当前位置:网站首页>Iclr2022 | ontoprotein: protein pre training integrated with gene ontology knowledge
Iclr2022 | ontoprotein: protein pre training integrated with gene ontology knowledge
2022-07-04 01:46:00 【Zhiyuan community】
Thesis title :OntoProtein: Protein Pretraining With Gene Ontology Embedding
The author of this article : Zhang Ningyu ( Zhejiang University )、 Bi Zhen ( Zhejiang University )、 Liang Xiaozhuan ( Zhejiang University )、 Cheng Siyuan ( Zhejiang University )、 Hong Haosen ( Zhejiang University )、 Deng Shumin ( Zhejiang University )、 Lian Jiachang ( Zhejiang University )、 Zhang Qiang ( Zhejiang University )、 Chen Huajun ( Zhejiang University )
Give a conference :ICLR 2022
Thesis link :https://arxiv.org/pdf/2201.11147.pdf
Code link :https://github.com/zjunlp/OntoProtein
Welcome to reprint , Reprint please indicate Source

One 、 introduction
Two 、 Protein pre training
Proteins are the basic macromolecules that control organisms and life itself , The study of proteins contributes to the understanding of human health and the development of disease therapy . Proteins contain primary structures , Secondary structure and tertiary structure , The primary structure has similar sequence characteristics with language . Inspired by the pre training model of natural language processing , Many protein pre training models and tools have been proposed , Include MSA Transformer[1]、ProtTrans[2]、 Enlightenment · Wensu [3]、 Baidu PaddleHelix etc. . Large scale unsupervised protein pre training can even acquire a certain degree of protein structure and function from the training corpus . However , Proteins are essentially different from natural language texts , It contains a lot of knowledge unique to Biology , It is difficult to learn directly through the pre training target , And it will be affected by the data distribution. The protein expression of low-frequency long tail . To solve these problems , We use the vast amount of biological knowledge about protein structure and function accumulated by human scientists , A protein pre training method based on knowledge map is proposed for the first time . The following first introduces the construction method of knowledge map .
3、 ... and 、 Gene knowledge map
By accessing the public gene ontology knowledge map “Gene Ontology( abbreviation Go)”, And compare it with that from Swiss-Prot Alignment of protein sequences in the database , To build a knowledge map for pre training ProteinKG25, The knowledge map contains 4,990,097 A triad , among 4,879,951 A protein -Go Triple of ,110,146 individual Go-Go A triple , And has been fully opened for community use . As shown in the figure below , be based on “ Structure determines function ” Thought , If you explicitly tell the model what kind of structure has what kind of function in the process of protein pre training , Obviously, it can promote the prediction of protein function 、 The effect of tasks such as protein interaction prediction .
Four 、 Protein pre training integrated into gene knowledge map :OntoProtein
Based on the constructed knowledge map , We designed a special protein pre training model OntoProtein. Note that there are two different sequences in the pre training input : Protein sequence and description of protein function 、 Text description information of biological process, etc . therefore , We use two different encoders . For protein sequences, we use the existing protein pre training model ProtBert Encoding , For text sequences, we use BERT Encoding . In order to better pre train and fuse triple knowledge information , We have adopted two optimization objectives . The first is the traditional mask language model , We pass the random Mask One of the sequences Token And predict the Token. The second is the triple knowledge enhancement goal , We implant biological triple knowledge by embedding learning similar to knowledge map , As shown in the following formula :
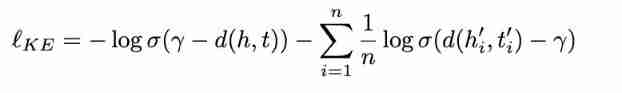
![]()
Notice that the factual knowledge here is divided into two different triples , Namely Go-Go And protein -Go, Therefore, we propose a knowledge enhanced negative sampling method , In order to obtain more representative negative samples and improve the effect of pre training , The sampling method is as follows :

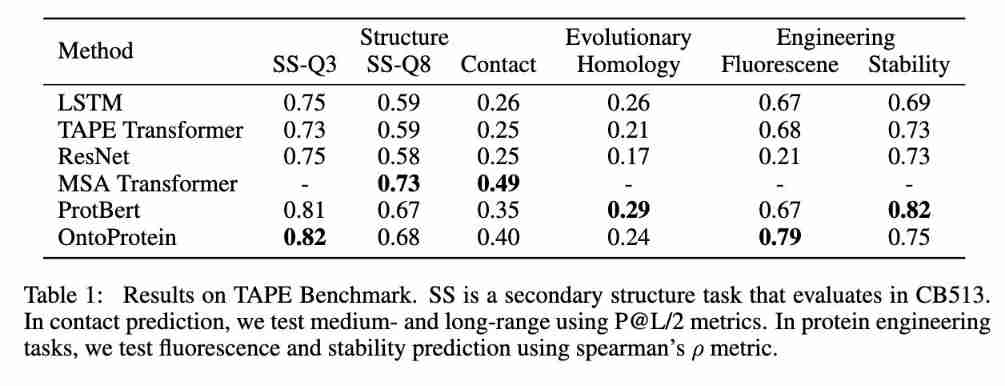
5、 ... and 、 experimental analysis

6、 ... and 、 Summary and prospect
The current booming AI for Science It is promoting the deep integration of Kepler paradigm driven by data and Newton paradigm driven by first principles . be based on “ Data and knowledge two wheel drive ” The academic thought of , In this paper, we propose a protein pre training method based on knowledge map for the first time OntoProtein, The effect of the model is verified in several downstream tasks . some time , We will maintain OntoProtein For more scholars to use , It is planned to explore the knowledge map enhancement pre training method integrating homologous sequence alignment to achieve better performance .
边栏推荐
- Ceramic metal crowns - current market situation and future development trend
- How programmers find girlfriends through blind dates
- Summary of JWT related knowledge
- 51 single chip microcomputer timer 2 is used as serial port
- Small program graduation project based on wechat e-book small program graduation project opening report function reference
- 【.NET+MQTT】. Net6 environment to achieve mqtt communication, as well as bilateral message subscription and publishing code demonstration of server and client
- mysql使用視圖報錯,EXPLAIN/SHOW can not be issued; lacking privileges for underlying table
- Maximum entropy model
- Development of user-defined navigation bar in uniapp
- The contact data on Jerry's management device supports reading and updating operations [articles]
猜你喜欢

Lightweight Pyramid Networks for Image Deraining
TP5 automatic registration hook mechanism hook extension, with a complete case
![[leetcode daily question] a single element in an ordered array](/img/3a/2b465589b70cd6aeec08e79fcf40d4.jpg)
[leetcode daily question] a single element in an ordered array

Applet graduation project based on wechat selection voting applet graduation project opening report function reference

Huawei cloud micro certification Huawei cloud computing service practice has been stable

Do you know the eight signs of a team becoming agile?
LeetCode 168. Detailed explanation of Excel list name
2020-12-02 SSM advanced integration Shang Silicon Valley

Huawei BFD and NQA

Three layer switching ①
随机推荐
Pyrethroid pesticide intermediates - market status and future development trend
Reading notes - learn to write: what is writing?
Summary of common tools and technical points of PMP examination
1189. Maximum number of "balloons"
MySQL statement learning record
Hbuilder link Xiaoyao simulator
How to delete MySQL components using xshell7?
All metal crowns - current market situation and future development trend
SRCNN:Learning a Deep Convolutional Network for Image Super-Resolution
Maximum entropy model
Pratique technique | analyse et solution des défaillances en ligne (Partie 1)
Why can't it run (unresolved)
Portable two-way radio equipment - current market situation and future development trend
MPLS③
Lightweight Pyramid Networks for Image Deraining
Logical operator, displacement operator
Small program graduation project based on wechat examination small program graduation project opening report function reference
A fan summed up so many interview questions for you. There is always one you need!
Related configuration commands of Huawei rip
2022 electrician (elementary) examination question bank and electrician (elementary) simulation examination question bank