当前位置:网站首页>Understand the recommendation system in one article: Recall 06: Two-tower model - model structure, training method, the recall model is a late fusion feature, and the sorting model is an early fusion
Understand the recommendation system in one article: Recall 06: Two-tower model - model structure, training method, the recall model is a late fusion feature, and the sorting model is an early fusion
2022-08-05 01:51:00 【Ice Dew Coke】
一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,The recall model is a late fusion feature,The ranking model is an early fusion feature
提示:最近系统性地学习推荐系统的课程.我们以小红书的场景为例,讲工业界的推荐系统.我只讲工业界实际有用的技术.说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,看书学不到推荐系统的关键技术.看书学不到推荐系统的关键技术.看书学不到推荐系统的关键技术.
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration FilterThe core idea and recommendation process of
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),To calculate the similarity between users
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,Basic no industry,But it helps to understand the twin tower model
提示:文章目录
文章目录
- 一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,The recall model is a late fusion feature,The ranking model is an early fusion feature
- 前言:The twin tower model can be seen as an upgraded version of the matrix supplement
- Let's start with the structure of the twin tower model
- 双塔模型
- The training method of the twin tower model:pointwise,parawise,listwise
- Explain in detail three ways to train the twin tower model
- See clearly recall is the backend features fusion,And fine row is front-end feature fusion
- 总结
前言:The twin tower model can be seen as an upgraded version of the matrix supplement
上一篇文章讲了矩阵补充模型,This article is about双塔模型.
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,Basic no industry,But it helps to understand the twin tower model
The twin tower model can be seen as an upgraded version of the matrix supplement,Below is the matrix complement model introduced earlier.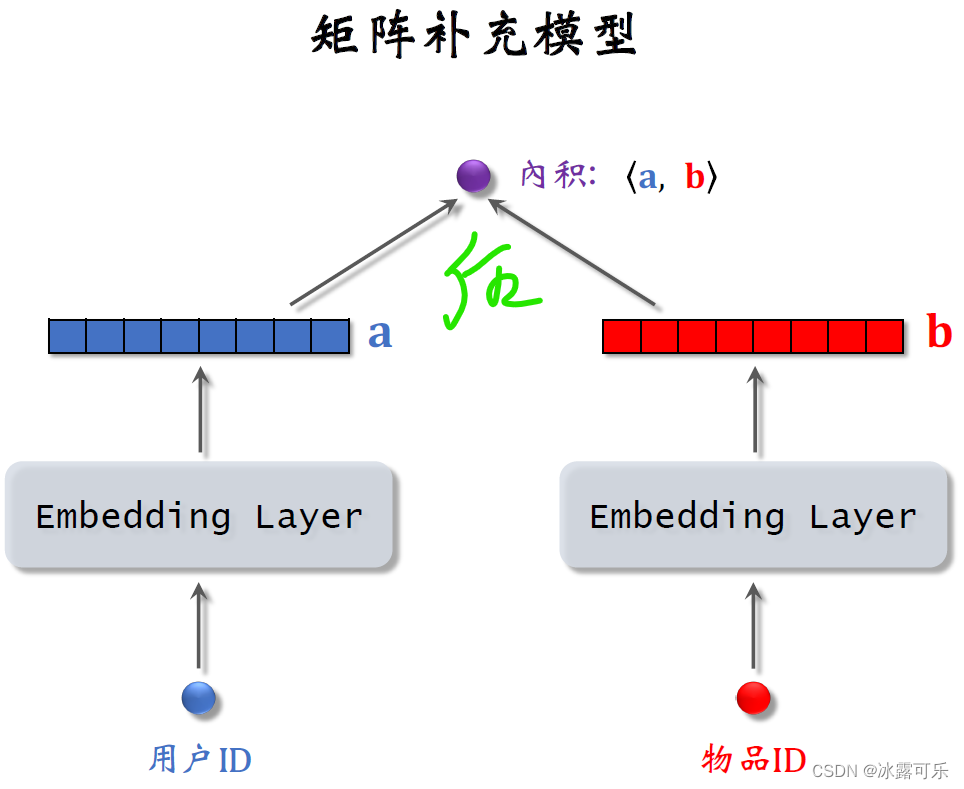
The input to the model is a userID和一个物品ID,model with twoembedding层把两个IDmap to two vectors,
Use the inner product of two vectors to estimate the user's interest score for the item.
This model is weak,using only users and itemsID,Don't use the user and the attribute of the item.
The twin-tower model introduced today can be seen as an upgrade of the matrix supplementary model.
Let's start with the structure of the twin tower model
Let's first look at the characteristics of users,we know usersIDIt can also obtain many characteristics from the information filled in by the user and user behavior,包括离散特征和连续特征.
All these features cannot be directly fed into the neural network,but do some processing first,比如用embedding层把用户IDmap to a vector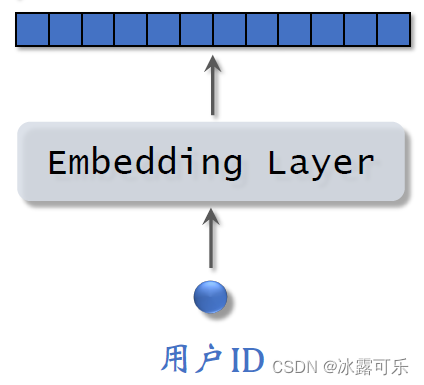
The same as the discrete features we talked about before,users still haveMultiple discrete features,Such as topics of interest in the city, etc..
用embeddinglayer maps discrete features of users into vectors,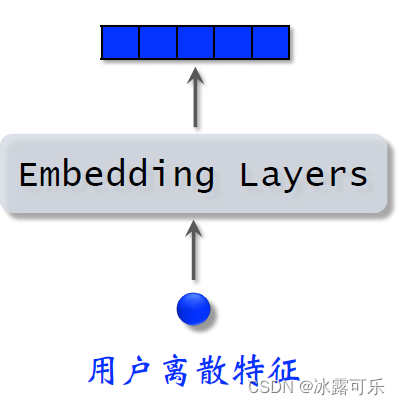
for each discrete feature,with a singleembedding层得到一个向量,such as the user's city,用一个embedding层
用户感兴趣的话题,用另一个embedding层
For discrete features with a small number of categories such as gender,直接用one hot编码就行,可以不做embedding
There are many more users连续特征,比如年龄、活跃程度、消费金额等等.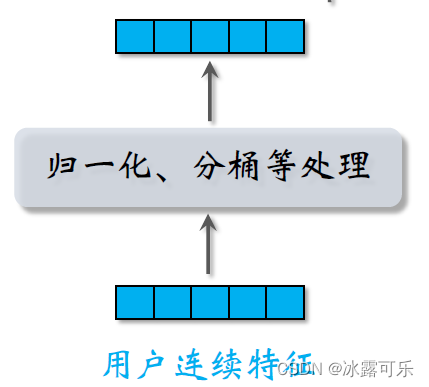
Different types of continuous features are handled differently,The easiest is to do normalization,Let the feature mean be zero,标准差是一.
Some continuous features of long-tailed distributions require special handling,比如取log,such as splitting,
complete feature processing,get many eigenvectors,Put these vectors together and feed them into the neural network.
Neural networks can be simple fully connected networks,Can also be a more complex structure,such as deep cross network.
The neural network outputs a vector,This vector is the representation of the user.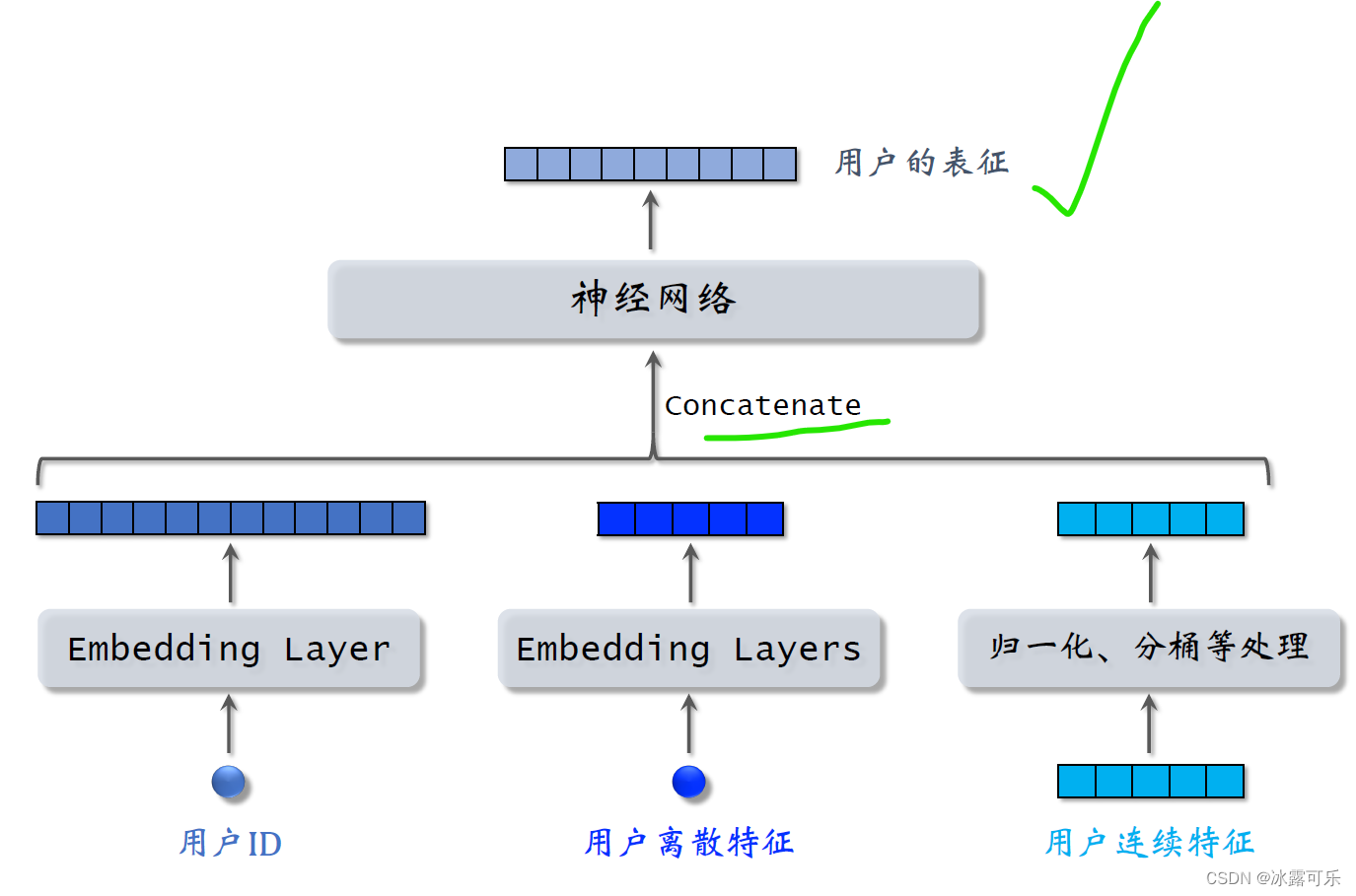
Do recall using this vector,
同理,The characteristics of the item is processed in a similar way.
用embeddingLayer Handling ItemsID和其他离散特征,
Use methods such as normalized logarithms or bucketing to process continuous features of items,
Feed the resulting features into a neural network.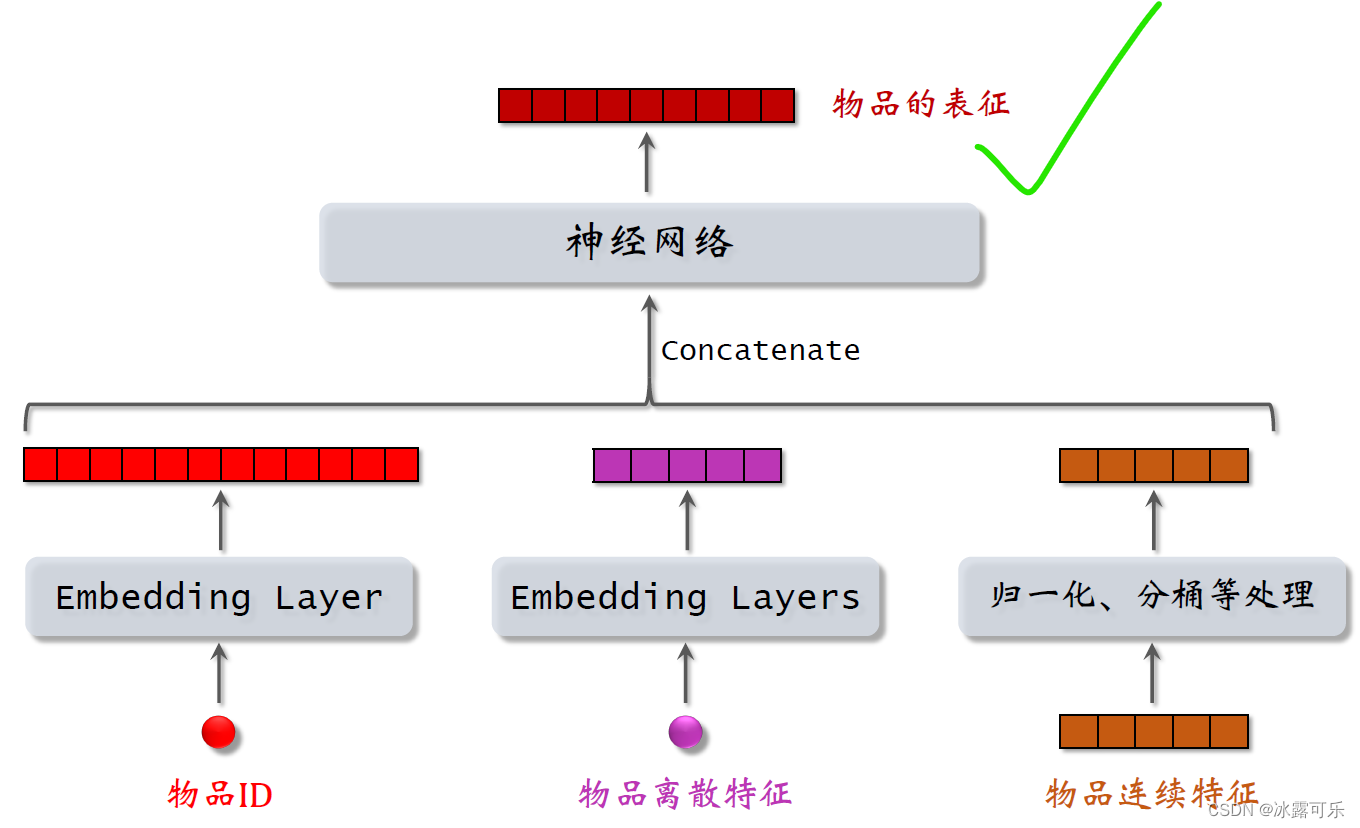
The vector output by the neural network is the representation of the item,用于召回.
双塔模型
The following model is called the twin tower model,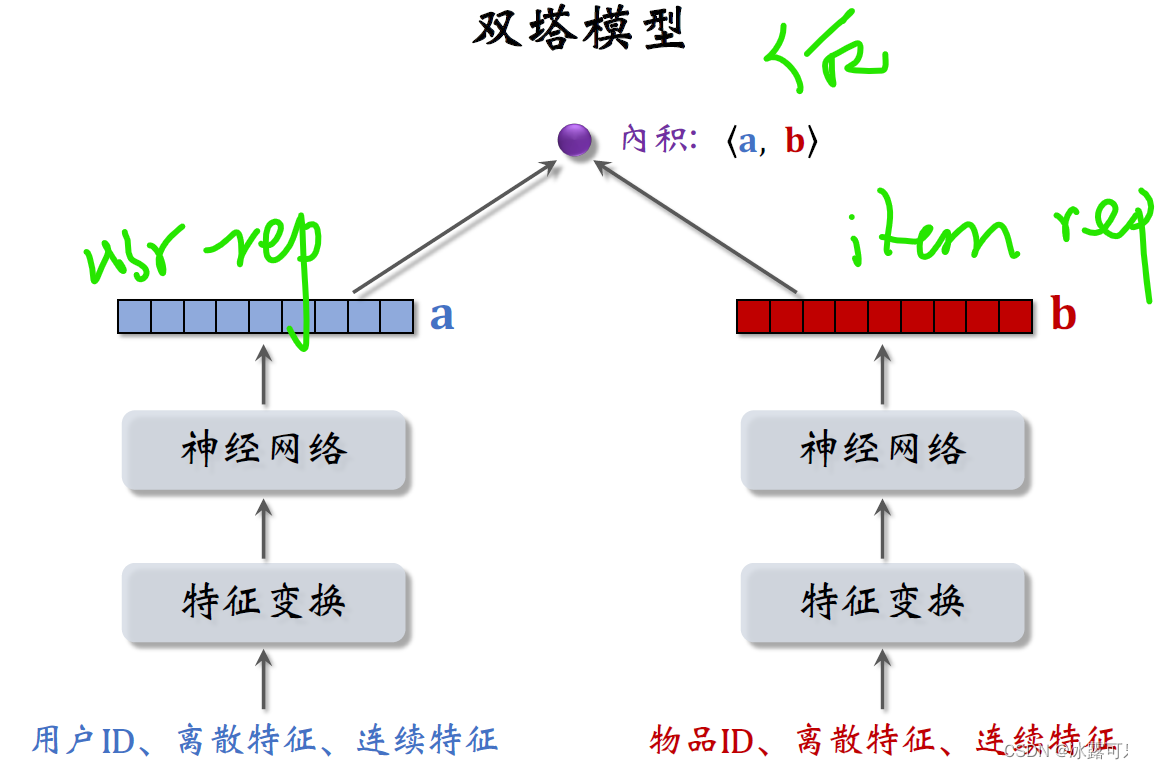
**尤其要注意:**This model takes the user representation directlyrep和物品表征rep去融合,History called back-end feature fusion model!!
——This is the usage of recall,absolutely not in advanceconcatRe-inject the neural network to map a scorerate(That's fine-tuning!)
The tower on the left extracts the features of the user
On the right it extracts the features of the item
Compared to the matrix supplemented model from the previous article,The difference between the two-tower model is the use ofID various features other than,
as input to the twin towers,Each of the two towers outputs a vector denoted asa和b,
The inner product of the two vectors is the final output of the modelrate,It estimates the user's interest in the item.
Now the more commonly used output method is余弦相似度.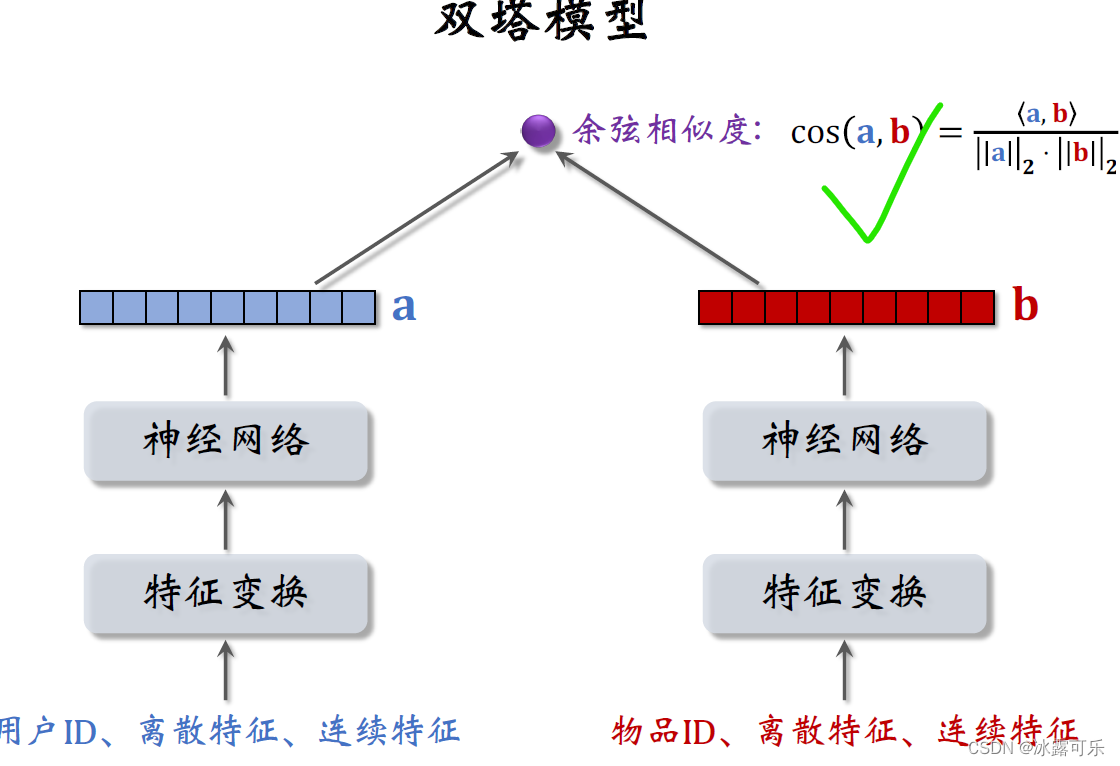
The output of the two towers,As vector, respectivelya和b,Cosine similarity means the cosine of the angle between two vectors,
It is equal to the vector inner product divided bya的二范数,再除以b的二范数,
In fact, it is equivalent to attributing the two vectors first.,Then find the inner product
The size of the cosine similarity is between negative one and positive one.
The training method of the twin tower model:pointwise,parawise,listwise
There are three ways to train a two-tower model

第一种是pointwise训练,Look at each positive and negative sample independently,
Do a simple binary classification training model,把正样本、Negative samples form a dataset.
Do stochastic gradient descent on the dataset to train a two-tower model.
The second way to train a two-tower model isparawise,每次取一个正样本,一个负样本组成一个二元组.
损失函数用triplely hing loss或者triple logistic loss
可以参考下面这篇Facebook发的论文.
《Jui-Ting Huang et al. Embedding-based Retrieval in Facebook Search. InKDD, 2020.》
The third way to train a two-tower model islistwise,每次取One positive sample and multiple negative samples组成一个list.
The training method is similar to multivariate classification,Refer to the following document two,这是Youtube发的论文,
《Xinyang Yi et al. Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations. In RecSys, 2019.》
Use positive and negative samples during training.
So how to choose positive and negative samples?
Positive samples are simple,is the item the user has clicked on,User clicked on an item,It means that the user is interested in the item,
Negative samples mean that users are not interested in,Negative sample selection no.
那么显然,In practice, the selection of negative samples is more particular.,There are several subsamples that seem reasonable:
such as not being recalled
召回了,but ripped,Eliminated
Also exposed,but the user did not click
该用哪种?In the next article, we will explain in detail how to choose positive and negative samples.,
感兴趣的话,You can read the two papers just mentioned by yourself,
论文讲解了Facebook Youtube如何选择正负样本,
我们The little red book basically did the same,Add some tips of your own,取得了很好的效果.
Explain in detail three ways to train the twin tower model
Pointwise训练
第一种是pointwise训练,pointwiseis the easiest way to train,
We treat recall as a simple binary classification task,A positive sample means that the history shows that the user is interested in the item
对于正样本,we want to encourage vectora和b的cosClose to the similarity of+1
Negative samples mean that the user is not interested in the item,对于负样本,we want to encourage vectora和b的cosClose to the similarity of-1
This is a typical binary classification problem..
如果做pointwise训练,The number of positive and negative samples can be controlled at1 : 2或者1 : 3.
我也不知道为什么,But the Internet companies to do so,This is industry experience.
Pairwise训练
The second way to train a two-tower model ispair wise,做训练的时候,Each set of input is a三元组,include a userIDand two itemsID.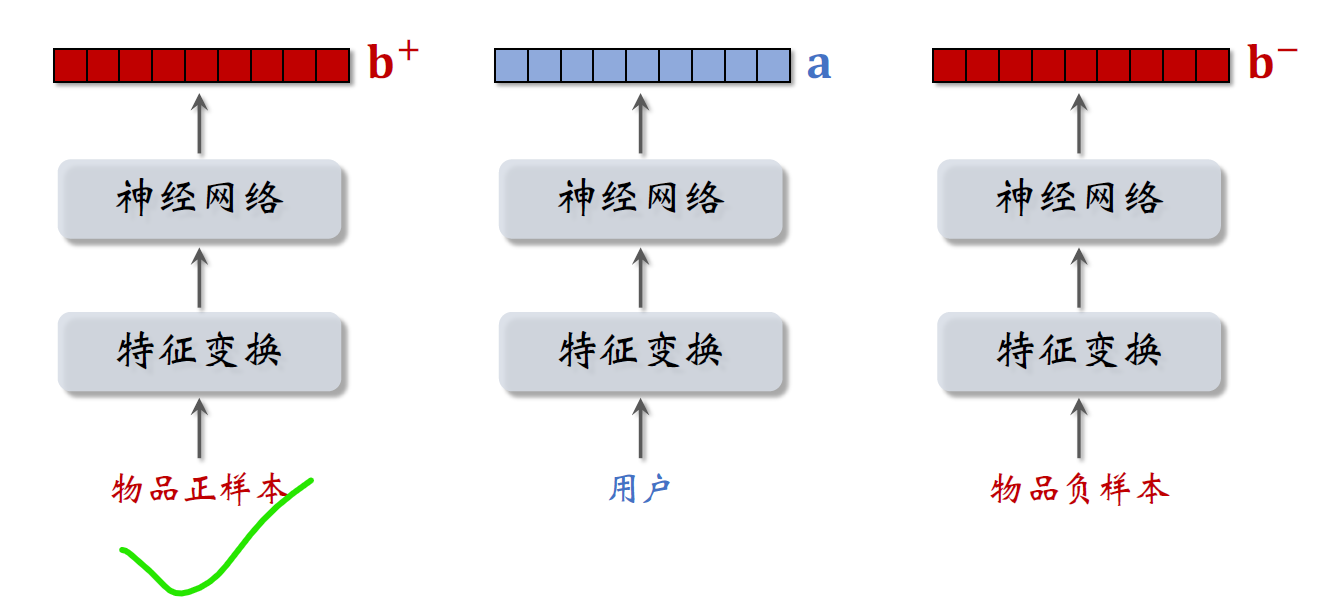
On the left side of the goods is like this,items that users are interested in.
The right of the item is a negative samples,is an item that the user is not interested in,
Transform the features of the user and the features of the item,然后输入神经网络,The final output is three vectors,
The user's feature vector is written asa,
Characteristics of two items,向量记作B加和Bminus two items,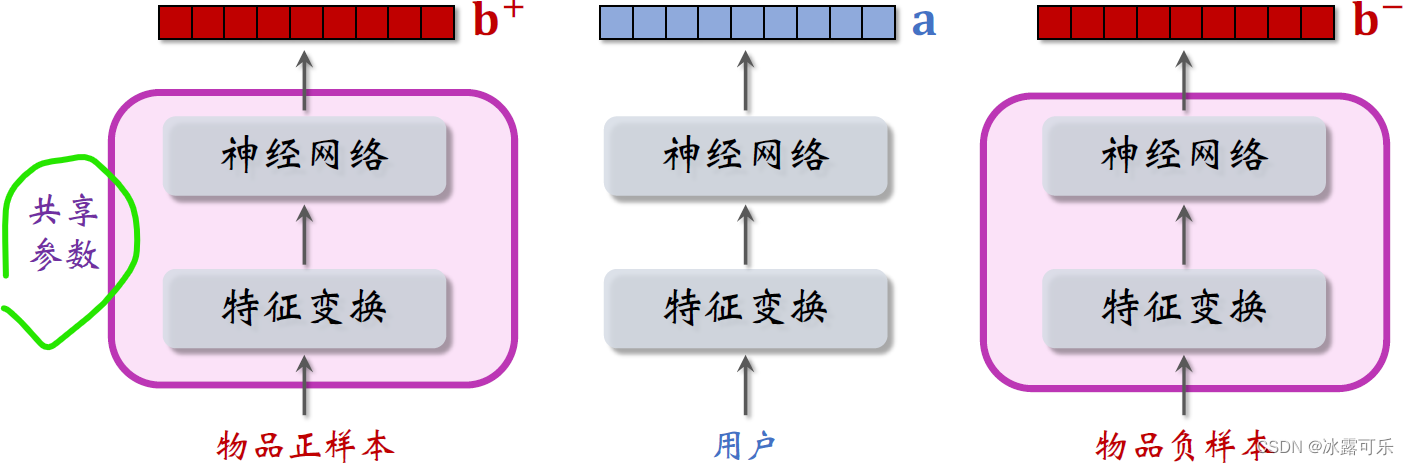
feature transformation maps the item'sembedding结构是相同的,里面的embeddingBoth layers and fully connected layers use the same parameters
Calculate the user's interest in two items separately
The user's interest in positive samples is a vectora和向量bAdded cosine similarity,这个值越大越好,最好是接近+1.
The user's interest in negative samples is a vectora和向量bSubtracted cosine similarity,这个值越接近-1越好.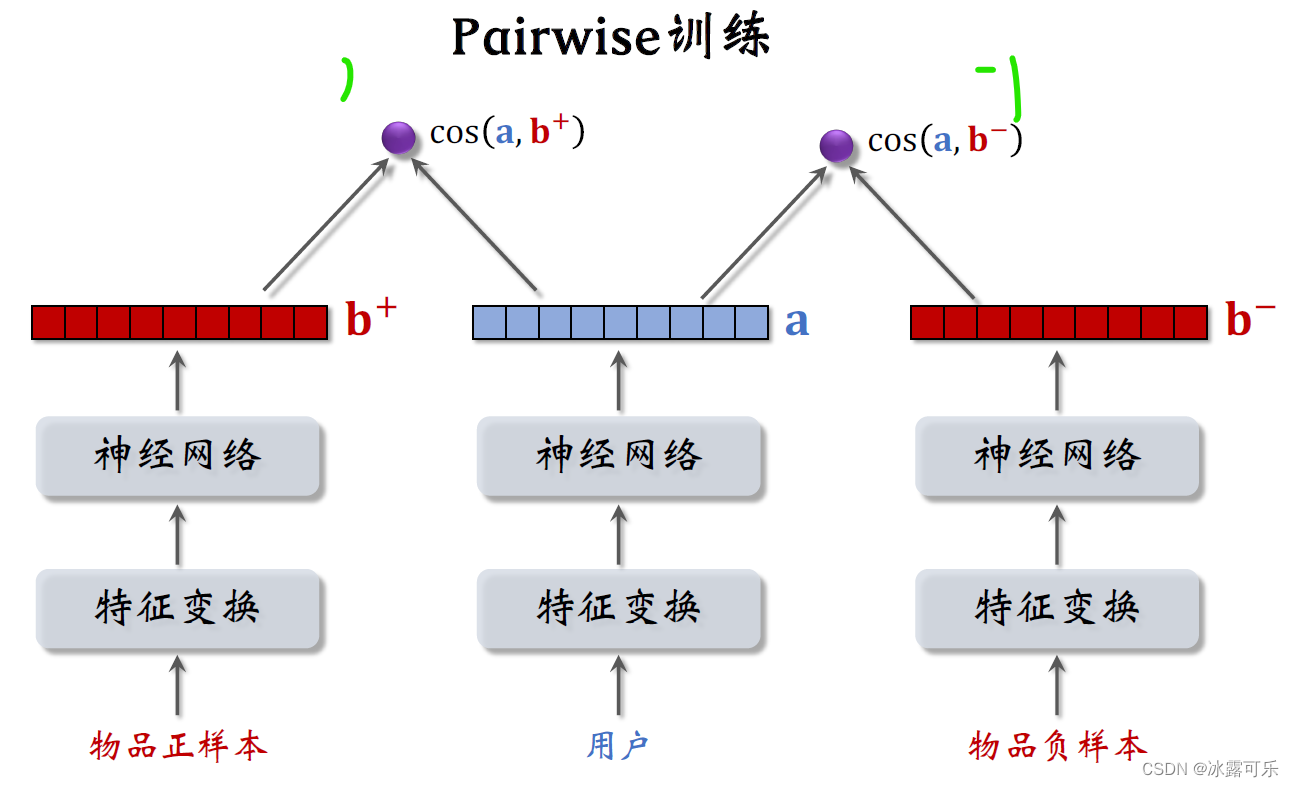
做pair wiseThe basic idea of training is to make users as interested in positive samples as possible,Minimize interest in negative samples.
That is, let the vectora和bThe added running similarity is greater than the vectora和bSubtracted cosine similarity,And the bigger the difference, the better.
Let's derive the loss function,
We want to see a lot of interest in positive examples from users,And little interest in negative samples,Preferably the former is bigger than the latterM这么多.
这个M是个超参数,需要调,比如设置成1,
If the former is larger than the latterM,then there is no loss,
Otherwise, if the user's interest in positive samples is not large enough,There is no negative samples of interestM这么多,就会有损失,
损失等于cos(a,b减)加上M,再减去cos(a,b加)【这个loss是正数,need to get it down to0才行】
This deducestriple hinge loss.
If you are familiar with the Siamese networksign is network,You should have seen this loss function.
During training, each training sample is a triple,向量ais the representation of the user,B加和BReduction are items characterization of positive samples and negative samples,
We want the loss function to be as small as possible,The training process is to minimize the loss function,
Updating parameters of a two-tower neural network with gradients,
Triplely hinge lossJust a kind of loss function,There are other loss functions that do the same thing.
triplet logistic loss是这样定义的,其实就是把logisticThe function acts on this term to minimize,
LogisticThe function will encourage this item to be as small as possible,也就是让cos( a,b减)尽量小.
让cos( a,b加)尽量大,
跟上面的Triplely hinge loss道理是一样的,
All are to make the user's interest score in the positive sample as high as possible,The user's interest score for negative samples should be as low as possible.
这里的sigmais a hyperparameter greater than zero that controls the shape of the loss function,Sigma需要手动设置.
稳了,We have deducedTriplely hinge loss和Triplely logistic loss,A two-tower model can be trained by minimizing a loss function like this.
The training samples are all triples,其中一个用户,a positive sample item,There is also a negative sample item.
Listwise训练
The third way to train a two-tower model islist wise.
做list wise训练的时候,Take one positive sample and many negative samples at a time,
requires a user to record its eigenvectors asa,
take a positive sample,Means the history shows that the user liked the item,Let the feature vector of this item be written asB加,
还需要取N个负样本,make their eigenvectorsB1减到BN减.
Encouragement when doing traininga和正样本b+The cosine similarity is as large as possible,
鼓励a和负样本bn-The cosine similarity is as small as possible.
下面我演示一下list whitehow to train.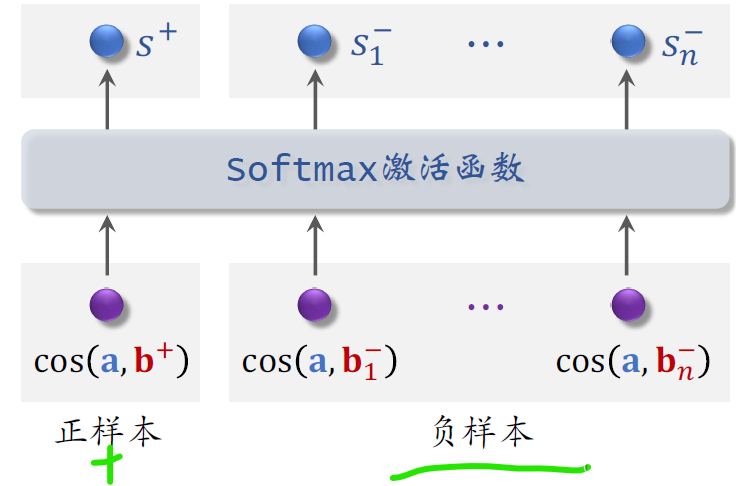
向量a和BThe added cosine similarity is a real number between negative one and positive one,It means the estimated score of the user's interest in the positive sample item.
The higher the score, the better,It's better to be close to
其余的cosSimilarity corresponds to negative samples,user pairNEstimated scores for negative sample interests,这NThe smaller the score, the better,preferably close to minus one
把这Nscore of negative samples,And the sample points,全部输入soft max激活函数【It is to normalize the whole to0–1的函数】,
激活函数输出N+1个分数,These scores are all between zero and one,
leftmost scoreSAdd the corresponding positive sample,We want this score to be as high as possible,best to be close1.
右边的Nscores correspond to negative samples,We want these scores to be as small as possible,preferably close to zero.
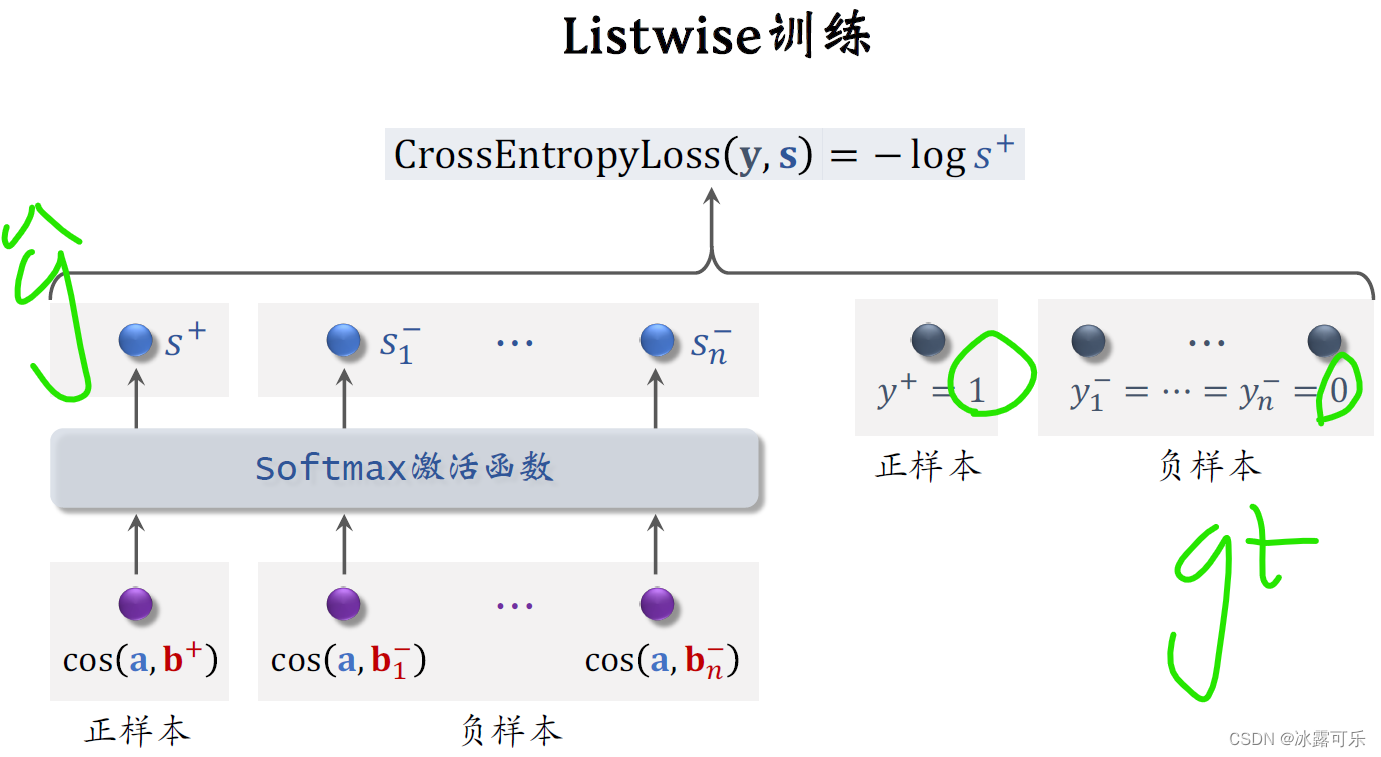
上图中,y+=1is the label of the positive sample,means to encourageS+接近1
负样本的标签是Y1减到YN减,set them both to0,means to encourageS1减到SNminus all close0,
我们用Y和S的交叉熵作为损失函数.
训练的时候,最小化交叉熵,means to encouragesoft max,输出的预测值S,as close to the label as possibleY,
In fact, the cross quotient is equal to the negativelog s加【上面公式】
Minimize the cross quotient during training最大化S加,
This is equivalent to the maximization is cosine similarity of samples,
Minimize cosine similarity of negative samples.
懂???The essence of the three training methods is to make the cosine similarity between the user and the positive sample item large.,The cosine similarity between the user and the negative sample is small..
I have finished the two-tower model and three training methods,Finally, summarize what this article has said,
双塔模型,As the name suggests there are two towers,a user tower,an item tower,
Each of the two towers outputs a vector,
The residual similarity of the vector is the estimated value of interest,这个值越大,Users are more likely to be interested in an item.
There are three ways to train a two-tower model,
一种是pointwise,One user and one item at a time,Items can be either positive or negative samples,
The second training method ispair wise,Take one such item at a time for one user,a negative sample item
The goal of training is to minimizeTriplely hinge loss和Triplely logistic loss,
That is to make the cosine similarity of positive samples as large as possible,As far as possible little cosine similarity and negative sample.
The third training method islist wise,one user at a time,a positive sample item,A number of negative samples
训练的时候用soft max激活函数
用交叉熵损失函数训练,As far as possible big cosine similarity and encourage is a sample
Negative sample cosine similarity should be as small as possible
See clearly recall is the backend features fusion,And fine row is front-end feature fusion
在结束之前,We discuss the design of a faulty recall model,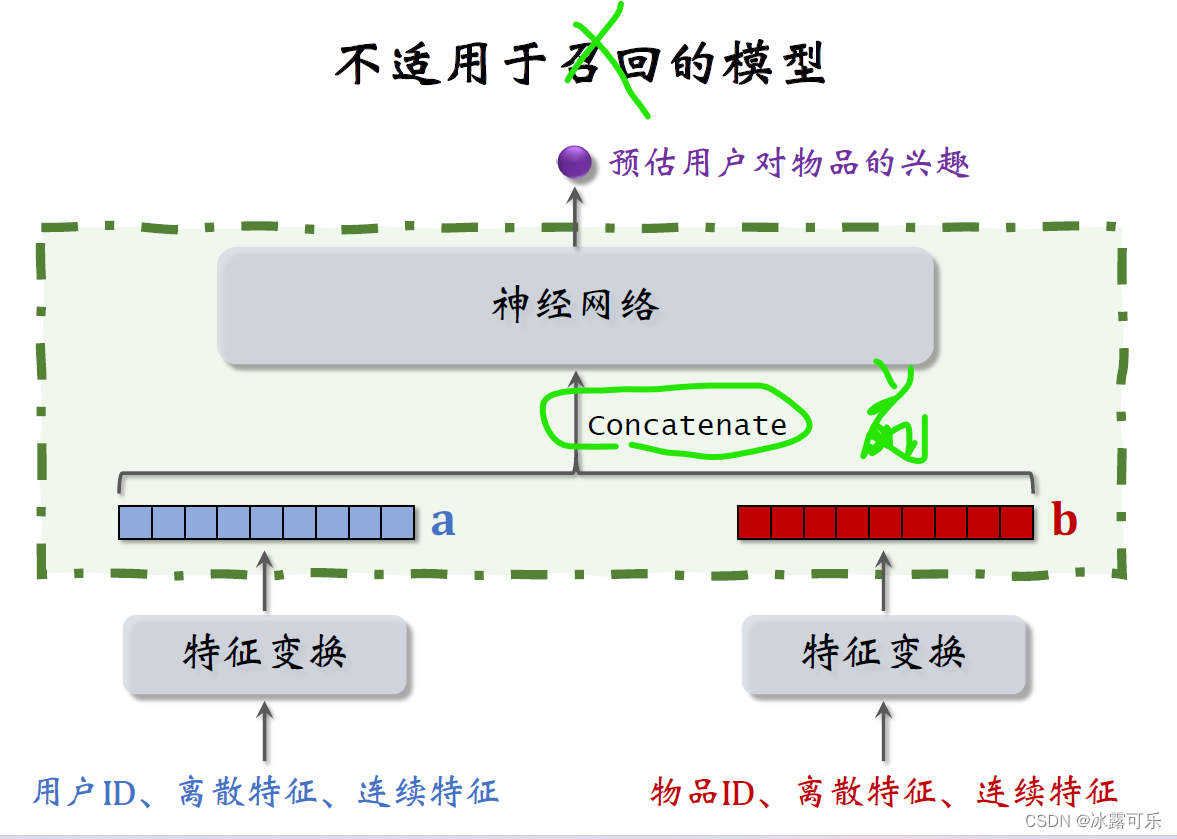
As soon as you see this structure, you should know that this is a rough or fine row model,instead of recalled models,This model cannot be applied to recall.
The following structure is the same as the twin tower model,Both extract user and item features separately,得到两个特征向量,
But the upper structure is different,Here directly do two vectorsconcat.
Then enter a neural network,Neural network can have a lot of layers,This neural network structure belongs to前期融合,
The feature vectors are pieced together before entering the fully connected layer.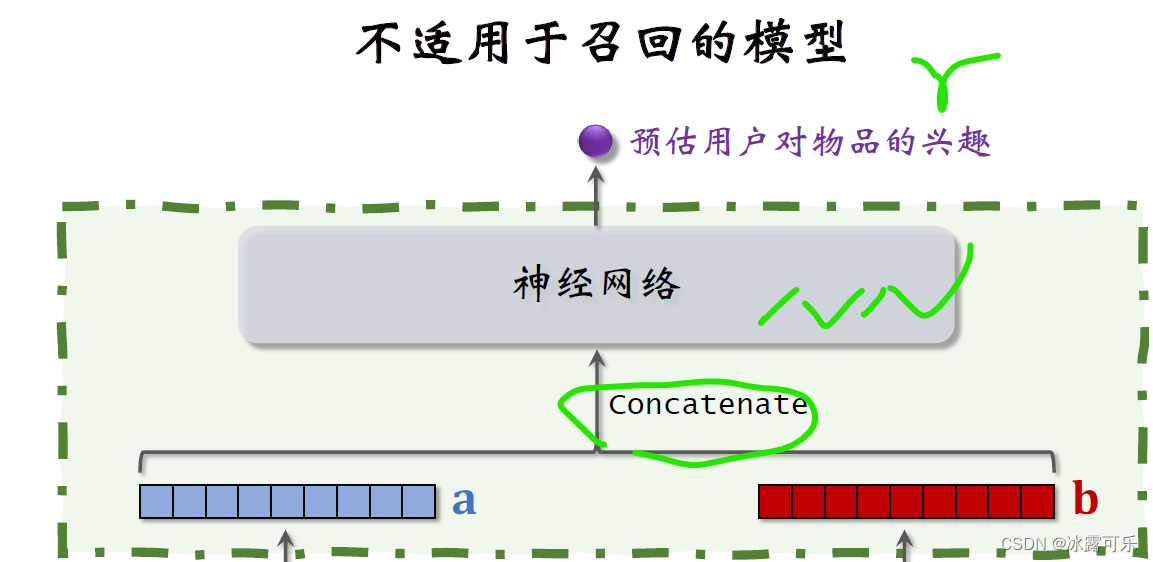
Take a look at the neural network in the refined model diagram,The neural network finally outputs a real number as the estimated score,Indicates a user's interest in an item,
Put the two feature vectors together and feed them into the neural network,This pre-fusion model is not suitable for recall.
This early-stage fusion neural network structure is very different from the two-tower model mentioned earlier,The twin tower model belongs to后期融合,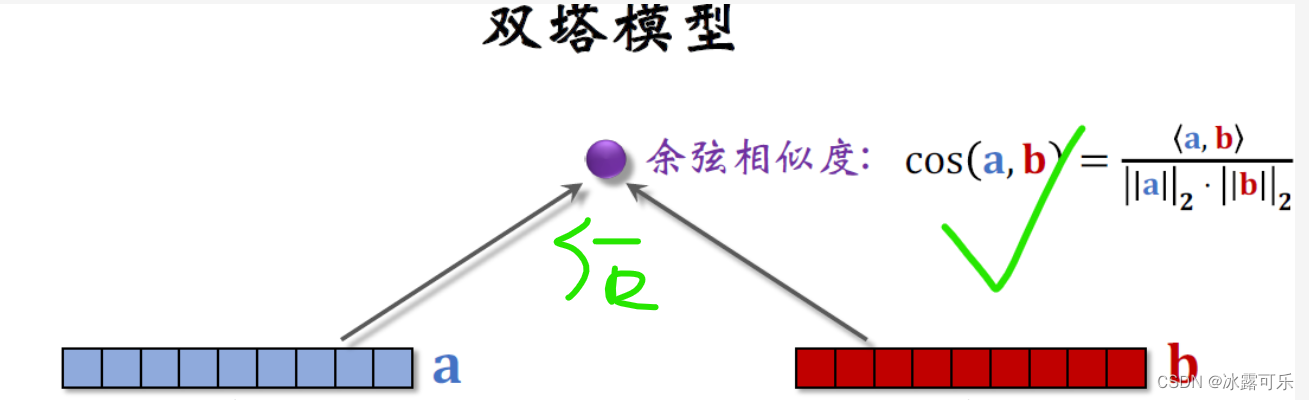
The two towers are only merged when the final output similarity is reached..【The neural network is not used to output the similarity at all.】
If this refined model is used for recall,It is necessary to input the features of all items into the model one by one,Estimate user interest in all items.
假设一共有1亿个物品,Every time a user is recalled,run this model1亿次,This amount of computation is clearly not feasible.
If this model is used,There is no way to use approximate nearest neighbor search to speed up computation.
This model is usually used for fine sorting,That is, select hundreds of candidate items from thousands,Not too much computation.
In the future, as soon as you see this pre-integrated model,It is necessary to understand that this is a sorting model,not a recall model.
Recall can only use late fusion models like Twin Towers.
okay,Today, I explained the neural network structure of the double tower model and three training methods..
When training, you need to select positive and negative samples,I'll tell you more about this part below.
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:The essence of the three training methods is to make the cosine similarity between the user and the positive sample item large.,The cosine similarity between the user and the negative sample is small..The model of early fusion is the sorting model,not a recall model,The recall model is all late fusion,Directly find cosine similarity,Indicates the user's preference for it.
边栏推荐
- Are testing jobs so hard to find?I am 32 this year and I have been unemployed for 2 months. What should an older test engineer do next to support his family?
- 【Endnote】Word插入自定义形式的Endnote文献格式
- Jin Jiu Yin Shi Interview and Job-hopping Season; Are You Ready?
- Transfer Learning - Distant Domain Transfer Learning
- 开篇-开启全新的.NET现代应用开发体验
- 记录谷歌gn编译时碰到的一个错误“I could not find a “.gn“ file ...”
- Oracle encapsulates restful interfaces into views
- If capturable=False, state_steps should not be CUDA tensors
- 新唐NUC980使用记录:在用户应用中使用GPIO
- If capturable=False, state_steps should not be CUDA tensors
猜你喜欢



随机推荐
Lattice PCIe 学习 1
Exercise: Selecting a Structure (1)
为什么他们选择和AI恋爱?
原生js实现多选框全部选中和取消效果
深度学习:使用nanodet训练自己制作的数据集并测试模型,通俗易懂,适合小白
[Endnote] Word inserts a custom form of Endnote document format
【TA-霜狼_may-《百人计划》】图形4.3 实时阴影介绍
Three handshake and four wave in tcp
Xunrui cms website cannot be displayed normally after relocation and server change
第十四天&postman
oracle将restful接口封装到视图中
[GYCTF2020]EasyThinking
Interview summary: Why do interviewers in large factories always ask about the underlying principles of Framework?
张驰咨询:揭晓六西格玛管理(6 Sigma)长盛不衰的秘密
方法重写与Object类
5.PCIe官方示例
【Endnote】Word插入自定义形式的Endnote文献格式
EBS uses virtual columns and hint hints to optimize sql case
Oracle encapsulates restful interfaces into views
pytorch的使用:卷积神经网络模块