当前位置:网站首页>机器学习中的概率模型
机器学习中的概率模型
2022-07-26 08:47:00 【Adenialzz】
机器学习中的概率模型
转自:https://zhuanlan.zhihu.com/p/164551678
机器学习中的概率模型
概率论,包括它的延伸-信息论,以及随机过程,在机器学习中有重要的作用。它们被广泛用于建立预测函数,目标函数,以及对算法进行理论分析。如果将机器学习算法的输入、输出数据看作随机变量,就可以用概率论的观点对问题进行建模,这是一种常见的思路。本文对机器学习领域种类繁多的概率模型做进行梳理和总结,帮助读者掌握这些算法的原理,培养用概率论作为工具对实际问题进行建模的思维。要顺利地阅读本文,需要具备概率论,信息论,随机过程的基础知识。
为什么需要概率论?
概率模型是机器学习算法中的大家族,从最简单的贝叶斯分类器,到让很多人觉得晦涩难懂的变分推断,到处都有它的影子。为什么需要概率论?这是我们要回答的第一个问题。
与支持向量机、决策树、Boosting、k均值算法这些非概率模型相比,概率模型可以给我们带来下面的好处:
对不确定性进行建模。假如我们要根据一个人的生理指标预测他是否患有某种疾病。与直接给出简单的是与否的答案相比,如果算法输出结果是:他患有这种疾病的概率是0.9,显然后者更为精确和科学。再如强化学习中的马尔可夫决策过程,状态转移具有随机性,需要用条件概率进行建模。
分析变量之间的依赖关系。对于某些任务,我们要分析各个指标之间的依赖关系。例如,学历对一个人的收入的影响程度有多大?此时需要使用条件概率和互信息之类的方法进行计算。
实现因果推理。对于某些应用,我们需要机器学习算法实现因果之间的推理,这种模型具有非常好的可解释性,与神经网络之类的黑盒模型相比,更符合人类的思维习惯。
能够生产随机样本数据。有些应用要求机器学习算法生成符合某一概率分布的样本,如图像,声音,文本。深度生成模型如生成对抗网络是其典型代表。
整体概览
在机器学习中,有大量的算法都是基于概率的。下面这张图列出了机器学习、深度学习、强化学习中典型的算法和理论所使用的概率论知识,使得大家对全貌有所了解。接下来我们将分别讲述这些算法是怎么以概率论作为工具进行建模的。

有监督学习
贝叶斯分类器
贝叶斯分类器是使用概率解决分类问题的典型代表。它的想法很简单:根据贝叶斯公式直接计算样本 x \mathbf{x} x 属于每个类的概率 p ( y ∣ x ) p(y|\mathbf{x}) p(y∣x)
p ( y ∣ x ) = p ( x ∣ y ) p ( y ) p ( x ) p(y|\mathbf{x})=\frac{p(\mathbf{x}|y)p(y)}{p(\mathbf{x})} p(y∣x)=p(x)p(x∣y)p(y)
这个概率也称为类后验概率。在这里 p ( y p(y p(y )是每个类出现的概率, p ( x ∣ y ) p(\mathbf{x}|y) p(x∣y) 是类条件概率,也是每个类的样本的特征向量 x \mathbf{x} x 所服从的概率分布。然后将样本判定为概率值最大的那个类
a r g m a x y p ( x ∣ y ) p ( y ) argmax_y\ p(\mathbf{x}|y)p(y) argmaxy p(x∣y)p(y)
这里忽略了上面那个概率计算公式中的分母 p ( x ) p(\mathbf{x}) p(x),因为它对所有类都是相同的,我们并不需要计算出每个类的概率值,而只需要找到概率最大的那个类。
实现时,需要确定每个类样本的特征向量所服从的概率分布 p ( x ∣ y ) p(\mathbf{x}|y) p(x∣y) 以及每个类出现的概率 p ( y ) p(y) p(y)。前者的参数通常通过最大似然估计确定。如果假设每个类的样本都服从正态分布,就是正态贝叶斯分类器。
logistic回归
伯努利分布+最大似然估计=logistic回归
logistic 回归用于解决二分类问题,它的想法与贝叶斯分类器类似,也是预测样本属于每个类的概率。不同的是它没有借助于贝叶斯公式,而是直接根据特征向量 x \mathbf{x} x 估计出了样本是正样本的概率
p ( x ) = 1 1 + e x p ( − w T x + b ) p(\mathbf{x})=\frac{1}{1+\rm{exp}(-\mathbf{w}^T\mathbf{x}+b)} p(x)=1+exp(−wTx+b)1
如果这个概率值大于 0.5,就被判定为正样本,否则是负样本。这里的参数 w \mathbf{w} w 和 b b b 通过最大似然估计得到。可以认为,logistic 回归拟合的是伯努利分布。需要强调的是,logistic 回归虽然是一种概率模型,但它不是生成模型,而是判别模型,因为它没有假设样本的特征向量服从何种概率分布。
softmax回归
多项分布 + 最大似然估计 = softmax回归
softmax 回归是 logistic 回归的多分类版本,它也是直接预测样本 x \mathbf{x} x 属于每个类的概率
h θ ( x ) = 1 ∑ i = 1 k e θ i T x [ e θ 1 T x … e θ k T x ] h_\theta(\mathbf{x})=\frac{1}{\sum_{i=1}^ke^{\theta_i^T\mathbf{x}}}\begin{bmatrix} e^{\theta_1^T\mathbf{x}} \\ \dots \\e^{\theta_k^T\mathbf{x}} \end{bmatrix}\quad hθ(x)=∑i=1keθiTx1⎣⎡eθ1Tx…eθkTx⎦⎤
然后将其判定为概率最大的那个类。这种方法假设样本的类别标签值服从多项分布,因此它拟合的是多项分布。模型的参数通过最大似然估计得到,由此也导出了著名的交叉熵目标函数:
− ∑ i = 1 l ∑ j = 1 k ( y i j l n e x p ( θ j T x i ) ∑ t = 1 k e x p ( θ j T x i ) ) -\sum_{i=1}^l\sum_{j=1}^k(y_{ij}\ ln\frac{\rm{exp}{(\theta}_j^T\mathbf{x}_i)}{\sum_{t=1}^k\rm{exp}(\theta_j^T\mathbf{x}_i)}) −i=1∑lj=1∑k(yij ln∑t=1kexp(θjTxi)exp(θjTxi))
最大化对数似然函数等价于最小化交叉熵损失函数。softmax 回归在训练时的目标就是使得模型预测出的分布与真实标签的概率分布的交叉熵最小化。
变分推断
贝叶斯公式+KL散度=变分推断
贝叶斯分类器是贝叶斯推断的简单特例,它们的目标是计算出已知观测变量 x \mathbf{x} x 时因变量 z \mathbf{z} z 的后验概率 p ( z ∣ x ) p(\mathbf{z}|\mathbf{x}) p(z∣x) ,从而完成因果推断:
p ( z ∣ x ) = p ( x ∣ z ) p ( z ) p ( x ) p(\mathbf{z|x})=\frac{p(\mathbf{x|z})p(\mathbf{z})}{p(\mathbf{x})} p(z∣x)=p(x)p(x∣z)p(z)
观测变量 x \mathbf{x} x 的值是已知的,例如可以使样本的特征向量。隐变量的值 z \mathbf{z} z 是不能直接观察到的,例如样本的类别。
这里面临的一个问题是上式中分母的 p ( x ) p(\mathbf{x}) p(x) 难以计算,如果 x \mathbf{x} x 是高维随机向量,计算这个分母涉及到计算高维联合概率密度函数 p ( x , z ) p(\mathbf{x},\mathbf{z}) p(x,z) 的积分:
p ( z ∣ x ) = p ( x ∣ z ) p ( z ) ∫ z p ( x ∣ z ) p ( z ) d z p(\mathbf{z|x})=\frac{p(\mathbf{x|z})p(\mathbf{z})}{\int_\mathbf{z}p(\mathbf{x|z)}p(\mathbf{z})d\mathbf{z}} p(z∣x)=∫zp(x∣z)p(z)dzp(x∣z)p(z)
既然精确地计算很困难,人们就想到了一个聪明的解决办法:我们能不能找出一个概率分布 q ( z ) q(\mathbf{z}) q(z) 来近似替代 p ( z ∣ x ) p(\mathbf{z|x}) p(z∣x),只要二者很相似就可以。找到这个近似概率分布 q ( z ) q(\mathbf{z}) q(z) 的依据是它与 p ( z ∣ x ) p(\mathbf{z|x}) p(z∣x) 的KL散度最小化,因为KL散度衡量了两个概率分布之间的差异。KL散度越大,两个概率分布的差异越大;如果这两个概率分布完全相等,KL散度的值为 0。由此得到了变分推断的核心公式:
l n p ( x ) = D K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) − ∫ z q ( z ) ln q ( z ) p ( z , x ) d z = D K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) + L ( q ( z ) ) \begin{align} ln\ p(\mathbf{x})&=D_{KL}(q(\mathbf{z})||p(\mathbf{z|x}))-\int_\mathbf{z}q(\mathbf{z})\ln\frac{q(\mathbf{z})}{p(\mathbf{z},\mathbf{x})}d\mathbf{z}\\ &=D_{KL}(q(\mathbf{z})||p(\mathbf{z|x}))+L(q(\mathbf{z})) \end{align} ln p(x)=DKL(q(z)∣∣p(z∣x))−∫zq(z)lnp(z,x)q(z)dz=DKL(q(z)∣∣p(z∣x))+L(q(z))
ln p ( x ) \ln\ p(\mathbf{x}) ln p(x) 是一个常数,因此最小化二者的KL散度等价于最大化证据下界函数 L ( q ( z ) ) L(q\mathbf{(z})) L(q(z))。这个下界函数通常易于优化,我们由此可以确定 q ( z ) q(\mathbf{z}) q(z)。实际实现时,通常假定 q ( z ) q(\mathbf{z}) q(z) 为正态分布,因为正态分布具有诸多优良的性质。我们也可以从变分推断的角度来解释EM算法。
高斯过程回归
高斯过程回归听起来很玄乎,实际上非常简单。有一组随机变量,假设它们服从多维正态分布,那么它们就构成了高斯过程,任意增加一个变量之后,还是服从正态分布。多维正态分布有着非常好的性质,我们可以直接得到它的边缘分布、条件分布的解析表达式。
高斯过程回归,就是假设我们要预测的函数在任意各个点 x x x 处的函数值 f ( x ) f(x) f(x) 形成一个高斯过程。根据高斯过程的性质,给定一组样本值 x x x 以及他们对应的函数值 f ( x ) f(x) f(x) ,我们可以得到任意点处的函数值的概率分布,当然,这是一个正态分布,它的均值和方差分别为:
μ = k T K − 1 ( f ( x 1 : t ) − μ ( x 1 : t ) ) + μ ( x t + 1 ) σ 2 = k ( x t + 1 , x t + 1 ) k T K − 1 k \mu=\mathbf{k}^T\mathbf{K}^{-1}(f(\mathbf{x}_{1:t})-\mu(\mathbf{x}_{1:t}))+\mu(\mathbf{x}_{t+1})\\ \sigma^2=k(\mathbf{x}_{t+1},\mathbf{x}_{t+1})\mathbf{k}^T\mathbf{K}^{-1}\mathbf{k} μ=kTK−1(f(x1:t)−μ(x1:t))+μ(xt+1)σ2=k(xt+1,xt+1)kTK−1k
得到函数在任意点处的函数值的概率分布之后,我们可以做很多事情。高斯过程回归是贝叶斯优化的核心模块之一。
无监督学习
SNE降维算法
正态分布+KL散度=SNE
随机近邻嵌入(SNE)是一种基于概率的流形降维算法,将向量组
x i , i = 1 , … , l \mathbf{x}_i,\ \ i=1,\dots,l xi, i=1,…,l
变换到低维空间,得到向量组
y i , i = 1 , … , l \mathbf{y}_i,\ \ i=1,\dots,l yi, i=1,…,l
它基于如下思想:在高维空间中距离很近的点投影到低维空间中之后也要保持这种近邻关系,在这里距离通过概率体现。假设在高维空间中有两个点样本点 x i \mathbf{x}_i xi 和 x j \mathbf{x}_j xj , x j \mathbf{x}_j xj 以 p j ∣ i p_{j|i} pj∣i 的概率作为 x i \mathbf{x}_i xi 的邻居,借助于正态分布,此概率的计算公式为:
p j ∣ i = e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 / 2 σ i 2 ) ∑ k ≠ i e x p ( − ∣ ∣ x i − x k ∣ ∣ 2 / 2 σ i 2 ) p_{j|i}=\frac{\rm{exp}(-||\mathbf{x}_i-\mathbf{x}_j||^2/2\sigma_i^2)}{\sum_{k\ne i}\rm{exp}(-||\mathbf{x}_i-\mathbf{x}_k||^2/2\sigma_i^2)} pj∣i=∑k=iexp(−∣∣xi−xk∣∣2/2σi2)exp(−∣∣xi−xj∣∣2/2σi2)
投影到低维空间之后仍然要保持这个概率关系。假设 x i \mathbf{x}_i xi 和 x j \mathbf{x}_j xj 投影之后对应的点为 y i \mathbf{y}_i yi 和 y j \mathbf{y}_j yj ,在低维空间中对应的近邻概率记为: q j ∣ i q_{j|i} qj∣i,计算公式与上面的相同,也使用了正态分布
q j ∣ i = e x p ( − ∣ ∣ y i − y j ∣ ∣ 2 ) ∑ k ≠ i e x p ( − ∣ ∣ y i − y k ∣ ∣ 2 ) q_{j|i}=\frac{\rm{exp}(-||\mathbf{y}_i-\mathbf{y}_j||^2)}{\sum_{k\ne i}\rm{exp}(-||\mathbf{y}_i-\mathbf{y}_k||^2)} qj∣i=∑k=iexp(−∣∣yi−yk∣∣2)exp(−∣∣yi−yj∣∣2)
如果考虑所有其他点,这些概率值构成一个离散型概率分布 p i p_i pi ,是所有样本点称为 x i \mathbf{x}_i xi 邻居的概率。在低维空间中对应的概率分布为 q i q_i qi ,投影的目标是这两个概率的分布尽可能接近。需要衡量两个概率分布之间的相似度。这里用KL散度衡量两个多项分布之间的差距。由此得到投影的目标为最小化如下函数:
L ( y i ) = ∑ i = 1 l D K L ( p i ∣ q i ) = ∑ i = 1 l ∑ j = 1 l p j ∣ i ln p j ∣ i q j ∣ i L(\mathbf{y}_i)=\sum_{i=1}^lD_{KL}(p_i|q_i)=\sum_{i=1}^l\sum_{j=1}^lp_{j|i}\ln\frac{p_{j|i}}{q_{j|i}} L(yi)=i=1∑lDKL(pi∣qi)=i=1∑lj=1∑lpj∣ilnqj∣ipj∣i
最小化该目标函数就可以得到降维之后的结果。
t-SNE降维算法
t分布 + KL散度 = t-SNE
t-SNE是SNE的改进版本。其中一个核心改进是将正态分布替换为t分布,t分布具有长尾的特性,在远离概率密度函数中点处依然有较大的概率密度函数值,因此更易于产生远离中心的样本,从而能够更好的处理离群样本点。
高斯混合模型
多项分布 + 正态分布 = 高斯混合模型
正态分布具有很多良好的性质,在应用问题中我们通常假设随机变量服从正态分布。不幸的是,单个高斯分布的建模能力有限,无法拟合多峰分布(概率密度函数有多个极值),如果将多个高斯分布组合起来使用则表示能力大为提升,这就是高斯混合模型。
高斯混合模型(GMM)通过多个正态分布的加权和来定义一个连续型随机变量的概率分布,其概率密度函数定义为:
p ( x ) = ∑ i = 1 k w i N ( x ; μ i , Σ i ) p(\mathbf{x})=\sum_{i=1}^kw_iN(\mathbf{x};\mathbf{\mu}_i,\Sigma_i) p(x)=i=1∑kwiN(x;μi,Σi)
GMM可以看做是多项分布与高斯分布的结合,首先从 k k k 个高斯分布中随机的选择一个,选中每一个的概率为 w i w_i wi,然后用该高斯分布产生出样本 x \mathbf{x} x。这里用隐变量 z \mathbf{z} z 来指示选择的是哪个高斯分布。高斯混合模型的参数通过最大似然估计得到,由于有隐变量的存在,无法像高斯分布那样直接得到对数似然函数极值点的解析解,需要使用EM算法。
Mean shift算法
核密度估计 + 梯度下降法 = Mean shift算法
很多时候我们无法给出概率密度函数的显式表达式,此时可以使用核密度估计。核密度估计(KDE)也称为Parzen窗技术,是一种非参数方法,它无需求解概率密度函数的参数,而是用一组标准函数的叠加表示概率密度函数。
p ( x ) = 1 n h d ∑ i = 1 n K ( x − x i h ) p(\mathbf{x})=\frac{1}{nh^d}\sum_{i=1}^nK(\frac{\mathbf{x}-\mathbf{x}_i}{h}) p(x)=nhd1i=1∑nK(hx−xi)
对于聚类,图像分割,目标跟踪等任务,我们需求概率密度函数的极值。均值漂移算法可以找到上面这种形式的概率密度函数的极大值点,是核密度估计与梯度上升法(与梯度下降法相反,用于求函数的极大值)相结合的产物。对上面的概率密度函数求梯度,可以得到下面的梯度计算公式
m h , G ( x ) = ∑ i = 1 n x i g ( ∣ ∣ x − x i h ∣ ∣ 2 ) ∑ i = 1 n g ( ∣ ∣ x − x i h ∣ ∣ 2 ) \mathbf{m}_{h,G}(\mathbf{x})=\frac{\sum_{i=1}^n\mathbf{x}_ig(||\frac{\mathbf{x}-\mathbf{x}_i}{h}||^2)}{\sum_{i=1}^ng(||\frac{\mathbf{x}-\mathbf{x}_i}{h}||^2)} mh,G(x)=∑i=1ng(∣∣hx−xi∣∣2)∑i=1nxig(∣∣hx−xi∣∣2)
这个向量也称为均值漂移向量。由此可以得到梯度上升法的迭代公式
x t + 1 = x t + m t \mathbf{x}_{t+1}=\mathbf{x}_t+\mathbf{m}_t xt+1=xt+mt
均值漂移算法简单而优美,当年在目标跟踪领域取得了令人刮目相看的效果。
概率图模型
概率论 + 图论 = 概率图模型
概率图模型是概率论与图论相结合的产物。它用图表示随机变量之间的概率关系,对联合概率或条件概率建模。在这种图中,顶点是随机变量,边为变量之间的依赖关系。如果是有向图,则称为概率有向图模型;如果是无向图,则称为概率无向图模型。概率有向图模型的典型代表是贝叶斯网络,概率无向图模型的典型代表是马尔可夫随机场。使用贝叶斯网络可以实现因果推理。
隐马尔可夫模型
马尔可夫链 + 观测变量 = 隐马尔可夫模型
马尔可夫过程是随机过程的典型代表。这种随机过程为随着时间进行演化的一组随机变量进行建模,假设系统在当前时刻的状态值只与上一个时刻有关,与更早的时刻无关,称为“无记忆性”。
有些实际应用中不能直接观察到系统的状态值,状态的值是隐含的,只能得到一组称为观测的值。为此对马尔可夫模型进行扩充,得到隐马尔可夫模型(HMM)。隐马尔可夫模型描述了观测变量和状态变量之间的概率关系。与马尔可夫模型相比,隐马尔可夫模型不仅对状态建模,而且对观测值建模。不同时刻的状态值之间,同一时刻的状态值和观测值之间,都存在概率关系。
隐马尔可夫模型可以表示为五元组:
{ S , V , π , A , B } \{S,V,\mathbf{\pi},\mathbf{A},\mathbf{B}\} { S,V,π,A,B}
其中 S S S 为状态集合, V V V 为观测集合, π \pi π 是初始状态的概率分布, A \mathbf{A} A 是状态转移矩阵, B \mathbf{B} B 是观测矩阵。
受限玻尔兹曼机
玻尔兹曼分布 + 二部图 = 受限玻尔兹曼机
受限玻尔兹曼机(RBM)是一种特殊的神经网络,其网络结构为二部图。这是一种随机神经网络。在这种模型中,神经元的输出值是以随机的方式确定的,而不像其他的神经网络那样是确定性的。
受限玻尔兹曼机的变量(神经元)分为可见变量和隐藏变量两种类型,并定义了它们服从的概率分布。可见变量是神经网络的输入数据,如图像;隐藏变量可以看作是从输入数据中提取的特征。在受限玻尔兹曼机中,可见变量和隐藏变量都是二元变量,其取值只能为 0 或 1,整个神经网络是一个二部图。
二部图的两个子集分别为隐藏节点集合和可见节点集合,只有可见单元和隐藏单元之间才会存在边,可见单元之间以及隐藏单元之间都不会有边连接。隐变量和可见变量的取值服从下面的玻尔兹曼分布:
p ( x ) = e − e n e r g y ( x ) Z p(x)=\frac{e^{-energy(x)}}{Z} p(x)=Ze−energy(x)
数据生成问题
数据生成模型以生成图像、声音、文字等数据为目标,生成的数据服从某种未知的概率分布,具有随机性。假设要生成猫、狗的图像,算法输出随机向量 x \mathbf{x} x ,该向量由图像的所有像素拼接而成,每类样本 x \mathbf{x} x 都服从各自的概率分布,定义了所有像素值的约束。例如对于狗来说,如果看上去要像真实的狗,则每个位置处的像素值必须满足某些约束条件,且哥哥同位置处的像素值之间存在相关性。算法生成的样本 x \mathbf{x} x 要有较高的概率值 p ( x ) p(\mathbf{x}) p(x) ,即像真的样本。
数据生成模型通常通过分布变换实现,原理很简单:对服从简单的概率分布(如正态分布,均匀分布)的数据数 z \mathbf{z} z 进行映射,得到一个新的随机变量 g ( z ) g(\mathbf{z}) g(z),这个随机变量服从我们想要的那种概率分布。问题的核心是如何找到这个映射 g ( z ) g(\mathbf{z}) g(z)。深度生成模型的典型代表-生成对抗网络,以及变分自动编码器,通过不同的路径实现了这一功能。
生成对抗网络
概率分布变换(生成器) + 二分类器(判别器) = 生成对抗网络
生成对抗网络由一个生成模型和一个判别模型组成。生成模型用于学习真实样本数据的概率分布,并直接生成符合这种分布的数据,实现分布变换函数 g ( z ) g(\mathbf{z}) g(z);判别模型的任务是判断一个输入样本数据是真实样本还是由生成模型生成的,即对生成模型生成的样本进行评判,以指导生成模型的训练。在训练时,两个模型不断竞争,从而分别提高它们的生成能力和判别能力。训练时要优化的目标函数定义为:
m i n G m a x D V ( D , G ) = E x ∼ p d a t a ( x ) [ ln ( 1 − D ( G ( z ) ) ) ] min_G\ max_D\ V(D,G)=\mathbb{E}_{\mathbf{x}\sim p_{data}(\mathbf{x})}[\ln(1-D(G(\mathbf{z})))] minG maxD V(D,G)=Ex∼pdata(x)[ln(1−D(G(z)))]
训练完成之后,生成模型就可以用来生成样本了,它的输入是随机变量 z \mathbf{z} z ,从而保证了生成的样本具有随机性。可以证明,当且仅当生成器所实现的概率分布与样本的真实概率分布相等时上面的目标函数取得极小值 p g = p d a t a p_g=p_{data} pg=pdata 。
从理论上来说,是使得生成器生成的样本的概率分布与真实样本的概率分布的KL散度最小化。
变分自动编码器
变分推断 + 神经网络 = 变分自动编码器
变分自动编码器(VAE)是变分推断与神经网络相结合的产物。整个系统遵循自动编码器的结构,由编码器和解码器构成。在训练时,编码器将训练样本 x \mathbf{x} x 映射成隐变量 z \mathbf{z} z 所服从的概率分布的参数,然后从此概率分布进行采样得到隐变量 z \mathbf{z} z,解码器则将隐变量 z \mathbf{z} z 映射回样本变量 x \mathbf{x} x,即进行重构。这种方法在标准自动编码器的基础上加入了随机性,从而保证可以输出带有随机性的数据。
训练时优化的目标为:
ln p ( x ) − D K L [ q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ] = E z ∼ q [ ln p ( x ∣ z ) ] − D K L [ q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ] \ln p(\mathbf{x})-D_{KL}[q(\mathbf{z|x})\ ||\ p(\mathbf{z|x})]=\mathbb{E}_{\mathbf{z}\sim q}[\ln p(\mathbf{x|z})]-D_{KL}[q(\mathbf{z|x})\ ||\ p(\mathbf{z|x})] lnp(x)−DKL[q(z∣x) ∣∣ p(z∣x)]=Ez∼q[lnp(x∣z)]−DKL[q(z∣x) ∣∣ p(z∣x)]
q ( z ∣ x ) q(\mathbf{z|x}) q(z∣x) 充当编码器的角色,将 x \mathbf{x} x 编码为 z \mathbf{z} z 。给定一个 x \mathbf{x} x ,输出其对应的隐变量的概率分布。编码器的输出为隐变量所服从分布的均值和方,而非隐变量本身。 p ( x ∣ z ) p(\mathbf{x|z}) p(x∣z) 充当解码器,从 z \mathbf{z} z 重构出 x \mathbf{x} x 。
强化学习
马尔可夫决策过程
马尔可夫过程 + 动作 + 奖励 = 马尔可夫决策过程
马尔可夫决策过程(MDP)是强化学模型的抽象,是对马尔可夫过程的扩充,在它的基础上加入了动作和奖励,动作可以影响系统的状态,奖励用于指导智能体学习正确的行为,是对动作的反馈。
在每个时刻智能体观察环境,得到一组状态值,然后根据状态来决定执行什么动作。执行动作之后,系统给智能体一个反馈,称为回报或奖励。回报的作用是告诉智能体之前执行的动作所导致的结果的好坏。
MDP可以抽象成一个五元组:
{ S , A , p , r , γ } \{S,A,p,r,\gamma\} { S,A,p,r,γ}
其中 S S S 为状态空间, A A A 为动作空间, p p p 为状态转移概率, r r r 为回报函数, γ \gamma γ 是折扣因子。从 0 时刻起,智能体在每个状态下执行动作,转入下一个状态,同时收到一个立即回报。这一演化过程如下所示:
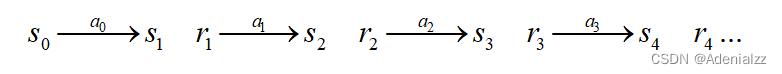
在这里,状态转移概率用于对不确定性进行建模,即使当前时刻的状态值,当前时刻要执行的动作是确定的,但下一个时刻转让何种状态,是具有随机性的。
边栏推荐
- Oracle 19C OCP 1z0-082 certification examination question bank (7-12)
- Which financial product has the highest yield in 2022?
- Uni app simple mall production
- P3743 kotori的设备
- [encryption weekly] has the encryption market recovered? The cold winter still hasn't thawed out. Take stock of the major events that occurred in the encryption market last week
- Cve-2021-26295 Apache OFBiz deserialization Remote Code Execution Vulnerability recurrence
- What are the contents of Oracle OCP and MySQL OCP certification exams?
- Human computer interaction software based on C language
- TypeScript版Snowflake主键生成器
- Oracle 19C OCP 1z0-082 certification examination question bank (30-35)
猜你喜欢

Transfer guide printing system based on C language design

keepalived双机热备

MySQL 8.0 OCP (1z0-908) has a Chinese exam

Grid segmentation
![[encryption weekly] has the encryption market recovered? The cold winter still hasn't thawed out. Take stock of the major events that occurred in the encryption market last week](/img/d8/a367c26b51d9dbaf53bf4fe2a13917.png)
[encryption weekly] has the encryption market recovered? The cold winter still hasn't thawed out. Take stock of the major events that occurred in the encryption market last week

Uni app simple mall production

at、crontab

03 exception handling, state keeping, request hook -- 04 large project structure and blueprint
![[freeswitch development practice] user defined module creation and use](/img/5f/3034577e3e2bc018d0f272359af502.png)
[freeswitch development practice] user defined module creation and use

合工大苍穹战队视觉组培训Day6——传统视觉,图像处理
随机推荐
Memory management - dynamic partition allocation simulation
Learn more about the difference between B-tree and b+tree
6、 Pinda general permission system__ pd-tools-log
C Entry series (31) -- operator overloading
【数据库 】GBase 8a MPP Cluster V95 安装和卸载
Registration of finite element learning knowledge points
[C language] programmer's basic skill method - "creation and destruction of function stack frames"
Use index to optimize SQL query "suggestions collection"
[recommended collection] summary of MySQL 30000 word essence - partitions, tables, databases and master-slave replication (V)
P3743 Kotori's equipment
Set of pl/sql -2
Cadence(十)走线技巧与注意事项
Typescript snowflake primary key generator
day06 作业--增删改查
Oracle 19C OCP 1z0-082 certification examination question bank (24-29)
Foundry教程:使用多种方式编写可升级的智能合约(上)
pl/sql之集合-2
Foundry tutorial: writing scalable smart contracts in various ways (Part 1)
Maximum common substring & regularity problem
TypeScript版加密工具PasswordEncoder