当前位置:网站首页>SA Siam: Twin network for real-time target tracking
SA Siam: Twin network for real-time target tracking
2022-07-26 14:45:00 【The way of code】
Address of thesis :https://openaccess.thecvf.com/content_cvpr_2018/papers/He_A_Twofold_Siamese_CVPR_2018_paper.pdf
Abstract
1. The core of this article is : Classify the image in the task Semantic features (Semantic features) Match with the similarity in the task Appearance features (Appearance features) Complementary combination , It is very suitable for target tracking tasks , Therefore, the method in this paper can be simply summarized as :SA-Siam= Semantic Branch + Appearance branch ;
2.Motivation: The characteristics of target tracking are , We want to distinguish the changing target object from many backgrounds , The difficulty is : Background and changes . The idea of this paper is to filter out the background with a semantic Branch , At the same time, a branch of appearance features is used to generalize the changes of targets , If an object is judged not to be the background by the semantic Branch , And it is judged by the appearance feature branch that the object is changed from the target object , Then we think this object is the object that needs to be tracked ;
3. The purpose of this article is to improve SiamFC Discrimination in target tracking tasks . At depth CNN In the task of training target classification , The deep features in the network have strong semantic information and are invariant to the appearance changes of the target . These semantic features can be used to complement SiamFC Appearance features used in target tracking tasks . Based on this discovery , We proposed SA-Siam, This is a double twin network , It consists of semantic branches and appearance branches . Each branch uses the twin network structure to calculate the similarity between the candidate image and the target image . In order to maintain the independence of the two branches , The two twin networks have nothing to do in the training process , It will only be combined during the test .
4. The second core of this paper : For the newly introduced semantic Branch , This paper further proposes the channel attention mechanism . When using the network to extract the features of the target object , Different targets activate different characteristic channels , We should give a high weight to the activated channel , This paper calculates the weights of these different layers through the response of the target object in the specific layer of the network . Experiments confirm that , In this way , It can further improve the discrimination of semantic twin Networks .
It is still used SiamFC During tracking, all frames are compared with the first frame , Is the main defect of this kind of method .
Related work
1.SiamFC: about A,B,C Three pictures , hypothesis C Pictures and A The picture is an object , But the appearance has changed ,B and A It doesn't matter .SiamFC Network input two pictures , So after SiamFC After get A and C High similarity ,A and B Low similarity . Through the above SiamFC The function of , Naturally, it can be used in target tracking algorithm .SiamFC The network has outstanding advantages : No need to be online fine-tune and end-to-end Tracking mode , So that it can do real-time tracking under the premise of ensuring the tracking effect .
2. Integrated tracker : Most tracking is a model A, Using models A Calculate the current data to get the tracking results , The integrated tracker has multiple models A,B,C, Analyze the current data respectively , Then we fuse the results to get the final tracking results . The semantic features of this paper + The appearance features draw on the idea of integrated tracker . In the integrated tracker , Model A,B,C The lower the correlation , The better the tracking effect , It's easy to understand , If the three of them are very relevant , Then there is no difference between using three and one , on this account , The semantic feature and appearance feature network in this paper are completely irrelevant in the training process .
frame

The proposed double SA-Siam The architecture of the network .A-Net Indicates appearance network . The network and data structures connected by dotted lines are similar to SiamFC Exactly the same .S-Net Represents the Semantic Web . Extract the features of the last two convolution layers . The channel attention module determines the weight of each characteristic channel based on the target and context information . Appearance branch and semantic branch are trained separately , Not until the test time .
1. Appearance branch ( The blue part )
One goal A Send to the network P in , A search domain larger than the target S Send to the network P in ,A The resulting feature map is similar to S The resulting characteristic graph is convoluted to obtain the correlation coefficient graph , The greater the correlation coefficient , The more likely it is to be the same goal , The network adopts and SiamFC The same network in .
Appearance branch with (z,X) For input . It cloned SiamFC The Internet . The convolution network used to extract appearance features is called A-Net. The response mapping from the appearance branch can be written as :
In the problem of similarity learning ,A-Net All parameters in are trained from scratch .
By minimizing the logical loss function L(·) To optimize A-Net, as follows :
among θa Express A-Net Parameters in ,N It's the number of training samples ,Yi yes ground truth Response .
2. Semantic Branch ( Orange part )
This is the focus of this article . Orange indicates Semantic Web , It is pre trained AlexNet, Fix all parameters during training and testing , Only extract the last conv4 and conv5 Characteristics of , The target template becomes zs,zs and X The same big as that , and z Have the same center , But it contains context information , Because the channel attention model is added to the branch , Determine the weight through the target and surrounding information , Choose a channel that has a greater impact on a specific tracking target . in addition , In order to better carry out subsequent related operations , The author adds the upper and lower branches to the fusion model , Joined the 1×1 The convolution of layer , Convolute each of the two extracted layers , Make the characteristic channels of the target template branch and the detection branch the same , And the total number of channels is the same as that of the appearance network .
When training semantic branch network, only channel attention module and fusion module are trained .
The response mapping from the semantic branch can be written as :
ξ Is the channel weight ,g() It is the fusion of features , Easy to operate .
Loss function L(·) as follows :
among θs Represents a trainable parameter ,N It's the number of training samples .
3. combination
The appearance network and semantic network are trained separately , Semantic network only trains channel attention module and fusion module . During the test time , The final response graph is calculated as the weighted average of the graphs from the two branches :
among λ Is the weighting parameter , To balance the importance of the two branches . In practice ,λ It can be estimated from the verification set . The author obtains through the experiment λ=0.3 best .
4. In the semantic Branch Channel Attention Mechanism
Why do you do this : The appearance of high-dimensional semantic features on the target ( The deformation of the picture 、 Spin, etc ) Change is robust , Resulting in low discrimination . In order to improve the discrimination of semantic branches , We designed a Channel Attention modular . Intuition , When tracking different objects , Different channels play different roles , Some channels are extremely important for some objects , But for other objects, it can be ignored , It may even introduce noise . If we can adaptively adjust the importance of channels , Then we will get the target and reliable feature expression . In order to achieve this goal , Not only is the goal important to us , The background in a certain range around it is also important for us , Therefore, the template of the input network here is one circle larger than the appearance Branch .
Now let's talk about how to realize this function .
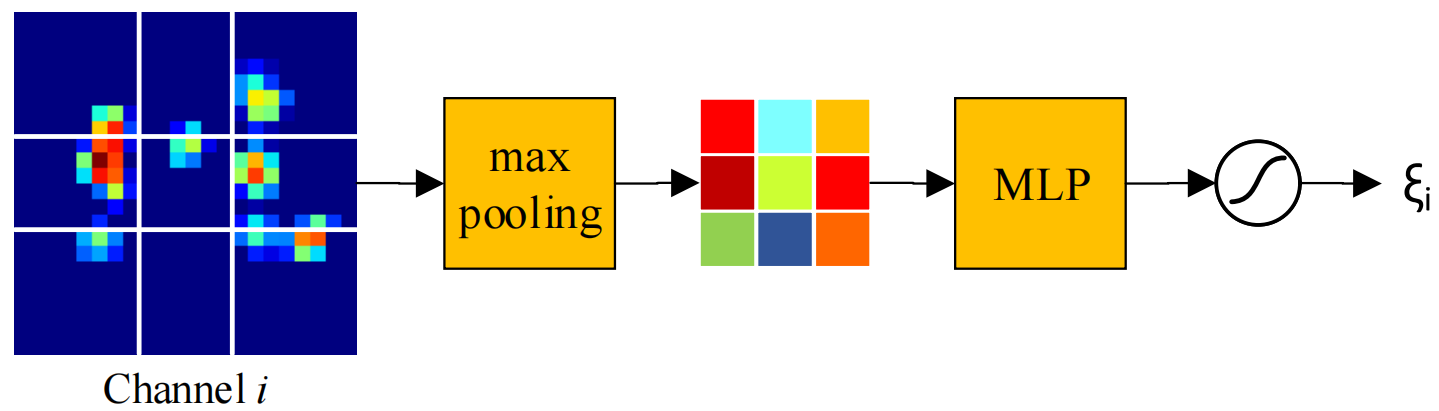
Channel attention passes through the maximized pool layer and multi-layer perceptron (MLP) Generate channels i The weighting coefficient of ξi.
In the above figure , The assumption is conv5 Layer of the first i Channel characteristic diagram , Dimension for 22×22, Divide the graph into 3×3 Share ( The middle one is 6×6, Is the exact goal ), after max-pooling Become after operation 3×3 Graph , After a two-layer MLP The Internet (Multi-Layer Perceptron Multilayer perceptron , contain 9 Neurons and a hidden layer , Hidden layer adoption ReLU function ) Score after , stay sigmoid once ( In order to make the score coefficient in 0~1 Between ) Get the final score coefficient . It is worth noting that : The score coefficient calculation operation here is only calculated in the first frame , Subsequent frames follow the results of the first frame , Therefore, the calculation time is negligible .
experiment
Data dimension : In our implementation , Target image block z The size is 127×127×3, also zs and X All have 255×255×3 The size of the . about z and X,A-Net The output features of have dimensions of 6×6×256 and 22×22×256. come from S-Net Of conv4 and conv5 The function has a size of 24×24×384 and 22×22×256 The tunnel zs and X. These two groups of functions 1×1 ConvNet Each output 128 Channels ( Up to 256 Channels ) ), The spatial resolution remains unchanged . The response graph has the same 17×17 dimension .

Learn more about programming , Please pay attention to my official account :

边栏推荐
- Mysql-04 storage engine and data type
- Unity学习笔记–无限地图
- [ostep] 04 virtualized CPU - process scheduling strategy
- SiamFC:用于目标跟踪的全卷积孪生网络
- Learning basic knowledge of Android security
- JS creative range select drag and drop plug-ins
- First knowledge of opencv4.x --- image perspective transformation
- 【2022国赛模拟】白楼剑——SAM、回滚莫队、二次离线
- ~6. CCF 2021-09-1 array derivation
- VBA 上传图片
猜你喜欢
自编码器 AE(AutoEncoder)程序

Win11 running virtual machine crashed? Solution to crash of VMware virtual machine running in win11

Keyboard shortcut to operate the computer (I won't encounter it myself)

Stacked noise reducing auto encoder (sdae)

Parsing XML files using Dom4j

Plato farm is expected to further expand its ecosystem through elephant swap

C# NanUI 相关功能整合
First knowledge of opencv4.x --- image perspective transformation

Siamrpn++: evolution of deep network connected visual tracking

OpenCV中图像算术操作与逻辑操作
随机推荐
CAS based SSO single point client configuration
全校软硬件基础设施一站式监控 ,苏州大学以时序数据库替换 PostgreSQL
目标跟踪相关知识总结
图神经网络Core数据集介绍
PyTorch的简单实现
.net6 encounter with the League of heroes - create a game assistant according to the official LCU API
Use of LINGO software
Unity学习笔记–无限地图
Self encoder AE (autoencoder) program
『SignalR』. Net using signalr for real-time communication
VP video structured framework
Would you please refer to the document of Database specification?
Multithreading - thread pool
Win11 running virtual machine crashed? Solution to crash of VMware virtual machine running in win11
Introduction to C language must brush the daily question of the collection of 100 questions (1-20)
如何评价测试质量?
【干货】MySQL索引背后的数据结构及算法原理
As the "first city" in Central China, Changsha's "talent attraction" has changed from competition to leadership
Some lightweight network models in detection and segmentation (share your own learning notes)
Seata deployment and microservice integration