当前位置:网站首页>Push technology practice | master these two tuning skills to speed up tidb performance a thousand times!
Push technology practice | master these two tuning skills to speed up tidb performance a thousand times!
2022-07-04 01:49:00 【Push @ little assistant】
At the Beijing Winter Olympics , Athletes are fighting hard , They are using speed 、 Power 、 Toughness interprets faster 、 Higher 、 Stronger Olympic spirit , Salute them ! Actually , stay 0 and 1 In the computer world , Developers and programmers in order to improve the running speed of the system 、 Maximize server performance , We also have to face all kinds of challenges , Keep putting forward plans , Practice , To break through the bottleneck 、 Solve the problem .
A push “ Big data cost reduction and efficiency improvement ” project , It is through summing up and sharing their own experience of stepping on the pit in the actual combat process of big data 、 Tuning skills, etc , Provide reference for practitioners to carry out big data practice . This article is about “ Big data cost reduction and efficiency improvement ” The third part of the topic , We will share the tuning through , Realization TiDB Practical experience of thousand times performance improvement .

Getui and TiDB The bond of
As a data intelligence enterprise , One push for hundreds of thousands APP It provides developer services such as message push , At the same time, we provide professional digital solutions for many industry customers . While rapidly developing the business , The company's data volume is also growing rapidly . as time goes on , More and more data ,MySQL It has been unable to meet the needs of the company for rapid query and analysis of data , A kind of Support horizontal elastic expansion , It can effectively deal with high concurrency 、 Massive data scenarios , At the same time, it's highly compatible MySQL The new database has become the selection demand of push .
After in-depth research , We found that “ online celebrity ” database TiDB Not only have the above characteristics , still Financial high availability 、 With strong data consistency 、 Support real-time HTAP Cloud native distributed database . therefore , We decided to MySQL Switch to TiDB, Expectation realization With the increasing amount of data storage , Still ensure fast query of data , Satisfy internal and external customers to analyze data efficiently The needs of , For example, provide timely push and distribution volume for developers and users 、 Arrival rate and other related data reports , Help them make scientific decisions .
After model selection , We started data migration . This migration MySQL The amount of data in the database instance is several T about , We use TiDB Self contained ecological tools Data Migration (DM) Migrate full and incremental data .
- Full data migration : Migrate the table structure of the corresponding table from the data source to TiDB, Then read the stock data , Write to TiDB colony .
- Incremental data replication : After the full data migration is completed , Read the corresponding table change from the data source , Then write to TiDB colony .

Pushers MySQL Data migration to TiDB
When the data synchronization is stable , Gradually migrate the application to TiDB Cluster. After migrating the last application , stop it DM Cluster. This is done from MySQL To TiDB Data migration .
notes :DM See the official document for the specific configuration and use of .
fall into TiDB The use of “ Anti pattern ”
However , When all applications are migrated to TiDB after , But the database response is slow 、 Carton , A series of problems such as application unavailability .
Here's the picture :
When logging in the database, I encountered Caton
By checking , We found a lot of slow SQL Is to use load Script for data import .

slow SQL The import of takes tens of minutes
After communicating with the business party , We found that Some import statements contain tens of thousands of records , Importing takes tens of minutes .
Compare the previous use of MySQL, One import takes only a few minutes or even tens of seconds to complete , And moved to TiDB But it takes double or even several times to complete , Made up of several machines TiDB Cluster is not as good as one MySQL machine .

This is definitely not open TiDB The right posture , We need to find out why , Optimize it .

The load on a single server is too high
Monitor by viewing , It is found that the server load pressure is on one of the machines ( Pictured above , The server marked in the red wireframe bears the main pressure ), This shows that we have not made full use of all our resources at present , Failed to play TiDB As the performance advantage of distributed database .
open TiDB Correct use of posture
First, optimize the configuration parameters
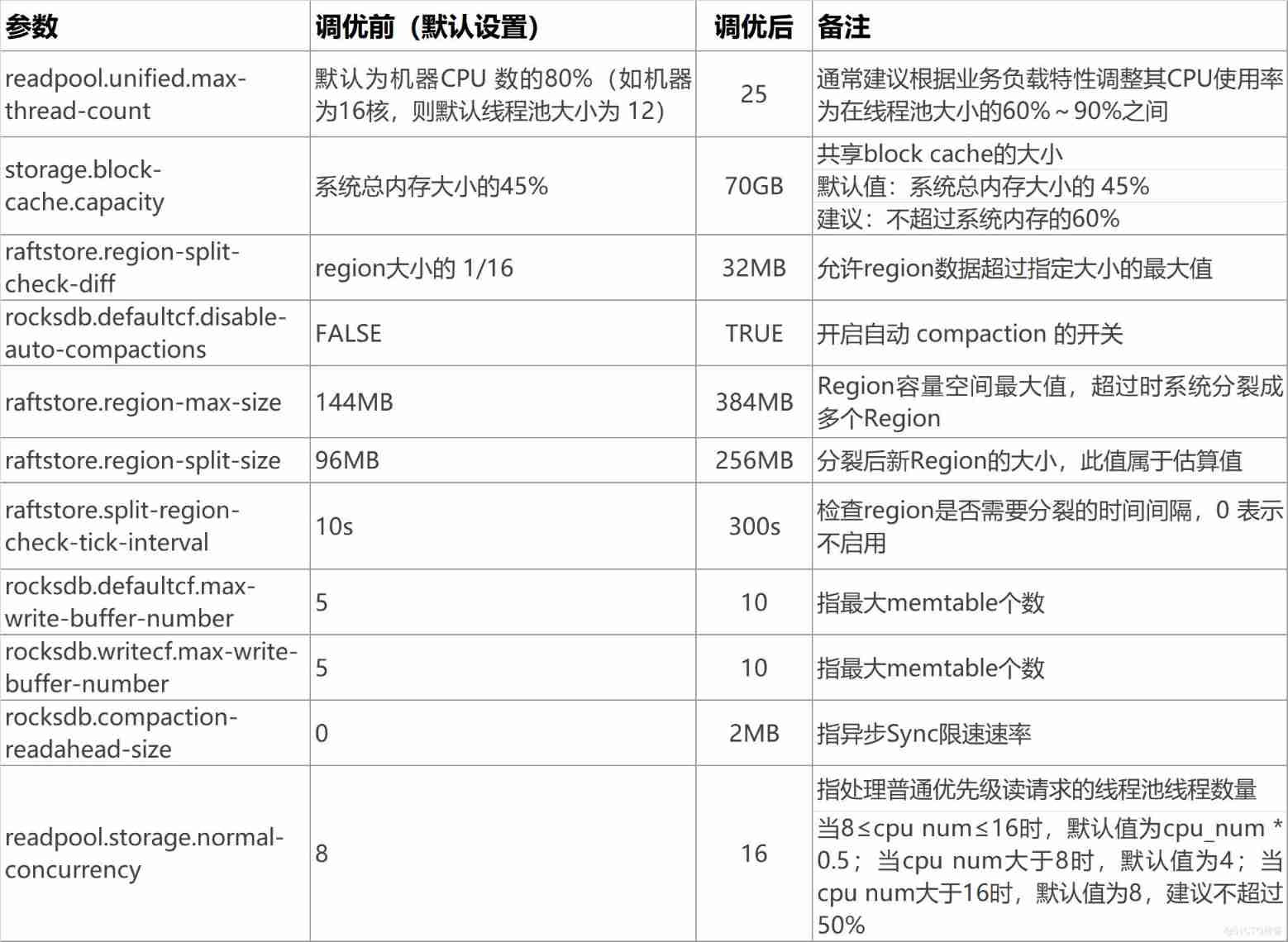
How to optimize it ? Let's start with configuration parameters . as everyone knows , Many configuration parameters are the default parameters of the system , This does not help us make rational use of the performance of the server . Through in-depth access to official documents and multiple rounds of measurement , We are right. TiDB The configuration parameters have been adjusted properly , So as to make full use of server resources , Make the server performance reach the ideal state .
The following table is a push right TiDB Description of adjustment of configuration parameters , For reference :
Focus on solving hot issues
Adjusting configuration parameters is only a basic step , We still need to fundamentally solve the problem that the server load pressure is concentrated on one machine . But how to solve it ? This requires us to have an in-depth understanding of TiDB The architecture of , as well as TiDB The internal principle of saving data in tables .
stay TiDB In the whole architecture of , Distributed data storage engine TiKV Server Responsible for storing data . When storing data ,TiKV Using range segmentation (range) Segment the data in a way , The smallest unit of segmentation is region. Every region There's a size limit ( The default upper limit is 96M), There will be multiple copies , Each set of copies , Become a raft group. Every raft group Zhongyou leader Be responsible for reading this block of data & Write .leader Will be automatically PD Components (Placement Driver, abbreviation “PD”, It is the management module of the whole cluster ) Uniform scheduling on different physical nodes , To divide reading and writing pressure equally , Load balancing .

TiDB Architecture diagram ( Image from TiDB Official website )
TiDB Each table will be assigned a TableID, Allocate one for each index IndexID, Assign one... To each row RowID( By default , If the table uses integer Primary Key, Then I can use Primary Key Value as RowID). The data of the same table will be stored in table ID A beginning with a prefix range in , The data will follow RowID The values are arranged in order . In the insert (insert) In the process of watch , If RowID The value of is increasing , The inserted row can only be appended at the end .
When Region After reaching a certain size, it will split , After the split, it can only be in the present range Append... At the end of the range , And always only in the same Region on insert operation , This forms a hot spot ( That is, the excessive load at a single point ), fall into TiDB The use of “ Anti pattern ”.
common increment The type self increment primary key is incremented in order , By default , When the primary key is an integer , The primary key value will be used as RowID , here RowID Also increasing in order , In large quantities insert The write hotspot of the table will be formed . meanwhile ,TiDB in RowID By default, it is also incremented in the order of self increment , When the primary key type is an integer , You will also encounter the problem of writing hotspots .
In the use of MySQL Database time , For convenience , We are all used to using self increasing ID As the primary key of the table . therefore , Take data from MySQL Migrate to TiDB after , The original table structure remains unchanged , It is still self increasing ID As the primary key of the table . This causes problems when importing data in batches TiDB Write hot issues , Lead to Region The division continues , Consume a lot of resources .
Regarding this , It's going on TiDB To optimize the , Let's start with table structure , Yes, self increasing ID Rebuild the table as the primary key , Delete auto increment ID, Use TiDB implicit _tidb_rowid Column as primary key , take
create table t (a int primary key auto_increment, b int);
Change it to :
create table t (a int, b int)SHARD_ROW_ID_BITS=4 PRE_SPLIT_REGIONS=2
By setting SHARD_ROW_ID_BITS, take RowID Break up and write multiple different Region, So as to alleviate the problem of writing hotspots .
Notice here ,SHARD_ROW_ID_BITS Value determines the number of slices :
- SHARD_ROW_ID_BITS = 0 Express 1 A shard
- SHARD_ROW_ID_BITS = 4 Express 16 A shard
- SHARD_ROW_ID_BITS = 6 Express 64 A shard
SHARD_ROW_ID_BITS Excessive value setting will cause RPC The number of requests is enlarged , increase CPU And network overhead , Here we will SHARD_ROW_ID_BITS Set to 4.
PRE_SPLIT_REGIONS It refers to the pre uniform segmentation after successful table creation , We set PRE_SPLIT_REGIONS=2, Pre uniform segmentation after successful table creation 2^(PRE_SPLIT_REGIONS) individual Region.
Summary of experience
· Self incrementing primary keys are not allowed for new tables in the future ,
Consider using a business primary key
· Add parameters SHARD_ROW_ID_BITS = 4 PRE_SPLIT_REGIONS=2
Besides , because TiDB Optimizer and MySQL There are some differences , The same SQL Statements in MySQL It can be executed normally in , And in the TiDB Slow execution in . We target specific slow SQL In depth analysis , And targeted index optimization , Good results .
Optimization results
Pass slowly SQL The query platform can see , optimized , Most imports are completed in seconds , Compared with the original tens of minutes , Thousands of times the performance improvement .

slow SQL Optimization results
meanwhile , The performance monitoring chart also shows , When the load is high , Several machines are high at the same time , Instead of raising alone , This shows that our optimization method is effective ,TiDB As a distributed database, its advantages can be truly reflected .

After optimization , Achieve server load balancing
summary
As a new distributed relational database ,TiDB Can be OLTP(Online Transactional Processing) and OLAP(Online Analytical Processing) The scenario provides a one-stop solution . A tweet not only uses TiDB Efficient query of massive data , At the same time, based on TiDB Real time data analysis 、 Exploration of insight .
More later “ Big data cost reduction and efficiency improvement ” Share the dry goods of , Please continue to lock in the technology to practice the official account. ( WeChat official account ID:getuitech)~
边栏推荐
- Three layer switching ②
- What are the advantages and disadvantages of data center agents?
- 2022 R2 mobile pressure vessel filling certificate examination and R2 mobile pressure vessel filling simulation examination questions
- Huawei cloud micro certification Huawei cloud computing service practice has been stable
- Portapack application development tutorial (XVII) nRF24L01 launch C
- Customize redistemplate tool class
- Iclr2022 | ontoprotein: protein pre training integrated with gene ontology knowledge
- All ceramic crowns - current market situation and future development trend
- ES6 deletes an attribute in all array objects through map, deconstruction and extension operators
- Which insurance products can the elderly buy?
猜你喜欢

ES6 deletes an attribute in all array objects through map, deconstruction and extension operators
Maximum entropy model

Yyds dry goods inventory it's not easy to say I love you | use the minimum web API to upload files

C import Xls data method summary II (save the uploaded file to the DataTable instance object)
What is the student party's Bluetooth headset recommendation? Student party easy to use Bluetooth headset recommended
MySQL deadly serial question 2 -- are you familiar with MySQL index?

Feign implements dynamic URL
Rearrangement of tag number of cadence OrCAD components and sequence number of schematic page
Solution to the problem that jsp language cannot be recognized in idea

How can enterprises optimize the best cost of cloud computing?
随机推荐
Writeup (real questions and analysis of ciscn over the years) of the preliminary competition of national college students' information security competition
0 basic learning C language - nixie tube dynamic scanning display
What is the student party's Bluetooth headset recommendation? Student party easy to use Bluetooth headset recommended
C library function int fprintf (file *stream, const char *format,...) Send formatted output to stream
Applet graduation project based on wechat selection voting applet graduation project opening report function reference
MySQL utilise la vue pour signaler les erreurs, Explicit / show ne peut pas être publié; Verrouillage des fichiers privés pour la table sous - jacente
Hamburg University of Technology (tuhh) | intelligent problem solving as integrated hierarchical reinforcement learning
51 single chip microcomputer timer 2 is used as serial port
Gnupg website
How to use AHAS to ensure the stability of Web services?
Jerry's modification setting status [chapter]
Who moved my code!
Cancer biopsy instruments and kits - market status and future development trends
A fan summed up so many interview questions for you. There is always one you need!
Ceramic metal crowns - current market situation and future development trend
Since the "epidemic", we have adhered to the "no closing" of data middle office services
Setting function of Jerry's watch management device [chapter]
C import Xls data method summary V (complete code)
2020-12-02 SSM advanced integration Shang Silicon Valley
After listening to the system clear message notification, Jerry informed the device side to delete the message [article]