当前位置:网站首页>Repoptimizer: it's actually repvgg2
Repoptimizer: it's actually repvgg2
2022-06-29 13:15:00 【3D vision workshop】
Click on the above “3D Visual workshop ”, choice “ Star standard ”
The dry goods arrive at the first time

The author 丨 zzk
Source GiantPandaCV
Preface
In the design of neural network structure , We often introduce some prior knowledge , such as ResNet Residual structure of . However, we still use the conventional optimizer to train the network .
In this work , We propose to use prior information to modify gradient values , It is called gradient reparameterization , The corresponding optimizer is called RepOptimizer. We focus on VGG The straight cylinder model of , Train to get RepOptVGG Model , He has high training efficiency , Simple and direct structure and extremely fast reasoning speed .
Official warehouse :RepOptimizer
Thesis link :Re-parameterizing Your Optimizers rather than Architectures
And RepVGG The difference between
RepVGG A structural prior is added ( Such as 1x1,identity Branch ), And use the regular optimizer to train . and RepOptVGG It is Add this prior knowledge to the optimizer implementation
Even though RepVGG In the reasoning stage, the branches can be fused , Become a straight tube model . however There are many branches in the training process , Need more memory and training time . and RepOptVGG But really - Straight cylinder model , From the training process is a VGG structure
We do this by customizing the optimizer , The equivalent transformation of structural reparameterization and gradient reparameterization is realized , This transformation is universal , It can be extended to more models
 Introducing structural prior knowledge into the optimizer
Introducing structural prior knowledge into the optimizer
We noticed a phenomenon , In special circumstances , Each branch contains a linearly trainable parameter , Add a constant scaling value , As long as the scaling value is set reasonably , The performance of the model will still be very high . We call this network block Constant-Scale Linear Addition(CSLA)
Let's start with a simple CSLA Start with examples , Consider an input , after 2 A convolution branch + Linear scaling , And added to an output :

We consider equivalent transformation into a branch , The equivalent transformation corresponds to 2 A rule :
Initialization rules
The weight of fusion shall be :
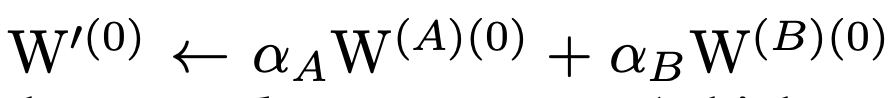
update rule
For the weight after fusion , The update rule is :
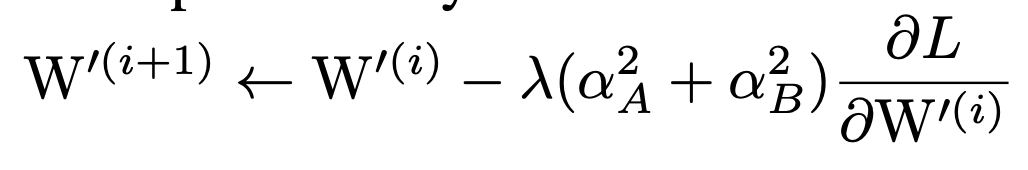
For this part of the formula, please refer to appendix A in , There is a detailed derivation
A simple example code is :
import torch
import numpy as np
np.random.seed(0)
np_x = np.random.randn(1, 1, 5, 5).astype(np.float32)
np_w1 = np.random.randn(1, 1, 3, 3).astype(np.float32)
np_w2 = np.random.randn(1, 1, 3, 3).astype(np.float32)
alpha1 = 1.0
alpha2 = 1.0
lr = 0.1
conv1 = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv2 = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv1.weight.data = torch.nn.Parameter(torch.tensor(np_w1))
conv2.weight.data = torch.nn.Parameter(torch.tensor(np_w2))
torch_x = torch.tensor(np_x, requires_grad=True)
out = alpha1 * conv1(torch_x) + alpha2 * conv2(torch_x)
loss = out.sum()
loss.backward()
torch_w1_updated = conv1.weight.detach().numpy() - conv1.weight.grad.numpy() * lr
torch_w2_updated = conv2.weight.detach().numpy() - conv2.weight.grad.numpy() * lr
print(torch_w1_updated + torch_w2_updated)import torch
import numpy as np
np.random.seed(0)
np_x = np.random.randn(1, 1, 5, 5).astype(np.float32)
np_w1 = np.random.randn(1, 1, 3, 3).astype(np.float32)
np_w2 = np.random.randn(1, 1, 3, 3).astype(np.float32)
alpha1 = 1.0
alpha2 = 1.0
lr = 0.1
fused_conv = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
fused_conv.weight.data = torch.nn.Parameter(torch.tensor(alpha1 * np_w1 + alpha2 * np_w2))
torch_x = torch.tensor(np_x, requires_grad=True)
out = fused_conv(torch_x)
loss = out.sum()
loss.backward()
torch_fused_w_updated = fused_conv.weight.detach().numpy() - (alpha1**2 + alpha2**2) * fused_conv.weight.grad.numpy() * lr
print(torch_fused_w_updated)stay RepOptVGG in , Corresponding CSLA Blocks are RepVGG In the block 3x3 Convolution ,1x1 Convolution ,bn The layer is replaced by With learnable scaling parameters 3x3 Convolution ,1x1 Convolution
Further expand to multi branch , hypothesis s,t Namely 3x3 Convolution ,1x1 Scaling coefficient of convolution , Then the corresponding update rule is :

The first formula corresponds to the input channel == Output channel , There is a total of 3 Branches , Namely identity,conv3x3, conv1x1
The second formula corresponds to the input channel != Output channel , At this time only conv3x3, conv1x1 Two branches
The third formula corresponds to other situations
It should be noted that CSLA No, BN This nonlinear operator during training (training-time nonlinearity), There is no non sequency (non sequential) Trainable parameter ,CSLA Here is just a description RepOptimizer Indirect tools for .
So there's one question left , That is, how to determine the scaling factor
HyperSearch
suffer DARTS inspire , We will CSLA Constant scaling factor in , Replace with trainable parameters . In a small data set ( Such as CIFAR100) Training on , After training on small data , We fix these trainable parameters as constants .
For specific training settings, please refer to the paper
experimental result
 The experimental results look very good , There are no multiple branches in the training , Trainable batchsize It can also increase , The throughput of the model is also improved .
The experimental results look very good , There are no multiple branches in the training , Trainable batchsize It can also increase , The throughput of the model is also improved .
Before RepVGG in , Many people roast that it is difficult to quantify , So in RepOptVGG Next , This straight cylinder model is very friendly to quantification :

The code is easy to read
We mainly look at repoptvgg.py This file , The core class is RepVGGOptimizer
stay reinitialize In the method , What it does is repvgg The job of , take 1x1 Convolution weight sum identity Branch into 3x3 The convolution :
if len(scales) == 2:
conv3x3.weight.data = conv3x3.weight * scales[1].view(-1, 1, 1, 1) \
+ F.pad(kernel_1x1.weight, [1, 1, 1, 1]) * scales[0].view(-1, 1, 1, 1)
else:
assert len(scales) == 3
assert in_channels == out_channels
identity = torch.from_numpy(np.eye(out_channels, dtype=np.float32).reshape(out_channels, out_channels, 1, 1))
conv3x3.weight.data = conv3x3.weight * scales[2].view(-1, 1, 1, 1) + F.pad(kernel_1x1.weight, [1, 1, 1, 1]) * scales[1].view(-1, 1, 1, 1)
if use_identity_scales: # You may initialize the imaginary CSLA block with the trained identity_scale values. Makes almost no difference.
identity_scale_weight = scales[0]
conv3x3.weight.data += F.pad(identity * identity_scale_weight.view(-1, 1, 1, 1), [1, 1, 1, 1])
else:
conv3x3.weight.data += F.pad(identity, [1, 1, 1, 1])Then let's take a look at GradientMask Generative logic , If only conv3x3 and conv1x1 Two branches , According to the preceding CSLA Equivalent transformation rule ,conv3x3 Of mask Corresponding to :
mask = torch.ones_like(para) * (scales[1] ** 2).view(-1, 1, 1, 1)and conv1x1 Of mask, You need to multiply by the square of the corresponding scaling factor , And add to conv3x3 middle :
mask[:, :, 1:2, 1:2] += torch.ones(para.shape[0], para.shape[1], 1, 1) * (scales[0] ** 2).view(-1, 1, 1, 1)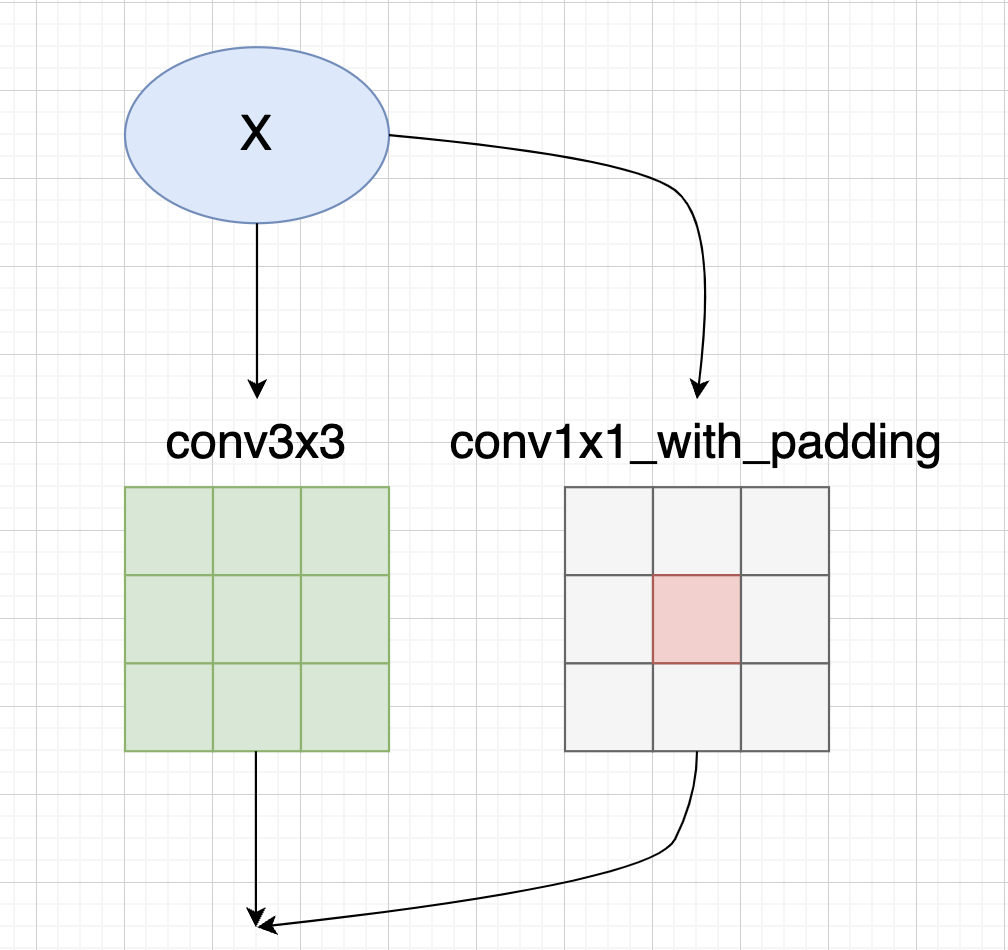
If there is Identity Branch , We need to add... To the diagonal 1.0(Identity Branches have no learnable scaling factor )
mask[ids, ids, 1:2, 1:2] += 1.0If you don't understand Identity Why do branches correspond to diagonals , Refer to the author's diagram RepVGG
summary
This article has been out for some time , But it seems that not many people pay attention to . In my opinion, this is a very practical job , Solved the problem of the previous generation RepVGG The small hole left , The model of completely straight cylinder during training is really realized , And quantify , Pruning friendly , Very suitable for actual deployment .
This article is only for academic sharing , If there is any infringement , Please contact to delete .
3D Visual workshop boutique course official website :3dcver.com
1. Multi sensor data fusion technology for automatic driving field
2. For the field of automatic driving 3D Whole stack learning route of point cloud target detection !( Single mode + Multimodal / data + Code )
3. Thoroughly understand the visual three-dimensional reconstruction : Principle analysis 、 Code explanation 、 Optimization and improvement
4. China's first point cloud processing course for industrial practice
5. laser - Vision -IMU-GPS The fusion SLAM Algorithm sorting and code explanation
6. Thoroughly understand the vision - inertia SLAM: be based on VINS-Fusion The class officially started
7. Thoroughly understand based on LOAM Framework of the 3D laser SLAM: Source code analysis to algorithm optimization
8. Thorough analysis of indoor 、 Outdoor laser SLAM Key algorithm principle 、 Code and actual combat (cartographer+LOAM +LIO-SAM)
10. Monocular depth estimation method : Algorithm sorting and code implementation
11. Deployment of deep learning model in autopilot
12. Camera model and calibration ( Monocular + Binocular + fisheye )
13. blockbuster ! Four rotor aircraft : Algorithm and practice
14.ROS2 From entry to mastery : Theory and practice
15. The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
blockbuster !3DCVer- Academic paper writing contribution Communication group Established
Scan the code to add a little assistant wechat , can Apply to join 3D Visual workshop - Academic paper writing and contribution WeChat ac group , The purpose is to communicate with each other 、 Top issue 、SCI、EI And so on .
meanwhile You can also apply to join our subdivided direction communication group , At present, there are mainly 3D Vision 、CV& Deep learning 、SLAM、 Three dimensional reconstruction 、 Point cloud post processing 、 Autopilot 、 Multi-sensor fusion 、CV introduction 、 Three dimensional measurement 、VR/AR、3D Face recognition 、 Medical imaging 、 defect detection 、 Pedestrian recognition 、 Target tracking 、 Visual products landing 、 The visual contest 、 License plate recognition 、 Hardware selection 、 Academic exchange 、 Job exchange 、ORB-SLAM Series source code exchange 、 Depth estimation Wait for wechat group .
Be sure to note : Research direction + School / company + nickname , for example :”3D Vision + Shanghai Jiaotong University + quietly “. Please note... According to the format , Can be quickly passed and invited into the group . Original contribution Please also contact .

▲ Long press and add wechat group or contribute
▲ The official account of long click attention
3D Vision goes from entry to mastery of knowledge : in the light of 3D In the field of vision Video Course cheng ( 3D reconstruction series 、 3D point cloud series 、 Structured light series 、 Hand eye calibration 、 Camera calibration 、 laser / Vision SLAM、 Automatically Driving, etc )、 Summary of knowledge points 、 Introduction advanced learning route 、 newest paper Share 、 Question answer Carry out deep cultivation in five aspects , There are also algorithm engineers from various large factories to provide technical guidance . meanwhile , The planet will be jointly released by well-known enterprises 3D Vision related algorithm development positions and project docking information , Create a set of technology and employment as one of the iron fans gathering area , near 4000 Planet members create better AI The world is making progress together , Knowledge planet portal :
Study 3D Visual core technology , Scan to see the introduction ,3 Unconditional refund within days
There are high quality tutorial materials in the circle 、 Answer questions and solve doubts 、 Help you solve problems efficiently
Feel useful , Please give me a compliment ~
边栏推荐
- C#实现二叉树的先序遍历、中序遍历、后序遍历
- Schiederwerk power supply maintenance smps12/50 pfc3800 analysis
- NvtBack
- 倍福控制器连接松下EtherCAT伺服注意事项
- RT-Thread内存管理
- 23、 1-bit data storage (delay line / core /dram/sram/ tape / disk / optical disc /flash SSD)
- Principle and Simulation of bind
- 强大、优秀的文件管理软件评测:图片管理、书籍管理、文献管理
- Schiederwerk Power Supply repair smps12 / 50 pfc3800 Analysis
- Definition of C # clue binary tree
猜你喜欢
C#通過中序遍曆對二叉樹進行線索化

别再重复造轮子了,推荐使用 Google Guava 开源工具类库,真心强大!
Lm07 - detailed discussion on cross section strategy of futures

ArcGIS中对面状河流进行等距分段【渐变赋色、污染物扩散】

cnpm报错‘cnpm‘不是内部或外部命令,也不是可运行的程序或批处理文件

Yolo series combs (IX) first taste of newly baked yolov6

C语言字符函数
Application Service Vulnerability scanning and exploitation of network security skills competition in secondary vocational schools (SSH private key disclosure)

Proteus Software beginner notes
Don't build the wheel again. It is recommended to use Google guava open source tool class library. It is really powerful!
随机推荐
Golang image/png 处理图片 旋转 写入
树状数组应用(AcWing 242,243,244)
Aes-128-cbc-pkcs7padding encrypted PHP instance
nvtmpp
C#通过线索二叉树进行中序遍历输出
MySQL常用语句和命令汇总
Proteus Software beginner notes
Beifu controls the third-party servo to follow CSV mode -- Taking Huichuan servo as an example
安装terraform-ovirt插件为ovirt提供自动化管理
Deep understanding of volatile keyword
Schiederwerk Power Supply repair smps12 / 50 pfc3800 Analysis
qt json
ZALSM_EXCEL_TO_INTERNAL_TABLE 导入数据大问题解决
神经网络各个部分的作用 & 彻底理解神经网络
QT custom control: value range
Cvpr2022 | a convnet for the 2020s & how to design neural network Summary
CVPR2022 | 长期行动预期的Future Transformer
Evaluation of powerful and excellent document management software: image management, book management and document management
Code tidiness learning notes
ArcGIS中对面状河流进行等距分段【渐变赋色、污染物扩散】