当前位置:网站首页>PyTorch⑥---卷积神经网络_池化层
PyTorch⑥---卷积神经网络_池化层
2022-08-02 14:07:00 【伏月三十】
最大池化
目的:保留输入的特征,同时减少数据量。参数更少了,使得训练的更快。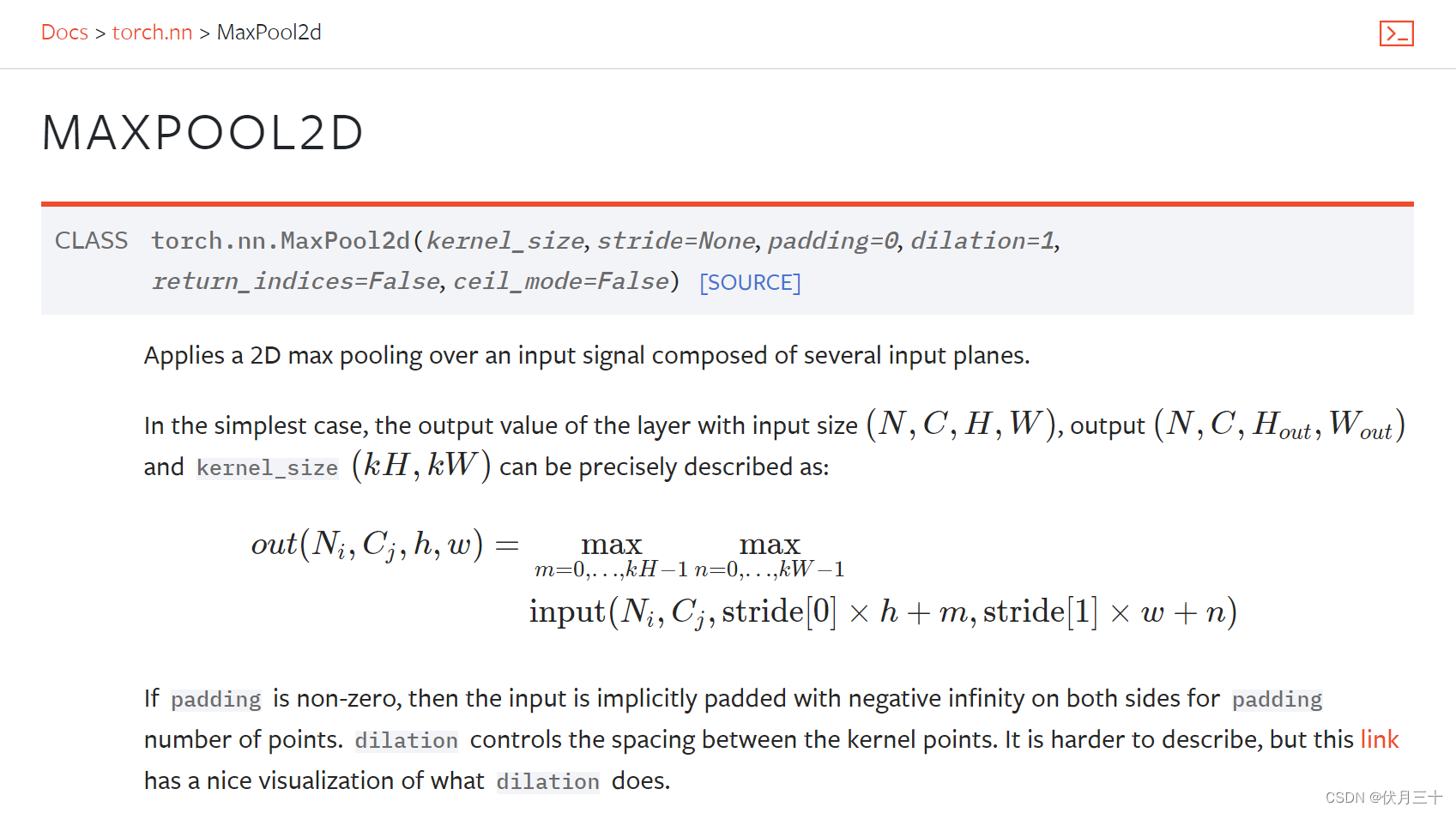

参数:
kernel_size:卷积核大小
ceil_mode:Ture保留、False不保留
注意输入输出都是四个参数或三个
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("dataset_CIFAR10",train=False,
download=True,
transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=64)
class Demo(nn.Module):
def __init__(self) -> None:
super().__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output=self.maxpool1(input)
return output
demo=Demo()
writer=SummaryWriter("logs_maxpool")
step=0
for data in dataloader:
imgs,targets=data
writer.add_images("input",imgs,step)
output=demo(imgs)
writer.add_images("output",output,step)
step=step+1
writer.close()
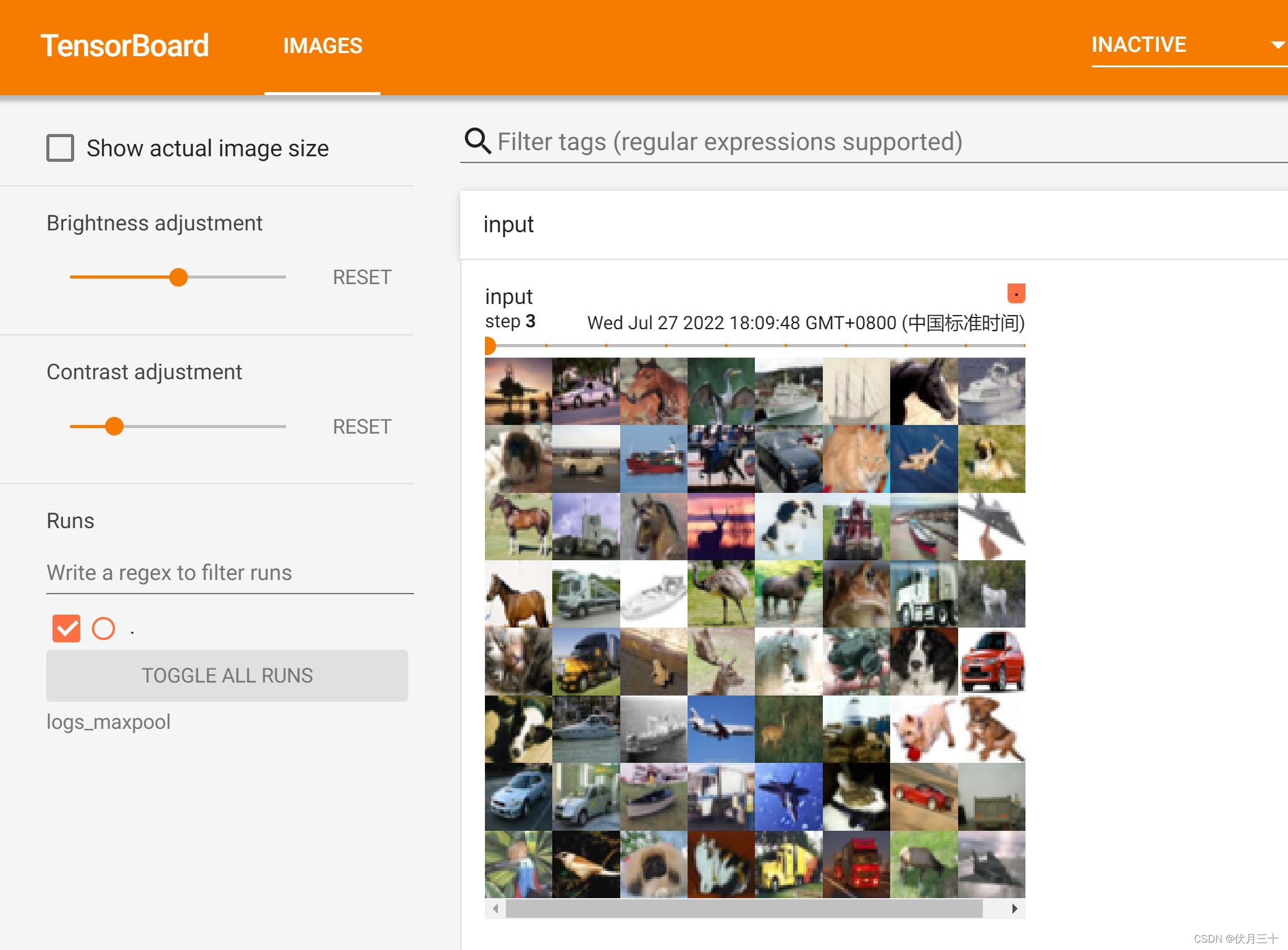
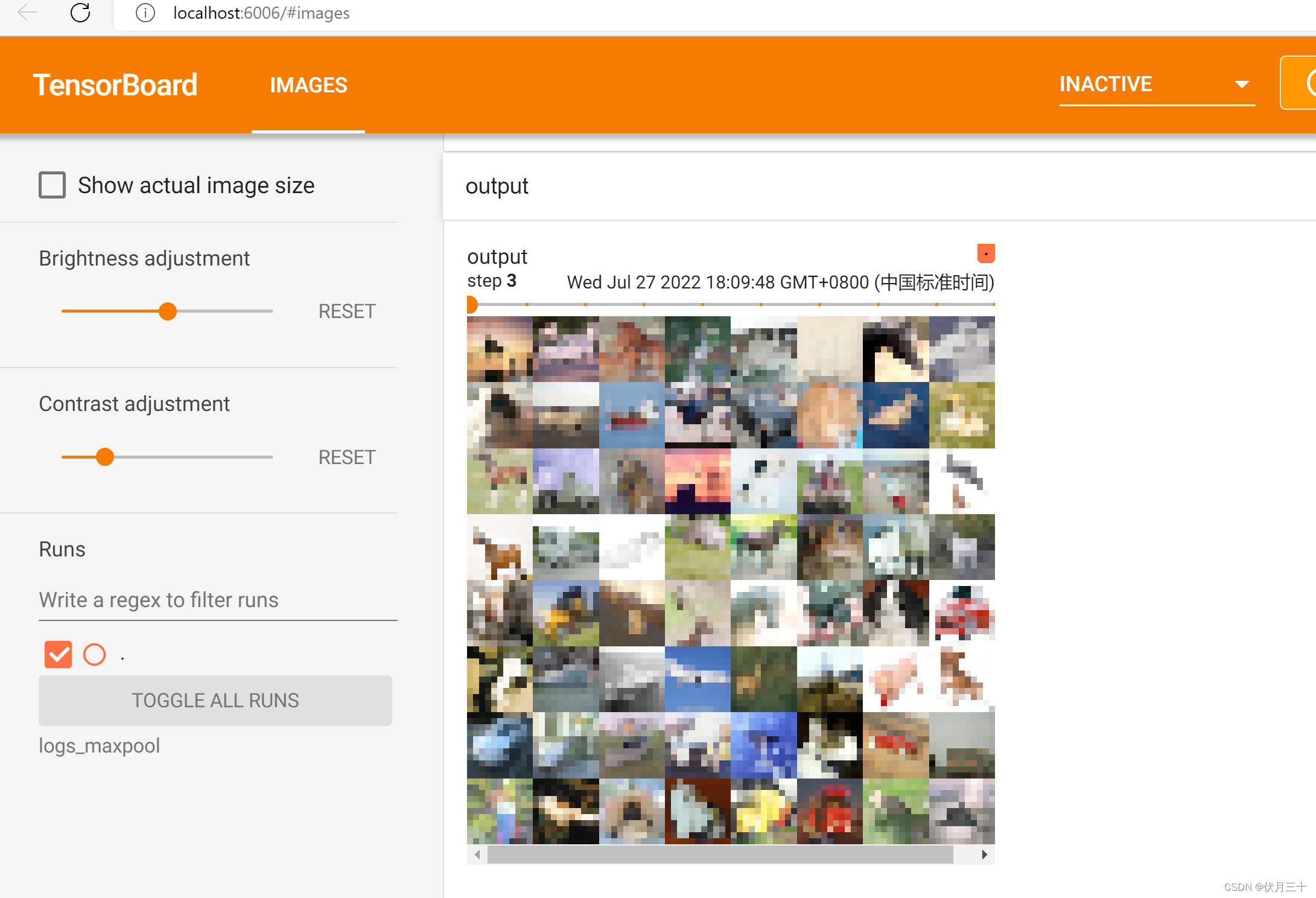
边栏推荐
猜你喜欢
MySQL知识总结 (四) 事务

宝塔搭建PHP自适应懒人网址导航源码实测

Using the cloud GPU + pycharm training model to realize automatic background run programs, save training results, the server automatically power off
![[论文阅读] ACT: An Attentive Convolutional Transformer for Efficient Text Classification](/img/59/88db682b6ff82d3612fd582cd499b2.png)
[论文阅读] ACT: An Attentive Convolutional Transformer for Efficient Text Classification
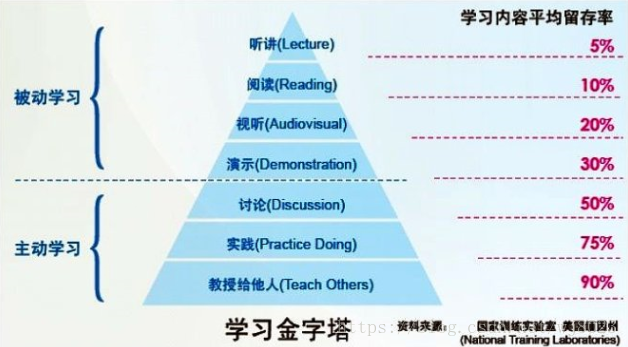
我理解的学习金字塔
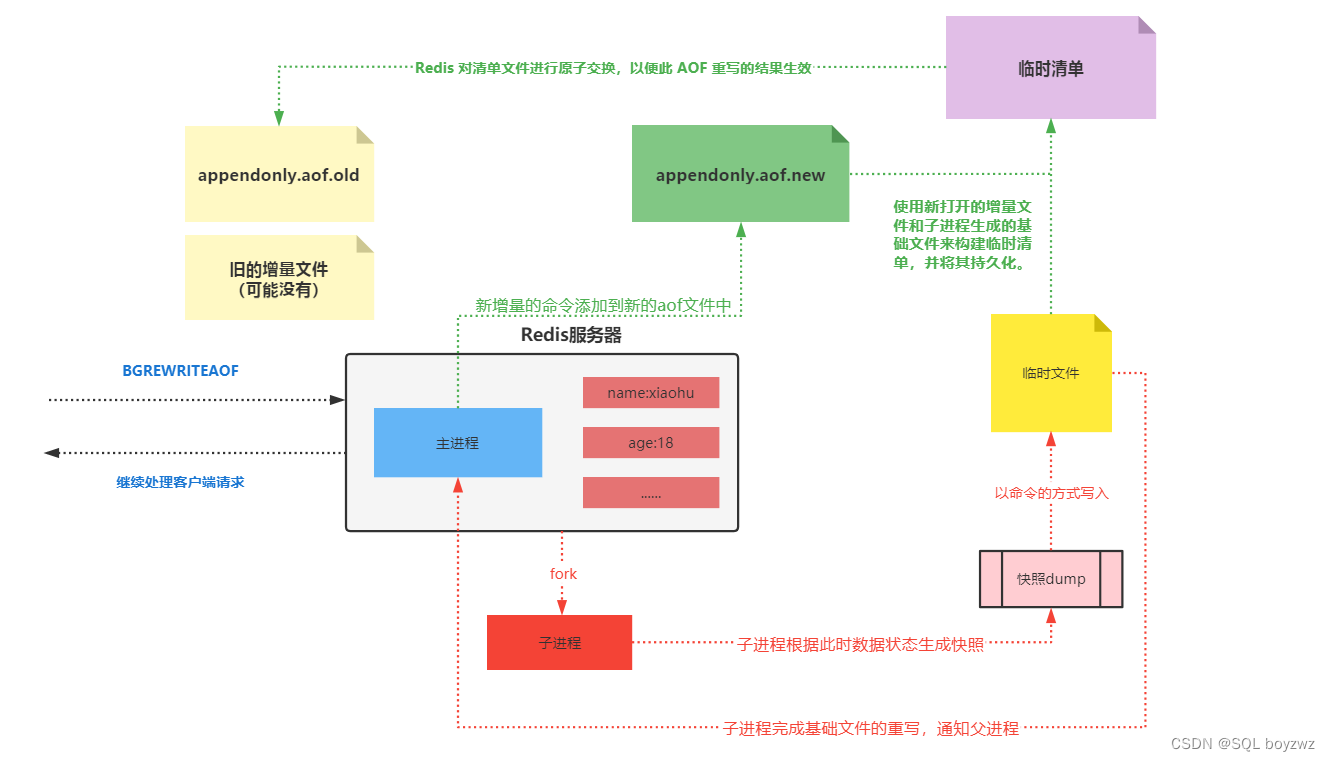
Redis持久化机制
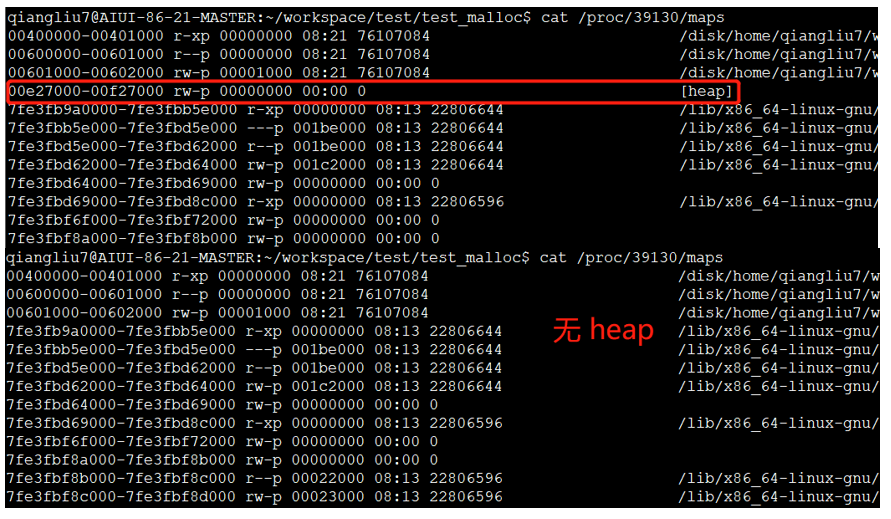
内存申请(malloc)和释放(free)之上篇
vscode编译keil工程,烧录程序

再见篇:App专项技术优化
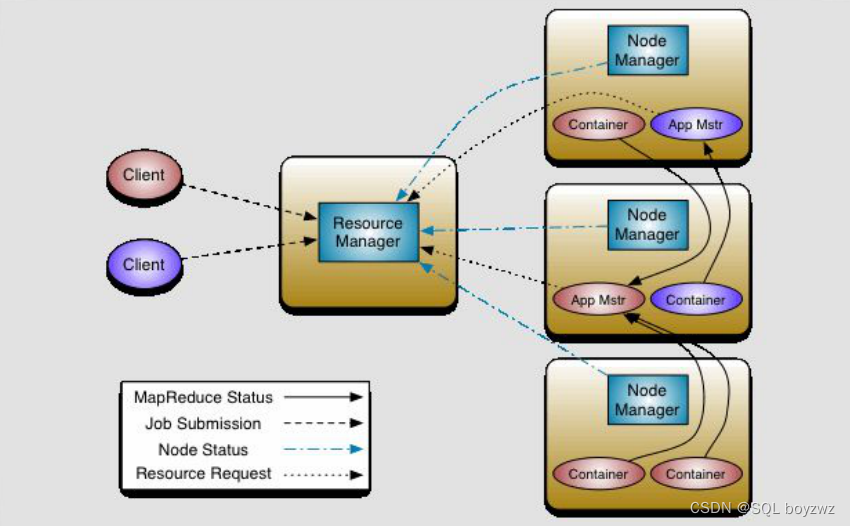
MapReduce流程
随机推荐
什么?都0202年了,你还不会屏幕适配?
还是别看学位论文
每周招聘|PostgreSQL专家,年薪60+,高能力高薪资
vscode compiles the keil project and burns the program
流,向量场,和微分方程
redis基础
Flink-独立集群/Yarn
LLVM系列第八章:算术运算语句Arithmetic Statement
spark on yarn
华为防火墙IPS
自定义UDF函数
文本匹配任务
LLVM系列第十八章:写一个简单的IR处理流程Pass
1.RecyclerView是什么
spark中RDD与DF的关系
LLVM系列第五章:全局变量Global Variable
MySQL知识总结 (五) 锁
App signature in flutter
RN开发时遇到的问题
Flink依赖汇总