当前位置:网站首页>spark写sql的方式
spark写sql的方式
2022-08-02 14:05:00 【大学生爱编程】
1.idea的把代码编写好打包上传到集群中运行
1.1依赖和插件
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
1.2 spark提交到集群中运行(导包)
spark-submit 提交
--conf spark.sql.shuffle.partitions=1 (设置spark sqlshuffle之后分区数据马,和代码里面设置是一样的,代码中优先级高)
spark提交到集群中运行
val spark: SparkSession =SparkSession //spark代码入口
.builder()
.appName("submit")
// .master("local")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
//读取hdfs数据
val studentDF: DataFrame =spark
.read
.format("csv")
.option("sep",",")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.load("/data/student/")
//统计性别人数
val gender_numDF: DataFrame =studentDF
.groupBy($"gender")
.agg(count(expr("1")) as "num") //需要的是列对象,不是数字也不是字符串
//保存数据到hdfs
gender_numDF
.write
.format("csv")
.option("sep",",")
.mode(SaveMode.Overwrite)
.save("/data/gender_num")
2.spark shell (repl读执行打印循环) 里面使用sqlContext
进入spark shell:spark-shell --master yarn-client
1.向yarn申请资源,进入spark代码的命令行
2.只能使用yarn-clint,打印日志,看到结果,测试使用,简单任务使用,代码无法保存
3.硬写代码,没有提示,有点小难
shell命令行中:
val studentDF=spark.read.format("csv").option("sep",",").schema("id STRING,name STRING,age INT,gender STRING,clazz STRING").load("/data/student/")
studentDF.show(100)
3. spark-sql
3.1 spark-sql --master yarn-client
不能使用yarn-cluster
和hive的命令行一样,直接写sql
在spark-sql是完全兼容hive sql的
spark-sql 底层使用spark进行计算
hive 底层使用的是MR进行计算
3.2 禁用集群spark日志
1.cd /usr/local/soft/spark-2.4.5/conf
2.mv log4j.properties.template log4j.properties
vim log4j.properties
3.修改配置
log4j.rootCategory=ERROR, console
3.2 spark sql和hvie的建表语句一样
create table student
(
id string,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS textfile
location '/data/student/'; //hdfs上的路径
spark-sql默认的把元数据库放进本地磁盘,删除后或者更改路径会找不到表
3.3 spark和hive整合
开启hive元数据服务,spark可以使用hive的元数据
1.在hive的..conf/hive-site.xml增加了一行配置
以后在使用hive之前都需要先启动元数据服务
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
将hive-site.xml 复制到spark conf目录下
cp hive-site.xml /usr/local/soft/spark-2.4.5/conf/
2.将mysql 驱动包复制到spark jars目录下
cd /usr/local/soft/hive-1.2.1/lib
cp mysql-connector-java-5.1.49.jar /usr/local/soft/spark-2.4.5/jars/
3.启动hive元数据服务, 将hvie的元数据暴露给第三方(spark使用)
nohup hive --service metastore >> metastore.log 2>&1 &
4.每次访问时必须重启hive元数据服务,整合好之后spark-sql里面就可以使用hive的表了
5.可以增加一些设置:
启动spark-sql时增加参数
默认是local模式
spark-sql -conf spark.sql.shuffle.partitions=2
---------------------------------------------------------------------------
可以指定yarn-client模式
spark-sql --master yarn-client --conf spark.sql.shuffle.partitions=2
---------------------------------------------------------------------------
进入spark-sql中再设置运行参数
set spark.sql.shuffle.partitions=2;
spark-sql-e:指定数据库后进行操作
spark-sql --database bigdata -e "select * from student"
saprk-sql-f
spark-sql --database bigdata -f a.sql
3.4 在idea代码中读取hive元数据,使用表
开启元数据服务后只能打包到服务器上运行
导入hive依赖:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-common</artifactId>
<version>1.2.1</version>
</dependency>
整个代码中没有创建表也没有读数据,直接将hive中的表转换成DataFrame进行操作
hive历史久,有很多表整合后可以节省重新建表的成本
val spark: SparkSession = SparkSession
.builder()
.appName("onhive")
.enableHiveSupport() //开启hive的元数据支持,在代码中读取hive的元数据
.getOrCreate()
//读取hive的表
val studentDF = spark.talbe("studnet")
3.5 spark-aql和hive的区别
spark-sql有缓存,对同一个表进行多次操作时
边栏推荐
猜你喜欢

随机推荐
verilog学习|《Verilog数字系统设计教程》夏宇闻 第三版思考题答案(第七章)
绕过正则实现SQL注入
宝塔搭建DM企业建站系统源码实测
C语言日记 7 输入/输出格式控制
C语言字符串——关于指针
Unit 13 Mixing in View Base Classes
ToF相机从Camera2 API中获取DEPTH16格式深度图
MySQL知识总结 (九) 用户与用户权限管理
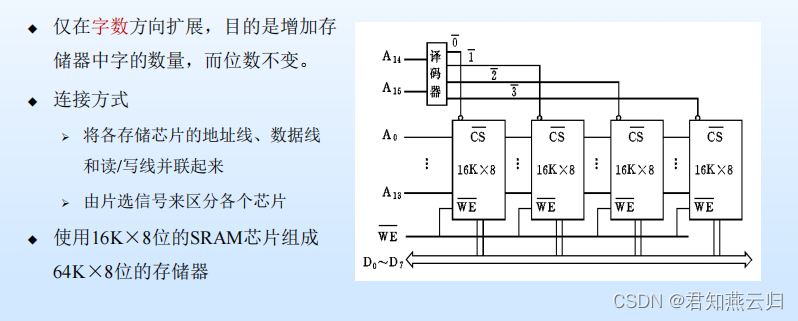
主存储器(一)
我的第一篇博客
线性代数期末复习存档
redis delay queue
Using the cloud GPU + pycharm training model to realize automatic background run programs, save training results, the server automatically power off
MongoDB Compass 安装与使用
Paddle window10 environment using conda installation
CTF-XSS
Web Design (Beginners) [easy to understand]
[ROS] (05) ROS Communication - Node, Nodes & Master
芝诺悖论的理解
The specific operation process of cloud GPU (Hengyuan cloud) training