial
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, reduce
from einops.layers.torch import Rearrange
# helpers
def exists(val):
return val is not None
def cast_tuple(val, depth):
return val if isinstance(val, tuple) else (val,) * depth
# classes
class DsConv2d(nn.Module):
def __init__(self, dim_in, dim_out, kernel_size, padding, stride=1, bias=True):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(dim_in, dim_in, kernel_size=kernel_size, padding=padding, groups=dim_in, stride=stride,
bias=bias),
nn.Conv2d(dim_in, dim_out, kernel_size=1, bias=bias)
)
def forward(self, x):
return self.net(x)
class LayerNorm(nn.Module):
def __init__(self, dim, eps=1e-5):
super().__init__()
self.eps = eps
self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
def forward(self, x):
std = torch.var(x, dim=1, unbiased=False, keepdim=True).sqrt()
mean = torch.mean(x, dim=1, keepdim=True)
return (x - mean) / (std + self.eps) * self.g + self.b
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = LayerNorm(dim)
def forward(self, x):
return self.fn(self.norm(x))
class EfficientSelfAttention(nn.Module):
def __init__(
self,
*,
dim,
heads,
reduction_ratio
):
""" From the attention level Args: dim: Input dimensions heads: Attention head count reduction_ratio: Zoom factor """
super().__init__()
self.scale = (dim // heads) ** -0.5
self.heads = heads
self.to_q = nn.Conv2d(dim, dim, 1, bias=False)
self.to_kv = nn.Conv2d(dim, dim * 2, reduction_ratio, stride=reduction_ratio, bias=False)
self.to_out = nn.Conv2d(dim, dim, 1, bias=False)
def forward(self, x):
h, w = x.shape[-2:]
heads = self.heads
q, k, v = (self.to_q(x), *self.to_kv(x).chunk(2, dim=1))
q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) (x y) c', h=heads), (q, k, v))
sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
attn = sim.softmax(dim=-1)
out = einsum('b i j, b j d -> b i d', attn, v)
out = rearrange(out, '(b h) (x y) c -> b (h c) x y', h=heads, x=h, y=w)
return self.to_out(out)
class MixFeedForward(nn.Module):
def __init__(
self,
*,
dim,
expansion_factor
):
super().__init__()
hidden_dim = dim * expansion_factor
self.net = nn.Sequential(
nn.Conv2d(dim, hidden_dim, 1),
DsConv2d(hidden_dim, hidden_dim, 3, padding=1),
nn.GELU(),
nn.Conv2d(hidden_dim, dim, 1)
)
def forward(self, x):
return self.net(x)
class MiT(nn.Module):
def __init__(
self,
*,
channels,
dims,
heads,
ff_expansion,
reduction_ratio,
num_layers
):
""" Mix Transformer Encoder Args: channels: dims: heads: ff_expansion: reduction_ratio: num_layers: """
super().__init__()
stage_kernel_stride_pad = ((7, 4, 3), (3, 2, 1), (3, 2, 1), (3, 2, 1))
dims = (channels, *dims)
dim_pairs = list(zip(dims[:-1], dims[1:]))
self.stages = nn.ModuleList([])
for (dim_in, dim_out), (kernel, stride, padding), num_layers, ff_expansion, heads, reduction_ratio in \
zip(dim_pairs, stage_kernel_stride_pad, num_layers, ff_expansion, heads, reduction_ratio):
get_overlap_patches = nn.Unfold(kernel, stride=stride, padding=padding)
overlap_patch_embed = nn.Conv2d(dim_in * kernel ** 2, dim_out, 1)
layers = nn.ModuleList([])
for _ in range(num_layers):
layers.append(nn.ModuleList([
PreNorm(dim_out, EfficientSelfAttention(dim=dim_out,
heads=heads,
reduction_ratio=reduction_ratio)),
PreNorm(dim_out, MixFeedForward(dim=dim_out, expansion_factor=ff_expansion)),
]))
self.stages.append(nn.ModuleList([
get_overlap_patches,
overlap_patch_embed,
layers
]))
def forward(self, x, return_layer_outputs=False):
# wide , high
h, w = x.shape[-2:]
layer_outputs = []
for (get_overlap_patches, overlap_embed, layers) in self.stages:
x = get_overlap_patches(x)
num_patches = x.shape[-1]
ratio = int(sqrt((h * w) / num_patches))
x = rearrange(x, 'b c (h w) -> b c h w', h=h // ratio)
x = overlap_embed(x)
# Start calculating
for (attn, ff) in layers:
x = attn(x) + x
x = ff(x) + x
layer_outputs.append(x)
ret = x if not return_layer_outputs else layer_outputs
return ret
class Segformer(nn.Module):
def __init__(
self,
*,
dims=(32, 64, 160, 256),
heads=(1, 2, 5, 8),
ff_expansion=(8, 8, 4, 4),
reduction_ratio=(8, 4, 2, 1),
num_layers=2,
channels=3,
decoder_dim=256,
num_classes=19
):
""" Args: dims: 4 Stages , The number of channels coming out heads: Each stage , The number of attention heads used ff_expansion: mix-ffn in 3*3 Expansion ratio of convolution reduction_ratio: Self attention layer scaling factor num_layers: Every transformer blocks Number of block repetitions channels: Enter the number of channels , It's usually 3 decoder_dim: Decoder dimension . effect : The characteristic diagram of encoder is unified On the sampling --> decoder_dim dimension num_classes: Number of categories """
super().__init__()
# This function is used to , If it's a number , Just copy 4 branch , become tuple. such as 2-->(2,2,2,2)
dims, heads, ff_expansion, reduction_ratio, num_layers = map(partial(cast_tuple, depth=4),
(dims, heads, ff_expansion, reduction_ratio,
num_layers))
assert all([*map(lambda t: len(t) == 4, (dims, heads, ff_expansion, reduction_ratio,
num_layers))]), 'only four stages are allowed, all keyword arguments must be either a single value or a tuple of 4 values'
self.mit = MiT(
channels=channels,
dims=dims,
heads=heads,
ff_expansion=ff_expansion,
reduction_ratio=reduction_ratio,
num_layers=num_layers
)
self.to_fused = nn.ModuleList([nn.Sequential(
nn.Conv2d(dim, decoder_dim, 1),
nn.Upsample(scale_factor=2 ** (i))
) for i, dim in enumerate(dims)])
self.to_segmentation = nn.Sequential(
nn.Conv2d(4 * decoder_dim, decoder_dim, 1),
nn.Conv2d(decoder_dim, num_classes, 1),
)
def forward(self, x):
# Back to 4 Eigenvalues , Respectively the 1/4 ,1/8, 1/16, 1/32
layer_outputs = self.mit(x, return_layer_outputs=True)
""" torch.Size([1, 32, 56, 56]) torch.Size([1, 64, 28, 28]) torch.Size([1, 160, 14, 14]) torch.Size([1, 256, 7, 7]) """
# Here is the upper sampling
fused = [to_fused(output) for output, to_fused in zip(layer_outputs, self.to_fused)]
# print(len(fused))
# print(fused[0].shape)
fused = torch.cat(fused, dim=1)
fused = self.to_segmentation(fused)
# Direct and right 1/4 Characteristic graph . Sample up
return F.interpolate(fused, size=x.shape[2:], mode='bilinear', align_corners=False)
if __name__ == '__main__':
x = torch.randn(size=(1, 3, 224, 224))
model = Segformer()
print(model)
from thop import profile
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input,))
print("flops:{:.3f}G".format(flops / 1e9))
print("params:{:.3f}M".format(params / 1e6))
# y = model(x)
# print(y.shape)
Reference material
https://blog.csdn.net/weixin_43610114/article/details/125000614
https://blog.csdn.net/weixin_44579633/article/details/121081763
https://blog.csdn.net/qq_39333636/article/details/124334384
Semantic segmentation of SegFormer Share _xuzz_498100208 The blog of -CSDN Blog
Hands teach you how to use Segformer Train your data _ Zhongke brother's blog -CSDN Blog
边栏推荐
猜你喜欢







随机推荐
Selection of all-optical technology in the park - Part 2
数字货币:影响深远的创新
awoo‘s Favorite Problem(优先队列)
【QT小作】封装一个简单的线程管理类
Awoo's favorite problem (priority queue)
SAP GUI 里的收藏夹事务码管理工具
Pytorch's code for visualizing feature maps after training its own network
基准环路增益与相位裕度的测量
Kubernetes创建Service访问Pod
死锁的处理策略—预防死锁、避免死锁、检测和解除死锁
[C language] detailed explanation of malloc function [easy to understand]
切面条 C语言
Delete AWS bound credit card account
# CutefishOS系统~
功能测试报告的编写
Mysql database detailed learning tutorial
Favorite transaction code management tool in SAP GUI
Cut noodles C language
陈天奇的机器学习编译课(免费)
Use three JS realize the 'ice cream' earth, and let the earth cool for a summer