当前位置:网站首页>关于MySQL主从复制的数据同步延迟问题
关于MySQL主从复制的数据同步延迟问题
2022-07-31 12:50:00 【YYniannian】
主从复制环境在单机应用的时候没有问题,但在实际的生产环境中,会存在 复制延迟 的问题。

查看从库同步状态
在从库中执行 show slave status\G :
mysql> show slave status\G*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.2.158 Master_User: root Master_Port: 3306 Connect_Retry: 60 Master_Log_File: master-bin.000001 Read_Master_Log_Pos: 2560 Relay_Log_File: mysql-slave-node01-relay-bin.000002 Relay_Log_Pos: 2292 Relay_Master_Log_File: master-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 2560 Relay_Log_Space: 2512 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 Master_UUID: c28a6a7f-2a61-11eb-91e9-000c2959176f Master_Info_File: /var/lib/mysql/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: 复制代码这里有几个比较重要的参数:
- Master_Log_File :slave中的IO线程正在读取的主服务器的二进制日志文件的名称
- Read_Master_Log_Pos :在当前的主服务器二进制日志中,slave中的IO线程已经读取的位置
- Relay_Log_File : SQL线程 当前正在读取和执行的中继日志文件的名称
- Relay_Log_Pos :在当前的中继日志中,SQL线程已经读取和执行的位置
- Relay_Master_Log_File :由SQL线程执行的包含多数近期事件的主服务器二进制日志文件的名称
- Slave_IO_Running : IO线程是否启动并成功的连接到主服务器上
- Slave_SQL_Running :SQL线程是否启动
- Seconds_Behind_Master :从服务SQL线程和从服务器IO线程之间的时间差(秒)
值得一提的是 Seconds_Behind_Master ,这个参数直接就给出了当前从库延迟了多长时间。
那么这个值是如何计算的呢?
- Master执行完成一个事务,写入 binlog ,这个时刻记为 T1 ;
- Master传输 binlog 给Slave,Slave接收完 binlog 的时刻记为 T2 ;
- Slave执行完这个事务的时刻记为 T3 ;
主从复制延迟时间 就是同一个事务,在从库执行完成的时间和主库执行完成的时间之间的差值,也就是 T3 - T1。
SBM(Seconds Behind Master) 在进行计算的时候就是按照这样的方式,每个事务的 binlog 中都有一个时间字段,用于记录主库写入的时间,从库取出当前正在执行的事务的时间字段的值,计算它与当前系统时间的差值,得到SBM。
SBM时间差值产生的原因
通过SBM计算方式的分析,我们分析一下这个时间差产生的可能原因,以便于我们能在实际生产环境中解决问题。
- 大事务执行
比如主库的一个事务执行了N分钟,而 binlog 的写入必须要等待事务完成之后,才会传入从库,那么此时从库在开始执行的时候就已经延迟了N分钟了。
- 从库随机操作数据
主库的写操作是 顺序写 binlog ,从库单线程去主库 顺序读 binlog ,从库取到 binlog 之后在本地执行。
MySQL的主从复制都是单线程的操作,由于主库是顺序写,所以效率很高,而从库也是顺序读取主库的日志,此时的效率也是比较高的,但是 当数据拉取回来之后变成了随机的操作,而不是顺序的,所以此时成本会提高 。
- 从库同步时与查询线程发生lock征用
从库在同步数据的同时,可能跟其他查询的线程发生锁抢占用的情况,此时也会发生延时。
- 主库TPS高
当主库的TPS并发非常高的时候,产生的DDL数量超过了一个线程所能承受的范围的时候,那么也可能带来延迟。
- 网络问题
主从在进行 binlog 日志传输的时候,如果网络带宽也不是很好,那么网络延迟也可能造成数据同步延迟。
复制延迟问题解决方案
从sync_binlog参数配置下手

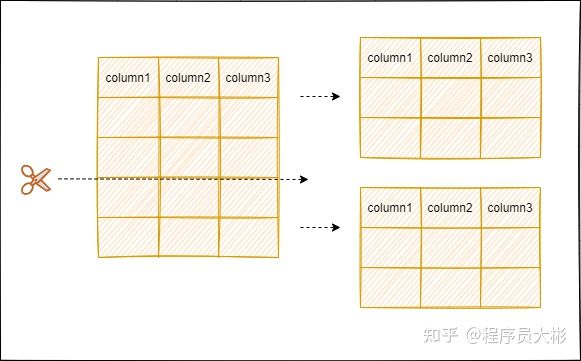
通过这个图我们可以看到,每个线程都有自己的 binlog cache ,但是共用同一份 binlog 文件。
其中的 write ,就是 把日志写入到文件系统的page cache,并没有把数据持久化到磁盘,所以速度快 。
fsync ,才是将数据持久化到磁盘的操作。一般情况下,我们认为 fsync才占用磁盘的IOPS 。
而 write 和 fsync 的时机就是 由参数sync_binlog来进行控制的 。
- sync_binlog=0:表示每次提交事务都只write,不fsync
- sync_binlog=1:表示每次提交事务都执行fsync
- sync_binlog=N:表示每次提交事务都write,但积累N个事务后才fsync
在大部分应用场景中,建议将此参数的值设置为1,因为这样的话能够保证数据的安全性。
但是如果出现主从复制的延迟问题,可以考虑将此值设置为100~1000中的某个数值,非常不建议设置为0,因为设置为0的时候没有办法控制丢失日志的数据量。
TIP:如果是对安全性要求比较高的业务系统,这个参数产生的意义就不是那么大了。
禁用salve上的binlog
直接禁用salve上的binlog,当从库的数据在做同步的时候,有可能从库的binlog也会进行记录,此时肯定也会消耗IO的资源,因此可以考虑将其关闭。
TIP:如果你搭建的集群是 级联 的模式的话,那么此时的 binlog 也会发送到另外一台从库里方便进行数据同步,此时这个配置项也不会起到太大的作用。
设置innodb_flush_log_at_trx_commit
innodb_flush_log_at_trx_commit 是用来表示每一次的事务提交是否需要把日志都写入磁盘(都写入磁盘耗时)。
**
innodb_flush_log_at_trx_commit ** 一共有三个属性值:
- =0 每次写到服务缓存,一秒钟刷写一次
- =1 每次事务提交都刷写一次磁盘
- =2 每次写到OS缓存,一秒钟刷写一次
一般情况下设置成2,这样就算MySQL的服务宕机了,写在OS缓存中的数据也会进行持久化。
从根本上解决
并行复制
**并行复制 ** 是MySQL 5.6版本之后引入的:

并行复制就是在中间加了一个 分发 任务的环节,也就是说原来的 SQL Thread 变成了现在的 Coordinator 组件,当日志来了之后, Coordinator 负责 读取日志信息以及分发事务 ,真正的日志执行的过程是放在了 worker线程 上,由多个线程并行的去执行。
并行复制操作
查看并行的slave的线程的个数,默认是0,表示单线程:
show global variables like 'slave_parallel_workers';复制代码根据实际情况设置开启多少线程:
set global slave_parallel_workers = 4;复制代码设置并发复制的方式,默认是一个线程处理一个库,值为database:
show global variables like '%slave_parallel_type%';复制代码设置slave_parallel_type属性值:
set global slave_parallel_type='logical_lock';复制代码查看线程数
show full processlist;复制代码MySQL 5.7的并行复制策略
MySQL 5.7版本优化了自己的并行复制策略,并且可以通过参数 slave-parallel-type 来控制并行复制的策略:
- 当配置的值为DATABASE的时候,则使用5.6版本的 数据库级别 的并行复制策略;
- 当配置的值为LOGICAL_CLOCK的时候,则使用MySQL 5.7全新的并行复制策略。
MySQL 5.7并行复制策略的思路是:
所有处于 redo log prepare 阶段的事务,都可以并行提交,原因是这些事务都已经经过了锁资源争用的阶段,都是没有冲突的。
反之,如果这些事务之间有冲突,则后来的事务会等待前面的事务释放锁之后才能执行,因此,这些事务就不会进入prepare阶段。
总结一下就是,一个组提交(group commit)的事务都是可以并行回放,因为这些事务都已进入到事务的prepare阶段,则说明事务之间没有任何冲突(否则就不可能提交)。
- binlog_group_commit_sync_delay 表示延迟多少微秒后才调用 fsync;
- binlog_group_commit_sync_no_delay_count 表示累积多少次以后才调用 fsync。
基于这样的处理机制,为了增加一组事务内的事务数量提高从库组提交时的并发量引入了
binlog_group_commit_sync_delay=N 和 binlog_group_commit_sync_no_delay_count=N 参数,MySQL等待 binlog_group_commit_sync_delay 毫秒直到达到 binlog_group_commit_sync_no_delay_count 事务个数时,将进行一次组提交。
基于GTID的主从复制
之前搭建主从复制环境的时候,在Slave上执行:
change master to master_host='192.168.2.158',master_user='root',master_password='123456',master_port=3306,master_log_file='master-bin.000001',master_log_pos=154复制代码这种写法限制我们必须知道具体的 binlog是哪个文件,同时在文件的哪个位置开始复制,正常情况下也没有问题。
但是如果是一个主备主从集群,那么如果主机宕机,当从机开始工作的时候,那么备机就要同步从机的位置,此时位置可能跟主机的位置是不同的,因此在这种情况下,再去找位置就会比较麻烦,所以在5.6版本之后出来一个 基于GTID的主从复制 。
GTID(Global Transaction ID) 是对于一个已提交事务的编号,并且是一个全局唯一的编号。
GTID实际上是由 UUID + TID 组成的,其中UUID是MySQL实例的唯一标识,TID表示该实例上已经提交的事务数量,并且随着事务提交单调递增。
这种方式保证事务在集群中有唯一的ID,强化了主备一致及故障恢复能力。
配置基于GTID的集群环境
虚拟机环境与 MySQL高可用之主从复制 中的集群环境一致。
三台MySQL实例配置文件修改:
192.168.2.158
[mysqld]# binloglog-bin=master-binlog-slave-updates=truebinlog-format=ROW# GTIDserver-id=158gtid_mode=on# 强制GTID一致性,开启后对于特定create table不被支持enforce_gtid_consistency=on# 从库:禁止开启IO线程和SQL线程,防止破坏从库skip_slave_start=1复制代码192.168.2.159
# binloglog-bin=master-binlog-slave-updates=truebinlog-format=ROW# GTIDserver-id=159gtid_mode=on# 强制GTID一致性,开启后对于特定create table不被支持enforce_gtid_consistency=on# 从库:禁止开启IO线程和SQL线程,防止破坏从库skip_slave_start=1复制代码192.168.2.157
[mysqld]# binloglog-bin=master-binlog-slave-updates=truebinlog-format=ROW# GTIDserver-id=157gtid_mode=on# 强制GTID一致性,开启后对于特定create table不被支持enforce_gtid_consistency=on# 从库:禁止开启IO线程和SQL线程,防止破坏从库skip_slave_start=1复制代码三台MySQL实例均重启。
在两个从库执行:
mysql> stop slave;Query OK, 0 rows affected (0.00 sec)mysql> change master to master_host='192.168.2.158',master_user='root',master_password='123456',master_auto_position=1;Query OK, 0 rows affected, 2 warnings (0.01 sec)复制代码关于master_auto_position
- master_auto_position = 0,表示采用老的binlog复制
- master_auto_position = 1,表示采用GTID复制
验证
在Master上执行:
mysql> show slave hosts;+-----------+------+------+-----------+--------------------------------------+| Server_id | Host | Port | Master_id | Slave_UUID |+-----------+------+------+-----------+--------------------------------------+| 157 | | 3306 | 158 | c269d11a-2a61-11eb-bf0d-000c29599fb3 || 159 | | 3306 | 158 | c2cba590-2a61-11eb-ac0e-000c2900ba99 |+-----------+------+------+-----------+--------------------------------------+2 rows in set (0.00 sec)复制代码可以看到,有两个从节点的MySQL实例。
在从节点上, show slave status\G

基于GTID复制的原理
当一个事务在Master提交时,该事务就被赋予了一个GTID,并记录在主库的binlog;
主库的binlog会被传输到从库的relay log中,从库读取此GTID并生成gtid_next系统参数;
从库验证此GTID并没有在自己的binlog中使用,则应用此事物在从库上。

如果我们不开启gtid,分组信息该如何保存呢? 其实是一样的,当没有开启的时候,数据库会有一个 Anonymous_Gtid ,用来保存组相关的信息。

点个赞,给个关注再走吧~
边栏推荐
- SAP message TK 248 solved
- Use docker to build mysql master-slave
- 串的基本概念与操作
- Json和对象之间转换的封装(Gson)
- 使用openssl命令生成证书和对应的私钥,私钥签名,公钥验签
- SAP 电商云 Spartacus UI 和 Accelerator UI 里的 ASM 模块
- [RPI]树莓派监控温度及报警关机保护「建议收藏」
- SAP e-commerce cloud Spartacus SSR Optimization Engine execution sequence of several timeouts
- NameNode (NN) 和SecondaryNameNode (2NN)工作机制
- 亲测可用!!!WPF中遍历整个窗口的所有TextBox组件,对每个输入框做非空判断。
猜你喜欢
PyQt5 rapid development and actual combat 9.7 Automated testing of UI layer

跨境电商小知识之跨境电商物流定义以及方式讲解
2022年最新重庆建筑安全员模拟题库及答案
MySQL面试八股文(2022最新整理)

networkx绘制度分布

CentOS7 安装MySQL 图文详细教程
分布式监视 Zabbix 和 Prometheus 到底怎么选?千万别用错了!

NameNode (NN) 和SecondaryNameNode (2NN)工作机制
Error EPERM operation not permitted, mkdir ‘Dsoftwarenodejsnode_cache_cacach两种解决办法

电脑重要文件很多,如何备份比较安全?
随机推荐
亲测可用!!!WPF中遍历整个窗口的所有TextBox组件,对每个输入框做非空判断。
centos7安装mysql5.7
ERROR 2003 (HY000) Can‘t connect to MySQL server on ‘localhost3306‘ (10061)解决办法
函数的参数
串的基本概念与操作
SAP e-commerce cloud Spartacus SSR Optimization Engine execution sequence of several timeouts
[core]-ARMV7-A、ARMV8-A、ARMV9-A 架构简介「建议收藏」
ASM module in SAP Ecommerce Cloud Spartacus UI and Accelerator UI
榕树贷款GPU 硬件架构
ipv4和ipv6对比(IPV4)
基本语法(二)
Introduction to using NPM
PyQt5快速开发与实战 10.1 获取城市天气预报
Flutter keyboard visibility
快速学完数据库管理
SAP 电商云 Spartacus UI 和 Accelerator UI 里的 ASM 模块
[RPI]树莓派监控温度及报警关机保护「建议收藏」
IDEA的database使用教程(使用mysql数据库)
docker部署完mysql无法连接
Adding data nodes and decommissioning data nodes in the cluster