当前位置:网站首页>[intensive reading of papers] grounded language image pre training (glip)
[intensive reading of papers] grounded language image pre training (glip)
2022-07-27 14:23:00 【joyce_ peng】
One . background
https://arxiv.org/abs/2112.03857
https://github.com/microsoft/GLIP

The task of this paper is phrase grounding, Belong to visual grounding A kind of .phrase grounding My task is to input sentences and pictures , Frame all the objects mentioned in the sentence .visual grounding Other tasks and details can be referred to
https://zhuanlan.zhihu.com/p/388504127
GLIP You can do both target detection and grounding,
- object detection :
In the field of amplification target detection SOTA,zero-shot It is better to , You can also do zero-shot Target detection task .
Compared with conventional target detection tasks, it has rich semantics . - grounding:
And Convention grounding Compared with tasks, we can do target detection tasks .
Two 、 contribution
contribution
- Target detection and phrase grounding Tasks are unified for pre training
- Expand visual semantics
- Strong transfer learning ability
performance
- 27M Training on related data . It has strong zero sample and small sample migration performance in target recognition tasks
- Zero-shot:coco val On 49.8AP,LVIS val On 26.9AP
- After fine tuning :COCO val On 60.8AP
- The downstream 13 Target detection tasks ,1 A sample of GLIP It can be done with Dynamic Head Compete with
3、 ... and 、 Method
3.1 Method 1: Detection and grounding Unified tasks

1. background:
For the detection data set :
Enter the tag name during training (person、hairdryer)、 box 、 picture .
Input pictures during the test , Predict box and tag names .
The training process is as follows :
2. background as grounding:
groudning The input to the model is the phrase 、 Boxes and pictures of nouns in phrases .
take object Model to grounding The way to : adopt prompt To convert tag names into phrases .
Such as coco Yes 80 A label , take 80 Tags are connected by commas , Add “Detect:”, To form short sentences .
The formula 2 Become a formula 3 In the process of ,T The size of will change , from Nc become NM
structure token: In the flow chart above ,M(sub-word tokens) Always better than phrase format c many , There are four reasons 1) Some phrases take up more than toeken Location , such as traffic light.2) Some phrases are separated into sub words, such as toothbrush Divided into tooth#, #brush.3) Some are added token, Like a comma ,Deteckt etc. ,4) The end will add [NoObj] Of token. During training ,phrase If it is a positive example , Multiple subwords They are all positive examples . When testing, there are multiple token The average of pro As a phrase probability.
3. detection and grounding linkage : By the above method , It can be used grounding Model to pre train detection tasks , So you can migrate GLIP The model makes zero-shot Detection of
3.2 Method 2: deep fusion, The combination of vision and language

fusion Some formulas are as follows :
O0 It's vision backbone Of feature, P0 It's the text backbone Of feature
X-MHA(cross-modality multi-head attention module)
L yes DyHead in DyHeadModules Number ,BERT Layer Add for .
attention Some are common in multimodal , such as co-attention、guided attention etc. . Refer to multimodal attention Other optimization .
DeepFusion advantage :
Improved phrase grounding effect
Make visual features language-aware
3.3 Method 3: Pre training with rich semantic data
grounding The semantics of data sets are very rich , Target detection does not exceed 2000 Categories , however grounding Data sets, such as Flickr30K It includes 4.4w Different phrases , The magnitude is different .
How to amplify grounding data :
- stay gold data(det+grounding) Train teachers GLIP
- Use this teacher model to predict 24M web image-text data , adopt NLP Analyze noun phrases , There is 5840 Different noun phrases
- The student model is gold data And fake tags grounding Training on data
Amplification effect :
The effect of student model is better than that of teacher model , For example, for some words ,vaccine The teacher model may not predict , But it can be predicted a small vial,subwords Right , whole phrase Will be right . When giving students unsupervised data of the model , Can be a small vial of vaccine The whole label is given to the student model as a learning label .
Four 、 experimental result

FourODs(2.66M data ) yes 4 A collection of detection data sets , Include objects365、OpenImages、VG Data sets ( except coco)、ImageNetBox.
GoldG+ The dataset includes 1.3M Data sets , Include Flickr30K、VG caption、GQA.
GoldG The dataset is GoldG+ In addition to the coco Data sets
4.1 The migration effect is on the detection data set
zero-shot stay coco On :
- Graphic data sets do not bring improvement
- C and B Greater than the improvement
- Objects365 It includes coco Of 80 individual
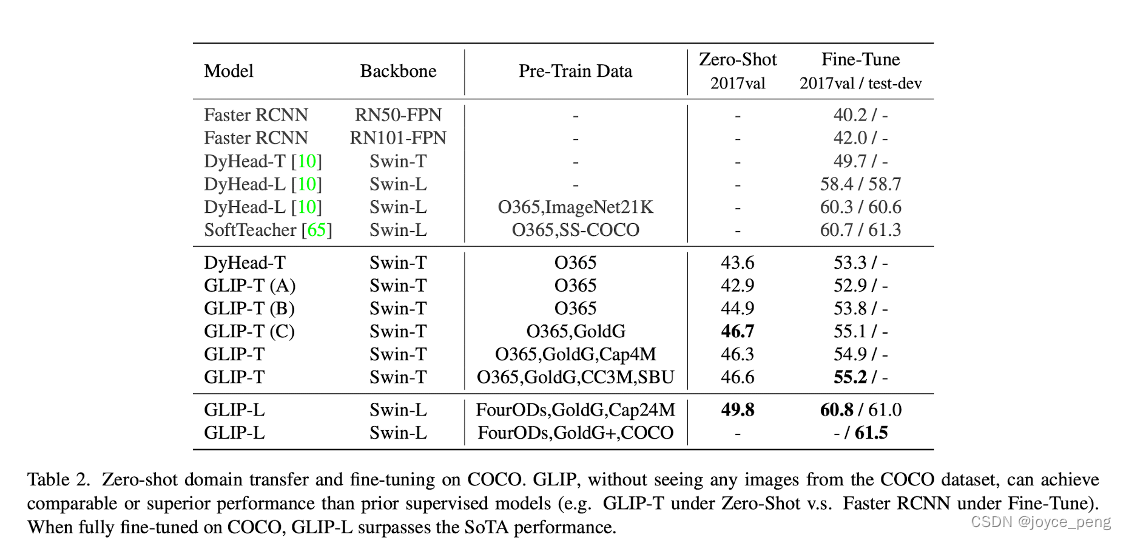
stay LVIS On the effect :
LVIS: Large scale fine-grained vocabulary level markup data set ,1000+ Category , Pineapple dices in pizza are also marked
Gold grounding It works (model C vs model B)
4.2 stay grounding On dataset
Flick 30k: Graphic matching grounding Data sets ,goldG This data set is included in 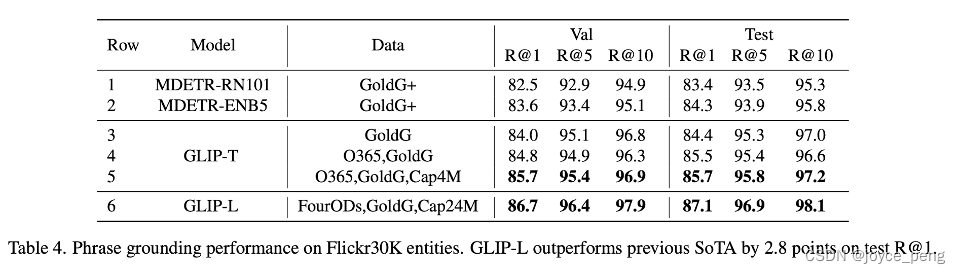
4.3 Ablation Experiment - Detect data set impact
O365: 0.66M
GoldG: 0.8M
FourODs: 2.66M
But it's not O365+GoldG The effect is better 
4.4 other
If the positioning is not good , You can add prompt words to help better locate , The figure below adds flat and round
边栏推荐
- watch VS watchEffect
- 线程知识总结
- A Keypoint-based Global Association Network for Lane Detection
- 次小生成树【模板】
- Research on automatic classification of electronic medical records based on unbalanced data
- 进程间通信
- [related contents of multithreading]
- Rtl8762dk environment construction (I)
- MySQL advanced II. Logical architecture analysis
- SLAM综述阅读笔记六:基于图像语义的SLAM调研:移动机器人自主导航面向应用的解决方案 2020
猜你喜欢
![[note] logistic regression](/img/2b/07cc3c26b1b34fbf2f09edaa33668e.jpg)
[note] logistic regression

How to view revenue and expenditure by bookkeeping software

万字详解 Google Play 上架应用标准包格式 AAB

知识关联视角下金融证券知识图谱构建与相关股票发现

Excellent basic methods of URL parsing using C language

Slam overview Reading Note 7: visual and visual intangible slam: state of the art, classification, and empirical 2021

592. Fraction addition and subtraction
Rtl8762dk environment construction (I)
Motion attitude control system of DOF pan tilt based on stm32
SLAM综述阅读笔记四:A Survey on Deep Learning for Localization and Mapping: Towards the Age of Spatial 2020
随机推荐
Navicate报错access violation at address 00000000
达科为生物IPO过会:年营收8.37亿 吴庆军父女为实控人
Document translation__ Tvreg V2: variational imaging method for denoising, deconvolution, repair and segmentation (part)
uniapp的request数据请求简单封装步骤
HDU4565 So Easy!【矩阵连乘】【推导】
进程间通信
HDU4496 D-City【并查集】
Golang excellent open source project summary
阿里最新股权曝光:软银持股23.9% 蔡崇信持股1.4%
DVWA全级别通关教程
开源版思源怎么私有部署
Named entity recognition of Chinese electronic medical records based on Roberta WwM dynamic fusion model
Chapter 3 business function development (add clues and remarks, and automatically refresh the added content)
为什么会出现Script file ‘D:\Anaconda3\envs\paddle_env\Scripts\pip-script.py‘ is not present.
Charles tutorial
@Repository详解
Travel notes from July 11 to August 1, 2022
机场云商sign解析
np.arange()和 range()的用法及区别
2022 Niuke multi School II_ E I