当前位置:网站首页>"Actual Combat" based on part-of-speech extraction in the field of e-commerce and its decision tree model modeling
"Actual Combat" based on part-of-speech extraction in the field of e-commerce and its decision tree model modeling
2022-07-31 00:58:00 【The young man who rides the wind】
——Text sentiment analysis and topic mining based on e-commerce——
一、数据预处理
This time the goal is achieved
1、Use text mining techniques,对碎片化、Unstructured e-commerce website comment data is cleaned and processed,转化为结构化数据.
2、Refer to the term set for sentiment analysis published by CNKI,Positive and negative sentiment index of statistical review data,然后进行情感分析,Visually view the keywords of positive and negative comments through the word cloud graph.
3、比较“The positive and negative emotions of machine mining”与“Positive and negative emotions of manual tagging”.
4、采用LDATopic models extract key information from reviews,to understand the needs of users、意见、购买原因、Product advantages and disadvantages, etc.
导入所需要的工具包
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.pylab import style #自定义图表风格
style.use('ggplot')
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
plt.rcParams['font.sans-serif'] = ['Simhei'] # 解决中文乱码问题
import re
import jieba.posseg as psg
import itertools
#conda install -c anaconda gensim
from gensim import corpora,models #主题挖掘,提取关键信息
# pip install wordcloud
from wordcloud import WordCloud,ImageColorGenerator
from collections import Counter
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
import graphviz
导入数据
raw_data=pd.read_csv('./reviews.csv')
raw_data.head()
Mainly has comment text、时间、用户名、商品名称、User sentiment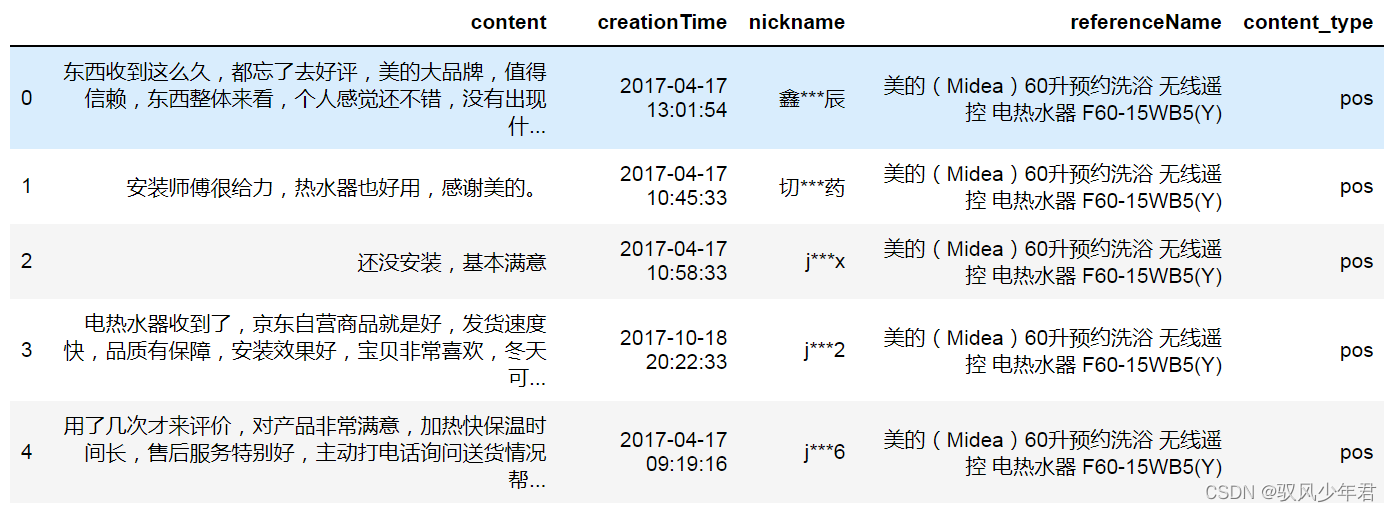
查看数据大致分布,有无缺失值
raw_data.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 2000 entries, 0 to 1999
Data columns (total 5 columns):
content 2000 non-null object
creationTime 2000 non-null object
nickname 2000 non-null object
referenceName 2000 non-null object
content_type 2000 non-null object
dtypes: object(5)
memory usage: 78.2+ KB
查看数据列名
raw_data.columns
Index([‘content’, ‘creationTime’, ‘nickname’, ‘referenceName’, ‘content_type’], dtype=‘object’)
Look under each column often,样本统计
#取值分布
for cate in ['creationTime', 'nickname', 'referenceName', 'content_type']:
raw_data[cate].value_counts()
#取值分布
2016-06-24 22:35:42 2
2015-06-25 17:36:36 2
2016-06-24 17:42:26 2
2016-06-20 16:03:00 2
2017-10-06 13:12:19 1
…
2017-10-22 08:08:35 1
2017-03-25 15:59:46 1
2017-10-01 10:13:38 1
2017-07-03 13:10:14 1
2017-03-19 10:19:17 1
Name: creationTime, Length: 1996, dtype: int64
j1 34
j6 30
j2 25
jb 25
jf 23
…
a1 1
切药 1
无主 1
小热 1
费能 1
Name: nickname, Length: 1190, dtype: int64
美的(Midea)60l Schedule a bath 无线遥控 电热水器 F60-15WB5(Y) 2000
Name: referenceName, dtype: int64
neg 1000
pos 1000
Name: content_type, dtype: int64
二、词性提取
2.1 去重
Make a copy of the data first,Then de-emphasize comments and emotional tendencies
reviews=raw_data.copy()
reviews=reviews[['content', 'content_type']]
print('去重之前:',reviews.shape[0])
reviews=reviews.drop_duplicates()
print('去重之后:',reviews.shape[0])
去重之前: 2000
去重之后: 1974
2.2 数据清洗
# 清洗之前
content=reviews['content']
for i in range(5,10):
print(content[i])
print('-----------')
物美价廉啊,特别划算的,And it heats up fast.It is very convenient to use at home
-----------
价格合理,配置挺高,Good value
-----------
Teachers are quick to dress up,装修中.没试.Hope is normal!
-----------
Five points is a habit
Fast delivery,It's also fast,很好,But renovations are in progress,Only a water heater is installed for the ceiling,Let's talk about other things later.
我也是醉了,The water heater remote has no batteries,Or the installation brother has a spare in the car to install.
Electric toothbrush to give away,The air purifier is waiting for delivery…….
Refrigerator drops in one day100、Washing machine down40、Water heater down100、The little chef is down30、Smoke stove set down100.But customer service said to report it,Phone notification pending……
-----------
The guy who installed it is very good,Work hard,Our house is an old house,Installation is more laborious than the average home.Installed very well.Because the whole building needs hot water,Skirts can only be worn like this.Kudos to my brother.Bought two water heaters,Works great as always.Beautiful big brand,质量非常好
-----------
Combine the brand name in the text with the number letters,Clean with regular
#清洗之后,将数字、字母、The words on Jingdongmei's electric water heaters have been deleted
info=re.compile('[0-9a-zA-Z]|京东|美的|电热水器|热水器|')
content=content.apply(lambda x: info.sub('',x)) #替换所有匹配项
for i in range(5,10):
print(content[i])
print('-----------')
物美价廉啊,特别划算的,And it heats up fast.It is very convenient to use at home
-----------
价格合理,配置挺高,Good value
-----------
Teachers are quick to dress up,装修中.没试.Hope is normal!
-----------
Five points is a habit
Fast delivery,It's also fast,很好,But renovations are in progress,I only installed it for the ceiling,Let's talk about other things later.
我也是醉了,The remote control has no batteries,Or the installation brother has a spare in the car to install.
Electric toothbrush to give away,The air purifier is waiting for delivery&;&;.
Refrigerator drops in one day、Washing machine down、降、The little chef is down、Smoke stove set down.But customer service said to report it,Phone notification pending&;&;
-----------
The guy who installed it is very good,Work hard,Our house is an old house,Installation is more laborious than the average home.Installed very well.Because the whole building needs hot water,Skirts can only be worn like this.Kudos to my brother.Bought two already,Works great as always.大品牌,质量非常好
-----------
清洗后,文本中的数字、The letters have been washed out
Save the cleaned text tocontent变量中
print(len(content))
1974
2.3 分词、词性标注、去除停用词、词云图
2.3.1 Extract the words and their parts of speech for each text
输入:
- content、content_type
- 共有1974comment sentence
输出:
- 构造DF,包含: 分词、Corresponding part of speech、participle of the original sentenceid、participle of the original sentencecontent_type
- 共有6万多行
非结构化数据——>结构化数据
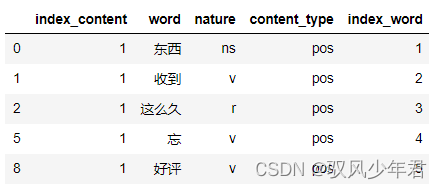
Tokenize each text,And remove the words from each text,and the part of speech of the corresponding word.主要通过import jieba.posseg as psg 实现
案例
def cut_word(s):
for x in psg.cut(s):
print((x.word,x.flag))
cut_word('物美价廉啊,特别划算的,And it heats up fast.It is very convenient to use at home')
输出结果
('物美价廉', 'l')
('啊', 'zg')
(',', 'x')
('特别', 'd')
('划算', 'v')
('的', 'uj')
(',', 'x')
('而且', 'c')
('加热', 'v')
('速度', 'n')
('快', 'a')
('.', 'x')
('家里', 's')
('用', 'p')
('着', 'uz')
('不错', 'a')
('特别', 'd')
('方便', 'a')
The actual operation is implemented with anonymous functions
#分词,由元组组成的list
seg_content=content.apply( lambda s: [(x.word,x.flag) for x in psg.cut(s)] )
seg_content.shape
len(seg_content)
print(seg_content[5])
(1974,)
1974
[(‘物美价廉’, ‘l’), (‘啊’, ‘zg’), (‘,’, ‘x’), (‘特别’, ‘d’), (‘划算’, ‘v’), (‘的’, ‘uj’), (‘,’, ‘x’), (‘而且’, ‘c’), (‘加热’, ‘v’), (‘速度’, ‘n’), (‘快’, ‘a’), (‘.’, ‘x’), (‘家里’, ‘s’), (‘用’, ‘p’), (‘着’, ‘uz’), (‘不错’, ‘a’), (‘特别’, ‘d’), (‘方便’, ‘a’)]
Count the number of word comments
Count out each comment,词+The total number of symbol occurrences,保存到n_word中
#统计评论词数
n_word=seg_content.apply(lambda s: len(s))
len(n_word)
n_word.head(6)
1974
0 32
1 11
2 6
3 39
4 44
5 18
Name: content, dtype: int64
Build each word,the corresponding comment
示例
seg_content.indexComment sequence
Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
…
1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999],
dtype=‘int64’, length=1974)
for x,y in zip(list(seg_content.index),list(n_word)):
print([x+1]*y)
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
[3, 3, 3, 3, 3, 3]
[4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4]
[5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5]
[6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
[7, 7, 7, 7, 7, 7, 7, 7]
[8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8]
[9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9]
[10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10]
[11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11]
[12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12]
sum([[2,2],[3,3,3]],[])
Take off the list
[2, 2, 3, 3, 3]
实际应用
#得到各分词在第几条评论
n_content=[ [x+1]*y for x,y in zip(list(seg_content.index),list(n_word))] #[x+1]*y,表示复制y份,由list组成的list
print('-----------Get the number of the comment corresponding to the word---------')
print(n_content[:2])
index_content_long=sum(n_content,[]) #表示去掉[],拉平,返回list
len(index_content_long)
print('----------去掉[],Stretch the ordinal list-----------')
print(index_content_long[:43])
-----------Get the number of the comment corresponding to the word---------
[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]]
63794
----------去掉[],Stretch the ordinal list-----------
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
分词及词性,去掉[],拉平
The comments after the participle are also removed[],合并
#分词及词性,去掉[],拉平
print('原始数据:','\n',seg_content.head())
seg_content_long=sum(seg_content,[])
type(seg_content_long)
print('去掉[],数据:','\n',seg_content_long[:5])
len(seg_content_long)
原始数据:
0 [(东西, ns), (收到, v), (这么久, r), (,, x), (都, d), …
1 [(安装, v), (师傅, nr), (很, d), (给, p), (力, n), (,…
2 [(还, d), (没, v), (安装, v), (,, x), (基本, n), (满意…
3 [(收到, v), (了, ul), (,, x), (自营, vn), (商品, n), …
4 [(用, p), (了, ul), (几次, m), (才, d), (来, v), (评价…
Name: content, dtype: object
list
去掉[],数据:
[(‘东西’, ‘ns’), (‘收到’, ‘v’), (‘这么久’, ‘r’), (‘,’, ‘x’), (‘都’, ‘d’)]
63794
Obtain words and their parts of speech separately
#得到加长版的分词、词性
word_long=[x[0] for x in seg_content_long]
nature_long=[x[1] for x in seg_content_long]
print(word_long[:5])
print(nature_long[:5])
len(word_long)
len(nature_long)
[‘东西’, ‘收到’, ‘这么久’, ‘,’, ‘都’]
[‘ns’, ‘v’, ‘r’, ‘x’, ‘d’]
63794
63794
content_type拉长
#content_type拉长
n_content_type=[ [x]*y for x,y in zip(list(reviews['content_type']),list(n_word))] #[x+1]*y,表示复制y份
content_type_long=sum(n_content_type,[]) #表示去掉[],拉平
len(content_type_long)
print('情感倾向:',content_type_long[:5])
63794
情感倾向: [‘pos’, ‘pos’, ‘pos’, ‘pos’, ‘pos’]
保存到Dataframe中
review_long=pd.DataFrame({
'index_content':index_content_long,
'word':word_long,
'nature':nature_long,
'content_type':content_type_long})
review_long.shape
review_long.head()
(63794, 4)

2.3.2 去除标点符号、去除停用词
review_long['nature'].unique()
array([‘ns’, ‘v’, ‘r’, ‘x’, ‘d’, ‘ul’, ‘a’, ‘n’, ‘u’, ‘nr’, ‘p’, ‘y’,
‘vn’, ‘t’, ‘c’, ‘m’, ‘l’, ‘b’, ‘i’, ‘uj’, ‘zg’, ‘s’, ‘uz’, ‘nz’,
‘f’, ‘uv’, ‘ad’, ‘q’, ‘j’, ‘g’, ‘ud’, ‘an’, ‘nrt’, ‘vg’, ‘ng’, ‘k’,
‘o’, ‘mq’, ‘df’, ‘e’, ‘vd’, ‘z’, ‘nt’, ‘tg’, ‘rz’, ‘ug’, ‘yg’, ‘h’,
‘vq’, ‘ag’, ‘rr’], dtype=object)
其中x表示标点符号
#去除标点符号
review_long_clean=review_long[review_long['nature']!='x'] #x表示标点符合
review_long_clean.shape
(51436, 4)
原本有 63794, After removal only51436行.
#导入停用词
stop_path=open('./stoplist.txt','r',encoding='UTF-8')
stop_words=stop_path.readlines()
len(stop_words)
stop_words[0:5]
#停用词,预处理,去除换行符号
stop_words=[word.strip('\n') for word in stop_words]
stop_words[0:5]
5748
[‘\ufeff \n’, ‘说\n’, ‘人\n’, ‘元\n’, ‘hellip\n’]
['\ufeff ', ‘说’, ‘人’, ‘元’, ‘hellip’]
#得到不含停用词的分词表
word_long_clean=list(set(word_long)-set(stop_words))
len(word_long_clean)
review_long_clean=review_long_clean[review_long_clean['word'].isin(word_long_clean)]
review_long_clean.shape
Remove stop words from comments
#得到不含停用词的分词表
word_long_clean=list(set(word_long)-set(stop_words))
print('All words in the text together:',len(set(word_long)))
print('Stop words are all words in total:',len(set(stop_words)))
print('去除停用词后,No repetitions in total:',len(set(word_long_clean)))
review_long_clean=review_long_clean[review_long_clean['word'].isin(word_long_clean)]
print('去除停用词后,剩下:',len(review_long_clean))
All words in the text together: 5135
Stop words are all words in total: 1905
去除停用词后,No repetitions in total: 4455
去除停用词后,剩下: 25172
2.3.3 在原df中,再增加一列,该分词在本条评论的位置
```python
#再次统计每条评论的分词数量
n_word=review_long_clean.groupby('index_content').count()['word']
print('去除停用词后,The number of word segmentations per text:','\n',n_word)
index_word=[ list(np.arange(1,x+1)) for x in list(n_word)]
index_word_long=sum(index_word,[]) #表示去掉[],拉平
len(index_word_long)
print('去除停用词后,From each text1开始编号:','\n',index_word_long[:20])
去除停用词后,The number of word segmentations per text:
index_content
1 14
2 4
3 2
4 20
5 23
…
1996 6
1997 20
1998 3
1999 10
2000 4
Name: word, Length: 1964, dtype: int64
25172
去除停用词后,From each text1开始编号:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 1, 2, 3, 4, 1, 2]
添加到df中进去
review_long_clean['index_word']=index_word_long
review_long_clean.head()
index_contentIndicates the comment number,index_wordIndicates the comment number
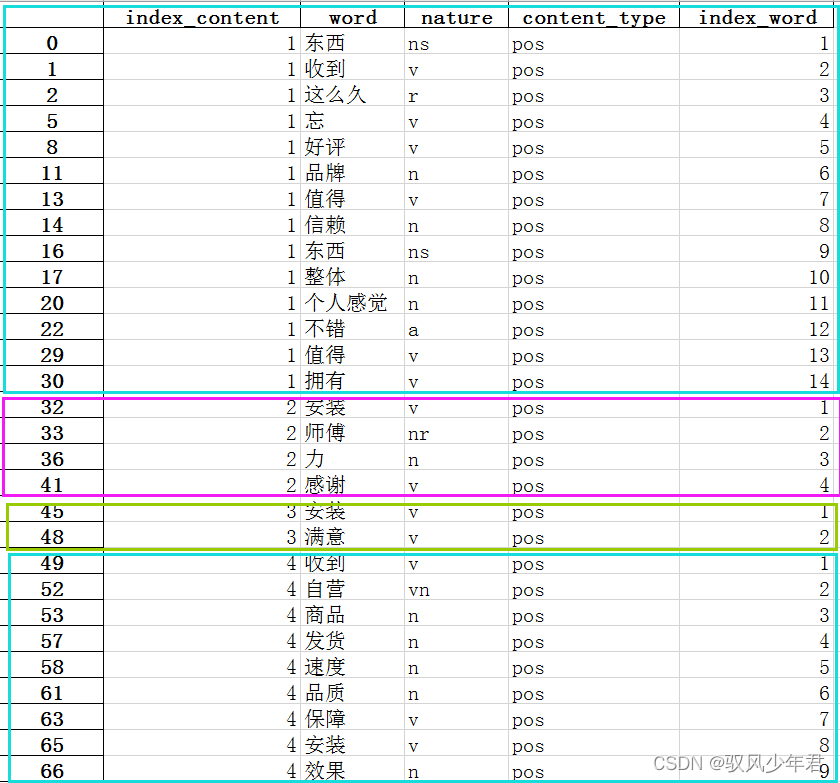
review_long_clean.to_csv('./1_review_long_clean.csv') #保存为csv格式
review_long_clean.to_excel('./1_review_long_clean.xlsx')#保存为xlsx格式
2.3.4 提取名词
Extract nouns from the text
n_review_long_clean=review_long_clean[[ 'n' in nat for nat in review_long_clean.nature]]
n_review_long_clean.shape
n_review_long_clean.head()
(10189, 5)
统计,并且保存
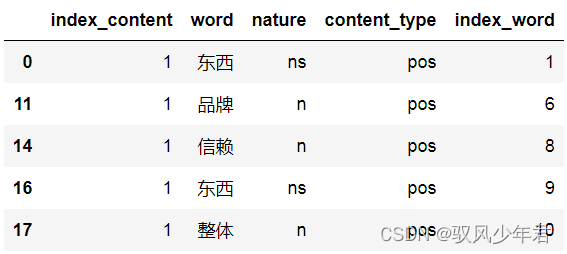
n_review_long_clean.nature.value_counts()
n_review_long_clean.to_csv('./1_n_review_long_clean.csv')
2.3.5 绘制词云
Word cloud diagram of all words
Counter(review_long_clean.word.values)
Counter({‘东西’: 224,
‘收到’: 85,
‘这么久’: 4,
‘忘’: 5,
‘好评’: 81,
‘品牌’: 120,
‘值得’: 110,
‘信赖’: 100,
‘整体’: 14,
‘个人感觉’: 1,
‘不错’: 309,
‘拥有’: 13,
‘安装’: 1626,
‘师傅’: 502,
‘力’: 68,
‘感谢’: 14,
‘满意’: 185,
font=r"C:\Windows\Fonts\msyh.ttc"
background_image=plt.imread('./pl.jpg')
wordcloud = WordCloud(font_path=font,
max_words = 100,
mask=background_image,
background_color='white'
) #width=1600,height=1200, mode='RGBA'
wordcloud.generate_from_frequencies(Counter(review_long_clean.word.values))
wordcloud.to_file('1_分词后的词云图.png')
plt.figure(figsize=(20,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

Word cloud for nouns
Counter(n_review_long_clean.word.values)
Counter({‘东西’: 224,
‘品牌’: 120,
‘信赖’: 100,
‘整体’: 14,
‘个人感觉’: 1,
‘师傅’: 502,
‘力’: 68,
‘自营’: 23,
‘商品’: 47,
‘发货’: 33,
‘速度’: 129,
‘品质’: 14,
‘效果’: 36,
‘宝贝’: 15,
‘小时’: 85,
‘热水’: 83,
‘评价’: 48,
‘产品’: 118,
font=r"C:\Windows\Fonts\msyh.ttc"
background_image=plt.imread('./pl.jpg')
wordcloud = WordCloud(font_path=font,
max_words = 100,
mode='RGBA' ,
background_color='white',
mask=background_image) #width=1600,height=1200
wordcloud.generate_from_frequencies(Counter(n_review_long_clean.word.values))
wordcloud.to_file('1_分词后的词云图(名词).png')
plt.figure(figsize=(20,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

三、决策树分类模型
3.1 Construct feature space and labels
The word for each comment will be refined,再合并起来
#第一步:Construct feature space and labels
Y=[]
for ind in review_long_clean.index_content.unique():
y=[ word for word in review_long_clean.content_type[review_long_clean.index_content==ind].unique() ]
Y.append(y)
len(Y)
X=[]
for ind in review_long_clean.index_content.unique():
term=[ word for word in review_long_clean.word[review_long_clean.index_content==ind].values ]
X.append(' '.join(term))
len(X)
X
Y
[‘东西 收到 这么久 忘 好评 品牌 值得 信赖 东西 整体 个人感觉 不错 值得 拥有’,
‘安装 师傅 力 感谢’,
‘安装 满意’,
‘收到 自营 商品 发货 速度 品质 保障 安装 效果 宝贝 喜欢 冬天 小时 热水 自营 值得 信赖 值得 推荐 自营’,
‘几次 评价 产品 满意 加热 保温 时间 长 售后服务 特别 主动 打电话 询问 送货 情况 帮 安装 非常感谢 售后 大姐 服务 下次 购买’,
‘物美价廉 特别 划算 加热 速度 家里 不错 特别’,
‘价格合理 配置 高 物美 价值’,
‘老师 装 装修 中 试 希望’,
‘五分 习惯 送 装 装修 中 吊顶 装 话 醉 遥控器 电池 安装 哥 车里 备用 to install 赠送 电动牙刷 空气 净化器 等待 配送 中 时间 冰箱 降 洗衣机 降 降 小厨 Bao drop 烟灶 Set drop 客服 上报 解决 电话 通知 等待 中’,
‘安装 小哥 工作 尽心 家 老房子 安装 家 费力 安装 不错 整栋 楼 热水 裙子 只能 装 小哥 点 赞 二个 一如既往 好用 品牌 质量’,
‘前 天下 单买 用上 发现 街上 卖 便宜 店家 网上 他家 贵 老板 面 网上’,
‘冲着 以内 变频 级 能效 制冷 效果 不错’,
‘购物 电器 问 型号 型号 相识 家电 下线 安装 师傅 挺好 加热 很快 购物 满意 walk with 安装费 Flower Yuan 喷头 槊 料 花 伞 安装 麻烦’,
‘物流 早上 送来 中午 安装 安装 安装 师傅 负责 效果 售后 确实’,
‘满意 价格 产品质量 货运 安装 调试 工作人员 服务态度 售后服务’,
‘收费 安装 速度 很快 管道 走 整齐 不错’,
…]
[[‘pos’],
[‘pos’],
[‘pos’],
[‘pos’],
[‘pos’],
[‘pos’],
[‘pos’],
[‘pos’],
[‘pos’],
[‘pos’],
…]
3.2 构建模型
The text vector is mainly constructed using the bag-of-words model,可以换成TFIDF应该会更好
#第二步:训练集、测试集划分
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=7)
#第三步:词转向量,01矩阵
count_vec=CountVectorizer(binary=True)
x_train=count_vec.fit_transform(x_train)
x_test=count_vec.transform(x_test)
#第四步:构建决策树
dtc=tree.DecisionTreeClassifier(max_depth=5)
dtc.fit(x_train,y_train)
print('accuracy on the training set:%.2f'% accuracy_score(y_train,dtc.predict(x_train)))
y_true=y_test
y_pred=dtc.predict(x_test)
print(classification_report(y_true,y_pred))
print('在测试集上的准确率:%.2f'% accuracy_score(y_true,y_pred))
DecisionTreeClassifier(max_depth=5)
accuracy on the training set:0.72
precision recall f1-score support
neg 0.63 0.96 0.76 197
pos 0.92 0.44 0.60 196
accuracy 0.70 393
macro avg 0.78 0.70 0.68 393
weighted avg 0.77 0.70 0.68 393
在测试集上的准确率:0.70
3.3绘制决策树
#第五步:画决策树
cwd=os.getcwd()
dot_data=tree.export_graphviz(dtc
,out_file=None
,feature_names=count_vec.get_feature_names())
graph=graphviz.Source(dot_data)
graph.format='svg'
graph.render(cwd+'/tree',view=True)
graph

边栏推荐
- GO GOPROXY proxy Settings
- ShardingSphere's vertical sub-database sub-table actual combat (5)
- ShardingSphere之水平分库实战(四)
- Why use high-defense CDN when financial, government and enterprises are attacked?
- 射频器件的基本参数1
- tensorflow与GPU版本对应安装问题
- What is Promise?What is the principle of Promise?How to use Promises?
- MySQL——数据库的查,增,删
- Typescript14 - (type) of the specified parameters and return values alone
- Summary of MySQL database interview questions (2022 latest version)
猜你喜欢

typescript12 - union types
What is Promise?What is the principle of Promise?How to use Promises?

ShardingSphere's unsharded table configuration combat (6)

响应式布局与px/em/rem的比对

MySQL的触发器

RTL8720DN开发笔记一 环境搭建与mqtt实例
基于Keras_bert模型的Bert使用与字词预测

Kotlin协程:协程上下文与上下文元素

小黑leetcode之旅:104. 二叉树的最大深度
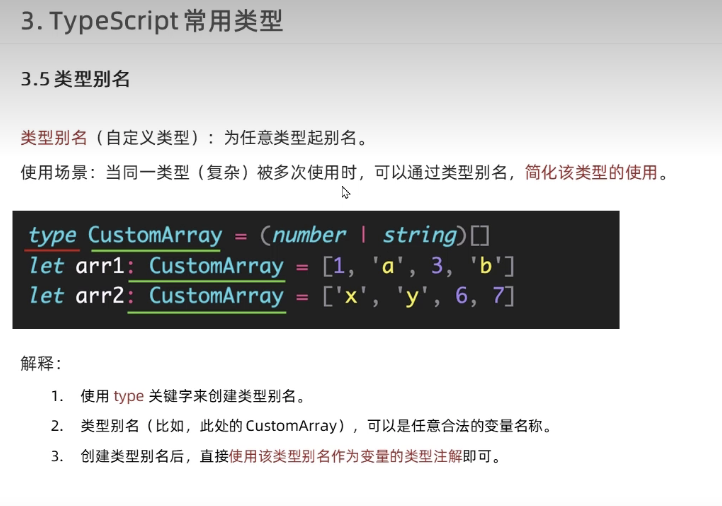
typescript13 - type aliases
随机推荐
这个项目太有极客范儿了
华为“天才少年”稚晖君又出新作,从零开始造“客制化”智能键盘
typescript17-函数可选参数
VS warning LNK4099:未找到 PDB 的解决方案
typescript11-数据类型
一万了解 Gateway 知识点
GO GOPROXY proxy Settings
Unity2D horizontal version game tutorial 4 - item collection and physical materials
【Demo】ABAP Base64加解密测试
Go study notes (84) - Go project directory structure
[C language course design] C language campus card management system
typescript18-对象类型
ShardingSphere之读写分离(八)
ShardingSphere之公共表实战(七)
基于Keras_bert模型的Bert使用与字词预测
typescript15-(同时指定参数和返回值类型)
How to Add a Navigation Menu on Your WordPress Site
redis学习
Kotlin协程:协程上下文与上下文元素
Oracle has a weird temporary table space shortage problem