当前位置:网站首页>带你认识图数据库性能和场景测试利器LDBC SNB
带你认识图数据库性能和场景测试利器LDBC SNB
2022-06-27 15:29:00 【华为云开发者联盟】
摘要:本文主要介绍基于交互式查询所用的数据生成器(下文简称Datagen),及LDBC SNB数据如何在华为图引擎服务GES中应用。
本文分享自华为云社区《【图数据库性能和场景测试利器LDBC SNB】系列一:数据生成器简介 & 应用于GES服务》,作者:闹闹与球球
本文的主要内容包括:基于交互式查询所用的数据生成器(下文简称Datagen)介绍,及LDBC SNB数据如何在华为图引擎服务GES中应用。LDBC SNB所预设的节点和关系、数据生成器和系统的测试用例,形成了一个逻辑自恰的数据“武林”,以ldbc snb为测试标准的图数据库产品,就像是行走于其中的侠客们,都得遵循同一套“武林规矩”(测试用例),究竟谁能击败各方高手,问鼎盟主呢?
LDBC SNB概述
LDBC SNB,全称The Linked Data Benchmark Council’s Social Network Benchmark,官网地址:http://ldbcouncil.org。LDBC是一个致力于发展图数据管理的产业联盟组织,它开发了一套标准的benchmarks,用于系统地衡量不同图数据库产品的功能和性能。SNB是基于社交网络场景开发的一组benchmarks,由交互式场景(Interactive workload)和商业智能场景(Business Intelligence workload)组成。
LDBC SNB 项目包括3个组件:数据生成器(Datagen)、测试驱动程序(Test Driver,用于执行Benchmark的测试)和测试用例实现(Reference Implementation,目前提供了基于Cypher(Neo4j)和SQL(PostgreSQL)两种查询语言的测试用例实现)
LDBC SNB有两种工作模式:
1、交互式查询(Interactive workload),适用于事务性的在线查询场景,比如基础的增删改查、shortestpath、多跳等;
2、商业智能 (Business Intelligence workload),适用于根据企业业务场景制定的复杂查询和大规模离线图分析等场景。
在不同的工作模式下,【Datagen】、【Test Driver】 和【测试用例实现】都是不同的。
章节概览
一、Datagen介绍
- 数据模型
- Data Types
- Data Schema
- Datagen的安装和运行流程
- Datagen的参数设置
- 常规参数设置
- 规模因子
- 序列化模式
二、LDBC SNB在GES中的应用
一、Datagen介绍
数据模型
Data Types
Datagen支持的属性datatype如下, 每种属性都支持单值和列表两种模式。
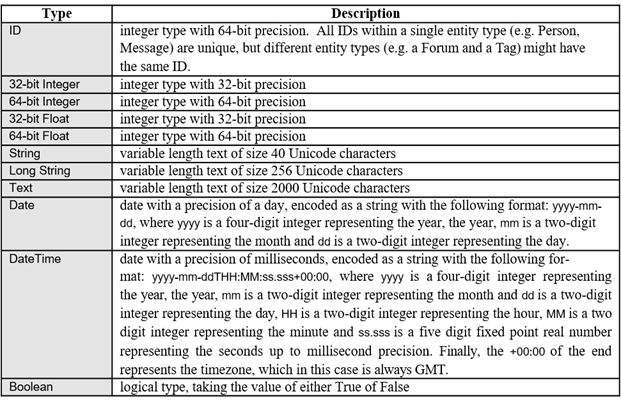
(截图来源于官官方文档http://ldbcouncil.org/ldbc_snb_docs/ldbc-snb-specification.pdf)
Data Schema

(截图来源于官方文档http://ldbcouncil.org/ldbc_snb_docs/ldbc-snb-specification.pdf)
如图所示,Datagen生成的数据有预设的一套图模型,包括:
8种节点:organization & place & tag & tagClass & person & forum & post & comment
15种关系,如下表:

这些预设的节点和关系,形成了一个逻辑自恰的数据“武林”,以ldbc snb为测试标准的图数据库产品,就像是行走于其中的侠客们,都得遵循同一套“武林规矩”(测试用例),究竟谁能击败各方高手,问鼎盟主呢?且拭目以待吧。
安装和运行流程
在Interactive Workload模式下,Datagen的底座为hadoop;在BI Workload模式下,底座为Spark。
本次调研主要使用基于伪分布式hadoop的Datagen。
1)下载基于hadoop的ldbc datagen
https://github.com/ldbc/ldbc_snb_datagen_hadoop
2)使用伪分布式的hadoop
cd ldbc_snb_datagen_hadoop/cp params-csv-composite.ini params.iniwget http://archive.apache.org/dist/hadoop/core/hadoop-3.2.1/hadoop-3.2.1.tar.gztar xf hadoop-3.2.1.tar.gzexport HADOOP_CLIENT_OPTS="-Xmx2G"# set this to the Hadoop 3.2.1 directoryexport HADOOP_HOME=`pwd`/hadoop-3.2.1./run.sh3)编译时出现缺失的jar包问题解决(报错如下)

解决方案:
从windows环境下载https://simulation.tudelft.nl/maven/dsol/dsol-xml/1.6.9/

手动安装缺失的jar包到本地的maven仓库
mvn install:install-file -Dfile=dsol-xml-1.6.9.jar -DgroupId=dsol -DartifactId=dsol-xml -Dversion=1.6.9 -Dpackaging=jar4)再次运行,完成生成
sh run.sh生成的数据文件存储在${outputDir}/social_network。
参数设置
(以下参数介绍均省略了前缀“ldbc.snb.datagen.”,即参数的完整格式为“ldbc.snb.datagen.xxx”)
1)常规参数

2)规模因子
LDBC SNB支持生成不同规模的图数据集,generator.scaleFactor参数各取值对应的点边数目如下表:

(截图来源于官方文档http://ldbcouncil.org/ldbc_snb_docs/ldbc-snb-specification.pdf)
3)序列化模式
Datagen主要有4种Csv文件的序列化模式,所生成的数据格式各有不同。
CsvBasic
基础序列化模式,每种节点、节点和节点之间的关系都有独立的csv文件,如图一所示:

图一 每种节点、节点和节点之间的关系都有独立的csv文件,其中person_xx.csv均为person节点的属性数据。
若某个属性有多个取值,例如person的email属性有多个值,则将person的email记录单独生成一个csv文件,并将多个email分成多行记录展示,如图二所示:

图二 person的email属性单独存储,并在多个email分成多条记录展示
CsvComposite(此模式生成的数据,与GES支持的Csv格式相似度最高)
在CsvBasic的基础上,将有多个值的属性和其他属性合并为一个记录,如图三;并将多个值进行合并(以list的格式,分号分隔),如图四;

图三 person节点的属性记录合并为person_0_0.csv

图四 language和email两个list属性合并在一行
CsvMergeForeign
在CsvBasic基础上,如果节点间关系是1对多的,则将关系作为外键合并入节点的属性文件中展示,如图五

图五 将comment-hasCreator->person、comment-isLocatedIn->place、comment-replyOf->post、comment-replyOf->comment关系与comment属性文件合并
CsvCompositeMergeForeign
是CsvComposite和 CsvMergeForeign的结合,既合并了list属性,又将一对多关系进行了压缩表示,如图六

图六 place列表示person-isLocatedIn->place关系的外键表示,同时language和email以list形式展示
各序列化模式对应的参数值如下
CsvBasic
- ldbc.snb.datagen.serializer.dynamicActivitySerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.activity.CsvBasicDynamicActivitySerializer
- ldbc.snb.datagen.serializer.dynamicPersonSerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.person.CsvBasicDynamicPersonSerializer
- #ldbc.snb.datagen.serializer.staticSerializer:ldbc.snb.datagen.serializer.snb.csv.staticserializer.CsvBasicStaticSerializer
CsvComposite
- ldbc.snb.datagen.serializer.dynamicActivitySerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.activity.CsvCompositeDynamicActivitySerializer
- ldbc.snb.datagen.serializer.dynamicPersonSerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.person.CsvCompositeDynamicPersonSerializer
- ldbc.snb.datagen.serializer.staticSerializer:ldbc.snb.datagen.serializer.snb.csv.staticserializer.CsvCompositeStaticSerializer
CsvMergeForeign
- ldbc.snb.datagen.serializer.dynamicActivitySerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.activity.CsvMergeForeignDynamicActivitySerializer
- ldbc.snb.datagen.serializer.dynamicPersonSerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.person.CsvMergeForeignDynamicPersonSerializer
- ldbc.snb.datagen.serializer.staticSerializer:ldbc.snb.datagen.serializer.snb.csv.staticserializer.CsvMergeForeignStaticSerializer
CsvCompositeMergeForeign
- ldbc.snb.datagen.serializer.dynamicActivitySerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.activity.CsvCompositeMergeForeignDynamicActivitySerializer
- ldbc.snb.datagen.serializer.dynamicPersonSerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.person.CsvCompositeMergeForeignDynamicPersonSerializer
- ldbc.snb.datagen.serializer.staticSerializer:ldbc.snb.datagen.serializer.snb.csv.staticserializer.CsvCompositeMergeForeignStaticSerializer
二、LDBC SNB在GES中的应用
Datagen生成的数据集与GES格式有以下3点区别
- 不同label的点id之间可能存在id重复的现象;
- knows关系是双向的;
- 没有label列。
使用DatagenToGES数据转换脚本(基于CsvComposite序列化模式)可以将LDBC数,需在python3.6环境下运行。
DatagenTOGES脚本有如下功能:
- 将8种节点类型映射为1-8个数字前缀,将原id转换为以数字前缀为开头、长度为20bytes的新id,解决不同label的点之间id重复的问题;
- 增加knows边文件的反向边数据;
- 增加label列。
转换前文件格式(CsvComposite序列化模式):


转换后文件格式:
DatagenToGES转换规模因子为100的大规模数据集用时约半个小时。
数据转换脚本核心代码片段:

在GES中导入转换后的LDBC SNB(示例数据为SF0.1),并执行PageRank算法,效果如下图:

边栏推荐
- Luogu_ P1007 single log bridge_ thinking
- 2022年最新《谷粒学院开发教程》:8 - 前台登录功能
- Cesium uses mediastreamrecorder or mediarecorder to record screen and download video, as well as turn on camera recording. [transfer]
- Vscode uses yapf auto format to set the maximum number of characters per line
- 专用发票和普通发票的区别
- R language error
- Beginner level Luogu 1 [sequence structure] problem list solution
- Eolink launched a support program for small and medium-sized enterprises and start-ups to empower enterprises!
- [issue 18] share a Netease go classic
- Programming skills: script scheduling
猜你喜欢

Programming skills: script scheduling

How is the London Silver point difference calculated
![[digital signal processing] discrete time signal (analog signal, discrete time signal, digital signal | sampling leads to time discrete | quantization leads to amplitude discrete)](/img/80/28d53985d56d64ca721b26e846c667.jpg)
[digital signal processing] discrete time signal (analog signal, discrete time signal, digital signal | sampling leads to time discrete | quantization leads to amplitude discrete)

PSS:你距离NMS-free+提点只有两个卷积层 | 2021论文

CAS之比较并交换

Creation and use of static library (win10+vs2022

一场分销裂变活动,不止是发发朋友圈这么简单!
![Beginner level Luogu 2 [branch structure] problem list solution](/img/53/d7bf659f7e1047db4676c9a01fcb42.png)
Beginner level Luogu 2 [branch structure] problem list solution

Atomic operation class
2022-2-15 learning the imitated Niuke project - Section 5 shows comments
随机推荐
Strong, weak, soft and virtual references of ThreadLocal
【170】PostgreSQL 10字段类型从字符串修改成整型,报错column cannot be cast automatically to type integer
我想买固收+产品,但是不了解它主要投资哪些方面,有人知道吗?
专家:让你低分上好校的都是诈骗
AbortController的使用
Can the teacher tell me what the fixed income + products are mainly invested in?
[170] the PostgreSQL 10 field type is changed from string to integer, and the error column cannot be cast automatically to type integer is reported
CNN convolutional neural network (the easiest to understand version in History)
Pychart installation and setup
[digital signal processing] discrete time signal (analog signal, discrete time signal, digital signal | sampling leads to time discrete | quantization leads to amplitude discrete)
Use of abortcontroller
Markdown syntax
What are the characteristics of fixed income + products?
SQL parsing practice of Pisa proxy
Expert: those who let you go to a good school with a low score are all Scams
洛谷_P1002 [NOIP2002 普及组] 过河卒_dp
NFT双币质押流动性挖矿dapp合约定制
Scrapy framework (I): basic use
设计原则和思想:设计原则
Design of electronic calculator system based on FPGA (with code)