当前位置:网站首页>Loss function in pytorch multi classification
Loss function in pytorch multi classification
2022-07-03 05:49:00 【code bean】
Preface
pytorch Loss function in :
- CrossEntropyLoss
- LogSoftmax
- NLLLoss
Softmax
In multi classification , We want the output to conform to the probability distribution , So the use of Softmax Normalized .

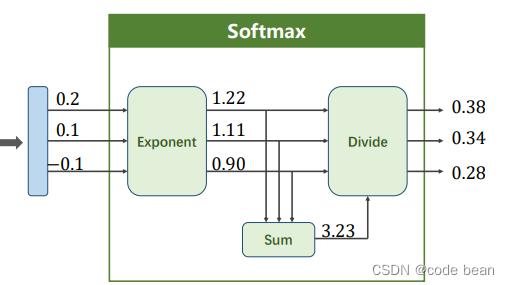
This process is very understandable , Add all the terms to get the denominator , Each is acting as a molecule , Just add one here e The exponential function at the bottom , Ensure that the values are greater than 0.
The last layer of multi classification neural network , It is usually used Softmax, So the last layer generally does not need to be activated ( See the code of the last numerical classification for details ), because Softmax It is equivalent to activation ( Map data to 0~1). Final Softmax Output the probability value of each category .
CrossEntropyLoss <==> LogSoftmax + NLLLoss
With the probability value , Start to construct the loss function , Cross entropy is still used here .
Maximum likelihood estimation , The divergence , Cross entropy _code bean The blog of -CSDN Blog

Recall the cross entropy of binary classification : Our function at that time BCE
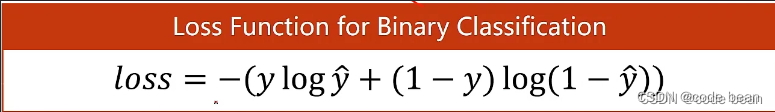
criterion = torch.nn.BCELoss(size_average=True) # Two class cross entropy loss function This is the expansion of the formula above ,p=y q=(1-y) and Y There are only two options 0 and 1, So when Y be equal to 1 When , The latter one is gone . So when it comes to multi classification, it's actually the same ,Y There are only two options 0 and 1. When a certain category is 1 Then other classes are 0.( The categories here are mutually exclusive , There will be this feature , If you are a cat, you won't be a dog )
Cross entropy formula , Finally, there is only one item saved .
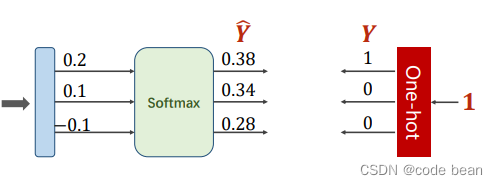
The single hot code on the right , It is the label of human judgment , It is also the probability given by people . Finally, there is only one term of mutually exclusive multi classification cross entropy :
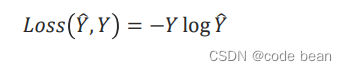
LogSoftmax
that LogSoftmax The meaning of is to softmax The result of takes a log
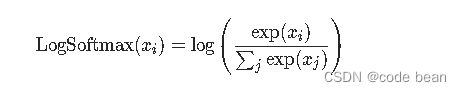
m = nn.LogSoftmax()
input = torch.randn(2, 3)
output = m(input)Why is the probability of good output , Add another one log what are you doing? ?
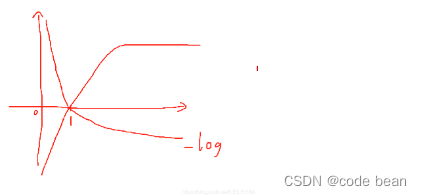
There is a saying that , Because the probability of output is 0~1, from log The function shows that , If the probability is closer 1, So it corresponds to Y The smaller the absolute value of . The greater the certainty of this representation , The less information , On the contrary, the greater the amount of information .
Then I think there is another reason , Namely LogSoftmax Generally and NLLLoss Used in combination with .
NLLLoss
NLLLoss What is done is the cross entropy part :


and NLLLoss The required input value is the result of logarithm of probability , that LogSoftmax and NLLLoss You can link seamlessly :
m = nn.LogSoftmax(dim=1)
loss = nn.NLLLoss()
# input is of size N x C = 3 x 5
input = torch.randn(3, 5, requires_grad=True)
# each element in target has to have 0 <= value < C
target = torch.tensor([1, 0, 4])
output = loss(m(input), target)
output.backward()CrossEntropyLoss
So much for that ,CrossEntropyLoss Do all the work of several people :

import torch
y = torch.LongTensor([0])
z = torch.Tensor([[0.2, 0.1, -0.1]])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z, y)
print(loss)
An example of multi classification of number recognition
Finally, take a look at a detailed example , Specific usage 
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
import torch.nn.functional as F
# Prepare the dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# Construct a network model
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
# take C*W*H The three-dimensional tensor becomes the two-dimensional tensor , For deep learning processing
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
# The last layer is not activated , No nonlinear transformation
return self.l5(x)
model = Net()
# Construct loss function and optimizer
criterion = torch.nn.CrossEntropyLoss() # This function , An inactive input is required , It will Cross entropy and softmax The calculation of .( This calculation is faster and more stable !)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # momentum: impulse
def train(epoch):
running_loss = 0
for batch_idx, data in enumerate(train_loader, 0):
# Get the input and label of a batch
inputs, target = data
# Start training
optimizer.zero_grad()
# Positive communication
y_pred = model(inputs)
# Calculate the loss
loss = criterion(y_pred, target)
# Back propagation
loss.backward()
# Update gradient
optimizer.step()
running_loss = running_loss + loss
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
# Don't calculate the gradient
with torch.no_grad():
for data in test_loader:
inputs, labels = data
prec = model(inputs)
'''
torch.max(input, dim) function
Input :
input yes softmax One of the outputs of the function tensor
dim yes max The dimension of the functional index 0/1,0 Is the maximum per column ,1 Is the maximum per line
Output :
The function returns two tensor, first tensor Is the maximum per line ,softmax The largest of the outputs is 1,
So the first one tensor It's all. 1 Of tensor; the second tensor Is the index of the maximum value per row , The value of this index is exactly equal to the predicted number .
'''
_, predicted = torch.max(prec.data, dim=1) # predicated Dimensionality (784,1) Tensor
total += labels.size(0)
# Comparison between tensors
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == "__main__":
for epoch in range(10): # After each round of training , Predict once
train(epoch)
test()
Output results :
[1, 300] loss: 2.166
[1, 600] loss: 0.820
[1, 900] loss: 0.422
accuracy on test set: 89 %
[2, 300] loss: 0.306
[2, 600] loss: 0.269
[2, 900] loss: 0.231
accuracy on test set: 94 %
[3, 300] loss: 0.185
[3, 600] loss: 0.172
[3, 900] loss: 0.152
accuracy on test set: 95 %
[4, 300] loss: 0.129
[4, 600] loss: 0.124
[4, 900] loss: 0.118
accuracy on test set: 96 %
[5, 300] loss: 0.103
[5, 600] loss: 0.094
[5, 900] loss: 0.095
accuracy on test set: 96 %
[6, 300] loss: 0.080
[6, 600] loss: 0.076
[6, 900] loss: 0.077
accuracy on test set: 97 %
[7, 300] loss: 0.062
[7, 600] loss: 0.067
[7, 900] loss: 0.059
accuracy on test set: 97 %
[8, 300] loss: 0.052
[8, 600] loss: 0.050
[8, 900] loss: 0.051
accuracy on test set: 97 %
[9, 300] loss: 0.036
[9, 600] loss: 0.045
[9, 900] loss: 0.042
accuracy on test set: 97 %
[10, 300] loss: 0.031
[10, 600] loss: 0.034
[10, 900] loss: 0.032
accuracy on test set: 97 % Reference material :
《PyTorch Deep learning practice 》 Complete the collection _ Bili, Bili _bilibili
softmax Why should cross entropy be taken -log_LEILEI18A The blog of -CSDN Blog _ Cross entropy log
边栏推荐
- Apache+php+mysql environment construction is super detailed!!!
- 今天很多 CTO 都是被幹掉的,因為他沒有成就業務
- 一起上水碩系列】Day 9
- Using the ethtool command by example
- [trivia of two-dimensional array application] | [simple version] [detailed steps + code]
- Ansible firewall firewalld setting
- 【无标题】
- Ensemble, série shuishu] jour 9
- QT read write excel -- qxlsx insert chart 5
- Btrfs and ext4 - features, strengths and weaknesses
猜你喜欢

伯努利分布,二项分布和泊松分布以及最大似然之间的关系(未完成)

理解 期望(均值/估计值)和方差

Capacity expansion mechanism of map

PHP笔记超详细!!!

期末复习(Day5)

Exception when introducing redistemplate: noclassdeffounderror: com/fasterxml/jackson/core/jsonprocessingexception
How to use source insight

Simpleitk learning notes
How to create and configure ZABBIX
Understand one-way hash function
随机推荐
[branch and cycle] | | super long detailed explanation + code analysis + a trick game
How to use source insight
Ansible firewall firewalld setting
Final review (Day2)
PHP notes are super detailed!!!
【一起上水硕系列】Day 7 内容+Day8
QT read write excel -- qxlsx insert chart 5
Es 2022 officially released! What are the new features?
Azure file synchronization of altaro: the end of traditional file servers?
[teacher Zhao Yuqiang] MySQL high availability architecture: MHA
ES 2022 正式发布!有哪些新特性?
2022.DAY592
kubernetes资源对象介绍及常用命令(五)-(ConfigMap)
2022.DAY592
"C and pointer" - Chapter 13 function of function pointer 1 - callback function 1
[escape character] [full of dry goods] super detailed explanation + code illustration!
[trivia of two-dimensional array application] | [simple version] [detailed steps + code]
How to create your own repository for software packages on Debian
How does win7 solve the problem that telnet is not an internal or external command
Jetson AgX Orin platform porting ar0233 gw5200 max9295 camera driver