当前位置:网站首页>N ¨UWA: Visual Synthesis Pre-training for Neural visUal World creAtionChenfei
N ¨UWA: Visual Synthesis Pre-training for Neural visUal World creAtionChenfei
2022-07-27 11:47:00 【Xiao Chen who wants money】
NUWA: A multimodal approach , Manipulate visual images .

contribution :
1、 One 3D transformer, Can include text 、 Picture and video input .
2、 Put forward 3D Nearby attention(3DNA).3DNA It is composed of local characteristics in spatial and time domain . It not only reduces the complexity , At the same time, the quality of the final visual image is improved .
3、 stay T2I(text-to-image),T2V(text-to-video),Video prediction And so on SOTA result . And the model is not only text-guided image manipulation( Text manipulation picture )( The first row and fourth column of Figure 1 ) It shows a good zero-shot Ability , stay text-guide video manipulation( Text manipulation video )( chart 1 The second row and the first column of ) Also showed a very good ability .
introduction :
some Auto-regressive Autoregressive models are based on pixel-by-pixel The way , So there is a disadvantage : Cannot process high dimensions high-dimensional visual data, Can only handle some low resolution low-resolution Pictures and videos .
lately ,VQ-VAE Is a discrete visual token The method of transformation , Can be effective and in large-scale Training visual synthesis task. But it has one drawback , Namely VQ-VAE Separate video from pictures , It's not friendly for training .
Method :
How to separate standard texts 、 Images 、 video ?
1、 Use a common dimension to get input  , among h and w Represents the height and width of the image ,s How many token(NLP The number of word vectors ),d For each token Dimensions .
, among h and w Represents the height and width of the image ,s How many token(NLP The number of word vectors ),d For each token Dimensions .
2、 Text with a lower-case byte pair encodeing(BPE) Embed text into  in . The text is in h and w Direction has no dimension , So with 1 Express ;
in . The text is in h and w Direction has no dimension , So with 1 Express ;
Input of pictures  , It also needs coding , The formula is as follows :
, It also needs coding , The formula is as follows :

 Representing one encoder, take raw data Send in encoder, obtain , Compare and
Representing one encoder, take raw data Send in encoder, obtain , Compare and  codebook Distance of , among
codebook Distance of , among  ,
, , Get away from Current token, Discretize it , And make use of decoder(G) restructure I_hat. This part is VQ-VAE, And then through G and D Continuous training of , obtain B. final
, Get away from Current token, Discretize it , And make use of decoder(G) restructure I_hat. This part is VQ-VAE, And then through G and D Continuous training of , obtain B. final ![B[z]\in \mathbb R^{h*w*1*d}](http://img.inotgo.com/imagesLocal/202207/27/202207271059007571_1.gif) Used for training ,1 It means there is no temporal dimensions
Used for training ,1 It means there is no temporal dimensions
3、 Video can be regarded as the time extension of images , Recent works such as VideoGPT[48] and VideoGen[51] take VQ-V AE Convolution in encoder starts from 2D Extended to 3D, And train video specific representations . However , This cannot share a common codebook for images and videos . In this paper , We showed how to simply use 2D VQ-GAN Each frame of encoded video can also produce time consistent video , Benefit from both image and video data . The result is expressed as asRh×w×s×d, Where represents the number of frames .
3DNA
A subtraction algorithm , The original paper is written clearly , Not here ( Mainly do K and V Subtraction of )
Loss

边栏推荐
- 你真的会写二分查找吗——变种二分查找
- The difference between microcomputer and single chip microcomputer
- VSCode复制代码时去掉样式/语法高亮/代码高亮/黑色背景
- Keil MDK编译出现..\USER\stm32f10x.h(428): error: #67: expected a “}“错误的解决办法
- 【机器学习-白板推导系列】学习笔记---概率图模型和指数族分布
- Smart pointer (shared_ptr, unique_ptr, weak_ptr)
- 【机器学习-白板推导系列】学习笔记---条件随机场
- Database cli tool docker image
- The C programming language -- (2nd) -- Notes -- 4.11.2
- Moveit2 - 5. Scenario Planning
猜你喜欢

Can you really write binary search - variant binary search

基于反馈率的控制系统原理
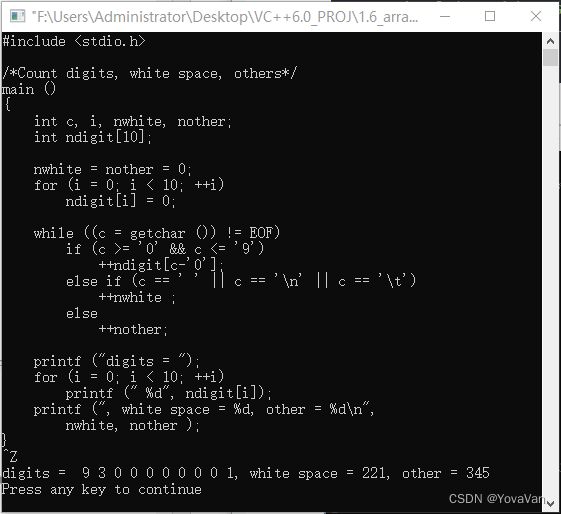
The C programming language (2nd) -- Notes -- 1.6

Keil MDK compilation appears..\user\stm32f10x H (428): error: # 67: expected a "}" wrong solution

Solution of digital tube flash back after proteus8 professional version cracking

【无标题】多模态模型 CLIP

N ¨UWA: Visual Synthesis Pre-training for Neural visUal World creAtionChenfei

第10章 枚举类与注解
Everything cannot be searched for startup_ Lpc11x.s file

Principle of PWM and generation of PWM wave
随机推荐
Arduino常见供电问题与解决
Temporary use of solo, difficult choice of Blog
Modelarts image classification and object detection
(7) Process control
检定和校准的区别
compute_class_weight() takes 1 positional argument but 3 were given
LAN SDN hard core technology insider 25 looking forward to the future - RDMA (Part 2)
Common power supply problems and solutions of Arduino
Stm32f10x -- C Language-1
【Unity入门计划】CreatorKitFPS:第一人称射击3D小游戏
LeetCode 04: T26. 删除排序数组中的重复项(简单); 剑指 Offer 67. 把字符串转换成整数(中等); 面试题 01.08. 零矩阵 (简单)
The C programming language (2nd) -- Notes -- 1.10
JUC框架 从Runnable到Callable到FutureTask 使用浅析
【机器学习-白板推导系列】学习笔记---条件随机场
A possibility that ch340 module cannot be recognized / burned
源码编译安装LAMP
Beyond compare 3 next difference segment / down search arrow not found
Moveit2 - 4. robot model and robot state
为什么选择智能电视?
w.r.t. ; i.e.; etc.; e. G. what does it mean