当前位置:网站首页>Migrate data from Mysql to tidb from a small amount of data
Migrate data from Mysql to tidb from a small amount of data
2022-07-03 06:05:00 【Tianxiang shop】
This document describes how to use TiDB DM ( hereinafter referred to as DM) In full quantity + Incremental mode data to TiDB. In this article “ Small data volume ” Usually refers to TiB Below grade .
generally speaking , Receive information such as the number of table structure indexes 、 Hardware and network environment impact , Migration rate at 30~50GB/h Unequal . Use TiDB DM The migration process is shown in the following figure .

Prerequisite
The first 1 Step : create data source
First , newly build source1.yaml file , Write the following :
# Unique name , Do not repeat . source-id: "mysql-01" # DM-worker Whether to use the global transaction identifier (GTID) Pull binlog. The premise of use is upstream MySQL Enabled GTID Pattern . If there is master-slave automatic switching in the upstream , Must be used GTID Pattern . enable-gtid: true from: host: "${host}" # for example :172.16.10.81 user: "root" password: "${password}" # Clear text password is supported but not recommended , It is recommended to use dmctl encrypt Encrypt the plaintext password and use port: 3306
secondly , After executing the following command in the terminal , Use tiup dmctl Load the data source configuration into DM In the cluster :
tiup dmctl --master-addr ${advertise-addr} operate-source create source1.yaml
The parameters in this command are described as follows :
| Parameters | describe |
|---|---|
--master-addr | dmctl Any of the clusters to be connected DM-master Node {advertise-addr}, for example :172.16.10.71:8261 |
operate-source create | towards DM The cluster loads the data source |
The first 2 Step : Create migration tasks
newly build task1.yaml file , Write the following :
# Task name , Multiple tasks running at the same time cannot have the same name . name: "test" # Task mode , May be set as # full: Only full data migration # incremental: binlog Real time synchronization # all: Total quantity + binlog transfer task-mode: "all" # The downstream TiDB Configuration information . target-database: host: "${host}" # for example :172.16.10.83 port: 4000 user: "root" password: "${password}" # Clear text password is supported but not recommended , It is recommended to use dmctl encrypt Encrypt the plaintext password and use # All upstream tasks required by current data migration MySQL The instance configuration . mysql-instances: - # Upstream instance or replication Group ID. source-id: "mysql-01" # The configuration item name of the black-and-white list of the library name or table name that needs to be migrated , Used to reference the black and white list configuration of the global , See the following for the global configuration `block-allow-list` Configuration of . block-allow-list: "listA" # Black and white list global configuration , Each instance refers to . block-allow-list: listA: # name do-tables: # White list of upstream tables that need to be migrated . - db-name: "test_db" # The library name of the table to be migrated . tbl-name: "test_table" # Name of the table to be migrated .
The above is the minimum task configuration for performing migration . More configuration items about tasks , You can refer to DM Introduction to the complete configuration file of the task .
The first 3 Step : Start the task
Before you start the data migration task , It is recommended to use check-task Command to check whether the configuration conforms to DM Configuration requirements for , To avoid errors in the later stage .
tiup dmctl --master-addr ${advertise-addr} check-task task.yaml
Use tiup dmctl Execute the following command to start the data migration task .
tiup dmctl --master-addr ${advertise-addr} start-task task.yaml
The parameters in this command are described as follows :
| Parameters | describe |
|---|---|
--master-addr | dmctl Any of the clusters to be connected DM-master Node {advertise-addr}, for example : 172.16.10.71:8261 |
start-task | Parameter is used to start the data migration task |
If the task fails to start , You can change the configuration according to the prompt of the returned result start-task task.yaml Command to restart the task . Please refer to Faults and handling methods as well as common problem .
The first 4 Step : View task status
If you need to know DM Whether there are running migration tasks and task status in the cluster , You can use tiup dmctl perform query-status Command to query :
tiup dmctl --master-addr ${advertise-addr} query-status ${task-name}
Detailed interpretation of query results , Please refer to State of the query .
The first 5 Step : Monitor tasks and view logs ( Optional )
To view the historical status of the migration task and more internal operation indicators , Please refer to the following steps .
If you use TiUP Deploy DM When the cluster , Deployed correctly Prometheus、Alertmanager And Grafana, Use the IP And port entry Grafana, choice DM Of Dashboard see DM Relevant monitoring items .
DM At run time ,DM-worker, DM-master And dmctl Will output relevant information through the log . The log directory of each component is as follows :
- DM-master Log directory : adopt DM-master Process parameters
--log-fileSet up . If you use TiUP Deploy DM, The log directory is located in/dm-deploy/dm-master-8261/log/. - DM-worker Log directory : adopt DM-worker Process parameters
--log-fileSet up . If you use TiUP Deploy DM, The log directory is located in/dm-deploy/dm-worker-8262/log/.
边栏推荐
- Core principles and source code analysis of disruptor
- [teacher Zhao Yuqiang] calculate aggregation using MapReduce in mongodb
- Kubernetes notes (I) kubernetes cluster architecture
- [teacher Zhao Yuqiang] Alibaba cloud big data ACP certified Alibaba big data product system
- There is no one of the necessary magic skills PXE for old drivers to install!!!
- Common exceptions when Jenkins is released (continuous update...)
- Installation du plug - in CAD et chargement automatique DLL, Arx
- Kubernetes notes (V) configuration management
- Btrfs and ext4 - features, strengths and weaknesses
- MySQL 5.7.32-winx64 installation tutorial (support installing multiple MySQL services on one host)
猜你喜欢

智牛股--03
![[teacher Zhao Yuqiang] use Oracle's tracking file](/img/0e/698478876d0dbfb37904d7b9ff9aca.jpg)
[teacher Zhao Yuqiang] use Oracle's tracking file
Apt update and apt upgrade commands - what is the difference?
![[trivia of two-dimensional array application] | [simple version] [detailed steps + code]](/img/84/98c1220d0f7bc3a948125ead6ff3d9.jpg)
[trivia of two-dimensional array application] | [simple version] [detailed steps + code]
Bio, NiO, AIO details
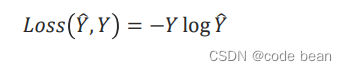
Loss function in pytorch multi classification
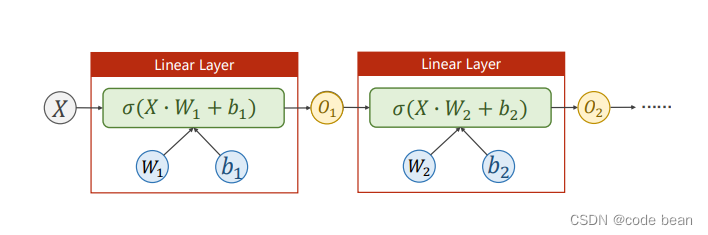
pytorch 搭建神经网络最简版

Kubernetes resource object introduction and common commands (V) - (configmap)

Clickhouse learning notes (2): execution plan, table creation optimization, syntax optimization rules, query optimization, data consistency

How does win7 solve the problem that telnet is not an internal or external command
随机推荐
Get a screenshot of a uiscrollview, including off screen parts
pytorch DataLoader实现miniBatch(未完成)
Kubernetes notes (IX) kubernetes application encapsulation and expansion
Apache+php+mysql environment construction is super detailed!!!
Leetcode solution - 02 Add Two Numbers
BeanDefinitionRegistryPostProcessor
[teacher Zhao Yuqiang] index in mongodb (Part 2)
Core principles and source code analysis of disruptor
How to create and configure ZABBIX
arcgis创建postgre企业级数据库
Simple solution of small up main lottery in station B
Exception when introducing redistemplate: noclassdeffounderror: com/fasterxml/jackson/core/jsonprocessingexception
项目总结--2(Jsoup的基本使用)
深度学习,从一维特性输入到多维特征输入引发的思考
Synthetic keyword and NBAC mechanism
The server data is all gone! Thinking caused by a RAID5 crash
MySQL帶二進制的庫錶導出導入
Strategy pattern: encapsulate changes and respond flexibly to changes in requirements
Understand the first prediction stage of yolov1
chromedriver对应版本下载