当前位置:网站首页>Clip can also do segmentation tasks? The University of Gottingen proposed a model clipseg that uses text and image prompt and can do three segmentation tasks at the same time, squeezing out the clip a
Clip can also do segmentation tasks? The University of Gottingen proposed a model clipseg that uses text and image prompt and can do three segmentation tasks at the same time, squeezing out the clip a
2022-07-25 19:06:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
Share this article CVPR 2022 The paper 『Image Segmentation Using Text and Image Prompts』, The University of Gottingen proposed a method of using text and images prompt, A model that can do three split tasks at the same time CLIPSeg, Squeeze dry CLIP The ability of !
The details are as follows :

Address of thesis :https://arxiv.org/abs/2112.10003
Code address :https://github.com/timojl/clipseg
01
Abstract
Image segmentation is usually solved by training a model for a set of fixed object classes . It is expensive to merge other classes or more complex queries later , Because it needs to retrain the model on the dataset containing these expressions .
In this paper , The author puts forward a method that can be tested according to any prompt System for generating image segmentation .prompt It can be text or image . This method enables the model to create a unified model for three common segmentation tasks ( Only once ), These tasks have different challenges : Reference expression segmentation 、zero-shot Division and one-shot Division .
This article takes CLIP Model as the backbone , Using a Transformer The decoder of , To achieve intensive Forecasting . In the face of PhraseCut After training the extended version of the dataset , The system in this paper will be based on free text prompt Or the additional image expressing the query generates a binary segmentation graph for the image . This novel hybrid input can not only dynamically adapt to the above three segmentation tasks , It can also adapt to any binary segmentation task that can formulate text or image queries . Last , The author finds that the system in this paper can well adapt to general query .
02
Motivation
The ability to generalize to unseen data is a basic problem related to the wide application of artificial intelligence . for example , It is important for home robots to understand the user's prompts , This may involve object types that you haven't seen or unusual expressions of objects . Although humans are good at this task , But this form of reasoning is challenging for computer vision systems .

Image segmentation requires a model to output the prediction of each pixel . Compared with image classification , Segmentation requires not only predicting what can be seen , You also need to predict where you can find it . The classical semantic segmentation model is limited to the categories in the segmentation training set . at present , Different ways have emerged to extend this rather limited setting ( As shown in the table above ):
In the broad sense zero-shot In segmentation , It is necessary to separate the seen and unseen categories by associating the unseen category with the seen category .
stay one-shot In segmentation , In addition to the query image to be segmented , It also provides the required classes in the form of images .
Split in reference expression (RES) in , The model is trained on complex text queries , But you can see all classes during training ( That is, you don't generalize classes you haven't seen ).

In this work , The author introduced CLIPSeg Model ( Pictured above ), The model can segment based on any text query or image .CLIPSeg It can solve all three tasks mentioned above . This multimodal input format goes beyond the existing multitask benchmark , for example Visual Decathlon, Where input is always provided in the form of an image . In order to implement this system , The author uses pre trained CLIP Model as the backbone , And train a lightweight conditional segmentation layer at the top ( decoder ).
Author use CLIP Joint text of - Visual embedding space to adjust the model of this paper , This enables the model to handle textual prompt And images . The idea of this article is to teach the decoder to CLIP Activation within is associated with output segmentation , At the same time, it allows as little data set deviation as possible and maintains CLIP Excellent and extensive predictive ability .
This paper adopts the general binary prediction setting , with prompt The matching foreground must be distinguished from the background . This binary setting can be adapted Pascal zero-shot Multi label prediction required for segmentation . Although the focus of this paper is to build a general model , The author found CLIPSeg In three low-shot Competitive performance is achieved in segmentation tasks . Besides , It can be generalized to classes and expressions that it has never seen split .
The main technical contribution of this paper is CLIPSeg Model , It proposes a method based on Transformer Lightweight decoder , Extends the famous CLIP Transformer be used for zero-shot and one-shot Split task . A key novelty of this model is that the segmentation target can be specified in different ways : By text or image .
This enables the model to train a unified model for multiple benchmarks . For text-based queries , And in PhraseCut The training network is different , The model in this paper can be generalized to new queries involving invisible words . For image-based queries , The author explores various forms of vision prompt engineering —— Similar to text in language modeling prompt engineering .
03
Method

The author uses vision based Transformer Of (ViT-B/16) CLIP Model as the backbone , And use small 、 Parameter efficient Transformer The decoder extends it . The decoder is trained on a custom data set to perform segmentation , and CLIP The encoder remains frozen . A key challenge is to avoid imposing strong pressure on predictions during segmentation training bias And keep CLIP The versatility of .
Considering these needs , The author puts forward CLIPSeg: A simple 、 Based solely on Transformer The decoder of . When querying images () adopt CLIP Vision Transformer when , Some layers S The activation of is read and projected onto the decoder token Embedded size D. then , Activation of these extracts ( Include CLS token) At every Transformer Previously added to the internal activation of the decoder .
The decoder has CLIP Activate as many Transformer block . The decoder passes on its Transformer( The last layer )
402 Payment Required
Of token Apply linear projection to generate binary segmentation , among P yes CLIP Of patch size . In order to inform the decoder of the segmentation target , Author use FiLM It is activated by the input of the conditional vector modulation decoder .This condition vector can be obtained in two ways :(1) Using text queries CLIP Text Transformer Embedding and (2) In Feature Engineering prompt Use... On images CLIP Vision Transformer.CLIP I haven't been trained , Only used as a frozen feature extractor . Due to the compact decoder , about D = 64,CLIPSeg Only 1,122,305 Three trainable parameters .
Because the learned position is embedded , original CLIP Limited to a fixed image size . This article enables different image sizes through insertion position embedding ( Including larger images ). To verify the feasibility of this method , The author compares the prediction quality of different image sizes , It is found that for greater than 350 Pixel image ,ViT-B/16 The performance of will only be reduced .
In this experiment , Author use CLIP ViT-B/16,patch size P by 16, If not otherwise stated , Then use D = 64 Projection size of . The author in S = [3 , 7 , 9] Layer extraction CLIP Activate , Therefore, the decoder in this paper has only three layers .
The model receives information about the segmentation target through the condition vector (“ What to split ?”), This can be done through text or images ( Through vision prompt engineering ) Provide . because CLIP Use shared embedding space for image and text titles , You can interpolate between the conditions on the embedding space and the interpolation vector . Formally , Set to support image embedding , Is the sample i Embedded text , The author obtains the condition vector by linear interpolation , among a It's from [0 , 1] Uniform sampling . The author uses this random interpolation as a data enhancement strategy during training .
3.1 PhraseCut + Visual prompts (PC+)
This article USES the PhraseCut Data sets , It contains more than 340,000 Phrases with corresponding image segmentation . first , This dataset does not contain visual support , Only the phrase , And each phrase has a corresponding object . The author extends this data set in two ways : Visual support samples and negative samples . For prompt p Add visual support image , Author from sharing prompt p All samples are randomly selected from the set .
Besides , The author introduces negative samples into the data set , That is, there is no object and prompt Matching samples . So , The phrase of the sample is replaced by a different phrase with a probability of . Phrases are randomly expanded with a set of fixed prefixes . Considering the position of the object , The author applies random clipping to the image , Make sure the object is at least partially visible . In the rest of this article , Call this extended data set PhraseCut+( Abbreviation for PC+). And use only text to specify the original target PhraseCut Data set comparison ,PC+ Support the use of images - Text interpolation for training . such , This paper can train a joint model for text and visual input .
3.2 Visual Prompt Engineering
In the tradition based on CNN Of one-shot In semantic segmentation ,masked pooling It has become a standard technique for computing prototype vectors for conditions . Support provided mask Be down sampled and compared with those from CNN Multiply the later feature map along the spatial dimension , Then gather along the spatial dimension . such , Only features related to supporting objects are considered in the prototype vector .
This method cannot be directly applied to Transformer The architecture of , Because semantic information is also in the whole hierarchy CLS token Accumulation , Not just in the feature map . Bypass CLS token And directly from the masked pooling It is also impossible to derive condition vectors from , Because it will destroy text embedding and CLIP Compatibility between visual embeddings .
To learn more about how to integrate target information into CLIP in , The authors compared several variants and their confounding effects in a simple experiment without segmentation . The author considers the cosine distance between vision and text-based embedding ( alignment ), And use the original CLIP Weight without any extra training .

say concretely , Author use CLIP To calculate the text embedding corresponding to the object name in the image . then , Embed them visually with the original image and use the modified RGB Image or attention mask Highlight the visual embedding of the target object for comparison . By aligning the vectors softmax, The distribution shown in the above figure is obtained .
For quantitative scores , The author only considers the target object name embedding , It is hoped that it will have stronger alignment with the highlighted image than with the original image . It means , If highlighting technology improves alignment , Then the object probability should increase greatly . The author is based on LVIS Data sets , Because its image contains multiple objects and a rich set of categories .
CLIP-Based Masking

Directly equivalent to vision Transformer Medium masked pooling Yes, it will mask be applied to token. Usually , Vision Transformer By a set of fixed token form , these token You can interact at each level through multiple attention : For reading CLS token And initially from the image patch Related to the image area obtained in token.
Now? , One or more Transformer The interaction of layers is constrained to mask Inside patch token And just CLS token To merge mask. submit a memorial to the emperor ( Left ) It shows that this introduction mask The form effect of is not good . By limiting and CLS token Interaction ( submit a memorial to the emperor Left , The top two lines ), Only small improvements have been achieved , Limiting all interactions will significantly reduce performance . From this we come to the conclusion that , Internally combine images and mask More complex strategies are needed .
Visual Prompt Engineering
In addition to the application in the model mask, Can also be mask Combine with the image to form a new image , Then by vision Transformer Handle . Be similar to NLP Medium prompt engineering ( For example, in GPT-3 in ), The author calls this process vision prompt engineering . Because of this form of prompt The design is novel , And the best strategy in this case is unknown , The author's vision of design prompt Different variants of have been widely evaluated .
Find out mask And the exact form of how the image is combined . The author identifies three image operations to improve the object text prompt Alignment between and image : Reduce background brightness 、 Fuzzy background ( Using a Gaussian filter ) And crop to object . The combination of all three performs best . So in the rest , This variant will be used .
04
experiment

The above table shows that in the original PhraseCut Evaluation on dataset referring expression segmentation(RES) Performance comparison of .

In the broad sense zero-shot In segmentation , In addition to the known categories, the test image , It also contains categories that have never been seen before . Author use Pascal-VOC Benchmark evaluation model zero-shot Segmentation performance , The performance is shown in the table above .

stay Pascal-5i On , The general model of this paper CLIPSeg (PC+) Competitive performance in the most advanced methods , Only the latest HSNet Perform better .COCO-20i The results show that CLIPSeg In addition PhraseCut(+) It can also work well when training on other data sets .
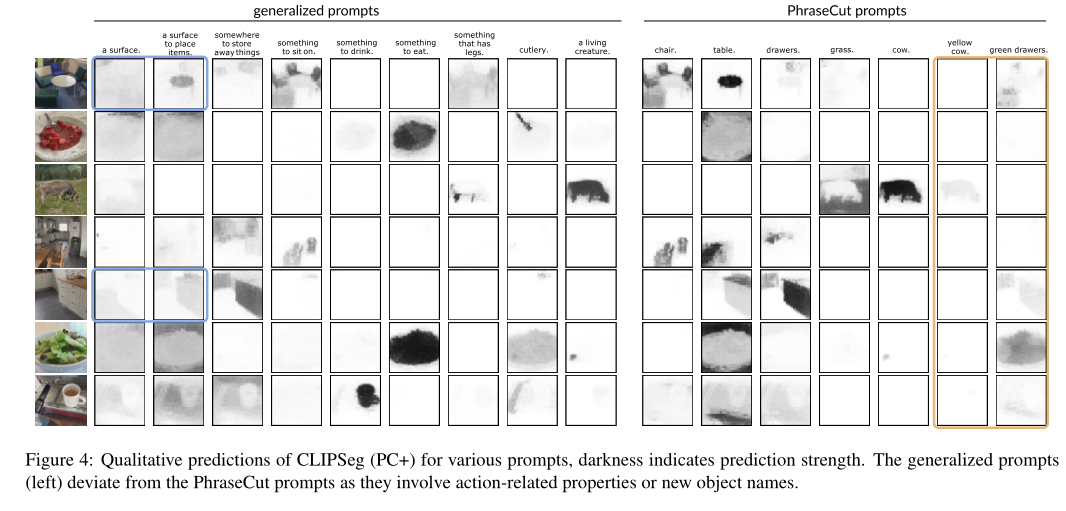
The picture above shows CLIPSeg(PC+) For all kinds of prompt Qualitative prediction , Dark color indicates prediction intensity .

From the above table , It can be found in PC+ Trained on CLIPSeg The performance of version is better than CLIP-Deconv baseline And in L VIS On the training version , The latter contains only object tags rather than complex phrases . This result shows that , The variability of data sets and the complexity of models are necessary for generalization .

In order to determine CLIPSeg Key to performance , The author of PhraseCut Ablation studies were carried out ., As shown in the table above , The authors evaluate text-based and visual based prompt To get a complete picture . When using random weights instead of CLIP Weight time (“ nothing CLIP Preliminary training ”), Both text-based performance and visual performance will decline . When the number of parameters is reduced to 16 individual (“D = 16”) when , Performance has dropped dramatically , This shows the importance of information processing in the decoder . Use unfavorable vision prompt Technology will reduce the performance of visual input .
05
summary
This paper proposes CLIPSeg Image segmentation method , This method can adapt to new tasks through text or image prompts during reasoning , Instead of expensive training for new data . say concretely , The author studied the novel vision in detail prompt engineering , It also shows the expression segmentation 、zero-shot Divide and one-shot Competitive performance on segmentation tasks . besides , Both qualitatively and quantitatively, the author proves that the model in this paper can be extended to new prompt.
The author believes that the method in this paper is useful , Especially for inexperienced users , Build a segmentation model by specifying prompts and robot settings that need to interact with humans . Multitasking is a promising direction for future research on more general and real-world compatible visual systems . The experiment of this paper , Especially based on ImageNet Of ViTSeg baseline Comparison , Highlight the image CLIP The ability of such a basic model to solve multiple tasks at once .
Reference material
[1]https://arxiv.org/abs/2112.10003
[2]https://github.com/timojl/clipseg

END
Welcome to join 「 Image segmentation 」 Exchange group notes : Division

边栏推荐
- ES6 implements the observer mode through proxy and reflection
- Single arm routing experiment demonstration (Huawei router device configuration)
- 有孚网络受邀参加2022全国CIO大会并荣获“CIO信赖品牌”称号
- 阿里云技术专家秦隆:可靠性保障必备——云上如何进行混沌工程?
- The degree of interval of basic music theory
- 【加密周报】加密市场有所回温?寒冬仍未解冻!盘点上周加密市场发生的重大事件!
- Deng Qinglin, a technical expert of Alibaba cloud: Best Practices for disaster recovery and remote multi activity across availability zones on cloud
- 基于Mysql-Exporter监控Mysql
- ThreadLocal Kills 11 consecutive questions
- Circulaindicator component, which makes the indicator style more diversified
猜你喜欢
SQL 实现 Excel 的10个常用功能,附面试原题

Basic music theory -- configuring chords

“未来杯”第二届知识图谱锦标赛正式启动

【Web技术】1391- 页面可视化搭建工具前生今世

人人可参与开源活动正式上线,诚邀您来体验!

Baklib:制作优秀的产品说明手册
![[open source project] stm32c8t6 + ADC signal acquisition + OLED waveform display](/img/5f/413f1324a8346d7bc4a9490702eef4.png)
[open source project] stm32c8t6 + ADC signal acquisition + OLED waveform display

ThreadLocal夺命11连问

MES管理系统有什么应用价值

Ultimate doll 2.0 | cloud native delivery package
随机推荐
Fearless of high temperature and rainstorm, how can Youfu network protect you from worry?
Pixel2mesh generates 3D meshes from a single RGB image eccv2018
软件测试(思维导图)
Weak network test tool -qnet
基于Mysql-Exporter监控Mysql
高并发下如何保证数据库和缓存双写一致性?
Care for front-line epidemic prevention workers, Haocheng JIAYE and Gaomidian sub district office jointly build the great wall of public welfare
QT compiled successfully, but the program could not run
基于FPGA的1080P 60Hz BT1120接口调试过程记录
How to prohibit the use of 360 browser (how to disable the built-in browser)
Typescript reflection object reflection use
怎样设计产品帮助中心?以下几点不可忽视
【小程序开发】你了解小程序开发吗?
"Wdsr-3" Penglai pharmaceutical Bureau solution
The bank's wealth management subsidiary accumulates power to distribute a shares; The rectification of cash management financial products was accelerated
接口自动化测试平台FasterRunner系列(二)- 功能模块
The degree of interval of basic music theory
Alibaba cloud technology expert haochendong: cloud observability - problem discovery and positioning practice
App test point (mind map)
Yyds dry inventory interview must brush top101: reverse linked list