当前位置:网站首页>How to select and build a real-time data warehouse scheme
How to select and build a real-time data warehouse scheme
2022-06-26 06:11:00 【Impl_ Sunny】
One 、 Real time data warehouse query requirements
Before the formal discussion of real-time data warehouse , Let's take a look at the main demand of the industry for real-time data warehouse , This helps us to understand the original intention of various schemes of real-time data warehouse , Understand what requirements it is based on .
This will also help us think about our needs from more dimensions 、 Conditions 、 How to evaluate and balance some key elements such as landing difficulties , The final implementation is based on how the function under the existing conditions maximizes its value .
Traditionally, we usually divide data processing into offline and real-time . For real-time processing scenarios , We can generally be divided into two categories :
- Such as monitoring alarm 、 Large screen display scenes require seconds or even milliseconds
- For example, most real-time reports do not have very high timeliness requirements , General minute level , such as 10 Minutes and even 30 Within minutes is acceptable

Based on the above query requirements , There are several common real-time data warehouse schemes in the industry :

Two 、 Comparison of different schemes
2.1 Scheme 1 :Kappa framework
Kapp Architecture understanding , May refer to :Kappa framework
2.1.1 Scheme description
Kappa The architecture will be multi-source data ( User logs , system log ,BinLog journal ) Send to in real time Kafka, And then through Flink colony , Build different flow computing tasks according to different businesses , Analyze and process data , And output the calculation results to MySQL/ElasticSearch/HBase/Druid/KUDU And the corresponding data source , Finally, it provides applications for data query or multidimensional analysis .

2.1.2 Program features
- advantage : The plan is simple ; Data real time
- shortcoming :
- Every time a user generates a new report requirement , All need to develop one Flink Streaming computing tasks , The labor cost and time cost of data development are both high .
- For the data platform that needs to access nearly 10 billion every day , If you want to analyze the data of the last month , You need Flink The scale of the cluster is very large , And many intermediate data of calculation need to be stored in memory for multiple streams Join.
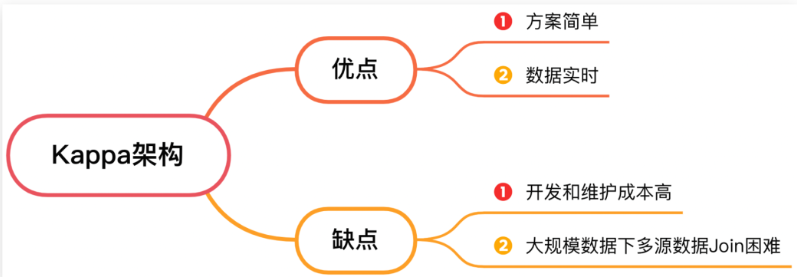
2.2 Option two : Standards based layering + Flow calculation
In order to solve 【Kappa Architecture 】 The high development and maintenance cost of putting all the data in one layer , So there is the standard based layering + The scheme of flow computing .
2.2.1 Scheme description
Build a real-time data warehouse based on the hierarchical standard of the traditional data warehouse , Divide the data into ODS、DWD、DWS、ADS layer . First, access data from various sources ODS Paste source data layer , Right again ODS Layer data usage Flink Real-time computing for filtering 、 cleaning 、 conversion 、 Operations such as Association , Form... For different business topics DWD Data detail layer , And send the data to Kafka colony .
After the DWD On the basis of , Reuse Flink Real time calculation for mild summary operation , To a certain extent, it is convenient to query DWS Light aggregation level . Finally, facing the business requirements , stay DWS On the basis of layer, the data is further organized into ADS Data application layer , Business supports user portrait on the basis of data application layer 、 User reports and other business scenarios .

2.2.2 Program features
- advantage : Data responsibilities at all levels are clear
- shortcoming :
- Multiple Flink Cluster maintenance is complicated , And too much data resides in Flink The load of the cluster will also increase
- I won't support it upset operation
- Schema Maintenance trouble .

2.3 Option three : The standard is layered + Flow calculation + Batch calculation
2.3.1 Scheme description
In order to solve 【 The standard is layered + Flow calculation scheme 】 I won't support it upset and schema Maintenance complexity and other issues , stay 【 The standard is layered + Flow calculation scheme 】 Add based on HDFS Join in Spark Offline solutions , That is to say The scheme of parallel flow of offline data warehouse and real-time data warehouse .

2.3.2 Program features
- advantage : Both support real-time OLAP Inquire about , It also supports offline large-scale data analysis
- shortcoming :
- Data quality management is complex : It is necessary to build a data management system compatible with the blood relationship between offline data and real-time data , It is a complicated engineering problem .
- Offline data and real-time data Schema Unification is difficult .
- Schema not supported upset.

2.4 Option four : Standard hierarchy + Flow calculation + Data Lake
2.4.1 Scheme description
With the development of technology , In order to solve the problems of data quality management and upset problem . A stream batch integration architecture has emerged , This architecture is based on the data Lake three swordsmen Delta Lake / Hudi / Iceberg Realization + Spark Realization .
We use Iceberg As an example, the architecture of this scheme is introduced , You can see this scheme and the previous scheme from the figure below 2 Very similar , Just in the data storage layer will Kafka In exchange for Iceberg.

2.4.2 Program features
It has several characteristics , Among them the first 2、3 spot , Particularly important , Need special attention , This is also an important difference between this scheme and other schemes .
In programming, flow calculation and batch calculation are unified into the same SQL Engine , Based on the same Flink SQL It can be used for flow calculation , Batch calculation can also be performed .
Unified storage of flow calculation and batch calculation , That is, unified to Iceberg/HDFS On , In this way, the blood relationship of data and the establishment of data quality system have also become simple .
Because the storage layer is unified , Data Schema Naturally, they are unified , In this way, compared with the two separate calculation logics of flow batch , The processing logic and metadata management logic have been unified .
Layers in the middle of the data (ODS、DWD、DWS、ADS) data , All support OLAP Real time query of .

So why Iceberg It can undertake the scheme of real-time data warehouse , The main reason is that it solves these problems in the process of flow batch unification for a long time :
Both streaming write and incremental pull are supported
Solve the problem of too many small files . Data Lake implements the interface of merging small files ,Spark / Flink The upper engine can call the interface periodically to merge small files .
Support batch and streaming Upsert(Delete) function . Batch Upsert / Delete The function is mainly used for offline data correction . streaming upsert The previous scene introduces , The main reason is that in the flow processing scenario, after window time aggregation, if there is a delay in the arrival of data, there will be an update demand . This kind of requirement needs a storage system that can support updating , The offline data warehouse needs full data coverage for updating , This is also one of the key reasons why offline data warehouse can not be real-time , Data Lake needs to solve this problem .
meanwhile Iceberg It also supports relatively complete OLAP ecology . Such as support Hive / Spark / Presto / Impala etc. OLAP Query engine , Provides efficient multidimensional aggregate query performance .

2.5 Option five : Based on the whole scene MPP Database implementation
The previous four schemes , It is based on the optimization of data warehouse scheme . The scheme is still relatively complex , If I can provide a database that can meet the storage of massive data , It can also realize rapid analysis , Isn't that convenient . At this time, there is a phenomenon called StartRocks、ClickHouse Ali Hologres The whole scene represented by MPP database .
be based on StartRocks perhaps ClickHouse Build real-time data warehouse . Let's take a look at the specific implementation : Write the real-time data on the data source directly to the consumer service .
There are two ways to handle the case where the data source is an offline file , One is to convert the file into streaming data for writing Kafka, Another case is to pass the file directly through SQL Import ClickHouse colony .
ClickHouse Access Kafka Message and write the data to the corresponding original table , Based on the original table, materialized views can be built 、Project Data aggregation and statistical analysis .
Application services are based on ClickHouse Data is provided externally BI、 Statistical report 、 Alarm rules and other services .

3、 ... and 、 Specific type selection suggestions
For this 5 Kind of plan , In the specific model selection , We should according to the specific business needs 、 Team size, etc . Here are some specific suggestions , I hope it can provide you with some references more or less 、 New perspectives or new ideas for reference :
- Simple for business , And the big data architecture with streaming data as the main data stream can adopt 【Kappa framework 】.
- If the business is based on Flow Computing , Layering data , Data access , High requirements for multi subject data , It is recommended to use 【 Standards based layering + Flow calculation 】 The plan .
- If the flow data of the business is batch data, there are many , And there is little direct correlation between stream data and batch data , It is recommended to use 【 The standard is layered + Flow calculation + Batch calculation 】 The plan . In this case, the respective advantages of flow computing and batch computing can be brought into play .
programme 4 It is a relatively perfect data warehouse scheme , To support larger and more complex application scenarios , It is suggested that the big data R & D personnel should 20 The above teams , You can focus on .
The big data R & D team is 10 Left and right , To maintain a solution like 2、3、4 In that way ODS、DWD、DWS、ADS If the real-time data warehouse construction is carried out in the way of data layering , We need to invest more resources . Recommended usage scheme 5 One stop implementation of simple real-time data warehouse .

Four 、 Big plant scheme sharing
Introduced so many real-time data warehouse schemes , So many friends will ask , What kind of scheme does the big factory use ? In fact, each large factory has its own business characteristics , You will also choose different solutions . Let's share briefly OPPO、 The scheme of didi and bitland , So that we can better understand the specific implementation of the five architectures in this sharing .
However, I will not introduce the specific architecture details too much , With the previous content foundation , I believe that you can quickly understand the characteristics of each architecture through the architecture diagram . I just hope you can learn from the experience of big factories , Understand the original intention of their architecture design and the specific problems to be solved , At the same time, it also provides some ideas for our architecture design .
OPPO Real time computing platform architecture , The scheme is actually similar to the scheme 2 Standards based layering of + Flow calculation :
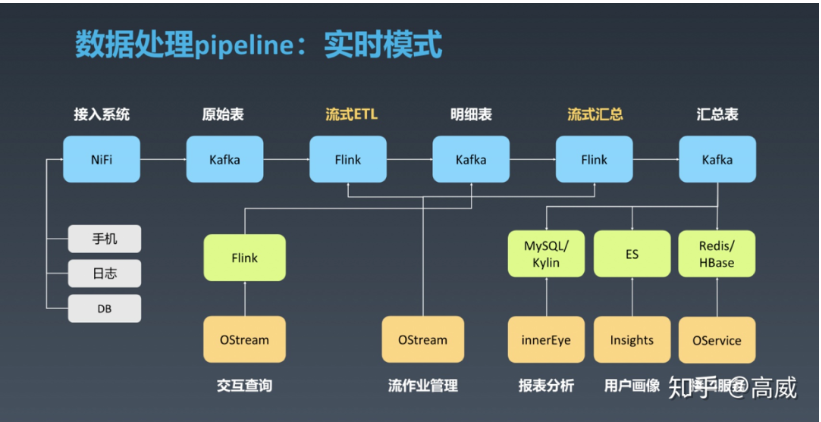
Didi's big data platform architecture is like this , Its scheme is actually similar to the scheme 2 Standards based layering of + Flow calculation :
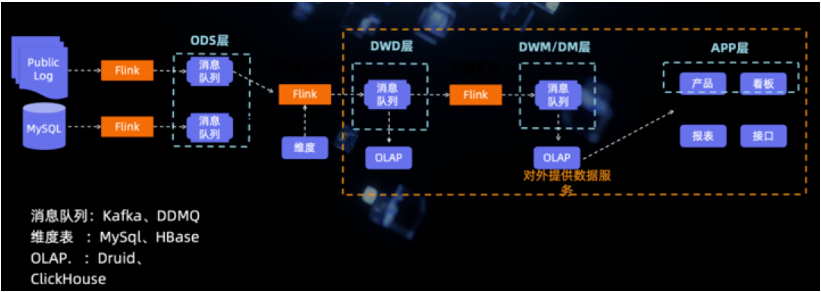
Take a look at the plan of bitland , Its scheme type is scheme 3 The standard layered embodiment of + Flow calculation + Batch calculation , It also introduces ClickHouse, It can be seen that the data scheme of bit continent is very complex :
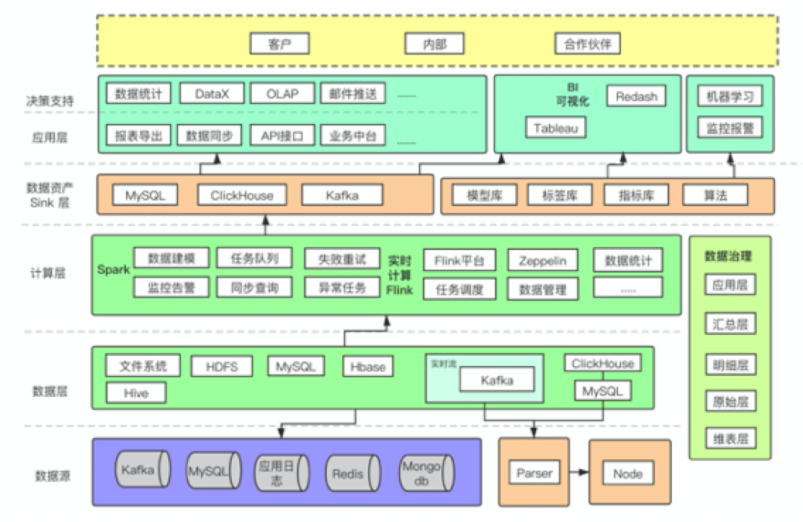
5、 ... and 、 summary
This paper introduces the common real-time data warehouse schemes in the market , The advantages and disadvantages of different schemes are introduced . In the process of use, we need to select the appropriate architecture according to our own business scenarios .
In addition, the real-time data warehouse scheme is not “ Move in ”, But according to the business “ Evolved ” Of , The specific design needs to be based on their own business conditions , Find the most suitable real-time data warehouse architecture .
During the construction of the real-time data warehouse, the major controversy is that we adopt the standard layered system + Flow calculation + Scheme of data Lake , Or try it based on the whole scene MPP Database implementation .
During the discussion, the major differences were based on the whole scene MPP Is the database implementation a data warehouse scheme , After all, there is no standard idea of data warehouse layering in this scheme , But around the needs of large-scale data statistics .
But my point is : All plans need to be based on actual needs , our 80% Your needs are in a 180 Large and wide table with multiple fields ( Every day 80 Billion bars ,3TB Data volume ) It can be used for flexible statistical analysis , Quickly provide the basis for business decisions . So we chose to base on the whole scene MPP Database scheme .
New technologies emerge in endlessly , It's a great thing for us technologists to try something new , However, the actual implementation still suggests that we should make decisions after the demand is converged , Keep a cool mind , Sometimes appropriately “ Bullet Fly ” It's also good .
Reference material :
There are various real-time data warehouse schemes , How to select and build the actual landing
边栏推荐
- volatile应用场景
- numpy.exp()
- String类学习
- 工作积累——Web请求中使用ThreadLocal遇见的问题
- Spark source code analysis (I): RDD collection data - partition data allocation
- Selective Search for Object Recognition 论文笔记【图片目标分割】
- Typora activation method
- Household accounting procedures (the second edition includes a cycle)
- canal部署、原理和使用介绍
- 【群内问题学期汇总】初学者的部分参考问题
猜你喜欢

Data visualization practice: Experimental Report

A tragedy triggered by "yyyy MM DD" and vigilance before New Year's Day~

如何设计好的技术方案

Overloading and overriding
重载和重写

MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications

Basic construction of SSM framework
Logstash——使用throttle过滤器向钉钉发送预警消息

Hot! 11 popular open source Devops tools in 2021!

Import / export function implementation
随机推荐
MySQL-08
Deeply uncover Ali (ant financial) technical interview process with preliminary preparation and learning direction
Detailed explanation of serial port communication principle 232, 422, 485
Adapter mode
Redis多线程与ACL
消息队列-消息事务管理对比
Tortoise and rabbit race example
架构设计方法
How to use the tablet as the second extended screen of the PC
numpy. exp()
Typora activation method
302. minimum rectangular BFS with all black pixels
SQL Server 函数
5 minutes to learn regular expressions
numpy.frombuffer()
Ribbon load balancing service call
numpy. random. choice
Data visualization practice: Experimental Report
冒泡排序(Bubble Sort)
Mongodb -- use mongodb to intercept the string content in the field and perform grouping statistics