当前位置:网站首页>pytorch 常见报错
pytorch 常见报错
2022-07-27 17:10:00 【遨游的菜鸡】
文章目录
1.RuntimeError: cuda runtime error (59) : device-side assert triggered
分类时有数据的标签超出了分类数目的标签、或者小于0,就会报这个错。
比如数据的标签从0开始,最大标签值是118,那么self.fc=nn.Linear(hidden_size,118)就会报错,因为从0到118,共119个类别
改正:因此self.fc=nn.Linear(hidden_size,119)
https://www.cnblogs.com/henuliulei/p/13258297.html
https://blog.csdn.net/qq_31049727/article/details/90671689
2.CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling cublasCreate(handle)
当时报这个错的时候是因为发生了错误1当中的标签值和分类数目不匹配的结果,即标签值从0到118,但我给的分类数目是80,即self.fc=nn.Linear(hidden_size,80),这样就会报错。
改正:当时分类数目给定80是因为set(train_label)=80,即0-118并不是连续的,有些值没有用到,因此要对数据的标签值进行重新划分,既让数据得标签值变成连续的,范围为0-79或1-80
3.pytorch BrokenPipeError: [Errno 32] Broken pipe
该问题的产生是由于windows下多线程的问题,和DataLoader类有关,具体细节点这里Fix memory leak when using multiple workers on Windows。
解决方案:
修改调用torch.utils.data.DataLoader()函数时的 num_workers 参数。该参数官方API解释如下:
num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
该参数是指在进行数据集加载时,启用的线程数目。截止当前2018年5月9日11:15:52,如官方未解决该BUG,则可以通过修改num_works参数为 0 ,只启用一个主进程加载数据集,避免在windows使用多线程即可。
或者将电脑无用程序关闭:
https://blog.csdn.net/u014380165/article/details/79058479
4.AssertionError

这个错误发生在self.multihead_attention = nn.MultiheadAttention(embed_dim=num_hiddens * 2, num_heads=4) attn_output, attn_output_weights = self.multihead_attention(self.query,self.key,value)
造成错误的原因有两个:
1.nn.MultiheadAttention接受的query、key、value的形状是【seq_len,batch_size,embedding_dims】;
因此哪怕在init()中定义query=【batch_size,seq_len,embedding_dims】,然后在forward()中交换query维度变为【seq_len,batch_size,embedding_dims】也会出错
解决:直接在init()中定义query=【seq_len,batch_size,embedding_dims】,key同理;value在forward()中交换维度后输入self.multihead_attention即可(value在forward中交换并不会出错)
2.因为query和key在init中具体维度已经定了,因此在train时候,有的数据batch大小不等于batch_size就会报错,因此在具体train时候这样做:
边栏推荐
- Adhering to the integration of software and hardware, one Hengke makes efforts to the intelligent educational robot market
- SystemService(系统服务)
- Come to sword finger offer 03. Repeated numbers in the array
- 【深度学习基础知识 - 41】深度学习快速入门学习资料
- View pagoda PHP extension directory
- Intel's process roadmap for the next 10 years is exposed: 1.4nm process will be launched in 2029! How?
- Turn Hyper-V on and off
- HDU1171_ Big event in HDU [01 backpack]
- [basic knowledge of deep learning - 42] detailed explanation of logistic regression
- [basic knowledge of in-depth learning - 40] Why does CNN have more advantages than DNN in the field of images
猜你喜欢

S32k series chips -- Introduction
![[RCTF2015]EasySQL-1|SQL注入](/img/69/aa1fc60ecf9a0702d35d876e8c3dda.png)
[RCTF2015]EasySQL-1|SQL注入

JVM概述和内存管理(未完待续)
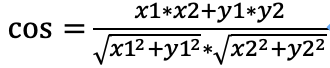
【深度学习基础知识 - 45】机器学习中常用的距离计算方法

JS 事件监听 鼠标 键盘 表单 页面 onclick onkeydown onChange

DatePicker(日期选择器)与TimePicker(时间选择器)

Debian recaptured the "debian.community" domain name, but it's still not good to stop and rest
jvisualvm的使用

A lock faster than read-write lock. Don't get to know it quickly

四大组件之ContentProvider
随机推荐
注入攻击
S32k series chips -- Introduction
Intel launched the world's smallest high-resolution lidar, priced at only $349
The first Xiaolong 765G! Redmi K30 5g release: support 5g dual-mode 120Hz screen, priced from 1999 yuan
S32K系列芯片--简介
Detailed interpretation of IEC104 protocol (I) protocol structure
GestureDetector(手势识别)
SumMenuDemo(子菜单)
Intel's process roadmap for the next 10 years is exposed: 1.4nm process will be launched in 2029! How?
Binary search tree
反超华为?爱立信已拿下超过75份5G商用合同
Uncover the mystery of Qualcomm ultrasonic fingerprint being "cracked by film"
英特尔发布Horse Ridge芯片:22nm工艺,能够控制多个量子位
Fzu1669 right angled triangle
Chinese character search Pinyin wechat applet project source code
Fabric上搭建Hyperledger caliper进行性能测试
IEC104 规约详细解读(二)交互流程以及协议解析
[basic knowledge of deep learning - 48] characteristics of Bayesian network
Object常用方法学习【clone和equals】
Oppo released the first AR glasses and announced that it would invest 50billion in research and development in the next three years