当前位置:网站首页>MySQL -- deduction of index storage model
MySQL -- deduction of index storage model
2022-07-01 22:54:00 【Xiao Xian.】
Recommended links :
summary ——》【Java】
summary ——》【Mysql】
summary ——》【Spring】
summary ——》【SpringBoot】
Mysql——》 Index storage model deduction
data structure
Data structure visualization :Data Structure Visualizations
One 、 Two points search
Tiktok is very popular in guessing numbers , Guess you are 100 Within several , Finally, by constantly narrowing the scope , Lock in the numbers .
This is the idea of binary search , Also called half search , every time , We've all halved the number of candidates .
If the data has been sequenced , This way is more efficient .
Two points search = Binary search = The data range of each query is reduced by half
1) Consider a data structure that uses an ordered array as an index
advantage : The efficiency of equivalent query and comparison query is very high
shortcoming : There will be a problem when updating the data , It's possible to move a lot of data ( change index)
summary : Only suitable for storing static data
2) Consider the data structure with linked list as index
advantage : Support frequent insertion / Modifying data
shortcoming : Single chain list , Its search efficiency is not high enough
Q: Is there a linked list that can be used for binary search ?
A: To solve this problem ,BST(Binary Search Tree) That is to say, the binary search tree is born .
Two 、 Binary search tree (BST)
Reference link :Binary Search Trees
BST = Binary Search Trees = Binary search tree
1、 characteristic
All nodes in the left subtree are smaller than the parent nodes , All nodes in the right subtree are larger than the parent nodes .
After projection to the plane , It's an ordered linear table .
Example : Insert... In order 14、7、5、12、17、25
2、 advantage
1) Quick search
2) Quick insert
3、 shortcoming
The search time is related to the depth of the tree , In the worst case, time complexity will degenerate into O(n).
Example : Insert... In order 5、7、12、14、17、 25
result : Become a list ( It's also called ” Oblique tree “), This situation does not achieve the purpose of speeding up the search , It is as efficient as sequential search
reason : The depth difference between the left and right subtrees is too large , The left subtree of this tree has no nodes at all , That is, it's not balanced 
Q: Is there a difference in the depth between the left and right subtrees that is not so big , A more balanced tree ?
A: This is the balanced binary tree , be called Balanced binary search trees, perhaps AVL Trees
3、 ... and 、 Balanced binary trees (AVL Trees)
Reference link :AVL Trees (Balanced binary search trees)
AVL : It is the abbreviation of the person who invented this data structure
AVL Trees = Balanced binary search trees = Balanced binary trees
Definition : The absolute value of the depth difference between left and right subtrees cannot exceed 1
1、 characteristic
To keep the balance ,AVL The tree performs a series of calculation and adjustment operations when inserting and updating data .
When the left depth and the right depth exceed 1 when , Can rotate left / Right hand
Example : Insert... In order 5、7、12、14、17、15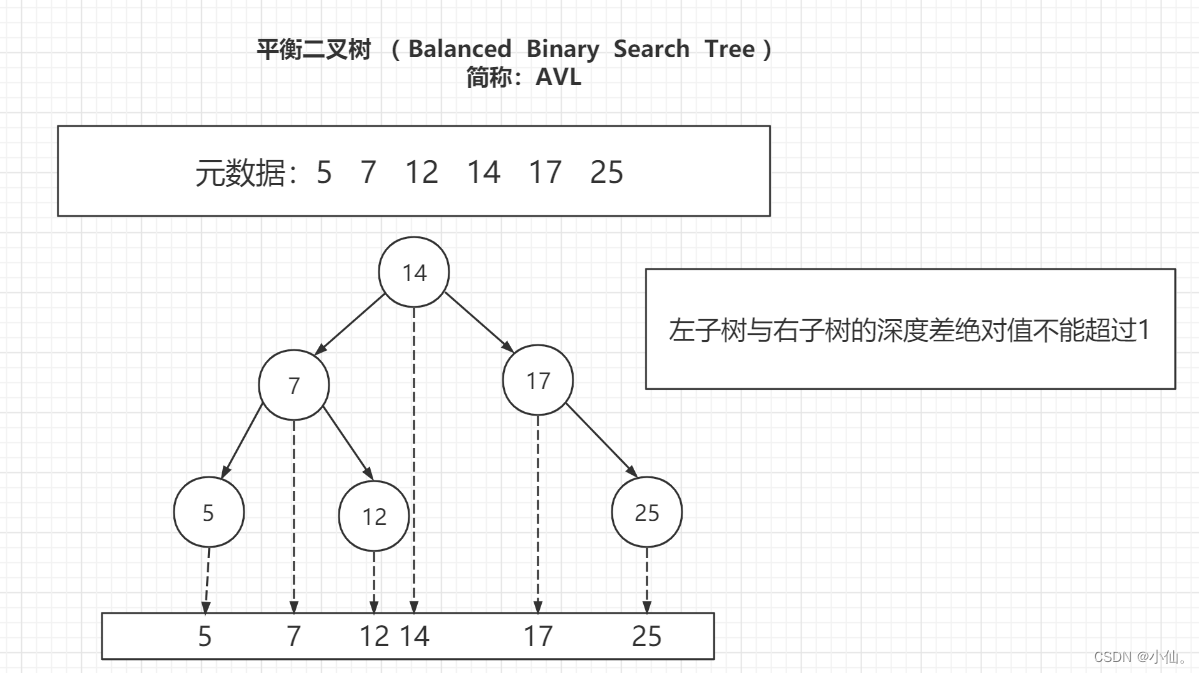
1) left-handed
Example : Insert... In order 5,7,14
The process : When we insert 5、7 after , If you follow the definition of binary search tree ,14 It must be in 7 On the right , This
Time root node 1 The right node depth of becomes 2, But the depth of the left node is 0, Because it has no children , So it will violate the balance
The definition of binary tree . What should I do then ? Because it's the right node next to the right node , Right - Right side , So at this time we have to put 7 Lift up , This operation is called left-handed .
2) Right hand
Example : Insert... In order 14,7,5
The process : Left left type , There will be a right-handed operation , hold 7 Lift up 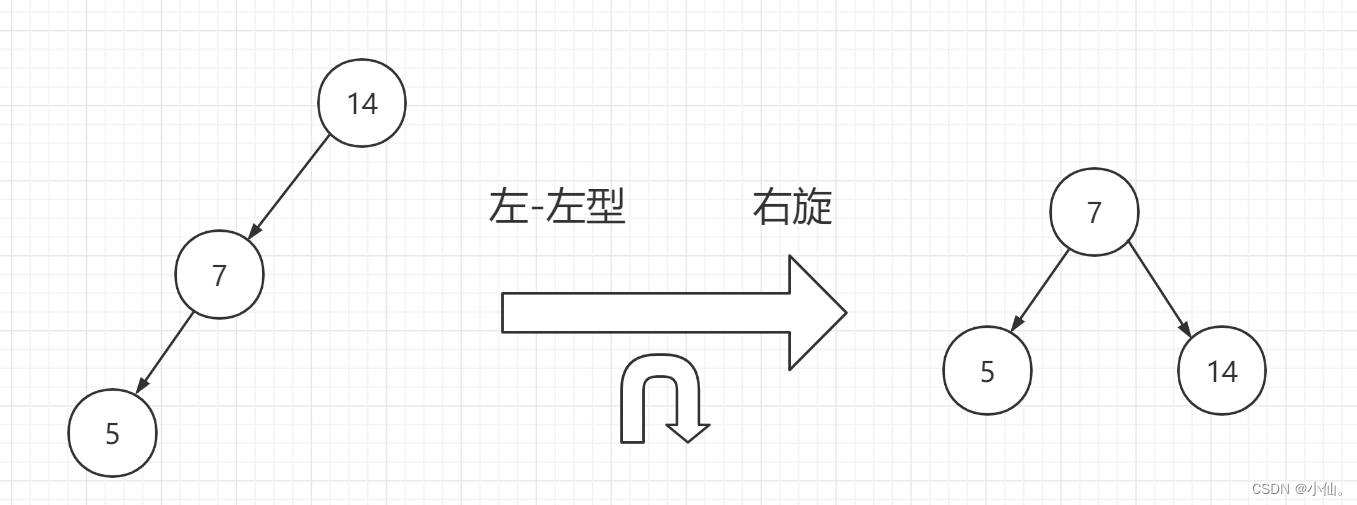
2、 The content stored in each node
In balanced binary tree , A node , Its size is a fixed unit , What should be stored as an index ?
1) Key value of index
Let's say we have id An index is created above , I am using where id =1 When querying the conditions of , Will find in the index id The key value of .
2) The disk address of the data
Because the function of index is to find the address where the data is stored .
3) References of left and right child nodes
Because it's a binary tree , It must also have references to left and right child nodes , So we can find the next node .
3、 How to query data with balanced binary tree as index
First , about InnoDB Come on , Index data , It's on the hard disk .
When we use tree structure to store index , Because if you get a piece of data, you have to Server Layer comparison is not required data , Such as
If not, read the disk again . Access to a node is about to happen once between the disk I/O.InnoDB The smallest unit to operate a disk is one page ( Or a disk block ), Size is 16K(16384 byte ). The node of a tree is 16K Size .
If we only have one key value in one node + data + quote , For example, the field of reshaping , It may only take a dozen or dozens of words
section , It is far from 16384 Byte capacity , So access a tree node , Do it once. IO When , Wasted a lot of space
between .
So if each node stores too little data , Find the data we need from the index , It's about accessing more nodes , signify
There will be too many interactions with the disk , The more time it takes .
Like the picture above , We have... In one watch 6 Data , When we look up id=66 When , To query two child nodes , Just
Need to interact with disk 3 Time , If we have millions of data ? This time is more difficult to estimate .
Q: How to solve the problem of many interactions ?
A: Let each node store more data , Greatly reduce the depth of the tree . Our trees have changed from their original tall and thin appearance , It's like a little fat . This is the time , Our tree is no longer a binary , It's more than a fork , Or multiplex .
Four 、 Multiway balanced search tree (B Trees)
Reference link :B Trees
B Tree = Balanced Tree = Multiway balanced search tree
1、 characteristic
1) Number of bifurcations ( Number of routes ) Always more than key words 1
2) Store key values in branch nodes and leaf nodes 、 Data address 、 Node reference
Example : For example, the tree we drew , Each node stores 2 Key words , Then there will be 3 A pointer points to 3 Child node .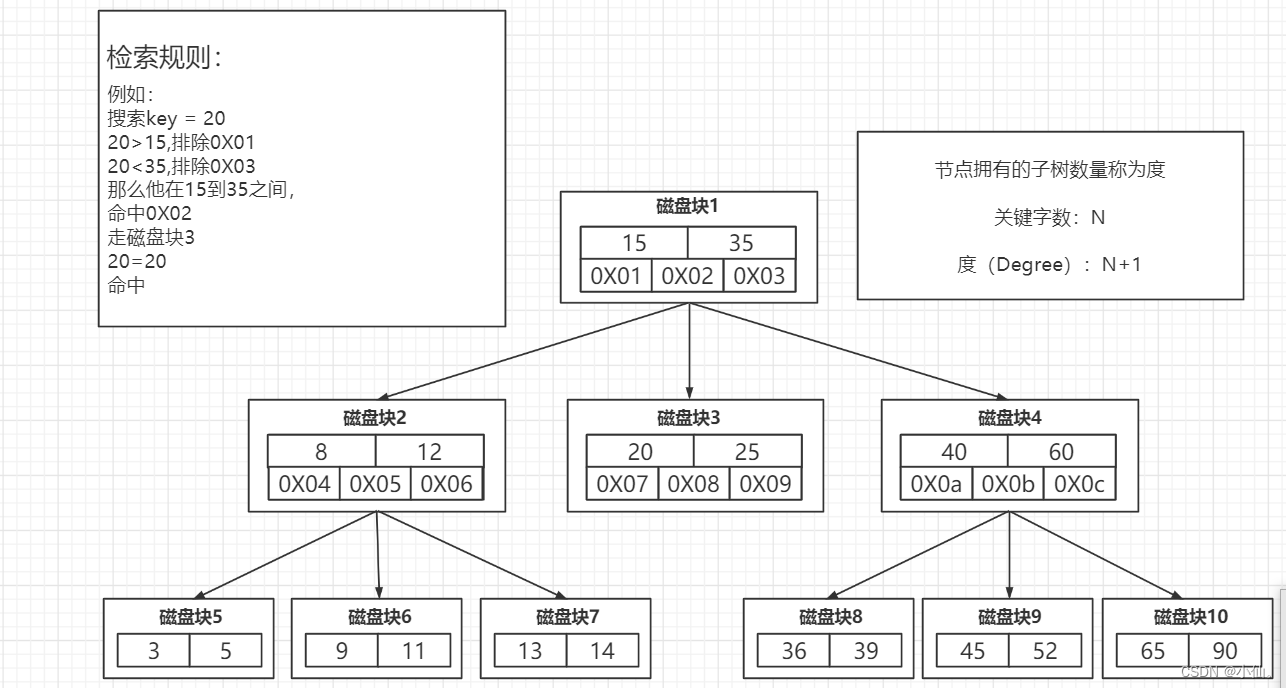
1) split
such as Max Degree( Number of routes / Degrees ) yes 3 When , We insert data 1、2、3, In the insert 3 When , It should have been in the
A disk block , But if a node has 3 When there are two keywords , It means that there is 4 A pointer to the , The child node becomes 4 road , So this
It's time to split ( In fact, that is B+Tree). Put the data in the middle 2 Lift up , hold 1 and 3 become 2 Child nodes of .
2) Merge
If you delete a node , There will be opposite merging operations .
Notice here's division and merger , Follow AVL The left and right turns of the tree are different .
Q: Why not build indexes on frequently updated columns ?
A: There will be a lot of index structure adjustments when updating the index .
Splitting and merging of nodes , In fact, that is InnoDB page (page) Division and amalgamation of .
5、 ... and 、 Enhanced multiway balanced search tree (B+Tree)
Q:B Tree The efficiency of , Why? MySQL Also right B Tree Make improvements , In the end B+Tree Well ?
A:B+Tree It solves more problems than B Tree More comprehensive
1、 Storage structure
Search keywords will not return directly , It will go to the leaf node of the last layer . For example, we search id=28, Although directly on the first floor Hit , But the data address is on the leaf node , So I'm going to keep searching , All the way to the leaf node .
2、 characteristic
1、 The number of keywords is equal to the number of paths ;
2、B+Tree No data will be stored in the root and branch nodes of , Only leaf nodes store data .
3、B+Tree Each leaf node of the adds a pointer to the adjacent leaf node , Its last data points to the first data of the next leaf node , The structure of an ordered list .
3、 advantage
1) It is B Tree Variants ,B Tree Problems that can be solved , It can solve .
1、 Every time Nodes store more keywords ;2、 More routes
2) Sweep Library 、 The ability to scan the watch is stronger
If we want to scan the whole table , You just need to traverse the leaf nodes , You don't need to traverse the whole tree B+Tree Get all the data
3)B+Tree The read and write ability of the disk is relative to B Tree To be stronger
The root node and the branch node do not save the data area , So a node You can save more keywords , More keywords for one disk load
4) Better sorting
Because the leaf node has a pointer to the next data area , The data forms a linked list
5) More stable efficiency
B+Tree Always get the data at the leaf node , therefore IO The number is stable
边栏推荐
- MySQL5.7 设置密码策略(等保三级密码改造)
- Two schemes of transforming the heat map of human posture estimation into coordinate points
- Vsphere+ and vsan+ are coming! VMware hybrid cloud focus: native, fast migration, mixed load
- 隐藏用户的创建和使用
- 转--拿来即用:分享一个检查内存泄漏的小工具
- C#/VB. Net to add text / image watermarks to PDF documents
- Use and function of spark analyze command map join broadcast join
- Deadlock handling strategies - prevent deadlock, avoid deadlock, detect and remove deadlock
- 元宇宙可能成为互联网发展的新方向
- 转--利用C语言中的setjmp和longjmp,来实现异常捕获和协程
猜你喜欢
C#/VB. Net to add text / image watermarks to PDF documents

Sogou wechat app reverse (II) so layer

Map container

Stimulate new kinetic energy and promote digital economy in multiple places

SAP UI5 应用开发教程之一百零四 - SAP UI5 表格控件的支持复选(Multi-Select)以及如何用代码一次选中多个表格行项目

Réimpression de l'article csdn
转载csdn文章操作

447-哔哩哔哩面经1
Delete AWS bound credit card account
Turn -- the underlying debugging principle of GDB is so simple
随机推荐
Quantifiers of regular series
Sogou wechat app reverse (II) so layer
Appium自动化测试基础 — APPium安装(一)
FFMpeg学习笔记
人体姿态估计的热图变成坐标点的两种方案
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received
Resttemplate remote call tool class
Kubernetes create service access pod
Understanding of transactions in MySQL
3DE resources have nothing or nothing wrong
搜狗微信APP逆向(二)so层
Understanding of indexes in MySQL
Mysql5.7 set password policy (etc. three-level password transformation)
Little red book scheme jumps to the specified page
vSphere+、vSAN+来了!VMware 混合云聚焦:原生、快速迁移、混合负载
El input text field word limit, beyond which the display turns red and input is prohibited
切面条 C语言
nn. Parameter] pytoch feature fusion adaptive weight setting (learnable weight use)
第三方验收测试有什么好处?专业第三方软件测试机构推荐
twenty million two hundred and twenty thousand seven hundred and one