当前位置:网站首页>并发概念基础:并发、同步、阻塞
并发概念基础:并发、同步、阻塞
2022-08-04 05:32:00 【real沛林】
多线程和并发
并发与多线程之间的关系就是目的与手段之间的关系。
并发(Concurrent)的反面是串行,串行好比多个车辆行驶在一股车道上,它们只能“鱼贯而行”。而并发好比多个车辆行驶在多股车道上,它们可以“并驾齐驱”。并发的极致就是并行(Parallel)。多线程就是将原本可能是串行的计算“改为”并发(并行)的一种手段、途径或者模型。
并行:在操作系统中,一组程序按独立异步的速度执行,无论从微观还是宏观,程序都是一起执行的。
因此,有时我们也称多线程编程为并发编程。当然,目的与手段之间常常是一对多的关系。并发编程还有其他的实现途径,例如函数式(Functional programming)编程。多线程编程往往是其他并发编程模型的基础,所以多线程编程的重要性不言而喻。
并发等级
1 阻塞
栗子:Synchronized和Lock
阻塞队列也是一种并发队列,但通常约定俗称阻塞队列是指阻塞并发队列,而并发队列是指非阻塞并发队列。
和并发队列的区别:在面对类似消费者-生产者模型时,就必须额外的实现同步策略以及线程间唤醒策略,这种就比较适合使用阻塞队列。
一个线程是阻塞的,那么在其他线程释放资源之前,当前线程无法继续执行。比如:使用synchronize关键字或者其他重入锁,我们得到的就是阻塞的线程。无论是synchronized或者重入锁,都会在试图执行后续代码前,得到临界区的锁,如果得不到,线程就会被挂起等待,直到占有了所需资源为止。
2 无饥饿(Starvation-Free)
如果线程之间是有优先级的,那么线程调度的时候总是会倾向于满足高优先级的线程。也就是说,对于同一个资源的分配,是不公平的。锁也分公平锁和非公平锁,对于非公平锁来说,系统允许高优先级的线程插队。这样就有可能导致低优先级的线程产生饥饿。但是如果是公平锁,满足先来后到,那么饥饿就不会产生,不管新来的线程优先级多高,要想获得资源,就必须乖乖排队。这样所有的线程都有机会执行。
3 无障碍(Obstruction-Free)
无障碍是一种最弱的非阻塞调度。两个线程如果是无障碍的执行,那么他们不会因为临界区的问题导致一方被挂起。换言之,大家都可以大摇大摆的进入临界区了。那么如果大家一起修改共享区数据,把数据修改坏了怎么办呢?对于无障碍的线程来说,一旦检测到这种情况,它就会立即对自己所做的修改进行回滚,确保数据安全。但是如果没有数据竞争发生,那么线程就可以顺利完成自己的工作,走出临界区。
从这个策略可以看出,无障碍的多线程程序不一定能顺畅的运行。因为当临界区中存在严重的冲突时,所有的线程可能都会不断的回滚自己的操作,导致没有一个线程能顺利走出临界区。这种情况会影响系统的正常执行。
一种可行的无障碍实现可以依赖一个“一致性标记”来实现,比如modCount:线程在操作之前,先读取并保存这个标记,在操作完成之后,再次读取,检查这个标记是否更改过,如果两者是一致的,则说明资源访问没有冲突。如果不一致,则说明资源可能在操作过程中与其他线程存在冲突,需要重新操作。而任何对资源有修改操作的线程,在修改数据前,都需要更新这个一致性的标记,表示数据不再安全。
4 无锁(Lock-Free)
CAS
无锁的并行都是无障碍的。在无锁的情况下,所有的线程都能尝试对临界区进行访问,但不同的是,无锁的并发保证必然有一个线程能够在有限步内完成操作走出临界区。
在无锁的调用中,一个典型的特点是可能会包含一个无线循环。在这个循环中,线程会不断尝试修改共享变量,如果没有冲突,修改成功,那么程序退出。否则继续尝试修改,但无论如何,无锁的并行总能保证一个线程胜出,不会全军覆没。至于临界区中竞争失败的线程,它们则必须不断重试,直到自己获胜,如果运气不好,总是不成功,则会出现饥饿的现象,线程会停止不前。
5 无等待(Wait-Free)
CopyOnWriteArrayList是一种典型的无等待实现
无锁只要求一个线程可以在有限步数内完成操作,而无等待则是在无锁的基础上更进一步进行扩展,它要求所有的线程都必须在有限步数内完成,这样就不会引起线程饥饿问题。
一种典型的无等待结构是RCU(Read-Copy-Update)。它的基本思想是,对数据的读可以不加控制。因此,所有的读操作是无等待的,他们既不会被锁定等待也不会引起任何冲突。但是在写数据的时候,先取得原始数据的副本,接着只修改副本数据(这就是为什么读可不加控制),修改完成后,在合适的时机回写数据。
并发和同步
由并发容器和同步容器的区别可以厘清概念上的差别
同步容器存在的问题
早期的JDK在java.util包中提供了Vector和HashTable两个同步容器,这两个容器的实现和早期的ArrayList和HashMap代码实现基本一样,不同在于Vector和HashTable在每个方法上都添加了synchronized关键字来保证同一个实例同时只有一个线程能访问
- 不论读还是写都会锁住整个容器
- 当多个线程进行复合操作时,是线程不安全的。可以通过下面的代码来说明这个问题:
//代码中对Vector进行了两步操作,首先获取size,然后移除最后一个元素,
//多线程情况下如果两个线程交叉执行,A线程调用size后,B线程移除最后一个元素,
//这时A线程继续remove将会抛出索引超出的错误。
//那么怎么解决这个问题呢?最直接的修改方案就是对代码块加锁来防止多线程同时执行
public static void deleteVector(){
int index = vectors.size() - 1;
vectors.remove(index);
}
同步容器:会导致多个线程中对容器方法调用的串行执行,降低并发性,因为它们都是以容器自身对象为锁,所以在需要支持并发的环境中,可以考虑使用并发容器来替代。
并发容器:并发容器是针对多个线程并发访问设计的,在jdk5.0引入了concurrent包,其中提供了很多并发容器,并发容器使用了与同步容器完全不同的加锁策略来提供更高的并发性和伸缩性
同步与异步、阻塞与非阻塞
本文所讨论的同步与异步,是指对于请求的发起者,是否需要等到请求的结果(同步),还是说请求完毕的时候以某种方式通知请求发起者(异步)。
在这个语义环境下,阻塞与非阻塞,是指请求的受理者在处理某个请求的状态,如果在处理这个请求的时候不能做其它事情(请求处理时间不确定),那么称之为阻塞,否则为非阻塞。
这里的阻塞原出处是线程5个状态中的"阻塞"。
生活示例1:
出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
1 老张把水壶放到火上,立等水开。(同步阻塞)
老张觉得自己有点傻
2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)
老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀~~~~的噪音。
3 老张把响水壶放到火上,立等水开。(异步阻塞)
老张觉得这样傻等意义不大
4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
老张觉得自己聪明了。
所谓同步异步,只是对于水壶而言。
普通水壶,同步;响水壶,异步。
虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。这是普通水壶所不能及的。
同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
所谓阻塞非阻塞,仅仅对于老张而言。
立等的老张,阻塞;看电视的老张,非阻塞。
情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
</>
生活示例2:
我去柜台办理业务,那我是请求者,柜员时受理者。如果我在柜台一直等着柜员办理,直到办理完毕,那么对于我来说,就是同步的;如果我只是在柜员那里登记,然后到一边歇着,等柜员办理完毕之后告诉我结果,那么就是异步的。对于柜员,办理业务的时候可能需要等待打印机打印,如果在这个时候柜员去处理其他人的业务,那么就是非阻塞的,如果一定得到把我的业务办完再接待下一位顾客,那么就是阻塞的。
程序示例
本文站在请求发起者的角度来思考同步与异步,在实际开发中,一个最简单的例子就是 http 请求。假设这么一个场景,程序需要访问两个网址(通过 url),如果只有一个线程。那么同步与异步分别怎么处理呢
python 的 urllib 是同步的,即当一个请求结束之后才能发起下一个请求,我们知道 http 请求基于 tcp,tcp 又需要三次握手建立连接(https 的握手会更加复杂),在这个过程中,程序很多时候都在等待IO,CPU 空闲,但是又不能做其他事情。但同步模式的优点是比较直观,符合人类的思维习惯: 那就是一件一件的来,干完一件事再开始下一件事。在同步模式下,要想发挥多核 CPU 的威力,可以使用多进程或者多线程(注意 python 的多线程并不能发挥多核,严格意义上是单线程)。
如果发出了请求就立即返回,这个时候程序可以做其他事情,等请求完成了时候通过某种方式告知结果,然后请求者再继续再来处理请求结果,那么我们称之为异步,最常见的就是回调(callback),在 python 中,tornado 提供了异步的 http 请求。
异步的优势所在:不用在 IO 上等待,在单核 CPU 上就有更好的性能。
IO示例:
再说一下IO发生时涉及的对象和步骤。
对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
1 等待数据准备 (Waiting for the data to be ready)
2 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO Model的区别就是在两个阶段上各有不同的情况。
blocking IO
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样: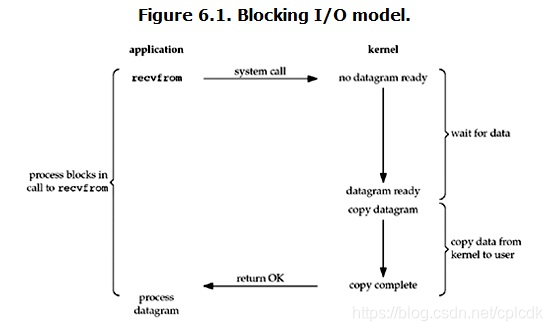
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
non-blocking IO
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子: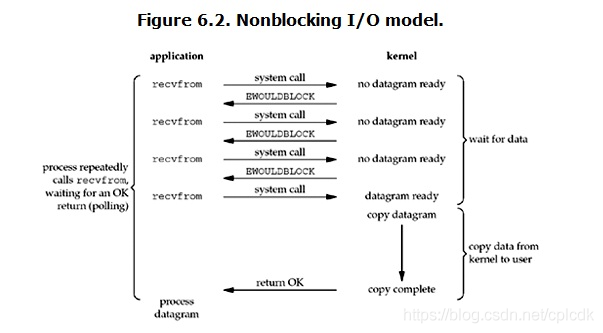
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,用户进程其实是需要不断的主动询问kernel数据好了没有。
IO multiplexing
IO multiplexing这个词可能有点陌生,但是如果我说select,epoll,大概就都能明白了。有些地方也称这种IO方式为event driven IO。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
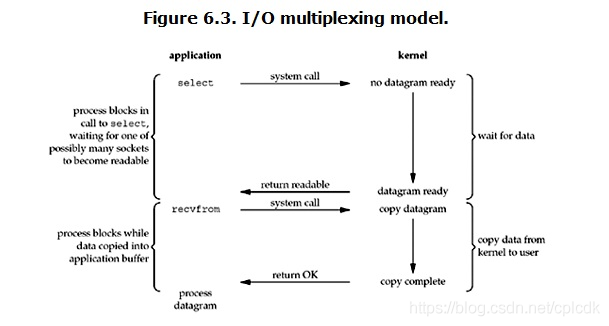
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。(多说一句。所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
Asynchronous I/O
linux下的asynchronous IO其实用得很少。先看一下它的流程:
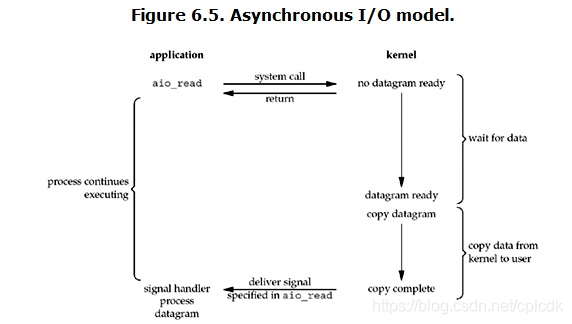
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
到目前为止,已经将四个IO Model都介绍完了。现在回过头来回答最初的那几个问题:blocking和non-blocking的区别在哪,synchronous IO和asynchronous IO的区别在哪。
先回答最简单的这个:blocking vs non-blocking。前面的介绍中其实已经很明确的说明了这两者的区别。调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。Stevens给出的定义(其实是POSIX的定义)是这样子的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
各个IO Model的比较如图所示:

经过上面的介绍,会发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
最后,再举几个不是很恰当的例子来说明这四个IO Model:
有A,B,C,D四个人在钓鱼:
A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆;
B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,隔会再看看有没有鱼上钩,有的话就迅速拉杆;
C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来;
D是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给D发个短信。
边栏推荐
猜你喜欢





随机推荐
IEEE802.X protocol suite
安装MySQL的详细步骤
多线程顺序输出
指针运算相关面试题详解【C语言】
C语言静态变量static的分析
跑跑飞弹室外跑步AR游戏代码方案设计
[Development miscellaneous][Debug]debug into kernel
2020-03-27
Vmmem 进程(WSL2)消耗内存巨大
网络通信与Socket编程概述
位段-C语言
调用时序错误导致webrtc无法建立链接
题目1000:输入两个整数a和b,计算a+b的和,此题是多组测试数据
Tensorflow/Pytorch安装(Anaconda环境下,无版本冲突,亲测有效)
Windows10重置MySQL用户密码
【五一专属】阿里云ECS大测评#五一专属|向所有热爱分享的“技术劳动者”致敬#
MNIST handwritten digit recognition - based on Mindspore to quickly build a perceptron to achieve ten categories
Deep learning, "grain and grass" first--On the way to obtain data sets
Object. RequireNonNull method
LeetCode_Nov_3rd_Week