当前位置:网站首页>[sca-cnn interpretation] spatial and channel wise attention
[sca-cnn interpretation] spatial and channel wise attention
2022-06-13 00:38:00 【AI bacteria】

Abstract
Visual attention has been successfully applied to structural prediction tasks , Such as visual subtitles and question answering . The existing visual attention models are generally spatial , Attention is modeled as spatial probability , The effect of the spatial probability on the encoding of the input image CNN And reweighted the last convolution feature map . However , We think , This kind of spatial attention does not necessarily conform to the attention mechanism —— A dynamic feature extractor that combines contextual gaze over time , because CNN Is characterized by spatial 、 Channeled and multilevel . In this paper , We introduce a new convolutional neural network , be called SCA-CNN, It's in CNN It combines spatial and channel orientation concerns . In the image caption task ,SCA-CNN Dynamically adjust sentence generation context in multi-level feature mapping , Where is the encoded visual attention ( namely , Multiple levels of attention to spatial location ) And what it is ( namely , Pay attention to the passage ). We are working on three benchmark image caption datasets :Flickr8K、Flickr30K and MSCOCO On the proposed SCA-CNN The architecture is evaluated . According to observation ,SCA-CNN Its performance is obviously superior to the most advanced image caption method based on visual attention .
One 、 introduction
Visual attention has been proved to be effective in various structural prediction tasks , Such as images / Video captioning and visual question answering . Its success is mainly due to a reasonable assumption , That is, human vision does not tend to process the whole image at once ; contrary , One pays attention to specific parts of the whole visual space only when and where it is needed . To be specific , Attention is not encoding images into static vectors , It allows the image features to evolve from the sentence context . In this way , Visual attention can be considered as a dynamic feature extraction mechanism , It combines contextual gaze over time .
In this paper , We will make full use of CNN Three features of visual attention based image captioning . especially , We propose a novel convolutional neural network based on spatial and channel attention , be called SCA-CNN, It learns to focus on multiple layers 3D Each feature entry in the feature map . chart 1 The motivation of introducing channel attention into multi-layer feature mapping is explained . First , Because the channel feature mapping is essentially the detection response mapping of the corresponding filter , Therefore, channel attention can be seen as a process of selecting semantic attributes according to the needs of sentence context . for example , When we want to predict the cake , Pay attention to the direction of our passage ( for example , stay Conv5 3/Conv5 4 In the characteristic diagram ) According to the cake 、 fire 、 Semantics such as light and candle shape assign more weight to the channel direction feature map generated by the filter . secondly , Because the feature map depends on its lower level feature map , Naturally, attention will be paid on many levels , Thus, visual attention to multiple semantic abstractions can be obtained . for example , It is useful to emphasize lower level channels corresponding to more basic shapes , Such as the array and cylinder that make up the cake .
We have three famous image captioning benchmarks :Flickr8K、Flickr30K and MSCOCO The proposed SCACNN The effectiveness of the . stay BLEU4 in ,SCA-CNN Can significantly exceed the spatial attention model 4.8%. in summary , We propose a unified SCA-CNN frame , To effectively integrate CNN Space in features 、 Channel and multi-layer visual attention , For image captions . especially , A new spatial and channel attention model is proposed . The model is universal , Therefore, it can be applied to any CNN Any layer in the architecture , For example, popular VGG[25] and ResNet[8].SCA-CNN Help us better understand CNN The evolution of features in the process of sentence generation .
Two 、 Related work
We are interested in the use of neural images / Video subtitles (NIC) And visual Q & A (VQA) The visual attention model used in the codec framework is of interest , This is in line with the recent trend of linking computer vision and natural language .NIC and VQA Groundbreaking work using CNN The image or video is encoded as a static visual feature vector , Then send it to RNN To decode language sequences such as subtitles or answers .
However , Static vectors do not allow image features to adapt to the sentence context at hand . Inspired by the attention mechanism introduced in machinetranslation , Decoding dynamically selects useful source language words or subsequences to translate into the target language , Visual attention model in NIC and VQA Has been widely used in . We classify these attention-based models into the following three areas , They inspire our SCA-CNN.
Xu Et al. Proposed the first visual attention model of image capture . in general , They used the method of selecting the most likely areas of interest “ hard ” aggregate , Or by focusing on the weighted average spatial features “ soft ” aggregate . as for VQA, Zhu et al “ soft ” Attention merges image region features . In order to further refine the spatial attention , Yang et al. Studied spatial attention . Xu et al. Used a stacked spatial attention model , The second attention is based on the attention characteristic graph of the first attention modulation . What's different from them is , Our multi-level focus applies to CNN On multiple levels . A common drawback of the above spatial models is that they usually resort to weighted aggregation on the feature map of interest . therefore , Spatial information will inevitably be lost . More serious , Their attention is focused only on the last layer , There? , The receptive field will be very large , And the difference between each receptive field area is very small , The spatial attention is not significant .
In addition to spatial information ,You They also put forward their own views , Proposed in NIC Select semantic concepts in , The image feature is the confidence vector of the attribute classifier . Jia et al. Used the correlation between images and subtitles as the global semantic information to guide LSTM Make sentences . However , These models require external resources to train these semantic attributes . stay SCA-CNN in , Each filter core of the convolution layer acts as a semantic detector . therefore ,SCA-CNN Channel attention is similar to semantic attention .
3、 ... and 、 Space and channel attention
3.1 summary
We use the popular codec framework to generate image captions , among CNN First, the input image is encoded into a vector , then LSTM Decode the vector into a sequence of words . Pictured 2 Shown ,SCA-CNN Through multi-layer channel attention and spatial attention, the original CNN The multi-layer feature map adapts to the sentence context .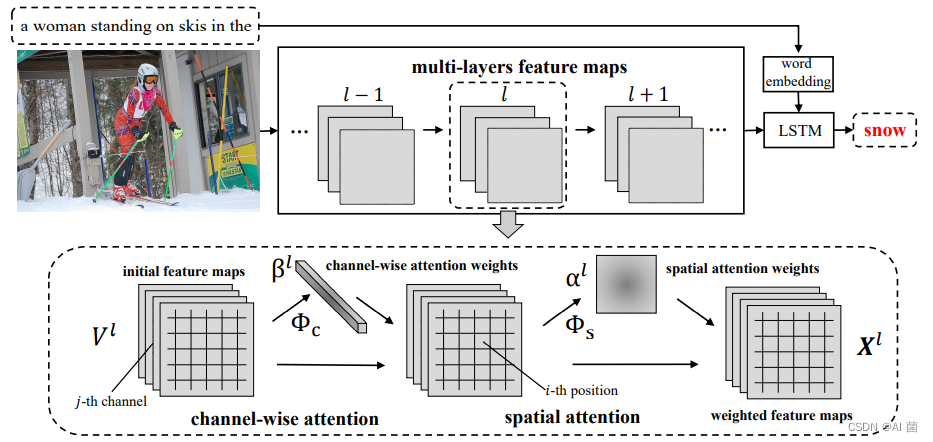
Formally , Suppose we want to generate the first... Of the image title t Word . Now? , We are LSTM Memory ht−1∈Rd The last sentence context is encoded in , among d Is the hidden state dimension . stay l layer , Space and channel direction of interest weights γ yes hT−1 And the current cnn features V1 Function of . therefore ,SCA-CNN Use attention weights in a circular and multi-layered manner γ To modulate VL, as follows :
among ,x1 It's a modulation feature ,Φ(·) Will be on the 3.2 Section and section 3.3 The spatial and channel oriented attention functions described in detail in section ,v1 It is the characteristic graph output from the previous convolution , for example , Followed by the merger 、 Convolution after down sampling or convolution [25,8],f(·) It's modulation cnn A linear weighting function of features and weights of interest . Compared with the existing popular attention based weight [34] The modulation strategies that summarize all the visual features are different , function f(·) Multiply by element... Is applied . up to now , We are ready to generate the... In the following way t Word :
among ,L Is the total number of conversion layers ;pt∈R|D| It's a probability vector ,D Is a predefined dictionary that includes all subtitle words .
3.2 Spatial attention
Generally speaking , Subtitle words only involve part of the image . for example , In the figure 1 in , When we want to predict the cake , Only the image area containing the cake is useful . therefore , Applying global image feature vectors to generate subtitles may lead to suboptimal results due to uncorrelated regions . Spatial attention mechanism attempts to pay more attention to semantic related areas , Instead of considering each image region equally . Without losing generality , We discard hierarchical superscripts l. We flatten the original V The width and height of V=[v1,v2,…,Vm], among vi∈Rc and m=W·H. We can think of a through-hole as the i Visual features of the positions . At a given previous time step LSTM Hidden state ht−1 Under the circumstances , We use a single-layer neural network , And then use Softmax Function to generate the attention distribution on the image area α. Here is the spatial attention model Φ The definition of :

3.3 Channel attention
Be careful , The formula (3) The spatial attention function in still needs visual features V To calculate the spatial attention weight , But visual features for spatial attention V It's not really based on attention . therefore , We introduce a channel based attention mechanism to focus on features V. It is worth noting that , Every CNN The filter acts as a pattern detector , and CNN Each channel of the feature map in is the response activation of the corresponding convolution filter . therefore , Applying the attention mechanism in a channelized way can be seen as a process of selecting semantic attributes .
Concerns about access , Let's start with V Remodel as U, also U=[U1,U2,…,UC], among UI∈RW×H Representation feature mapping V Of the i Channels , and C Is the total number of channels . then , We apply average pooling to each channel , To obtain channel characteristics v:
Where scalar vi It means No i A vector of channel features ui Average value . After the definition of spatial attention model , Channel based attention model Φ It can be defined as follows :
3.4 Mixed attention mechanism
According to the different implementation sequence of channel attention and spatial attention , There are two models that contain both attention mechanisms . We distinguish these two types as follows :
passageway - Spatial attention . The first type is called a channel - Space (C-S), Apply channel attention before spatial attention .C-S Type of flow chart is shown in Figure 2 Shown . First , In a given initial characteristic graph V Under the circumstances , We use channel based attention weights Φ To get the attention weight of the channel β. adopt β and V The linear combination of , We get a channel weighted feature map . Then the channel weighted feature map is fed back to the spatial attention model Φ, Get the weight of spatial attention α. Get two attention weights α and β after , We can V、β,α Feed to the modulation function f To calculate the modulation characteristic diagram X. All processes are summarized as follows :
Space - Channel attention . The second type is called SpatialChannel(S-C), Is a model that first implements spatial attention . about S-C type , In a given initial characteristic graph V Under the circumstances , We first use spatial attention Φ To gain spatial attention weight α. be based on α、 Linear function fs(·) And the direction of the channel Φc, We can follow C-S Type of recipe to calculate modulation characteristics X:
Four 、 experiment
We will verify the proposed by answering the following questions SCACNN Effectiveness of image caption framework :
- First of all , Pay attention to whether the channel is effective ? Does it improve spatial attention ?
- second , Is multi-level attention effective ? Compared with other most advanced visual attention models ,SCA-CNN How do you behave ?
4.1 Data sets and evaluation criteria
We conducted experiments on three famous benchmarks :
- 1)Flickr8k: contain 8000 A picture . According to its official split , It chooses 6000 Images for training ,1000 I want to verify it with two images ,1000 I want to test this image ;
- 2)Flickr30k: contain 31000 A picture . In the absence of a formal split , In order to make a fair comparison with the previous work , We report the results of publicly available splits used in previous work . In this split ,29,000 Images for training ,1,000 Images are used to verify ,1,000 Images are used to test
- 3)MSCOCO: The training set contains 82,783 Images , The validation set contains 40,504 Images , The test set contains 40,775 Images . because MSCOCO The basic facts of the test set are not available , Therefore, the validation set is further divided into validation subsets for model selection and test subsets for local experiments . This split followed , It uses the whole 82,783 Training set images for training , And select from the official verification set 5,000 Images are verified and 5,000 Two images are tested . For sentence preprocessing , We follow the public code 1. We use BLEU([email protected],[email protected],[email protected],[email protected])、 A shooting star (MT)、 Cider (CD) And rouge -L(RG) As an evaluation indicator . In short , For all four measures , They measure n The consistency of meta grammar in the generated sentences and basic fact sentences , This consistency is determined by n The significance and rarity of meta grammar are used to weight . meanwhile , These four indicators can be passed MSCOCO Subtitle evaluation tool 2 Directly calculate . And our source code is publicly available .



5、 ... and 、 Conclusion
This paper proposes a new model of deep attention SCA-CNN For image captions .SCA-CNN Make the most of it CNN Characteristics , Generate image features of interest : Spatiality 、 Channel intelligence and multi-level , Thus achieving the most advanced performance on popular benchmarks .SCA-CNN The contribution of is not only a more powerful attention model , And better understand the process of sentence generation CNN Where is your attention ( That's space ) And what ( That is, the channel ) The evolution of . In the future work , We are going to SCA-CNN Introduction of time notice in , So as to participate in the characteristics of video subtitles in different video frames . We will also study how to increase the number of attention layers without over matching .
边栏推荐
- Basics of network security (1)
- [MRCTF2020]Ez_bypass --BUUCTF
- Binary search the specified number of numbers in the array binary advanced
- 2022施工員-設備方向-通用基礎(施工員)操作證考試題及模擬考試
- Explain bio, NiO, AIO in detail
- 睡前小故事之MySQL起源
- 浏览器控制台注入JS
- String类中split()方法的使用
- MySQL query table field information
- Kali system -- host, dig, dnsenum, imtry for DNS collection and analysis
猜你喜欢
![[MRCTF2020]Ez_bypass --BUUCTF](/img/73/85262c048e177968be67456fa4fe02.png)
[MRCTF2020]Ez_bypass --BUUCTF
![[GXYCTF2019]禁止套娃--详解](/img/c8/8c588ab8f58e2b38b9c64c4ccd733f.png)
[GXYCTF2019]禁止套娃--详解

Easyexcel read excel simple demo
![[C] Inverts the binary of a decimal number and outputs it](/img/40/dcbe0aac2d0599189697db1f0080b5.jpg)
[C] Inverts the binary of a decimal number and outputs it

Browser cache execution process
![[buglist] serial port programming does not read data](/img/bf/8e63f679bf139fbbf222878792ae21.jpg)
[buglist] serial port programming does not read data

高阶极点对于波形的影响

6.824 Lab 3B: Fault-tolerant Key/Value Service

Maya modeling VI

Stm32f4 development of DMA transmission to GPIO port
随机推荐
1115. alternate printing foobar
[LeetCode]1. Sum of two numbers thirty-four
What are the conditions of index invalidation?
[LeetCode]14. Longest common prefix thirty-eight
Buuctf's babysql[geek challenge 2019]
[GYCTF2020]Ezsqli --BUUCTF
哲學和文學的區別
Using com0com/com2tcp to realize TCP to serial port (win10)
Binary search the specified number of numbers in the array binary advanced
The e-commerce employee changed the product price to 10% off after leaving the company, and has been detained
MAYA建模六
[LeetCode]3. The longest substring without duplicate characters forty
Some basic design knowledge
TypeError: wave.ensureState is not a function
[error] invalid use of incomplete type uses an undefined type
也许尘埃落地,我们才能想清楚互联网的本质
Blinker FAQs
New blog address
[gxyctf2019] no dolls -- detailed explanation
Building crud applications in golang