当前位置:网站首页>Encoding format for x86
Encoding format for x86
2022-06-25 09:38:00 【ADA King】
1 x86 The encoding format of
x86 Coding with variable length , The main reason should be 8086 The performance of the machine is not high , The shorter the code, the better . and 8086 The encoding mode of is compared with x64 Simpler , And x64 compatible x86 code , therefore , The following description will be made by 8086 Keep talking about x64
1.1 8086 code
8086 Take the following encoding format

among opcode Is a must , Others are optional
opcode
opcode Before the format of 6 Bits indicate operations , after 2 It's divided into d or s as well as w position

Mod R/M

Mod R/M Indicates the addressing mode , The following table shows the types of addressing
| ModRM.mod | Addressing mode | describe |
|---|---|---|
| 00 | [base] | Memory addressing , Provide [base] Formal memory Addressing |
| 01 | [base+disp8] | Memory addressing , Provide [base+disp8] Formal memory Addressing |
| 10 | [base+disp16] | Memory addressing , Provide [base+disp32] Formal memory Addressing |
| 11 | register | Assignment between two registers |
First of all mod=11 Give an example to illustrate
First, formulate reg Encoding rules for domains , This rule applies to any mod The way
| REG | W=0 | W=1 |
|---|---|---|
| 000 | AL | AX |
| 001 | CL | CX |
| 010 | DL | DX |
| 011 | BL | BX |
| 100 | AH | SP |
| 101 | CH | BP |
| 110 | DH | SI |
| 111 | BH | DI |
Suppose the instruction is mov %sp %bp Then the instruction sequence is 89 e5, According to the above format
89 by opcode,e5 by ModRM, Yes 89 Analyze
1000,1001==>[1000,00] by opcode
==>[01] by DW, among W Express 16 The value of a
Yes e5 Analyze
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-oxZJsKYA-1655714796572)(./images/regreg.png)].
Let's say mod==00 And mod=01 For example
mod==00 Indicates that the access is directly based on the memory base address
R/M decoding 000 [BX+SI] 001 [BX+DI] 010 [BP+SI] 011 [BP+DI] 100 [SI] 101 [DI] 110 111 [BX]
SI Index register for source
DI Write registers for the purpose
These two registers are in 8086 There are special uses in , Not mentioned here , Don't go into
because ModR/M The executable operations in can be divided into
- Register -> Memory
- Memory -> Register
therefore , No matter how , As long as there is memory related data , It must be on r/m domain , And the simple register is put in Register in
The same can also mean mod=01 And mod=10, The decoded value only needs to look up the table
1.2 x86 Instruction code
x86 Series coding has always adhered to the concept of downward compatibility , At the same time, it also supports new registers and codes , The treatment method is in the original 8086 Add... To the instruction header above the encoding rules of prefix Domain , When the decoder reads the corresponding value in this field, it knows that the current value is x86 code ,x86 Coded prefix Values are as follows
| Encoding value | meaning |
|---|---|
| 66H | Change the default size of the data expected by the instruction , For example, by 16 Displacement 32 position |
| 67H | Change the default size of the address expected by the instruction , For example, by 16 Displacement 32 position |
| 2EH | CS register |
| 3EH | DS register |
| 26H | ES register |
| 64H | FS register |
| 65H | GS register |
| 26H | SS register |
| F3H | REP,REPE, Repeat instruction , The quantity is determined by ECX decision , When ECX=0 Stop when |
| F2H | Stop the cycle , When ZF Flag bit assignment |
| F0H | Ensure that instructions will have dedicated shared memory usage , Until the instruction is complete This ensures that in x86 When multiple processes are processed at the same time , Will not be interfered with in a single instruction operation |
Other parts are related to 8086 The coding logic is consistent , Only the length of the data is changed , Can be coded by looking up the table
1.3 x64 code
x64 Than x86 Not only are there more general-purpose registers 8 individual , More importantly, the data and address length can be extended to 64 position , therefore , Its code is also x86 More replication , then , Adhering to the principle of downward compatibility , The coding method is in the original prefix That's an increase from REX prefix grammar , Will be in x86 Under the prefix Renamed legacy prefix, This also means that when the instruction is decoded , If you come across x86 The head of the , Still in x86 To decode , And meet REX prefix Head time , with x64 To decode .
It is emphasized here that legacy prefix and REX prefix Share the same space .

x64 Maximum allowable 16 Byte instructions , But so far , The biggest is 15 Bytes
representative x64 The special prefix is
0100, WRXB
That is to say 4 Lead , Followed by WRXB Bit instruction , among
W: Express wide, If this is 1, The object of the operation is 64 position
R: Express Register, Used to extend the existing 8 General purpose registers to 16 A register , according to 8086 The coding rules are known , stay Mod R/M domain ,reg The value range bits of the field [0,7], If you add R Of [0,1], Then the whole value range can be extended to [0000B, 1111B] common 16 Elements
X: Express Extention, Used to extend SIB Of Index Domain ( I'll be right back SIB Analyze )
B: Used to extend Mod R/M Medium r/m Domain , So that the range of general-purpose registers can be from 8 Extended to 16 individual , And the access and storage are also from 8 Extended to 16 individual
The matching is shown in the figure below

example 1
Now in order to mov %rsp %rbp Give an example to illustrate
First, this is the transfer of values between registers , So we know mod==11, in addition , Registers use 64 Bit , therefore ,W=1, By disassembling the above assembly statements, it can be known that
48 89 e5 mov %rsp,%rbp
Disassemble the above sentence

Look up the register code table
_.Reg Register
----------------
0.000 RAX
0.001 RCX
0.010 RDX
0.011 RBX
0.100 RSP
0.101 RBP
0.110 RSI
0.111 RDI
1.000 R8
1.001 R9
1.010 R10
1.011 R11
1.100 R12
1.101 R13
1.110 R14
1.111 R15
You know R.100 The register represented is RSP, B.101 The register represented is RBP
In line with the front 8086 The coding rules of , It's just a prefix
example 2
Now let's do an example of memory access mov %rsp 10(%rbp)
adopt gcc and objdump The following output is obtained after
48 89 65 0a mov %rsp,0xa(%rbp)

You know R.100 The register represented is RSP, B.101 The register represented is RBP, Because the address is not [base + index*scale] Calculate , therefore SIB by 0, Offset for the 10.
example 3
Visiting and depositing mov %rsp (%rbp,%rax), from objdump The instructions are as follows
48 89 64 05 00 mov %rsp,0x0(%rbp,%rax,1)
You can see here , The destination value is M[%rbp + %rax *1 + 0], Analyze instruction values

First know reg=R.100 It means RSP
The target value needs to be calculated by looking up the table , And then calculate according to the instruction value
Now give the corresponding mod surface , Look up the table to get the corresponding operation
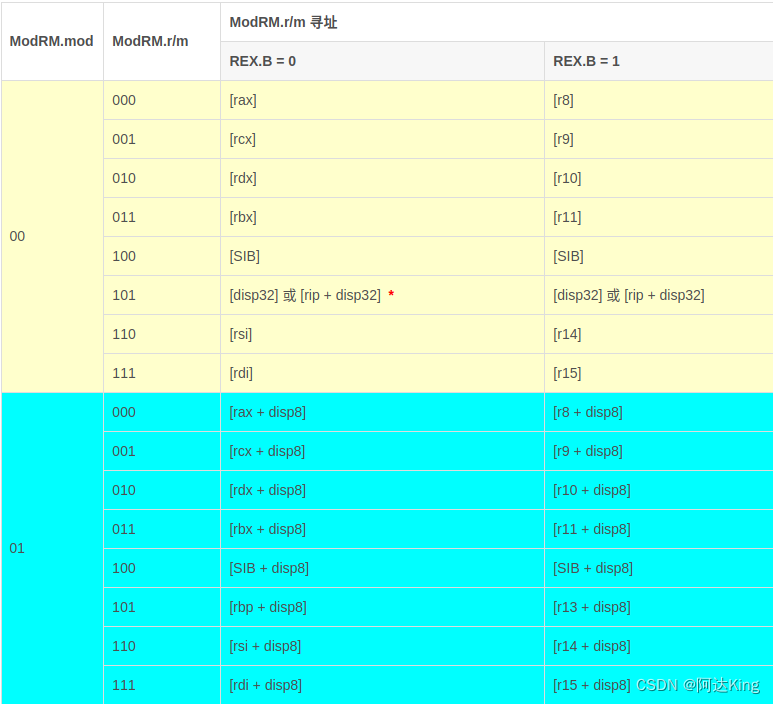
reg=B.100 by [SIB+disp8]
Obviously ,disp8=0,SIB The value of is 05H
according to SIB The definition of

among SS It means scale, Its value range is 1.2.4.8
| Encoded value (binary) | scale factor |
|---|---|
| 00 | 1 |
| 01 | 2 |
| 10 | 4 |
| 11 | 8 |
Index Indicates the number of the index register
base Indicates the number of the base address register
In this case , Its SIB The value of is 05H, in other words

SS by 0,index by 0 Number register (rax),base by 5 Number register (rbp), therefore , The calculated valid address is
effective_address = 1 * rax + rbp + 00
Meet the requirements of assembly language
To sum up
Transfer values between registers ,Mod by 11, And SIB,Disp And Imm No need
When making a deposit call ,Mod The range of values is {00,01,10},SIB For optional
If you simply perform constant offset on the base address , be SIB Unwanted
If variable addressing , be SIB need , And SIB Medium S The value range is
Encoded value
(binary)scale factor 00 1 01 2 10 4 11 8
completion Mod R/M Encoding table

Other common instructions
Because it is a common instruction , It usually operates on registers or memory alone , Therefore, the above model is not required , Instead, the method of directly giving the operation code , It often happens that you just 1 Bytes to complete the required operation .
push
With
push %rspFor example , according to objdump Printed results54 push %rspInquire about AMD 64 manual
push reg64Corresponding opcode50+rq, and rsp The register number of is 4pop
5c pop %rspInquire about AMD 64 manual
pop reg64Corresponding opcode58+rqcall
With the following C Program
int bar() { return 100; } int foo(){ int i = bar(); return i; } int main(){ int i = foo(); return i; }First use
gcc -STo view the generated assembly code.file "main.c" .text .globl bar .type bar, @function bar: .LFB0: .cfi_startproc endbr64 pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $100, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size bar, .-bar .globl foo .type foo, @function foo: .LFB1: .cfi_startproc endbr64 pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 subq $16, %rsp movl $0, %eax call bar movl %eax, -4(%rbp) movl -4(%rbp), %eax leave .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE1: .size foo, .-foo .globl main .type main, @function main: .LFB2: .cfi_startproc endbr64 pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 subq $16, %rsp movl $0, %eax call foo movl %eax, -4(%rbp) movl -4(%rbp), %eax leave .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE2: .size main, .-main .ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0" .section .note.GNU-stack,"",@progbits .section .note.gnu.property,"a" .align 8 .long 1f - 0f .long 4f - 1f .long 5 0: .string "GNU" 1: .align 8 .long 0xc0000002 .long 3f - 2f 2: .long 0x3 3: .align 8 4:You can see
call barAnd then use objdump Disassemble the instructions to see what the difference is
main.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <bar>: 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp 8: b8 64 00 00 00 mov $0x64,%eax d: 5d pop %rbp e: c3 retq 000000000000000f <foo>: f: f3 0f 1e fa endbr64 13: 55 push %rbp 14: 48 89 e5 mov %rsp,%rbp 17: 48 83 ec 10 sub $0x10,%rsp 1b: b8 00 00 00 00 mov $0x0,%eax 20: e8 00 00 00 00 callq 25 <foo+0x16> 25: 89 45 fc mov %eax,-0x4(%rbp) 28: 8b 45 fc mov -0x4(%rbp),%eax 2b: c9 leaveq 2c: c3 retq 000000000000002d <main>: 2d: f3 0f 1e fa endbr64 31: 55 push %rbp 32: 48 89 e5 mov %rsp,%rbp 35: 48 83 ec 10 sub $0x10,%rsp 39: b8 00 00 00 00 mov $0x0,%eax 3e: e8 00 00 00 00 callq 43 <main+0x16> 43: 89 45 fc mov %eax,-0x4(%rbp) 46: 8b 45 fc mov -0x4(%rbp),%eax 49: c9 leaveq 4a: c3 retqamong
call barThe order ise8 00 00 00 00 callq 25 <foo+0x16>Inquire about AMD 64 The manual shows that
CALL re/16off E8 iwcall The opcode of the instruction is E8,E8 Direct reading PC value , So you jump to bar function
The following value is the offset of the next instruction from the current instruction after the call ends ( Nothing here Mod and SIB, Because there is no need to calculate the location of memory access through registers ), The calculation formula of this offset is
displacement = destination address - address of next instructionamong displacement The big end approach is adopted , Should be converted to a small end expression , The following example is more obvious
#include <stdio.h> int main(void) { printf("Hello, world!\n"); printf("Hello, world!\n"); return 0; }objdump The result
/helloworld.c:3 804842c: 83 ec 0c sub $0xc,%esp 804842f: 68 f0 84 04 08 push $0x80484f0 8048434: e8 b7 fe ff ff call 80482f0 8048439: 83 c4 10 add $0x10,%esp /helloworld.c:4 804843c: 83 ec 0c sub $0xc,%esp 804843f: 68 f0 84 04 08 push $0x80484f0 8048444: e8 a7 fe ff ff call 80482f0 8048449: 83 c4 10 add $0x10,%espamong
8048434: e8 b7 fe ff ff call 80482f0The opcode for this instruction is
E8, followed by the relative offset that is computed by the following equation:destination address - address of next instruction.In this case, the relative offset of the first call is
80482f0 - 8048439 = FFFFFEB7, and the relative offset of the second call is80482f0 - 8048449 = FFFFFEA7.ret
Inquire about AMD 64 Test knowable
C3The actual implementation is shown in the figure

add,sub,mul
The three kinds of computing instructions involve register and memory access operations , The coding rules can be referred to mov,opcode Consult the manual , Let's say add Give instructions to explain
0: 48 01 c3 add %rax,%rbx 3: 48 03 04 25 0a 00 00 add 0xa,%rax a: 00 b: 48 01 03 add %rax,(%rbx) e: 48 01 04 18 add %rax,(%rax,%rbx,1) 12: 48 01 44 58 0a add %rax,0xa(%rax,%rbx,2)add %rax, %rbx
48 01 c3 add %rax,%rbx48 yes REX prefix, 01 yes opcode, c3 yes mod r/m, namely

R.000 yes rax
B.011 yes rbx
add 0xa,%rax
48 03 04 25 0a 00 00 add 0xa,%raxThe code is as shown in the figure

add %rax,(%rbx)
48 01 03 add %rax,(%rbx)
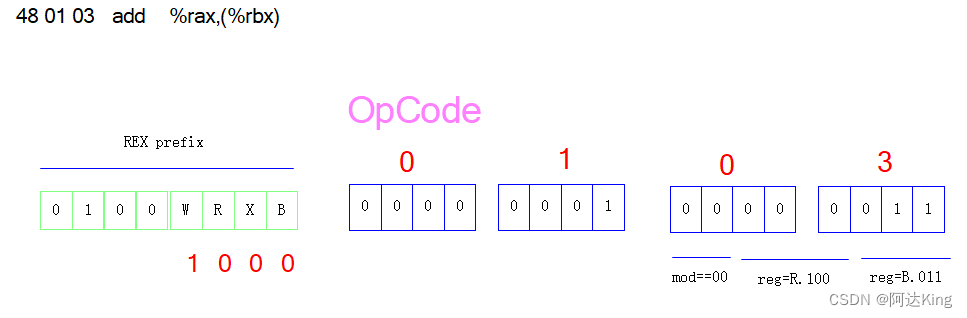
div
div It is a special instruction , The dividend of the instruction is placed in
RAXIn the register , The divisor is specified as a register or Memory address ( The experiment didn't work out )Take the following example to illustrate
48 f7 f0 divq %raxInquire about AMD64 The manual knows about division opcode yes
F7/6
High in the second byte 4 All bits are 1, low 4 Bit is the register number
1.4 Intel MMX technology
MMX The technology is Intel The company aims to enhance CPU In audio and video 、 Graphics and communications applications ,MMX Technology is following Intel386 processor ( Extend the architecture to 32 position ) And then to Intel The most important enhancement of the architecture . The instructions of these technologies can speed up the processing of relevant graphics 、 image 、 Application of sound, etc ,MMX Strengthen the lack of multimedia processing function , It can use its built-in multimedia instructions to simulate 3D Processing of drawings 、 MPEG Compression of / decompression , Stereo sound effects, etc , As long as the software supports MMX CPU, That is, it can replace these hardware interfaces to achieve the effect of multimedia .
MMX Technology is in CPU Specially joined for video signal (Video Signal), sound signal (Audio Signal) And image processing (Graphical Manipulation) And designed a set of basic 、 General purpose integer instructions 、 Single command 、 More data (SIMD) technology , It can be easily applied to various multimedia and communication applications .
1.5 SSE Instructions
SSE instructions are an extension of the SIMD execution model introduced with the MMX technology. SSE instructions are divided into four subgroups:
Most involve 128 position Memory variable Operation of the , The first address of the memory variable must be aligned 16 byte , That is to say Memory address low 4 Position as 0, Otherwise it will cause CPU abnormal , Causes instruction execution to fail , This error compiler Do not check .
边栏推荐
- 浅谈Mysql底层索引原理
- Online notes on Mathematics for postgraduate entrance examination (8): Kego equations, eigenvalues and eigenvectors, similarity matrix, quadratic series courses
- Creo makes a mobius belt in the simplest way
- Data-driven anomaly detection and early warning of item C in the May 1st mathematical modeling competition in 2021
- [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate
- 1、 Construction of single neural network
- matplotlib matplotlib中axvline()和axhline()函数
- matplotlib 简单逻辑回归可视化
- Online notes on Mathematics for postgraduate entrance examination (9): a series of courses on probability theory and mathematical statistics
- Nano data World Cup data interface, CSL data, sports data score, world cup schedule API, real-time data interface of football match
猜你喜欢

Format analysis and explanation of wav file

Oracle one line function Encyclopedia

Matplotlib decision boundary drawing function plot in Matplotlib_ decision_ Boundary and plt Detailed explanation of contour function

Reza RA series - development environment construction
matplotlib matplotlib中plt.axis()用法

Matplotlib plt grid()

How to delete a blank page that cannot be deleted in word
x86的编码格式

Prepare for the 1000 Android interview questions and answers that golden nine silver ten must ask in 2022, and completely solve the interview problems

Cassava tree disease recognition based on vgg16 image classification
随机推荐
vscode试图过程写入管道不存在
Nano data World Cup data interface, CSL data, sports data score, world cup schedule API, real-time data interface of football match
[2020 cloud development + source code] 30 minutes to create and launch wechat applet practical project | zero cost | cloud database | cloud function
[wechat applet full stack development course] course directory (mpvue+koa2+mysql)
How to delete a blank page that cannot be deleted in word
[buuctf.reverse] 117-120
Online notes on Mathematics for postgraduate entrance examination (8): Kego equations, eigenvalues and eigenvectors, similarity matrix, quadratic series courses
Specific usage of sklearn polynomialfeatures
Wechat official account can reply messages normally, but it still prompts that the service provided by the official account has failed. Please try again later
Analysis on the thinking of 2022 meisai C question
【mysql学习笔记20】mysql体系结构
How much money have I made by sticking to fixed investment for 3 years?
JMeter interface test, associated interface implementation steps (token)
通过客户经理的开户二维码开股票账户安全吗?
Where is safe for FTSE A50 to open an account
瑞吉外卖项目(二)
Are the top ten securities companies at great risk of opening accounts and safe and reliable?
[smart agriculture program] smart agriculture small program project is currently popular.
Japanese online notes for postgraduate entrance examination (9): composition template
[learn C from me and master the key to programming] insertion sort of eight sorts