当前位置:网站首页>Scrapy + Selenium 实现模拟登录,获取页面动态加载数据
Scrapy + Selenium 实现模拟登录,获取页面动态加载数据
2022-08-03 09:26:00 【月亮给我抄代码】
本文是模拟登录某招聘网站,然后获取一个招聘信息页面中的浏览人数。
直接上代码!
1. Scrapy 爬虫文件
import scrapy
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['cs.58.com'] # 允许的域
# 某一个数据信息的url
start_urls = ['https://sz.58.com/zpyiyuanyiliao/45641604514186x.shtml']
# 前置请求,访问登录界面,存储cookie
def start_requests(self):
log_url = "https://passport.58.com/login/?path=https%3A%2F%2Fcs.58.com%2Fjob.shtml%3Futm_source%3Dmarket%26spm%3Du-2d2yxv86y3v43nkddh1.BDPCPZ_BT%26PGTID%3D0d100000-0019-e329-e4d5-4bb0d0c6e79f%26ClickID%3D4&source=58-homepage-pc&PGTID=0d202408-0019-ed52-7dcd-8033768af605&ClickID=2"
yield scrapy.Request(url=log_url)
# 登录成功后,发起对页面数据的请求
def parse(self, response):
print("发起页面信息请求")
yield scrapy.Request(url=self.start_urls[0], callback=self.test, dont_filter=True)
# 解析页面数据,打印输出测试结果
def test(self, response):
print(response.xpath("//span[@class='pos_base_num pos_base_browser']/i/text()").extract_first())
2. 下载中间件:
只改动了 process_request 方法。
import json
import time
from scrapy import signals
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
# 下载中间件
class DemoDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# 无头模式
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
opt.add_argument("log-level=3") # 设置日志等级
# opt.add_argument("--proxy-server=162.14.98.117:16817") # 设置代理
# 规避检测
chrome_opt = ChromeOptions()
chrome_opt.add_experimental_option('excludeSwitches', ['enable-automation', 'enable-logging'])
driver = webdriver.Chrome(executable_path="F:/pycharm/test/3.动态加载数据处理/chromedriver.exe", options=chrome_opt,
chrome_options=opt)
# 设置selenium携带cookie
# 如果是登录请求,存储cookie
if "login" in request.url:
driver.get(request.url)
time.sleep(5)
# 通过selenium输入账号密码,如果只能扫码登录的话就把睡眠时间调长一点,进行手动扫码登录。
driver.find_element(By.ID, "mask_body_item_username").send_keys("xxxxx")
driver.find_element(By.ID, "mask_body_item_newpassword").send_keys("xxxx")
driver.find_element(By.ID, "mask_body_item_login").click()
time.sleep(2)
# 存储cookie
cookies = driver.get_cookies()
jsonData = json.dumps(cookies)
with open("./cookie.json", 'w') as fp:
fp.write(jsonData)
print("cookie存储成功")
return None
# 正常请求,加载 cookie
with open("./cookie.json", "r") as fp2:
list_cookies = json.loads(fp2.read())
driver.get(request.url) # 预请求,很重要!不然会报错。
# cookie的参数可以看存储的json文件
for cookie in list_cookies:
cookie_dict = {
"domain": ".58.com",
# "expiry": int(cookie.get('expiry')),
"httpOnly": False,
"name": cookie.get('name'),
"path": "/",
"secure": False,
"value": cookie.get('value')
}
driver.add_cookie(cookie_dict)
driver.get(request.url) # 携带cookie的真实请求
driver.refresh() # 刷新页面,很重要!
time.sleep(2) # 等待页面加载
data = driver.page_source # 获取页面
driver.close()
# 封装返回对象
response = HtmlResponse(url=request.url, body=data, encoding='utf-8', request=request)
return response
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)注意:运行前,请在 settings 文件中开启 cookie,设置 UA,关闭 robots 协议,启用下载中间件!
效果图:
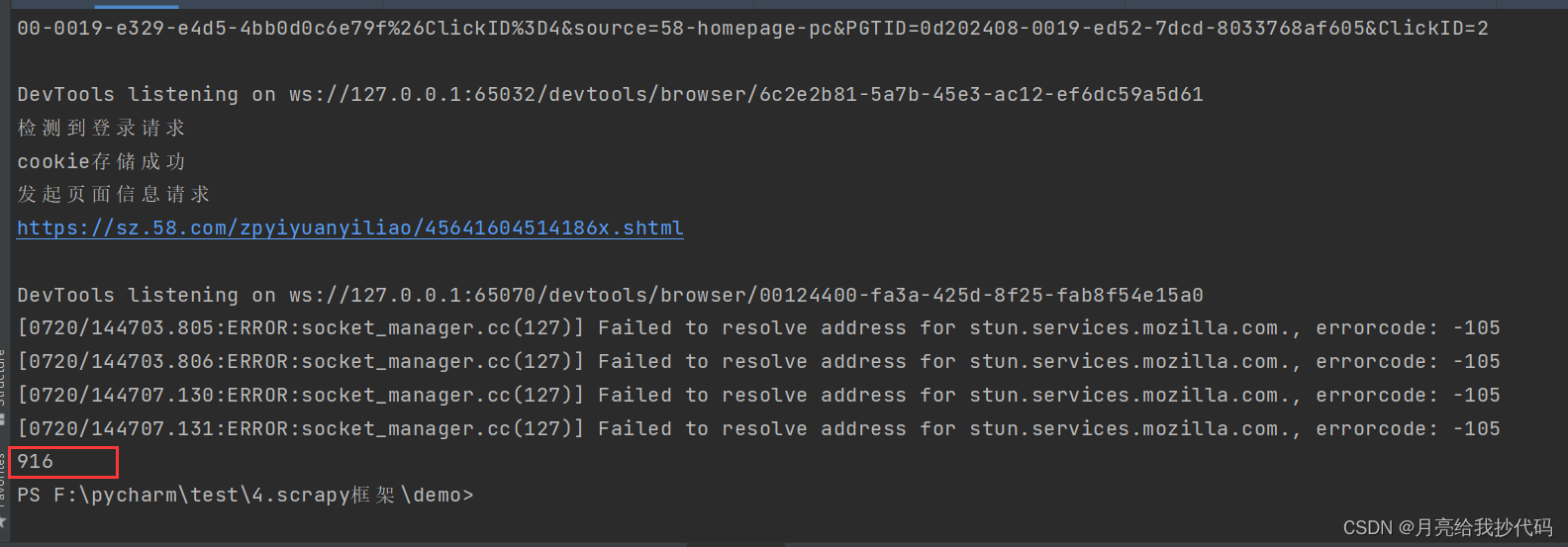
问题一:在添加 cookie 时,报错:selenium.common.exceptions.InvalidArgumentException: Message: invalid argument: invalid ‘expiry’
解决:我直接注释掉了这个参数,然后就正常了。
问题二:添加 cookie 参数后出现报错:selenium.common.exceptions.InvalidCookieDomainException: Message: invalid cookie domain
解决:没有在添加 cookie 前发送预请求,看我代码,加上就可以正常访问了。
边栏推荐
猜你喜欢



随机推荐
Redis的基础与django使用redis
redis实现分布式锁的原理
dflow入门2——Slices
Redis实现分布式锁
cmd(命令行)操作或连接mysql数据库,以及创建数据库与表
【字节面试】word2vector输出多少个类别
milvus
【LeetCode】226. Flip the binary tree
scala reduce、reduceLeft 、reduceRight 、fold、foldLeft 、foldRight
mysql 事务原理详解
MySQL——几种常见的嵌套查询
Redis和Mysql数据同步的两种方案
selenium IDE的3种下载安装方式
Path Prefixes (倍增!树上の二分)
线程介绍与使用
MySQL的主从复制
Redis集群概念与搭建
行业 SaaS 微服务稳定性保障实战
机器学习(公式推导与代码实现)--sklearn机器学习库
ClickHouse删除数据之delete问题详解