当前位置:网站首页>10 tf.data
10 tf.data
2022-06-26 15:30:00 【X1996_】
学到这一节,内容整理的很乱
tf.data主要是tensorflow里面数据输入
Data类以及相关操作还有TFRecord文件的保存和读取
所有代码在notebook中编写的



数据处理




 代码
代码
Dataset类
Dataset类读取numpy数据
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
mnist = np.load("mnist.npz")
x_train, y_train = mnist['x_train'],mnist['y_train']
# 最后面增加一维
x_train = np.expand_dims(x_train, axis=-1)
mnist_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
Pandas数据读取
import pandas as pd
df = pd.read_csv('heart.csv')
df['thal'] = pd.Categorical(df['thal'])
df['thal'] = df.thal.cat.codes
target = df.pop('target')
dataset = tf.data.Dataset.from_tensor_slices((df.values, target.values))
thal,target为文件中,感觉相当于键名吧
从Python generator构建数据管道
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
flowers = './flower_photos/flower_photos/'
def Gen():
gen = img_gen.flow_from_directory(flowers)
for (x,y) in gen:
yield (x,y)
ds = tf.data.Dataset.from_generator(
Gen,
output_types=(tf.float32, tf.float32)
# output_shapes=([32,256,256,3], [32,5])
)
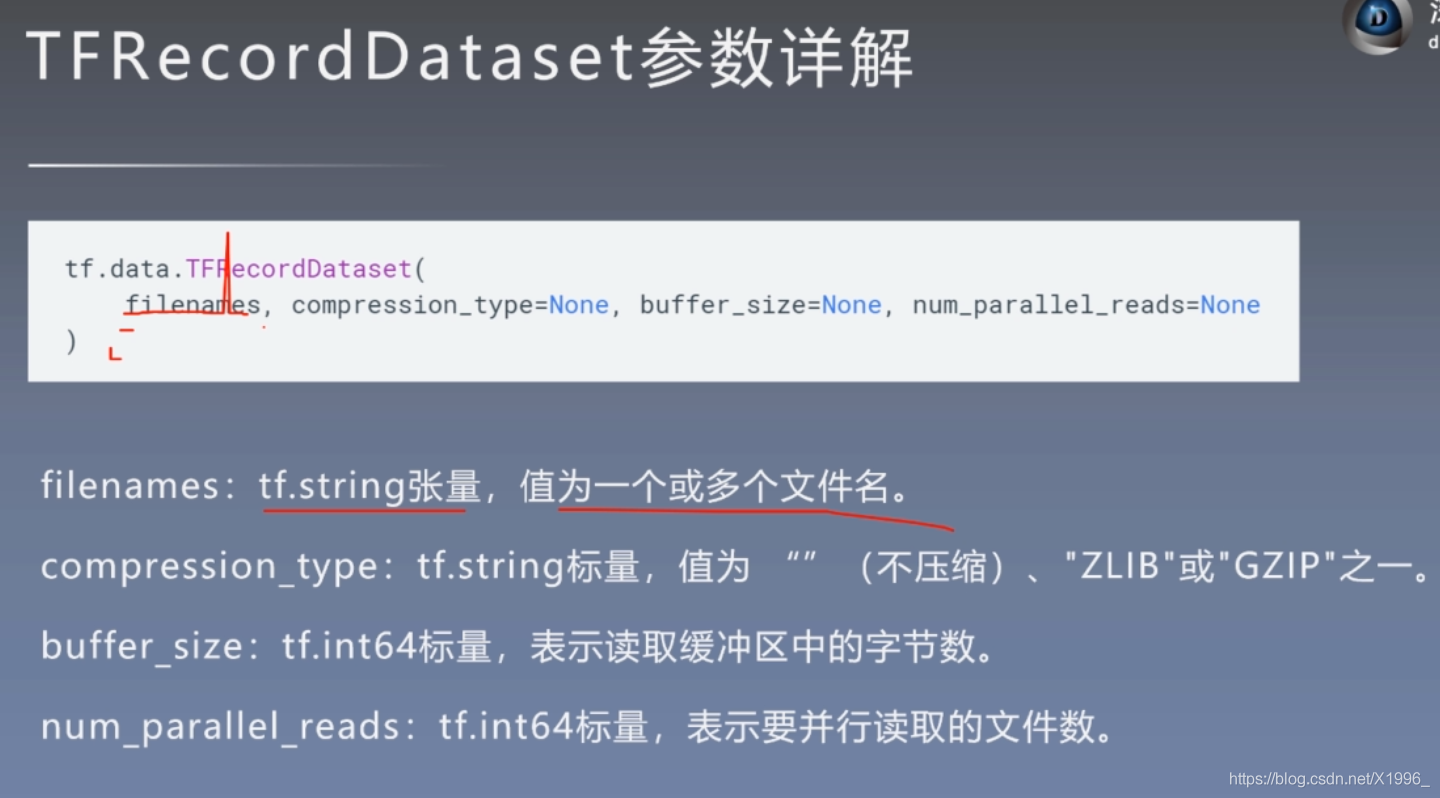
TFRecordDataset类
feature_description = {
# 定义Feature结构,告诉解码器每个Feature的类型是什么
'image': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.int64),
}
def _parse_example(example_string): # 将 TFRecord 文件中的每一个序列化的 tf.train.Example 解码
feature_dict = tf.io.parse_single_example(example_string, feature_description)
feature_dict['image'] = tf.io.decode_jpeg(feature_dict['image']) # 解码JPEG图片
feature_dict['image'] = tf.image.resize(feature_dict['image'], [256, 256]) / 255.0
return feature_dict['image'], feature_dict['label']
batch_size = 32
train_dataset = tf.data.TFRecordDataset("sub_train.tfrecords") # 读取 TFRecord 文件
# filename label
train_dataset = train_dataset.map(_parse_example)
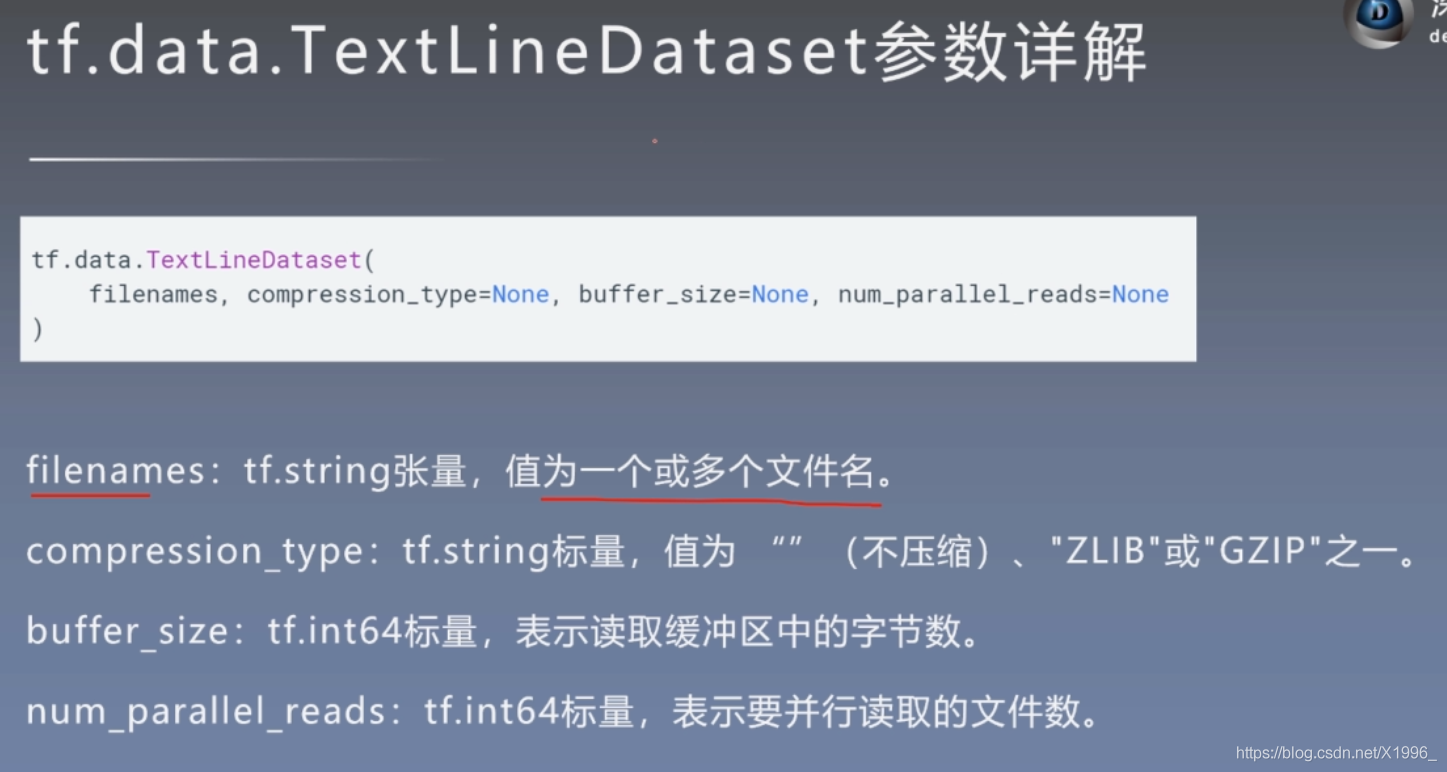
TextLineDataset类
titanic_lines = tf.data.TextLineDataset(['train.csv','eval.csv'])
def data_func(line):
line = tf.strings.split(line, sep = ",")
return line
titanic_data = titanic_lines.skip(1).map(data_func)
二 Dataset类相关操作
flat_map
zip
concatenate


 从多个文件中读取
从多个文件中读取




 代码
代码
flat_map
a = tf.data.Dataset.range(1, 6) # ==> [ 1, 2, 3, 4, 5 ]
# NOTE: New lines indicate "block" boundaries.
b=a.flat_map(lambda x: tf.data.Dataset.from_tensors(x).repeat(6))
zip
a = tf.data.Dataset.range(1, 4) # ==> [ 1, 2, 3 ]
b = tf.data.Dataset.range(4, 7) # ==> [ 4, 5, 6 ]
ds = tf.data.Dataset.zip((a, b))
concatenate
# 连接
a = tf.data.Dataset.range(1, 4) # ==> [ 1, 2, 3 ]
b = tf.data.Dataset.range(4, 7) # ==> [ 4, 5, 6 ]
ds = a.concatenate(b)
性能优化
prefetch方法
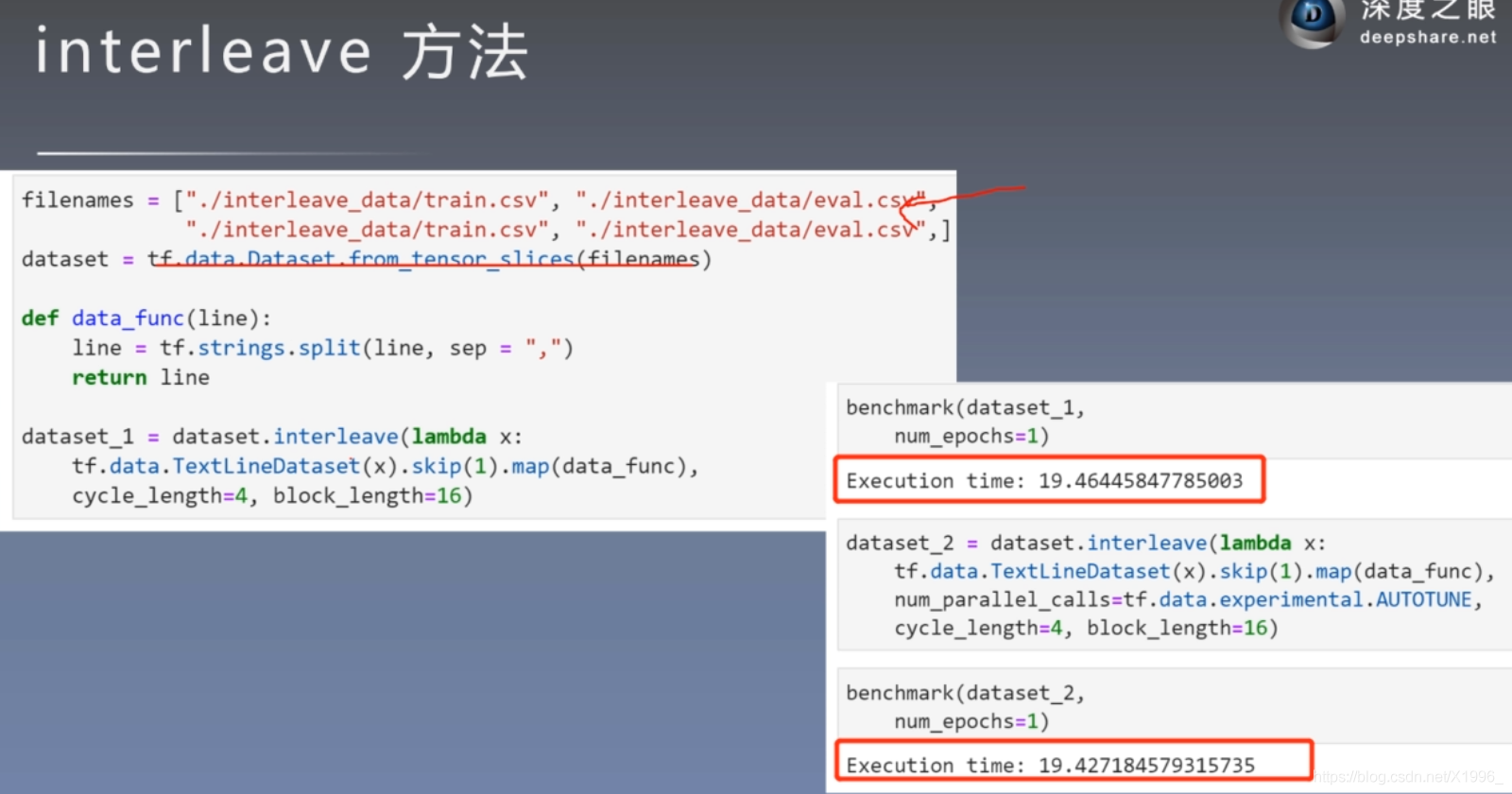
interleave 方法
map方法
cache方法
不太懂,后面有要用到·懂了后再来补吧
哎,比蔡文姬还菜



一个猫狗大战实例
import tensorflow as tf
import os
# 定义图片路径
data_dir = './datasets'
train_cats_dir = data_dir + '/train/cats/'
train_dogs_dir = data_dir + '/train/dogs/'
test_cats_dir = data_dir + '/valid/cats/'
test_dogs_dir = data_dir + '/valid/dogs/'
# os.listdir(train_cats_dir) 得到该文件夹下的所有文件名
train_cat_filenames = tf.constant([train_cats_dir + filename for filename in os.listdir(train_cats_dir)])
train_dog_filenames = tf.constant([train_dogs_dir + filename for filename in os.listdir(train_dogs_dir)])
train_filenames = tf.concat([train_cat_filenames, train_dog_filenames], axis=-1)
# cat 0 dog :1
train_labels = tf.concat([
tf.zeros(train_cat_filenames.shape, dtype=tf.int32),
tf.ones(train_dog_filenames.shape, dtype=tf.int32)],
axis=-1)
def _decode_and_resize(filename, label):
image_string = tf.io.read_file(filename) # 读取原始文件
image_decoded = tf.image.decode_jpeg(image_string) # 解码JPEG图片
image_resized = tf.image.resize(image_decoded, [256, 256]) / 255.0
return image_resized, label
#构建训练集
def _decode_and_resize(filename, label):
image_string = tf.io.read_file(filename) # 读取原始文件
image_decoded = tf.image.decode_jpeg(image_string) # 解码JPEG图片
image_resized = tf.image.resize(image_decoded, [256, 256]) / 255.0
return image_resized, label
batch_size = 32
train_dataset = tf.data.Dataset.from_tensor_slices((train_filenames, train_labels))
#名字
train_dataset = train_dataset.map(
map_func=_decode_and_resize,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
# 取出前buffer_size个数据放入buffer,并从其中随机采样,采样后的数据用后续数据替换
train_dataset = train_dataset.shuffle(buffer_size=23000)
train_dataset = train_dataset.repeat(count=1)
train_dataset = train_dataset.batch(batch_size)
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)
# 构建测试数据集
test_cat_filenames = tf.constant([test_cats_dir + filename for filename in os.listdir(test_cats_dir)])
test_dog_filenames = tf.constant([test_dogs_dir + filename for filename in os.listdir(test_dogs_dir)])
test_filenames = tf.concat([test_cat_filenames, test_dog_filenames], axis=-1)
test_labels = tf.concat([
tf.zeros(test_cat_filenames.shape, dtype=tf.int32),
tf.ones(test_dog_filenames.shape, dtype=tf.int32)],
axis=-1)
test_dataset = tf.data.Dataset.from_tensor_slices((test_filenames, test_labels))
test_dataset = test_dataset.map(_decode_and_resize)
test_dataset = test_dataset.batch(batch_size)
class CNNModel(tf.keras.models.Model):
def __init__(self):
super(CNNModel, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(32, 3, activation='relu')
self.maxpool1 = tf.keras.layers.MaxPooling2D()
self.conv2 = tf.keras.layers.Conv2D(32, 5, activation='relu')
self.maxpool2 = tf.keras.layers.MaxPooling2D()
self.flatten = tf.keras.layers.Flatten()
self.d1 = tf.keras.layers.Dense(64, activation='relu')
self.d2 = tf.keras.layers.Dense(2, activation='softmax') #sigmoid 和softmax
def call(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.flatten(x)
x = self.d1(x)
x = self.d2(x)
return x
# softmax CategoricalCrossentropy
#sigmoid tf.keras.losses.BinaryCrossentropy
learning_rate = 0.001
model = CNNModel()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
#label 没有one-hot
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, predictions)
def test_step(images, labels):
predictions = model(images)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)
EPOCHS=10
for epoch in range(EPOCHS):
# 在下一个epoch开始时,重置评估指标
train_loss.reset_states()
train_accuracy.reset_states()
test_loss.reset_states()
test_accuracy.reset_states()
for images, labels in train_dataset:
train_step(images, labels)
for test_images, test_labels in test_dataset:
test_step(test_images, test_labels)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print(template.format(epoch + 1,
train_loss.result(),
train_accuracy.result() * 100,
test_loss.result(),
test_accuracy.result() * 100
))
TFRecord保存 读取






 代码
代码
import tensorflow as tf
import os
data_dir = './datasets'
train_cats_dir = data_dir + '/train/cats/'
train_dogs_dir = data_dir + '/train/dogs/'
train_tfrecord_file = data_dir + '/train/train.tfrecords'
test_cats_dir = data_dir + '/valid/cats/'
test_dogs_dir = data_dir + '/valid/dogs/'
test_tfrecord_file = data_dir + '/valid/test.tfrecords'
train_cat_filenames = [train_cats_dir + filename for filename in os.listdir(train_cats_dir)]
train_dog_filenames = [train_dogs_dir + filename for filename in os.listdir(train_dogs_dir)]
train_filenames = train_cat_filenames + train_dog_filenames
train_labels = [0] * len(train_cat_filenames) + [1] * len(train_dog_filenames) # 将 cat 类的标签设为0,dog 类的标签设为1
with tf.io.TFRecordWriter(train_tfrecord_file) as writer:
for filename, label in zip(train_filenames, train_labels):
image = open(filename, 'rb').read() # 读取数据集图片到内存,image 为一个 Byte 类型的字符串
feature = {
# 建立 tf.train.Feature 字典
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])), # 图片是一个 Bytes 对象
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[label])) # 标签是一个 Int 对象
}
example = tf.train.Example(features=tf.train.Features(feature=feature)) # 通过字典建立 Example
writer.write(example.SerializeToString()) # 将Example序列化并写入 TFRecord 文件
#### 测试集
test_cat_filenames = [test_cats_dir + filename for filename in os.listdir(test_cats_dir)]
test_dog_filenames = [test_dogs_dir + filename for filename in os.listdir(test_dogs_dir)]
test_filenames = test_cat_filenames + test_dog_filenames
test_labels = [0] * len(test_cat_filenames) + [1] * len(test_dog_filenames) # 将 cat 类的标签设为0,dog 类的标签设为1
with tf.io.TFRecordWriter(test_tfrecord_file) as writer:
for filename, label in zip(test_filenames, test_labels):
image = open(filename, 'rb').read() # 读取数据集图片到内存,image 为一个 Byte 类型的字符串
feature = {
# 建立 tf.train.Feature 字典
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])), # 图片是一个 Bytes 对象
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[label])) # 标签是一个 Int 对象
}
example = tf.train.Example(features=tf.train.Features(feature=feature)) # 通过字典建立 Example
serialized = example.SerializeToString() #将Example序列化
writer.write(serialized) # 写入 TFRecord 文件
# 读取TFREcoed文件
train_dataset = tf.data.TFRecordDataset(train_tfrecord_file) # 读取 TFRecord 文件
feature_description = {
# 定义Feature结构,告诉解码器每个Feature的类型是什么
'image': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.int64),
}
def _parse_example(example_string): # 将 TFRecord 文件中的每一个序列化的 tf.train.Example 解码
feature_dict = tf.io.parse_single_example(example_string, feature_description)
feature_dict['image'] = tf.io.decode_jpeg(feature_dict['image']) # 解码JPEG图片
feature_dict['image'] = tf.image.resize(feature_dict['image'], [256, 256]) / 255.0
return feature_dict['image'], feature_dict['label']
train_dataset = train_dataset.map(_parse_example)
batch_size = 32
train_dataset = train_dataset.shuffle(buffer_size=23000)
train_dataset = train_dataset.batch(batch_size)
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)
test_dataset = tf.data.TFRecordDataset(test_tfrecord_file) # 读取 TFRecord 文件
test_dataset = test_dataset.map(_parse_example)
test_dataset = test_dataset.batch(batch_size)
class CNNModel(tf.keras.models.Model):
def __init__(self):
super(CNNModel, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(32, 3, activation='relu')
self.maxpool1 = tf.keras.layers.MaxPooling2D()
self.conv2 = tf.keras.layers.Conv2D(32, 5, activation='relu')
self.maxpool2 = tf.keras.layers.MaxPooling2D()
self.flatten = tf.keras.layers.Flatten()
self.d1 = tf.keras.layers.Dense(64, activation='relu')
self.d2 = tf.keras.layers.Dense(2, activation='softmax')
def call(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.flatten(x)
x = self.d1(x)
x = self.d2(x)
return x
learning_rate = 0.001
model = CNNModel()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
#batch
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss) #update
train_accuracy(labels, predictions)#update
@tf.function
def test_step(images, labels):
predictions = model(images)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)
EPOCHS=10
for epoch in range(EPOCHS):
# 在下一个epoch开始时,重置评估指标
train_loss.reset_states()
train_accuracy.reset_states()
test_loss.reset_states()
test_accuracy.reset_states()
for images, labels in train_dataset:
train_step(images, labels) #mini-batch 更新
for test_images, test_labels in test_dataset:
test_step(test_images, test_labels)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print(template.format(epoch + 1,
train_loss.result(),
train_accuracy.result() * 100,
test_loss.result(),
test_accuracy.result() * 100
))
边栏推荐
- 【leetcode】701. Insert operation in binary search tree
- 【C语言练习——打印空心上三角及其变形】
- selenium将元素保存为图片
- Audio and video learning (II) -- frame rate, code stream and resolution
- Is it safe to open a stock account through the account opening link of the broker manager? Or is it safe to open an account in a securities company?
- How to handle 2gcsv files that cannot be opened? Use byzer
- CNN优化trick
- 安全Json协议
- JS simple deepcopy (Introduction recursion)
- IDEA本地代理后,无法下载插件
猜你喜欢

NFT 项目的开发、部署、上线的流程(2)

Notes on brushing questions (19) -- binary tree: modification and construction of binary search tree

Solana capacity expansion mechanism analysis (1): an extreme attempt to sacrifice availability for efficiency | catchervc research

# 粒子滤波 PF——三维匀速运动CV目标跟踪(粒子滤波VS扩展卡尔曼滤波)

AbortController的使用

NFT Platform Security Guide (1)

Reflection modification final

NFT 项目的开发、部署、上线的流程(1)

「干货」NFT 上中下游产业链全景分析

How to configure and use the new single line lidar
随机推荐
NFT 项目的开发、部署、上线的流程(1)
2022 Beijing Shijingshan District specializes in the application process for special new small and medium-sized enterprises, with a subsidy of 100000-200000 yuan
How to configure and use the new single line lidar
/etc/profile、/etc/bashrc、~/. Bashrc differences
【C语言练习——打印空心上三角及其变形】
How do I open an account on my mobile phone? Is online account opening safe?
svg上升的彩色气泡动画
反射修改final
[CEPH] cephfs internal implementation (II): example -- undigested
[CEPH] Lock Notes of cephfs
PCIe Capabilities List
Solana capacity expansion mechanism analysis (2): an extreme attempt to sacrifice availability for efficiency | catchervc research
[tcapulusdb knowledge base] tcapulusdb doc acceptance - transaction execution introduction
JVM笔记
Application of ansible automation
Reflection modification final
如何配置使用新的单线激光雷达
Particle filter PF -- Application in maneuvering target tracking (particle filter vs extended Kalman filter)
音视频学习(三)——sip协议
Transaction input data of Ethereum