当前位置:网站首页>After using Stream for many years, does collect still have these "saucy operations"?
After using Stream for many years, does collect still have these "saucy operations"?
2022-08-03 16:40:00 【Young,】
本篇文章就来专门剖析collect操作,一起解锁更多高级玩法,让Stream操作真正的成为我们编码中的神兵利器.
初识Collector
先看一个简单的场景:
现有集团内所有人员列表,需要从中筛选出上海子公司的全部人员
假定人员信息数据如下:
| 姓名 | 子公司 | 部门 | 年龄 | 工资 |
|---|---|---|---|---|
| 大壮 | 上海公司 | 研发一部 | 28 | 3000 |
| 二牛 | 上海公司 | 研发一部 | 24 | 2000 |
| 铁柱 | 上海公司 | 研发二部 | 34 | 5000 |
| 翠花 | 南京公司 | 测试一部 | 27 | 3000 |
| 玲玲 | 南京公司 | 测试二部 | 31 | 4000 |
如果你曾经用过Stream流,或者你看过我前面关于Stream用法介绍的文章,那么借助Stream可以很轻松的实现上述诉求:
public void filterEmployeesByCompany() {
List<Employee> employees = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(Collectors.toList());
System.out.println(employees);
}
上述代码中,先创建流,然后通过一系列中间流操作(filter方法)进行业务层面的处理,然后经由终止操作(collect方法)将处理后的结果输出为List对象.

但我们实际面对的需求场景中,往往会有一些更复杂的诉求,比如说:
现有集团内所有人员列表,需要从中筛选出上海子公司的全部人员,并按照部门进行分组
其实也就是加了个新的分组诉求,那就是先按照前面的代码实现逻辑基础上,再对结果进行分组处理就好咯:
public void filterEmployeesThenGroup() {
// 先 筛选
List<Employee> employees = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(Collectors.toList());
// 再 分组
Map<String, List<Employee>> resultMap = new HashMap<>();
for (Employee employee : employees) {
List<Employee> groupList = resultMap
.computeIfAbsent(employee.getDepartment(), k -> new ArrayList<>());
groupList.add(employee);
}
System.out.println(resultMap);
}
似乎也没啥毛病,相信很多同学实际编码中也是这么处理的.但其实我们也可以使用Stream操作直接完成:
public void filterEmployeesThenGroupByStream() {
Map<String, List<Employee>> resultMap = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(Collectors.groupingBy(Employee::getDepartment));
System.out.println(resultMap);
}
两种写法都可以得到相同的结果:
{
研发二部=[Employee(subCompany=上海公司, department=研发二部, name=铁柱, age=34, salary=5000)],
研发一部=[Employee(subCompany=上海公司, department=研发一部, name=大壮, age=28, salary=3000), Employee(subCompany=上海公司, department=研发一部, name=二牛, age=24, salary=2000)]
}
上述2种写法相比而言,第二种是不是代码上要简洁很多?而且是不是有种自注释的味道了?
通过collect方法的合理恰当利用,可以让Stream适应更多实际的使用场景,大大的提升我们的开发编码效率.下面就一起来全面认识下collect、解锁更多高级操作吧.
collect\Collector\Collectors区别与关联
刚接触Stream收集器的时候,很多同学都会被collect,Collector,Collectors这几个概念搞的晕头转向,甚至还有很多人即使已经使用Stream好多年,也只是知道collect里面需要传入类似Collectors.toList()这种简单的用法,对其背后的细节也不甚了解.
这里以一个collect收集器最简单的使用场景来剖析说明下其中的关系:

概括来说:
1️⃣
collect是Stream流的一个终止方法,会使用传入的收集器(入参)对结果执行相关的操作,这个收集器必须是Collector接口的某个具体实现类2️⃣
Collector是一个接口,collect方法的收集器是Collector接口的具体实现类3️⃣
Collectors是一个工具类,提供了很多的静态工厂方法,提供了很多Collector接口的具体实现类,是为了方便程序员使用而预置的一些较为通用的收集器(如果不使用Collectors类,而是自己去实现Collector接口,也可以).
Collector使用与剖析
到这里我们可以看出,Stream结果收集操作的本质,其实就是将Stream中的元素通过收集器定义的函数处理逻辑进行加工,然后输出加工后的结果.
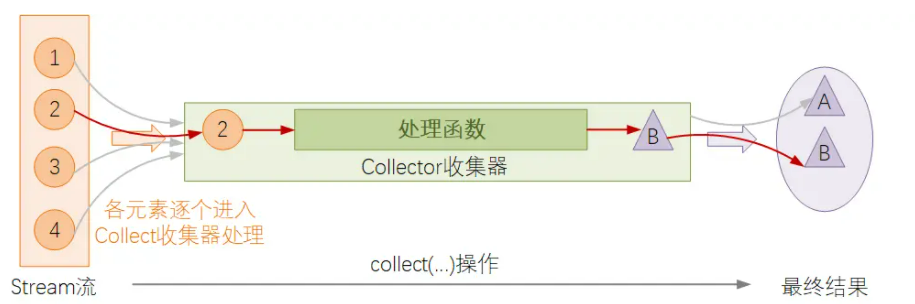
根据其执行的操作类型来划分,又可将收集器分为几种不同的大类:
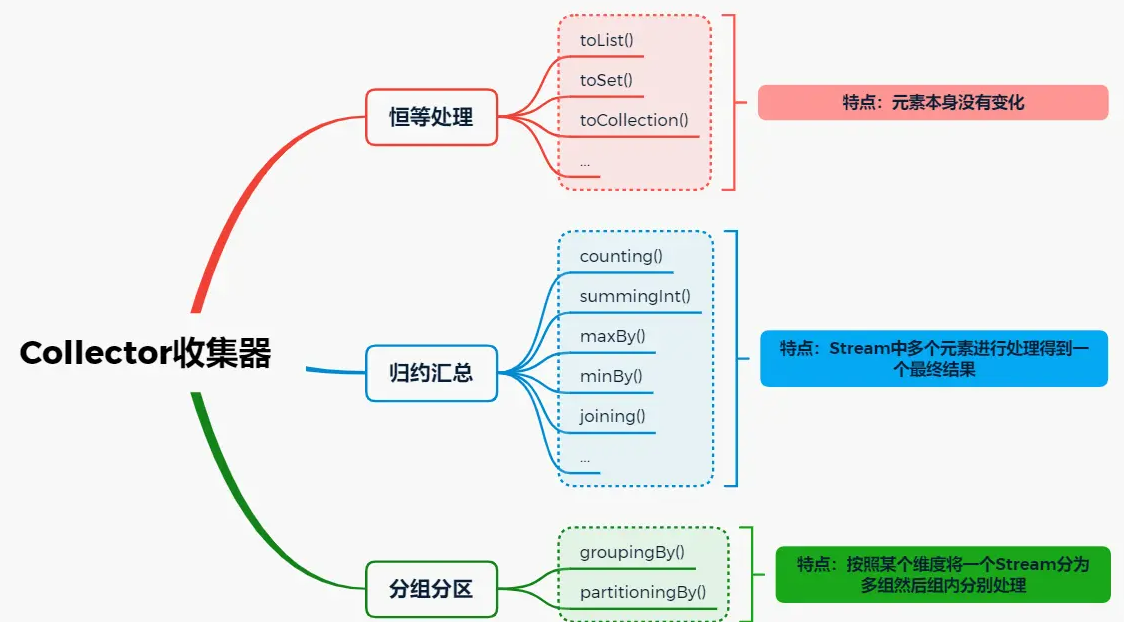
下面分别阐述下.
恒等处理Collector
所谓恒等处理,指的就是Stream的元素在经过Collector函数处理前后完全不变,例如toList()操作,只是最终将结果从Stream中取出放入到List对象中,并没有对元素本身做任何的更改处理:
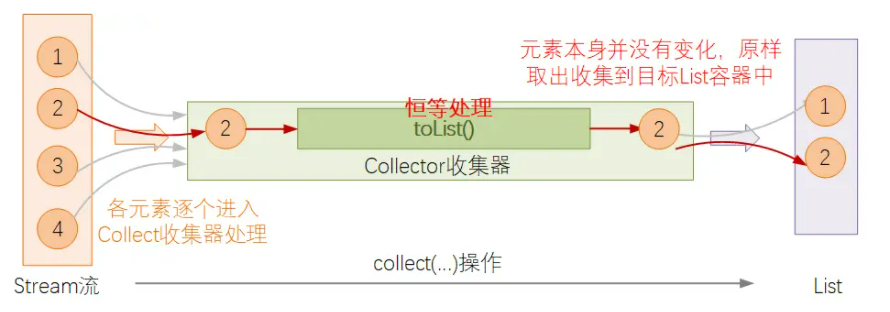
恒等处理类型的Collector是实际编码中最常被使用的一种,比如:
list.stream().collect(Collectors.toList());
list.stream().collect(Collectors.toSet());
list.stream().collect(Collectors.toCollection());
归约汇总Collector
对于归约汇总类的操作,Stream流中的元素逐个遍历,进入到Collector处理函数中,然后会与上一个元素的处理结果进行合并处理,并得到一个新的结果,以此类推,直到遍历完成后,输出最终的结果.比如Collectors.summingInt()方法的处理逻辑如下:
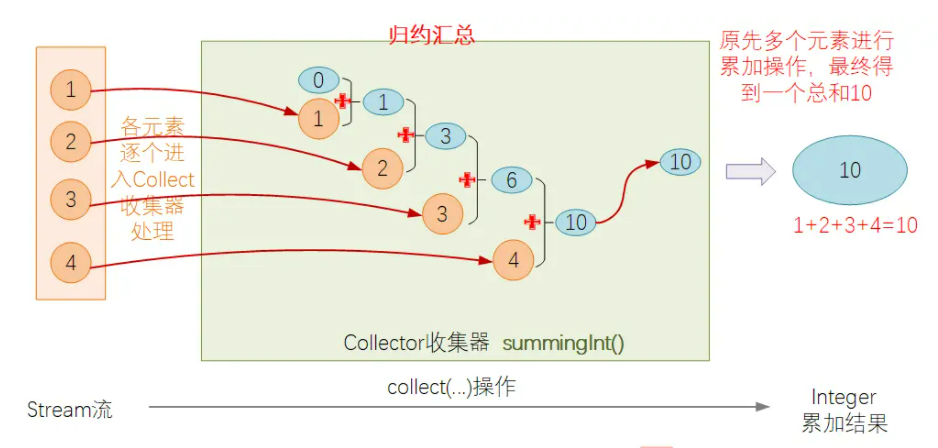
比如本文开头举的例子,如果需要计算上海子公司每个月需要支付的员工总工资,使用Collectors.summingInt()可以这么实现:
public void calculateSum() {
Integer salarySum = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(Collectors.summingInt(Employee::getSalary));
System.out.println(salarySum);
}
需要注意的是,这里的汇总计算,不单单只数学层面的累加汇总,而是一个广义上的汇总概念,即将多个元素进行处理操作,最终生成1个结果的操作,比如计算Stream中最大值的操作,最终也是多个元素中,最终得到一个结果:
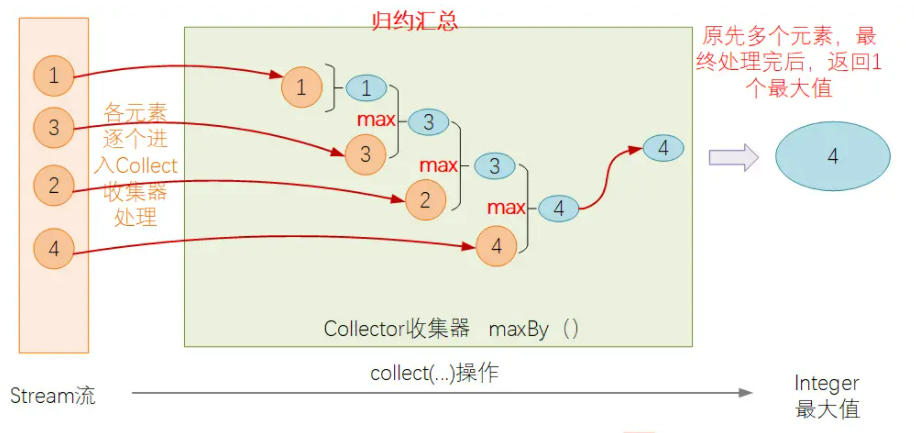
还是用之前举的例子,现在需要知道上海子公司里面工资最高的员工信息,我么可以这么实现:
public void findHighestSalaryEmployee() {
Optional<Employee> highestSalaryEmployee = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(Collectors.maxBy(Comparator.comparingInt(Employee::getSalary)));
System.out.println(highestSalaryEmployee.get());
}
因为这里我们要演示collect的用法,所以用了上述的写法.实际的时候JDK为了方便使用,也提供了上述逻辑的简化封装,我们可以直接使用max()方法来简化,即上述代码与下面的写法等价:
public void findHighestSalaryEmployee2() {
Optional<Employee> highestSalaryEmployee = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.max(Comparator.comparingInt(Employee::getSalary));
System.out.println(highestSalaryEmployee.get());
}
分组分区Collector
Collectors工具类中提供了groupingBy方法用来得到一个分组操作Collector,其内部处理逻辑可以参见下图的说明:
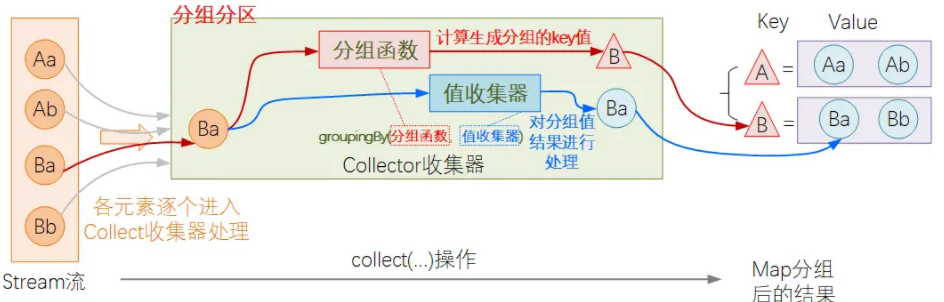
groupingBy()操作需要指定两个关键输入,即分组函数和值收集器:
- 分组函数:一个处理函数,用于基于指定的元素进行处理,返回一个用于分组的值(即分组结果
HashMap的Key值),对于经过此函数处理后返回值相同的元素,将被分配到同一个组里. - 值收集器:对于分组后的数据元素的进一步处理转换逻辑,此处还是一个常规的Collector收集器,和collect()方法中传入的收集器完全等同(可以想想
俄罗斯套娃,一个概念).
对于groupingBy分组操作而言,分组函数与值收集器二者必不可少.为了方便使用,在Collectors工具类中,提供了两个groupingBy重载实现,其中有一个方法只需要传入一个分组函数即可,这是因为其默认使用了toList()作为值收集器:

例如:仅仅是做一个常规的数据分组操作时,可以仅传入一个分组函数即可:
public void groupBySubCompany() {
// 按照子公司维度将员工分组
Map<String, List<Employee>> resultMap =
getAllEmployees().stream()
.collect(Collectors.groupingBy(Employee::getSubCompany));
System.out.println(resultMap);
}
这样collect返回的结果,就是一个HashMap,其每一个HashValue的值为一个List类型.
而如果不仅需要分组,还需要对分组后的数据进行处理的时候,则需要同时给定分组函数以及值收集器:
public void groupAndCaculate() {
// 按照子公司分组,并统计每个子公司的员工数
Map<String, Long> resultMap = getAllEmployees().stream()
.collect(Collectors.groupingBy(Employee::getSubCompany,
Collectors.counting()));
System.out.println(resultMap);
}
这样就同时实现了分组与组内数据的处理操作:
{南京公司=2, 上海公司=3}
上面的代码中Collectors.groupingBy()是一个分组Collector,而其内又传入了一个归约汇总Collector Collectors.counting(),也就是一个收集器中嵌套了另一个收集器.
除了上述演示的场景外,还有一种特殊的分组操作,其分组的key类型仅为布尔值,这种情况,我们也可以通过Collectors.partitioningBy()提供的分区收集器来实现.
例如:
统计上海公司和非上海公司的员工总数, true表示是上海公司,false表示非上海公司
使用分区收集器的方式,可以这么实现:
public void partitionByCompanyAndDepartment() {
Map<Boolean, Long> resultMap = getAllEmployees().stream()
.collect(Collectors.partitioningBy(e -> "上海公司".equals(e.getSubCompany()),
Collectors.counting()));
System.out.println(resultMap);
}
结果如下:
{false=2, true=3}
Collectors.partitioningBy()分区收集器的使用方式与Collectors.groupingBy()分组收集器的使用方式相同.单纯从使用维度来看,分组收集器的分组函数返回值为布尔值,则效果等同于一个分区收集器.
Collector的叠加嵌套
有的时候,我们需要根据先根据某个维度进行分组后,再根据第二维度进一步的分组,然后再对分组后的结果进一步的处理操作,这种场景里面,我们就可以通过Collector收集器的叠加嵌套使用来实现.
例如下面的需求:
现有整个集团全体员工的列表,需要统计各子公司内各部门下的员工人数.
使用Stream的嵌套Collector,我们可以这么实现:
public void groupByCompanyAndDepartment() {
// 按照子公司+部门双层维度,统计各个部门内的人员数
Map<String, Map<String, Long>> resultMap = getAllEmployees().stream()
.collect(Collectors.groupingBy(Employee::getSubCompany,
Collectors.groupingBy(Employee::getDepartment,
Collectors.counting())));
System.out.println(resultMap);
}
可以看下输出结果,达到了需求预期的诉求:
{
南京公司={
测试二部=1,
测试一部=1},
上海公司={
研发二部=1,
研发一部=2}
}
上面的代码中,就是一个典型的Collector嵌套处理的例子,同时也是一个典型的多级分组的实现逻辑.对代码的整体处理过程进行剖析,大致逻辑如下:
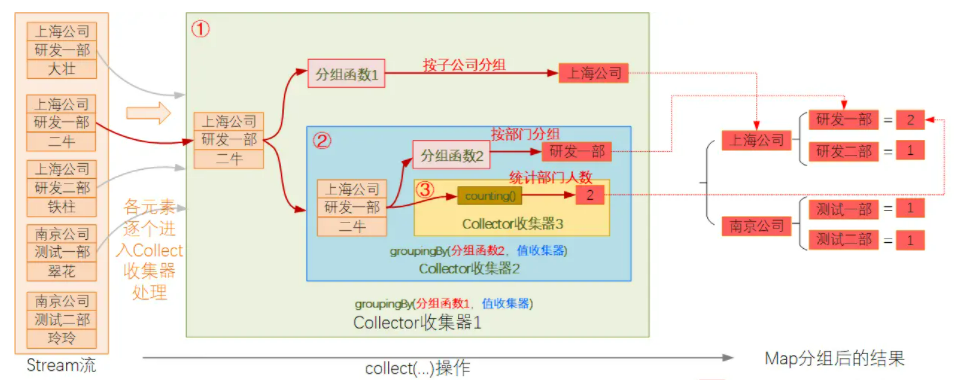
借助多个Collector嵌套使用,可以让我们解锁很多复杂场景处理能力.你可以将这个操作想象为一个套娃操作,如果愿意,你可以无限嵌套下去(实际中不太可能会有如此荒诞的场景).
Collectors提供的收集器
为了方便程序员使用呢,JDK中的Collectors工具类封装提供了很多现成的Collector实现类,可供编码时直接使用,对常用的收集器介绍如下:
| 方法 | 含义说明 |
|---|---|
| toList | 将流中的元素收集到一个List中 |
| toSet | 将流中的元素收集到一个Set中 |
| toCollection | 将流中的元素收集到一个Collection中 |
| toMap | 将流中的元素映射收集到一个Map中 |
| counting | 统计流中的元素个数 |
| summingInt | 计算流中指定int字段的累加总和.针对不同类型的数字类型,有不同的方法,比如summingDouble等 |
| averagingInt | 计算流中指定int字段的平均值.针对不同类型的数字类型,有不同的方法,比如averagingLong等 |
| joining | 将流中所有元素(或者元素的指定字段)字符串值进行拼接,可以指定拼接连接符,或者首尾拼接字符 |
| maxBy | 根据给定的比较器,选择出值最大的元素 |
| minBy | 根据给定的比较器,选择出值最小的元素 |
| groupingBy | 根据给定的分组函数的值进行分组,输出一个Map对象 |
| partitioningBy | 根据给定的分区函数的值进行分区,输出一个Map对象,且key始终为布尔值类型 |
| collectingAndThen | 包裹另一个收集器,对其结果进行二次加工转换 |
| reducing | 从给定的初始值开始,将元素进行逐个的处理,最终将所有元素计算为最终的1个值输出 |
上述的大部分方法,前面都有使用示例,这里对collectAndThen补充介绍下.
collectAndThen对应的收集器,必须传入一个真正用于结果收集处理的实际收集器downstream以及一个finisher方法,当downstream收集器计算出结果后,使用finisher方法对结果进行二次处理,并将处理结果作为最终结果返回.
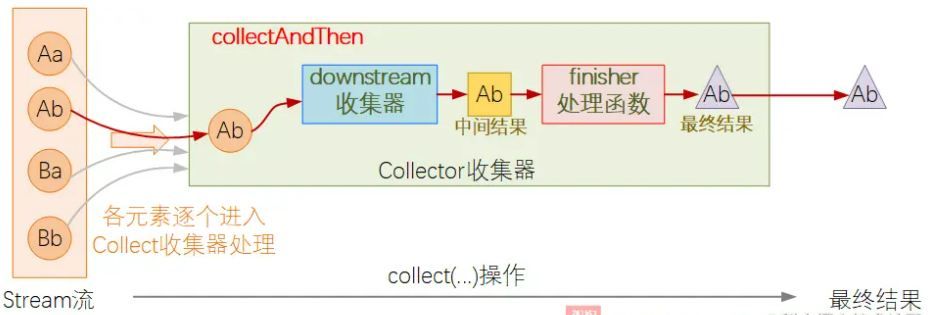
还是拿之前的例子来举例:
给定集团所有员工列表,找出上海公司中工资最高的员工.
我们可以写出如下代码:
public void findHighestSalaryEmployee() {
Optional<Employee> highestSalaryEmployee = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(Collectors.maxBy(Comparator.comparingInt(Employee::getSalary)));
System.out.println(highestSalaryEmployee.get());
}
但是这个结果最终输出的是个Optional<Employee>类型,使用的时候比较麻烦,那能不能直接返回我们需要的Employee类型呢?这里就可以借助collectAndThen来实现:
public void testCollectAndThen() {
Employee employeeResult = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(
Collectors.collectingAndThen(
Collectors.maxBy(Comparator.comparingInt(Employee::getSalary)),
Optional::get)
);
System.out.println(employeeResult);
}
这样就可以啦,是不是超简单的?
开发个自定义收集器
前面我们演示了很多Collectors工具类中提供的收集器的用法,上一节中列出来的Collectors提供的常用收集器,也可以覆盖大部分场景的开发诉求了.
但也许在项目中,我们会遇到一些定制化的场景,现有的收集器无法满足我们的诉求,这个时候,我们也可以自己来实现定制化的收集器.
!
Collector接口介绍
我们知道,所谓的收集器,其实就是一个Collector接口的具体实现类.所以如果想要定制自己的收集器,首先要先了解Collector接口到底有哪些方法需要我们去实现,以及各个方法的作用与用途.
当我们新建一个MyCollector类并声明实现Collector接口的时候,会发现需要我们实现5个接口:
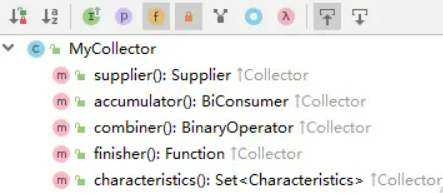
这5个接口的含义说明归纳如下:
| 接口名称 | 功能含义说明 |
|---|---|
| supplier | 创建新的结果容器,可以是一个容器,也可以是一个累加器实例,总之是用来存储结果数据的 |
| accumlator | 元素进入收集器中的具体处理操作 |
| finisher | 当所有元素都处理完成后,在返回结果前的对结果的最终处理操作,当然也可以选择不做任何处理,直接返回 |
| combiner | 各个子流的处理结果最终如何合并到一起去,比如并行流处理场景,元素会被切分为好多个分片进行并行处理,最终各个分片的数据需要合并为一个整体结果,即通过此方法来指定子结果的合并逻辑 |
| characteristics | 对此收集器处理行为的补充描述,比如此收集器是否允许并行流中处理,是否finisher方法必须要有等等,此处返回一个Set集合,里面的候选值是固定的几个可选项. |
对于characteristics返回set集合中的可选值,说明如下:
| 取值 | 含义说明 |
|---|---|
| UNORDERED | 声明此收集器的汇总归约结果与Stream流元素遍历顺序无关,不受元素处理顺序影响 |
| CONCURRENT | 声明此收集器可以多个线程并行处理,允许并行流中进行处理 |
| IDENTITY_FINISH | 声明此收集器的finisher方法是一个恒等操作,可以跳过 |
现在,我们知道了这5个接口方法各自的含义与用途了,那么作为一个Collector收集器,这几个接口之间是如何配合处理并将Stream数据收集为需要的输出结果的呢?下面这张图可以清晰的阐述这一过程:
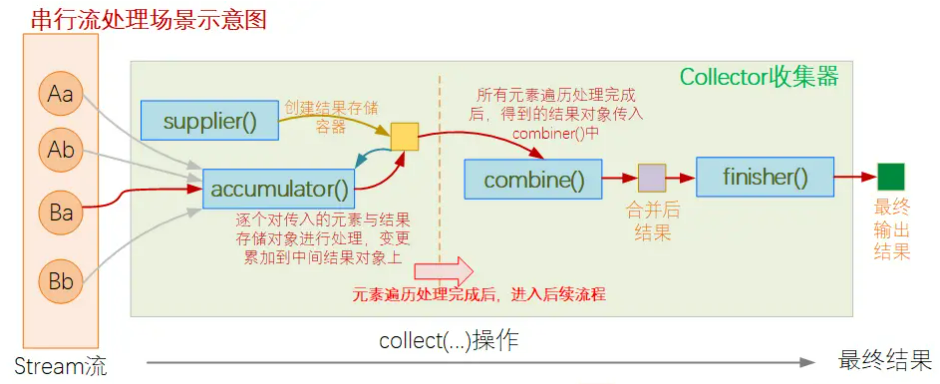
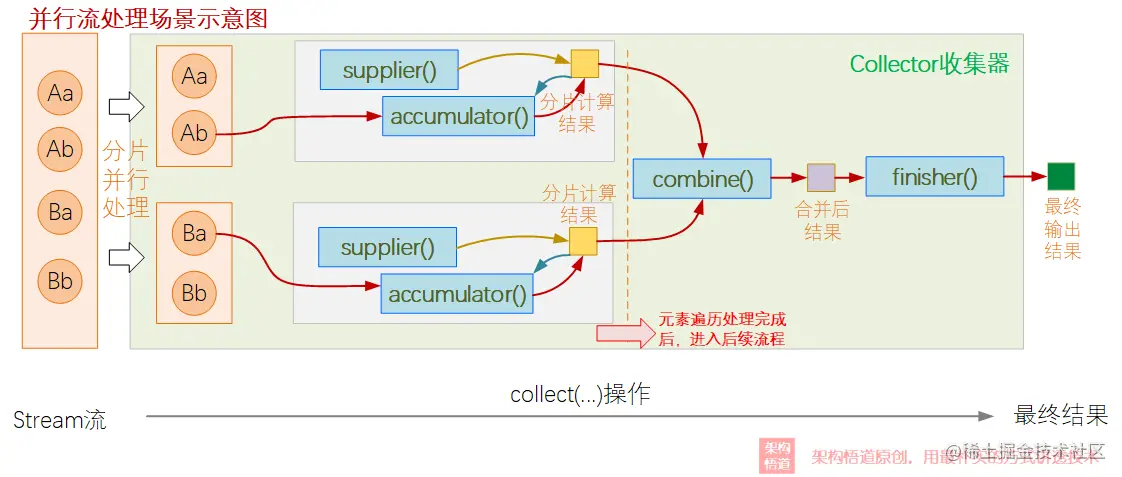
当然,如果我们的Collector是支持在并行流中使用的,则其处理过程会稍有不同:
为了对上述方法有个直观的理解,我们可以看下Collectors.toList()这个收集器的实现源码:
static final Set<Collector.Characteristics> CH_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH));
public static <T> Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> {
left.addAll(right); return left; },
CH_ID);
}
对上述代码拆解分析如下:
- supplier方法:
ArrayList::new,即new了个ArrayList作为结果存储容器. - accumulator方法:
List::add,也就是对于stream中的每个元素,都调用list.add()方法添加到结果容器追踪. - combiner方法:
(left, right) -> { left.addAll(right); return left; },也就是对于并行操作生成的各个子ArrayList结果,最终通过list.addAll()方法合并为最终结果. - finisher方法:没提供,使用的默认的,因为无需做任何处理,属于恒等操作.
- characteristics:返回的是
IDENTITY_FINISH,也即最终结果直接返回,无需finisher方法去二次加工.注意这里没有声明CONCURRENT,因为ArrayList是个非线程安全的容器,所以这个收集器是不支持在并发过程中使用.
通过上面的逐个方法描述,再联想下Collectors.toList()的具体表现,想必对各个接口方法的含义应该有了比较直观的理解了吧?

实现Collector接口
既然已经搞清楚Collector接口中的主要方法作用,那就可以开始动手写自己的收集器啦.新建一个class类,然后声明实现Collector接口,然后去实现具体的接口方法就行咯.
前面介绍过,Collectors.summingInt收集器是用来计算每个元素中某个int类型字段的总和的,假设我们需要一个新的累加功能:
计算流中每个元素的某个int字段值平方的总和
下面,我们就一起来自定义一个收集器来实现此功能.
- supplier方法
supplier方法的职责,是创建一个结果存储累加的容器.既然我们要计算多个值的累加结果,那首先就是要先声明一个int sum = 0用来存储累加结果.但是为了让我们的收集器可以支持在并发模式下使用,我们这里可以采用线程安全的AtomicInteger来实现.
所以我们便可以确定supplier方法的实现逻辑了:
@Override
public Supplier<AtomicInteger> supplier() {
// 指定用于最终结果的收集,此处返回new AtomicInteger(0),后续在此基础上累加
return () -> new AtomicInteger(0);
}
- accumulator方法
accumulator方法是实现具体的计算逻辑的,也是整个Collector的核心业务逻辑所在的方法.收集器处理的时候,Stream流中的元素会逐个进入到Collector中,然后由accumulator方法来进行逐个计算:
@Override
public BiConsumer<AtomicInteger, T> accumulator() {
// 每个元素进入的时候的遍历策略,当前元素值的平方与sum结果进行累加
return (sum, current) -> {
int intValue = mapper.applyAsInt(current);
sum.addAndGet(intValue * intValue);
};
}
这里也补充说下,收集器中的几个方法中,仅有accumulator是需要重复执行的,有几个元素就会执行几次,其余的方法都不会直接与Stream中的元素打交道.
- combiner方法
因为我们前面supplier方法中使用了线程安全的AtomicInteger作为结果容器,所以其支持在并行流中使用.根据上面介绍,并行流是将Stream切分为多个分片,然后分别对分片进行计算处理得到分片各自的结果,最后这些分片的结果需要合并为同一份总的结果,这个如何合并,就是此处我们需要实现的:
@Override
public BinaryOperator<AtomicInteger> combiner() {
// 多个分段结果处理的策略,直接相加
return (sum1, sum2) -> {
sum1.addAndGet(sum2.get());
return sum1;
};
}
因为我们这里是要做一个数字平方的总和,所以这里对于分片后的结果,我们直接累加到一起即可.
- finisher方法
我们的收集器目标结果是输出一个累加的Integer结果值,但是为了保证并发流中的线程安全,我们使用AtomicInteger作为了结果容器.也就是最终我们需要将内部的AtomicInteger对象转换为Integer对象,所以finisher方法我们的实现逻辑如下:
@Override
public Function<AtomicInteger, Integer> finisher() {
// 结果处理完成之后对结果的二次处理
// 为了支持多线程并发处理,此处内部使用了AtomicInteger作为了结果累加器
// 但是收集器最终需要返回Integer类型值,此处进行对结果的转换
return AtomicInteger::get;
}
- characteristics方法
这里呢,我们声明下该Collector收集器的一些特性就行了:
- 因为我们实现的收集器是允许并行流中使用的,所以我们声明了
CONCURRENT属性; - 作为一个数字累加算总和的操作,对元素的先后计算顺序并没有关系,所以我们也同时声明
UNORDERED属性; - 因为我们的finisher方法里面是做了个结果处理转换操作的,并非是一个恒等处理操作,所以这里就不能声明
IDENTITY_FINISH属性.
基于此分析,此方法的实现如下:
@Override
public Set<Characteristics> characteristics() {
Set<Characteristics> characteristics = new HashSet<>();
// 指定该收集器支持并发处理(前面也发现我们采用了线程安全的AtomicInteger方式)
characteristics.add(Characteristics.CONCURRENT);
// 声明元素数据处理的先后顺序不影响最终收集的结果
characteristics.add(Characteristics.UNORDERED);
// 注意:这里没有添加下面这句,因为finisher方法对结果进行了处理,非恒等转换
// characteristics.add(Characteristics.IDENTITY_FINISH);
return characteristics;
}
这样呢,我们的自定义收集器就实现好了,如果需要完整代码,可以到文末的github仓库地址上获取.
我们使用下自己定义的收集器看看:
public void testMyCollector() {
Integer result = Stream.of(new Score(1), new Score(2), new Score(3), new Score(4))
.collect(new MyCollector<>(Score::getScore));
System.out.println(result);
}
输出结果:
30
完全符合我们的预期,自定义收集器就实现好了.回头再看下,是不是挺简单的?
总结
好啦,关于Java中Stream的collect用法与Collector收集器的内容,这里就给大家分享到这里咯.看到这里,不知道你是否掌握了呢?是否还有什么疑问或者更好的见解呢?欢迎多多留言切磋交流.
边栏推荐
- Understand the recommendation system in one article: Outline 02: The link of the recommendation system, from recalling rough sorting, to fine sorting, to rearranging, and finally showing the recommend
- Small Tools (4) integrated Seata1.5.2 distributed transactions
- MySQL窗口函数 PARTITION BY()函数介绍
- C专家编程 第1章 C:穿越时空的迷雾 1.9 阅读ANSI C标准,寻找乐趣和裨益
- 纯纯粹粹纯纯粹粹
- node connection mongoose database process
- How ArkUI adapter somehow the screen
- leetcode:189. 轮转数组
- C专家编程 第1章 C:穿越时空的迷雾 1.7 编译限制
- To add digital wings to education, NetEase Yunxin released the overall solution of "Internet + Education"
猜你喜欢


![[Unity Getting Started Plan] Basic Concepts (8) - Tile Map TileMap 01](/img/8e/fcf79d150af4384c14a118fb209725.png)



随机推荐
Big guys.Use flink-cdc-sqlserver version 2.2.0 to read sqlserver2008R
uniapp的webview滑动缩放
从MatePad Pro进化看鸿蒙OS的生态势能
中小微企业如何简单便捷、低成本实现数字化?360视觉云有妙招
C语言01、数据类型、变量常量、字符串、转义字符、注释
兄弟组件通信context
SQL中对 datetime 类型操作
STM32 GPIO LED and buzzer implementation [Day 4]
Hannah荣获第六季完美童模全球总决赛全球人气总冠军
MySQL窗口函数 OVER()函数介绍
使用 PowerShell 将 Windows 转发事件导入 SQL Server
To add digital wings to education, NetEase Yunxin released the overall solution of "Internet + Education"
C# 获取文件名和扩展名(后缀名)
附录A 程序员工作面试的秘密
devops-2:Jenkins的使用及Pipeline语法讲解
C语言04、操作符
error:Illegal instruction (core dumped),离线下载安装这个other版本numpy
MySQL窗口函数
Async的线程池使用的哪个?
Web3 安全风险令人生畏?应该如何应对?