当前位置:网站首页>Index Mysql in order to optimize paper 02 】 【 10 kinds of circumstances and the principle of failure
Index Mysql in order to optimize paper 02 】 【 10 kinds of circumstances and the principle of failure
2022-08-05 03:32:00 【Half old 518】

前 言
作者简介:半旧518,长跑型选手,立志坚持写10年博客,专注于java后端
专栏简介:mysql基础、进阶,主要讲解mysql数据库sql刷题、进阶知识,包括索引、数据库调优、分库分表等
文章简介:This article will introduce the index of failure10Kind of situation and principle,Absolutely don't need to rote,建议收藏备用.
相关推荐:
文章目录
1️⃣ Database tuning scene
上一篇mysql进阶优化篇,We introduced the database performance analysis tools,Know how to find the database performance issues,This blog we will introduce the index optimization with the query optimization.
First to get to know the possible need for database optimization scenario.
- 索引失效(According to the criteria to write、调整sql)
- 没有充分利用到索引(建立索引)
- 关联查询太多的JOIN(JOINQuery performance index of correlation between the number of tables and,Generally not more than three,否则需要进行sqlOptimization or reverse Fan Shihua design,Add the necessary redundancy)
- Server tuning and each parameter Settings,如缓存、线程数等(修改my.conf)
- The data is too high(Have full tuning in software aspects,But still can't face the high concurrency scenario,Can consider table depots scattered server pressure)
接下来我们介绍下sql查询优化.虽然sqlQuery optimization technology a lot,But roughly constant Physical check query optimization 和 逻辑查询优化 两大块.
- 物理查询优化:通过索引和表连接方式进行优化
- 逻辑查询优化:通过sql语句的等价代换,Realization of database query optimization.
2️⃣数据准备
Students table inserted50万 条, Insert class table1万条.
(1)建表
#班级表
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
#学员表
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
(2)设置参数
命令开启:允许创建函数设置:
set global log_bin_trust_function_creators=1;
# 不加global只是当前窗口有效.
(3)创建函数
保证每条数据都不同.
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#假如要删除
#drop function rand_string;
随机产生班级编号
#用于随机产生多少到多少的编号
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
#假如要删除
#drop function rand_num;
(4)创建存储过程
创建往stu表中插入数据的存储过程
#创建往stu表中插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_stu( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, name ,age ,classId ) VALUES
((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_stu;
创建往class表中插入数据的存储过程
#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE `insert_class`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES
(rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_class;
(5)调用存储过程
往class表添加1万条数据
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
往stu表添加50万条数据,This will be a little long,请耐心等待哟.
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);
Under the query data is inserted into the success.
SELECT COUNT(*) FROM class;
SELECT COUNT(*) FROM student;
(6)删除某表上的索引
Create index stored procedure.This is in order to facilitate our study,Because when we are in some index demonstration effect,May need to delete the other index,If you need to manually delete one by one,就太费劲了.
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM
information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND
seq_in_index=1 AND index_name <>'PRIMARY' ;
#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
#若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
执行存储过程(To retain don't perform)
CALL proc_drop_index("dbname","tablename");
3️⃣索引失效的情况
这里我们以InnoDB的B+The focus of the tree index structure as explain,Interpretation of the index case of failure of(3.1Interpretation of the index of best practice,).The reason of index failure would happen,It is because we optimizer passed overhead cost calculation,Decided no index.Use indexes are the optimizer word,SqlStatements will use the index,跟数据库版本、数据量和数据选择度都有关系.
3.1 全值匹配我最爱(索引最佳)
All values match can make full use of composite index.
When no index for data query speed will be slow.
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd';
SQL_NO_CACHE表示不使用查询缓存.
Below is without creating an index of,第一条sql的执行效果.The query time is0.048s.
The following set up the index.
CREATE INDEX idx_age ON student(age);
CREATE INDEX idx_age_classid ON student(age,classId);
CREATE INDEX idx_age_classid_name ON student(age,classId,NAME);
Q What is the difference between the above three indexes,Why is it so index?
The above is indexed with threesqlThe use of scene matching,Adhere to the rules of the whole value matches,Is to establish several composite index field,最好就用上几个字段.且按照顺序来用.
再次执行查询sql,就可以使用到索引idx_age.And shorten the query time consuming as0.024s.
执行如下sql.Select index is:idx_age_classid.思考下为什么?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4;
This is because we in constructing indexidx_age_classid的B+树时,会先按照age排序,在按照calssId排序,对于这个sql来说,更加高效.
But the index above may not be effective oh,在数据量较大的情况下,We all value matchingSELECT *,The optimizer may calculate found,We use the index query after all the data,Also need to find the data back to the table operation,Performance is not as good as a full table scan.Here we do not have made so much data,So don't demonstrate effects cough up.
3.2 Don't follow the leftmost prefix matching principle
运行如下sql.
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name='abcd';
将使用索引idx_age.
下面的sql不会使用索引,Because I didn't do not createclassId或者name的索引.或者
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classId=4 AND student.name='abcd';
Q:为什么不会使用idx_age_classid索引?
索引idx_age_classid的B+The tree will be useage排序,在使用classId给ageThe same data sorting,This index with no yo.This principle is the leftmost prefix below.
在 MySQL 建立联合索引时会遵守最佳左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配.
MySQL 可以为多个字段创建索引,一个索引可以包括 16 个字段,For multiple column,Filter conditions to use so that must be established in accordance with the index order,依次满足,一旦跳过某个字段,索引后面的字段都无法使用.如果查询条件中没有使用这些字段中的第一个字段时,Multi-column index will be used.
拓展:Alibaba《Java开发手册》
索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引.
下面的sqlThe query is to follow the principle of open the right way.
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age = 30 AND student.classId=4 AND student.name='abcd';
思考:下面sqlWill use the index?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classId=4 AND student.age = 30 AND student.name='abcd';
答案是会!Because the optimizer can perform optimization oh,To adjust the order of the query conditions.But we are still in the process of development to maintain good habits of development yo.
思考:Delete indexidx_age_classid和idx_age,只保留idx_age_classid_name
DROP INDEX idx_age_classid ON student;
DROP INDEX idx_age ON student;
执行如下sql,Will use the index?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age = 30 AND student.name='abcd';
答案是会,But will only use part of.看看执行结果.
使用了idx_age_classid_name,但是key_len是5,也就是说只使用了agePart of the order,因为age是int类型,4个字节加上nullList of values altogether5个字节哦.想想就知道,B+The tree is in accordance with the firstage排序,再按照classid排序,最后按照name排序,So you can't skipclassIdThe sort of direct usenameThe ordering of oh.
3.3 Not in increasing order into the key
对于一个使用 InnoDB 存储引擎的表来说,在我们没有显式的创建索引时,表中的数据实际上都是存储在 聚簇索引 的叶子节点的.而记录又是存储在数据页中,Page data and records are in accordance with the Record the primary key value since the childhood 的顺序进行排序,所以如果我们 插入 的记录的 The primary key is, in turn, increase 的话,那我们每插满一个数据页就换到下一个数据页继续插,而如果我们插入的 主键值忽大忽小 的话,就比较麻烦了,假设某个数据页存储的记录已经满了,它存储的主键值在 1~100 之间: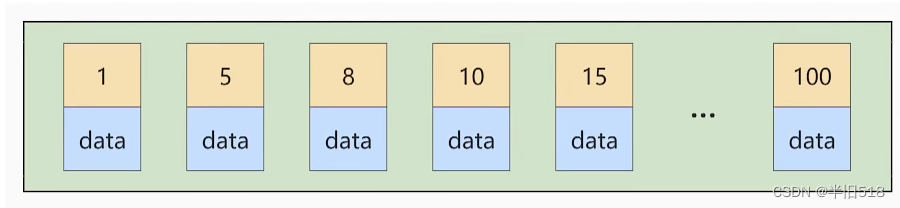
如果此时再插入一条主键值为 9 的记录,那它插入的位置就如下图: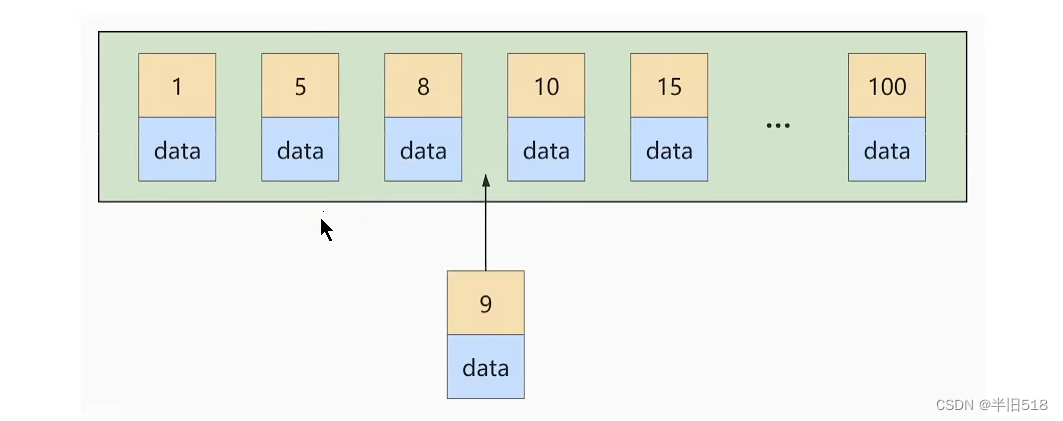
可这个数据页已经满了,再插进来咋办呢?我们需要把当前 页面分裂 成两个页面,把本页中的一些记录移动到新创建的这个页中.页面分裂和记录移位意味着什么?意味着:性能损耗!所以如果我们想尽量避免这样无谓的性能损耗,最好让插入的记录的 主键值依次递增 ,这样就不会发生这样的性能损耗了. 所以我们建议:让主键具有 AUTO_INCREMENT ,让存储引擎自己为表生成主键,而不是我们手动插入
我们自定义的主键列 id 拥有 AUTO_INCREMENT 属性,在插入记录时存储引擎会自动为我们填入自增的主键值.这样的主键占用空间小,顺序写入,减少页分裂.
Tips:
We usually set the primary key strategy for automatic incrementalAUTO_INCREMENT哦!(The core business except the table,Behind will introduce this kind of situation)
3.4 计算、函数、类型转换(自动或手动)导致索引失效
思考:这两条 sql 哪种写法更好?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
In the execution result,上面sqlResults no difference.But in operation efficiency,第1条sqlIt is better than later,Because the first can be used in the index!And because the second USES the function,Even if the index can also lead to index failure.
Why use function optimizer will disable index?您想想,我们只是对student.name字段建立了索引,但并没有对LEFT(student.name,3)建立索引,After using the function keyword set up with usB+Trees can't corresponding to,怎么能使用B+Optimized query tree?
3.5 类型转换导致索引失效
# 未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;
# 使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';
name = 123 发生类型转换,索引失效,The causes and using the function as well,Type conversion is actually using the implicit type conversion function.
3.6 范围条件右边的列索引失效
We prepared in front of the stored procedure call first delete other indexes except the primary key index.
CALL proc_drop_index('atguigu_db2','student');
SHOW INDEX FROM student;
创建联合索引.
CREATE INDEX idx_age_classId_name ON student(age,classId,NAME);
执行查询.
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.classId>20 AND student.name = 'abc' ;
执行结果如下.
注意到key_len是10,Specification values used toidx_age_classId_name索引中的age与classId部分,而nameThere is no use.这是因为classId>20是范围查询,Lead to the right hand column index failure.
If you want to use to the index,Need as follows to create index:Write the equivalent query column,Column to write range queries.
create index idx_age_name_classid on student(age,name,classid);
Q:Why condition range query will lead to the back of the column index failure?
比如说有三个字段 a b c,建立复合索引a_b_c
此时叶子节点的数据排序后可能为
(a=1 b=1 c=1) (a=1 b=2 c=1) (a=1 b=2 c=3)
(a=2 b=2 c=3) (a=2 b=2 c=5) (a=2 b=5 c=1) (a=2 b=5 c=2)
(a=3 b=0 c=1) (a=3 b=3 c=5) (a=3 b=8 c=6)
假设查找 select a,b,c from table where a = 2 and b = 5 and c = 2
此时先根据a = 2找到第二行的四条数据
(a=2 b=2 c=3) (a=2 b=2 c=5) (a=2 b=5 c=1) (a=2 b=5 c=2)
然后根据b=5查到两条
(a=2 b=5 c=1) (a=2 b=5 c=2)
最后根据c=2查到目标数据
(a=2 b=5 c=2)
接下来 Assumptions used range condition
select a,b,c from table where a = 2 and b >1 and c = 2
此时先根据a = 2找到第二行的四条数据
(a=2 b=2 c=3) (a=2 b=2 c=5) (a=2 b=5 c=1) (a=2 b=5 c=2)
然后根据b>1查到四条数据
(a=2 b=2 c=3) (a=2 b=2 c=5) (a=2 b=5 c=1) (a=2 b=5 c=2)
此时要查找c=2了 但是我们发现 The four datac分别是
3,5,1,2 是无序的 所以索引失效了
总结:
因为前一个条件相同的情况下,Subsequent columns will is ordered.
Tips:
应用开发中范围查询,例如:金额查询,日期查询往往都是范围查询.应将查询条件放置where语句最后.(创建的联合索引中,Be sure to write in the final design to the scope of the field)
3.7 不等于(!= 或者 <>)索引失效
为name字段创建索引
CREATE INDEX idx_name ON student(NAME);
查看索引是否失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name <> 'abc' ;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name != 'abc' ;
执行结果如下.
没有失效!!!The reason is not particularly clear,可能mysqlHigh version of the optimizer had update(After all is not equal to is equal to take anti,Can realize optimization)?笔者的mysql版本为8.2.06,If you have know bosses can leave a message in the comments section to discuss.But in the actual production or interview,It still can serve as a kind of need to pay attention to the special circumstances of.
3.8 is null可以使用索引,is not null无法使用索引
The reason and principle the same.
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;

EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
同样的,In low version index will failure,高版本中,Index nor failure oh.
结论:When designing the database will be best 字段设置为 NOT NULL 约束.比如可以将 INT 类型的字段,默认设置为 0.The default value of the string is set to the empty string(“”).
扩展:同理,在查询中使用 not like 也无法使用索引,导致全表扫描
3.9 like 以通配符 % 开头索引失效
在使用 LIKE 关键字进行查询的查询语句中,如果匹配字符串的第一个字符为“%”,The index is not the role of.只有“%”不在第一个位置,索引才会起作用.
使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE 'ab%';

未使用到索引.
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE '%ab%';

Think about itb+树,A fuzzy front then the sort and what use?
拓展:Alibaba《Java 开发手册》
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决.
3.10 OR前后存在非索引的列
在WHERE 子句中,如果在 OR 前的条件列进行了索引,而在 OR 后的条件列没有进行索引,那么索引会失效.也就是说,OR 前后的两个条件中的列都是索引时,查询中才使用索引.
因为 OR 的含义就是两个只要满足一个即可,因此 只有一个条件列进行了索引是没有意义的,只要有条件列没有进行索引,就会进行全表扫描,因此索引的条件列也会失效.
查询语句使用 OR 关键字的情况:
#Remove the existing index
CALL proc_drop_index('mymysql', 'student')
# 创建索引
CREATE INDEX idx_age ON student(age);
# 未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;

这是因为orThe connection of the query terms are need query,If a use index,An index of without a full table scan,The role of the index don't optimize performance.It is better to only a full table scan.
The solution is to not use the index column index creation.
# 再创建一个索引
CREATE INDEX idx_cid ON student(classid);
#使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
又翻车了·...It seems this situation have to be careful.
再来.
EXPLAIN SELECT SQL_NO_CACHE age,classid FROM student WHERE age = 10 OR classid = 100;

总结:没事别用select *.
3.11 Database and table character set do not match
统一使用 utf8mb4(5.5.3版本以上支持)兼容性更好,统一字符集可以避免由于字符集转换产生的乱码.不同的 字符集 进行比较前需要进行 转换 会造成索引失效.
4.The index general advice
假设,index(a,b,c),The following lists some worthy of attention index application scenario.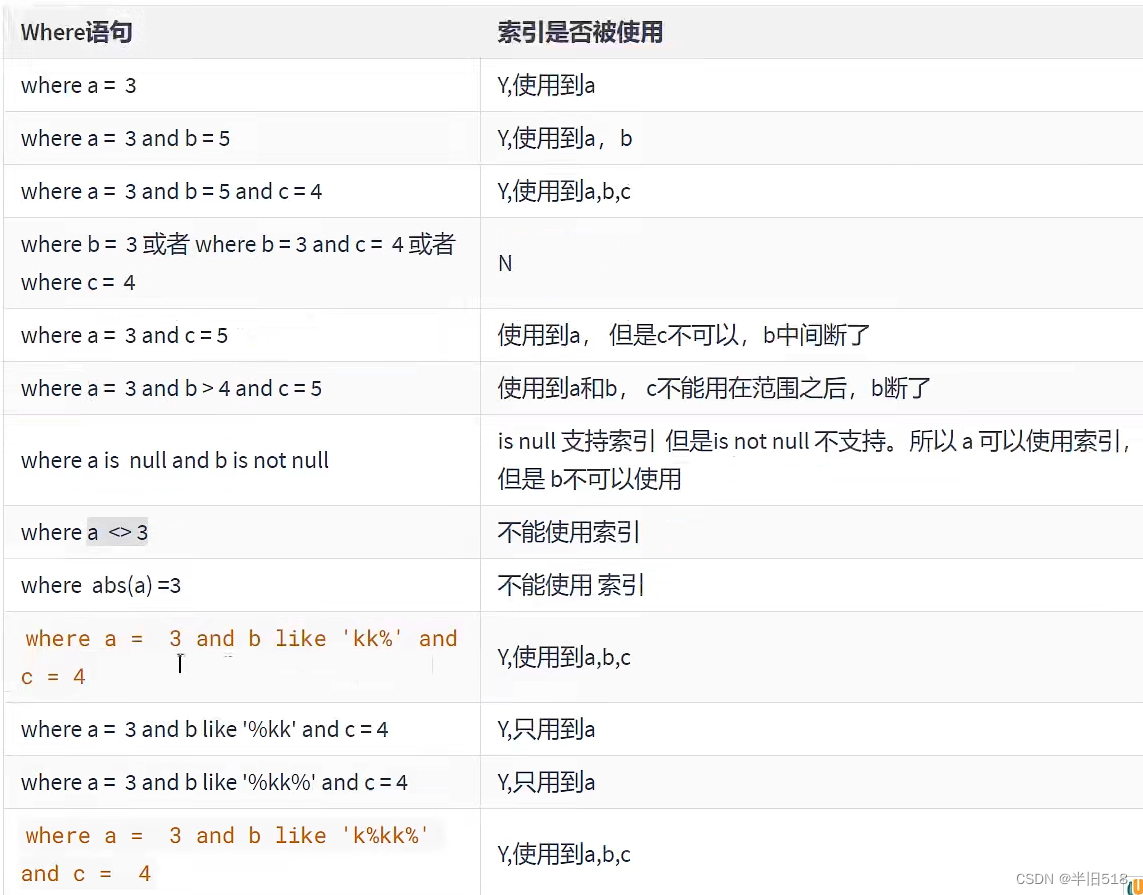
建议
对于单列索引,尽量选择针对当前 query 过滤性更好的索引
在选择组合索引的时候,当前 query 中过滤性最好的字段在索引字段顺序中,位置越靠前越好
在选择组合索引的时候,尽量选择能够包含当前 query 中的 where 子句中更多字段的索引
在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面.
总之,书写 SQL 语句时,尽量避免造成索引失效的情况.
工欲善其事,必先利其器”.If you want to work on database as a master,面试时的题霸,独步江湖,就必须拿到一份"武林秘籍".
我个人强推牛客网:找工作神器|大厂java面经汇总|超全笔试题库
推荐理由:
1.刷题题库,题目特别全面,刷爆笔试再也不担心
链接: 找工作神器|大厂java面经汇总|超全笔试题库
2.超全面试题、成体系、高质量,还有AI模拟面试黑科技
链接: 工作神器|大厂java面经汇总|超全笔试题库
3.超多面经,大厂面经很多
4.内推机会,大厂招聘特别多
链接: 找工作神器|大厂java面经汇总|超全笔试题库
5.大厂真题,直接拿到大厂真实题库,而且和许多大厂都有直接合作,题目通过率高有机会获得大厂内推资格.
链接: 找工作神器|大厂java面经汇总|超全笔试题库


边栏推荐
- 开发Hololens遇到The type or namespace name ‘HandMeshVertex‘ could not be found..
- 龙蜥社区第二届理事大会圆满召开!理事换届选举、4 位特约顾问加入
- This year's Qixi Festival, "love vegetables" are more loving than gifts
- Ffmpeg - sources analysis
- Redis key基本命令
- 从“能用”到“好用” 国产软件自主可控持续推进
- UE4 通过互动(键盘按键)开门
- 沃谈小知识 |“远程透传”那点事儿
- MRTK3 develops Hololens application - gesture drag, rotate, zoom object implementation
- .NET Application -- Helloworld (C#)
猜你喜欢
presto启动成功后出现2022-08-04T17:50:58.296+0800 ERROR Announcer-3 io.airlift.discovery.client.Announcer

Confessing the era of digital transformation, Speed Cloud engraves a new starting point for value
Why is the pca component not associated
![[Qixi Festival] Romantic Tanabata, code teaser.Turn love into a gorgeous three-dimensional scene and surprise her (him)!(send code)](/img/10/dafea90158adf9d43c4f025414fef7.png)
[Qixi Festival] Romantic Tanabata, code teaser.Turn love into a gorgeous three-dimensional scene and surprise her (him)!(send code)
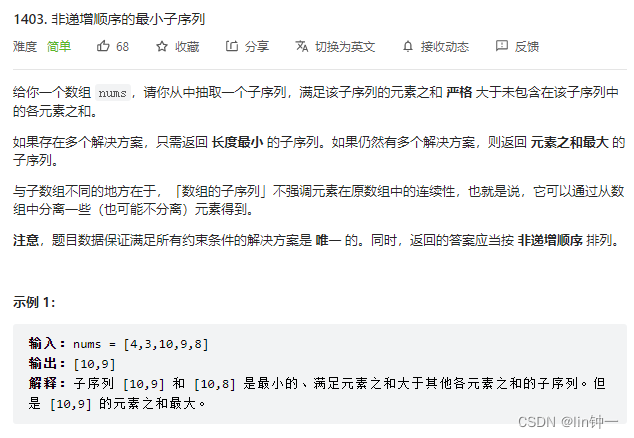
leetcode-每日一题1403. 非递增顺序的最小子序列(贪心)
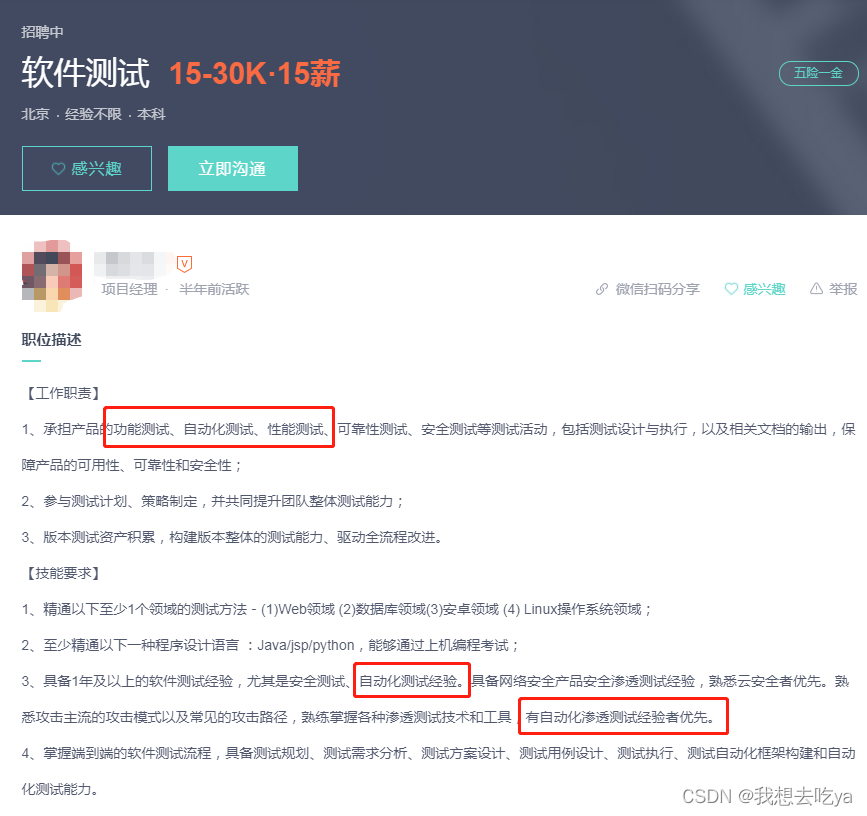
测试薪资这么高?刚毕业就20K
开发Hololens遇到The type or namespace name ‘HandMeshVertex‘ could not be found..
public static
List asList(T... a) What is the prototype? Increasing leetcode - a daily topic 1403. The order of the boy sequence (greed)
静态方法获取配置文件数据
随机推荐
You may use special comments to disable some warnings. 报错解决的三种方式
Ice Scorpion V4.0 attack, security dog products can be fully detected
Talking about data security governance and privacy computing
基于生长的棋盘格角点检测方法
The sword refers to Offer--find the repeated numbers in the array (three solutions)
[TA-Frost Wolf_may-"Hundred Talents Project"] Graphics 4.3 Real-time Shadow Introduction
Step by step how to perform data risk assessment
Redis key基本命令
MySql的索引学习和使用;(本人觉得足够详细)
高项 02 信息系统项目管理基础
MRTK3开发Hololens应用-手势拖拽、旋转 、缩放物体实现
事件解析树Drain3使用方法和解释
Spark基础【介绍、入门WordCount案例】
The second council meeting of the Dragon Lizard Community was successfully held!Director general election, 4 special consultants joined
Use Unity to publish APP to Hololens2 without pit tutorial
Beyond YOLO5-Face | YOLO-FaceV2 officially open source Trick+ academic point full
[Solved] Unity Coroutine coroutine is not executed effectively
GC Gaode coordinate and Baidu coordinate conversion
队列题目:最近的请求次数
今年七夕,「情蔬」比礼物更有爱