当前位置:网站首页>Flume面试题
Flume面试题
2022-07-01 19:40:00 【L缶神】
1. 你是如何实现Flume 数据传输的监控的
使用第三方框架 Ganglia 实时监控 Flume。
2. Flume 的Source,Sink,Channel 的作用?你们Source 是什么类型?
1. 作用
(1)Source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spoolingdirectory、netcat、sequence generator、syslog、http、legacy
(2)Channel组件对采集到的数据进行缓存,可以存放在Memory 或 File 中。
(3)Sink 组件是用于把数据发送到目的地的组件,目的地包括 HDFS、Logger、avro、thrift、ipc、file、Hbase、solr、自定义。
2. 我公司采用的 Source 类型为
(1)监控后台日志:exec
(2)监控后台产生日志的端口:netcat
Exec spooldir
3. Flume 的Channel Selectors
ChannelSelectors,可以让不同的项目日志通过不同的Channel到不同的Sink中去。官方文档上ChannelSelectors 有两种类型:ReplicatingChannel Selector (default)和MultiplexingChannel Selector
这两种Selector的区别是:Replicating 会将source过来的events发往所有channel,而Multiplexing可以选择该发往哪些Channel。
4. Flume 参数调优
1. Source
增加 Source 个(使用 Tair Dir Source 时可增加 FileGroups 个数)可以增大 Source 的读取数据的能力。例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个文件目录,同时配置好多个 Source 以保证 Source 有足够的能力获取到新产生的数据。
batchSize 参数决定 Source 一次批量运输到 Channel 的 event 条数,适当调大这个参数可以提高 Source 搬运 Event 到 Channel 时的性能。
2. Channel
type 选择 memory 时 Channel 的性能最好,但是如果 Flume 进程意外挂掉可能会丢失数据。type 选择 file 时 Channel 的容错性更好,但是性能上会比 memory channel 差。使用 file Channel 时 dataDirs 配置多个不同盘下的目录可以提高性能。
Capacity 参数决定 Channel 可容纳最大的 event 条数。transactionCapacity 参数决定每次 Source 往 channel 里面写的最大 event 条数和每次 Sink 从 channel 里面读的最大 event条数。transactionCapacity 需要大于 Source 和 Sink 的 batchSize 参数。
3. Sink
增加 Sink 的个数可以增加 Sink 消费 event 的能力。Sink 也不是越多越好够用就行,过多的 Sink 会占用系统资源,造成系统资源不必要的浪费。
batchSize 参数决定 Sink 一次批量从 Channel 读取的 event 条数,适当调大这个参数可以提高 Sink 从 Channel 搬出 event 的性能。
5. Flume 的事务机制
Flume 的事务机制(类似数据库的事务机制):Flume 使用两个独立的事务分别负责从Soucrce 到 Channel,以及从Channel到Sink的事件传递。比如spooling directory source为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到 Channel 且提交成功,那么 Soucrce 就将该文件标记为完成。同理,事务以类似的方式处理从 Channel 到 Sink 的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到 Channel 中,等待重新传递。
6. Flume 采集数据会丢失吗?
根据 Flume 的架构原理,Flume 是不可能丢失数据的,其内部有完善的事务机制,Source 到 Channel 是事务性的,Channel 到 Sink 是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是 Channel 采用 memoryChannel,agent 宕机导致数据丢失,或者 Channel 存储数据已满,导致 Source 不再写入,未写入的数据丢失。
Flume 不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由 Sink 发出,但是没有接收到响应,Sink 会再次发送数据,此时可能会导致数据的重复。
7. Flume基础架构(*)

(1)Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有 3 个部分组成,Source、Channel、Sink。
(2)Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
(3)Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
(4)Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和File Channel 以及 Kafka Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
(5)Event
传输单元,Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。
Event 由Header 和Body 两部分组成,Header 用来存放该 event 的一些属性,为 K-V 结构,Body 用来存放该条数据,形式为字节数组。
8. Flume事务(*)

Put事务流程
•doPut:将批数据先写入临时缓冲区putList
•doCommit:检查channel内存队列是否足够合并。
•doRollback:channel内存队列空间不足,回滚数据
Take事务
•doTake:将数据取到临时缓冲区takeList,并将数据发送到HDFS
•doCommit:如果数据全部发送成功,则清除临时缓冲区takeList
•doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区t akeList中的数据归还给channel内存队列。
9. Flume Agent内部原理(*)

重要组件:
1)ChannelSelector
ChannelSelector 的作用就是选出 Event 将要被发往哪个 Channel。其共有两种类型,分别是Replicating(复制)和Multiplexing(多路复用)。
ReplicatingSelector 会将同一个 Event 发往所有的 Channel,Multiplexing 会根据相应的原则,将不同的 Event 发往不同的 Channel。
2)SinkProcessor
SinkProcessor 共有三种类型,分别是DefaultSinkProcessor
、LoadBalancingSinkProcessor 和FailoverSinkProcessor 。
DefaultSinkProcessor 对应的是单个的 Sink , LoadBalancingSinkProcessor 和FailoverSinkProcessor 对应的是 Sink Group,LoadBalancingSinkProcessor 可以实现负载均衡的功能,FailoverSinkProcessor 可以实现故障转移的功能。
10. Flume 与 Kafka 的选取?
采集层主要可以使用 Flume、Kafka 两种技术。Flume:Flume 是管道流方式,提供了很多的默认实现,让用户通过参数部署,及扩展 API。
Kafka:Kafka 是一个可持久化的分布式的消息队列。Kafka 是一个非常通用的系统。你可以有许多生产者和很多的消费者共享多个主题Topics。相比之下,Flume 是一个专用工具被设计为旨在往 HDFS,HBase 发送数据。它对HDFS 有特殊的优化,并且集成了 Hadoop 的安全特性。所以,Cloudera 建议如果数据被多个系统消费的话,使用 kafka;如果数据被设计给 Hadoop 使用,使用 Flume。正如你们所知 Flume 内置很多的 source 和 sink 组件。然而,Kafka 明显有一个更小的生产消费者生态系统,并且 Kafka 的社区支持不好。希望将来这种情况会得到改善,但是目前:使用 Kafka 意味着你准备好了编写你自己的生产者和消费者代码。如果已经存在的 Flume Sources 和 Sinks 满足你的需求,并且你更喜欢不需要任何开发的系统,请使用 Flume。Flume 可以使用拦截器实时处理数据。这些对数据屏蔽或者过量是很有用的。Kafka 需要外部的流处理系统才能做到。
Kafka 和 Flume 都是可靠的系统,通过适当的配置能保证零数据丢失。然而,Flume 不支持副本事件。于是,如果 Flume 代理的一个节点奔溃了,即使使用了可靠的文件管道方式,你也将丢失这些事件直到你恢复这些磁盘。如果你需要一个高可靠行的管道,那么使用Kafka 是个更好的选择。
Flume 和 Kafka 可以很好地结合起来使用。如果你的设计需要从 Kafka 到 Hadoop 的流数据,使用 Flume 代理并配置 Kafka 的 Source 读取数据也是可行的:你没有必要实现自己的消费者。你可以直接利用Flume 与HDFS 及HBase 的结合的所有好处。你可以使用ClouderaManager 对消费者的监控,并且你甚至可以添加拦截器进行一些流处理。
边栏推荐
猜你喜欢

薛定谔的日语学习小程序源码
如何用OpenMesh创建一个四棱锥
Practical project notes (I) -- creation of virtual machine

After adding cocoapods successfully, the header file cannot be imported or an error is reported in not found file

《軟件工程導論(第六版)》 張海藩 複習筆記

Richview RichEdit srichviewedit PageSize page setup and synchronization
关联线探究,如何连接流程图的两个节点

Kuberntes云原生实战一 高可用部署架构
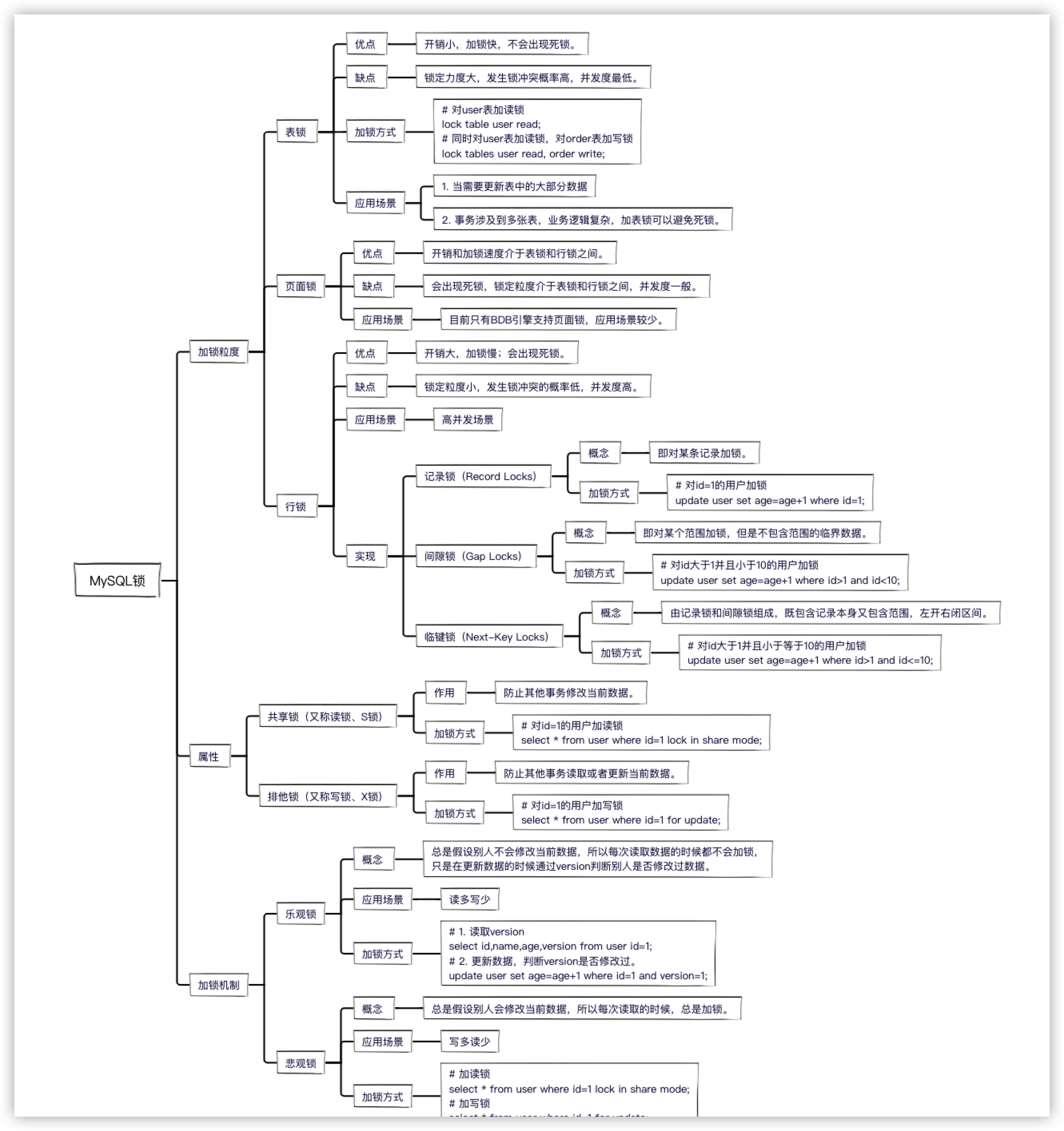
Myslq ten kinds of locks, an article will take you to fully analyze

Optimization of the problem that the request flow fails to terminate during page switching of easycvr cluster video Plaza
随机推荐
Common components of flask
写博客文档
RichView 文档中的 ITEM
Data analysts sound tall? Understand these points before you decide whether to transform
从20s优化到500ms,我用了这三招
Develop those things: easycvr platform adds playback address authentication function
2022安全员-A证考题及在线模拟考试
leetcode刷题:栈与队列03(有效的括号)
薛定谔的日语学习小程序源码
Big factories are wolves, small factories are dogs?
EMC-电路保护器件-防浪涌及冲击电流用
Keras machine translation practice
强大的万年历微信小程序源码-支持多做流量主模式
新版图解网络PDF即将发布
RichView TRVDocParameters 页面参数设置
从20s优化到500ms,我用了这三招
Penetration tools - trustedsec's penetration testing framework (PTF)
想请教一下,券商选哪个比较好尼?本人小白不懂,现在网上开户安全么?
[multithreading] lock strategy
三菱PLC FX3U脉冲轴点动功能块(MC_Jog)