当前位置:网站首页>Android 面试题——如何徒手写一个非阻塞线程安全队列 ConcurrentLinkedQueue?
Android 面试题——如何徒手写一个非阻塞线程安全队列 ConcurrentLinkedQueue?
2022-08-05 03:23:00 【代码不难写】
从队列容器选择,到算法一步步迭代,这是一篇从零开始逐步推演出“非阻塞线程安全队列”思想方法的文章。(有剧情反转~)
队列容器设计
若用数组作为队列的容器,就必须得加锁,因为数组是一块连续内存地址,多线程场景下,读写同一块内存地址不得不互斥地访问。
链式结构
链式结构就没有这个烦恼。链的每个结点都对应不同的内存地址,在多线程场景下,取头结点和插尾结点就不存在并发问题。(至少是降低了并发问题产生的概率)
通用的队列应该可存放任何类型的元素。
综上,就得声明一个带泛型的链结点:
// 结点
private static class Node<E> {
E item; // 结点数据字段
Node<E> next; // 结点后续指针
}
易变的字段
会不会存在多线程同时操纵同一个 Node 结点的 item 和 next 字段的情况?
当然有可能!为了让所有线程都能看到最新的 item 和 next,就得保证其 “可见性”:
private static class Node<E> {
volatile E item;
volatile Node<E> next;
}
volatile的字面意思是“易变的”,它用来形容共享变量高速缓存中的副本:
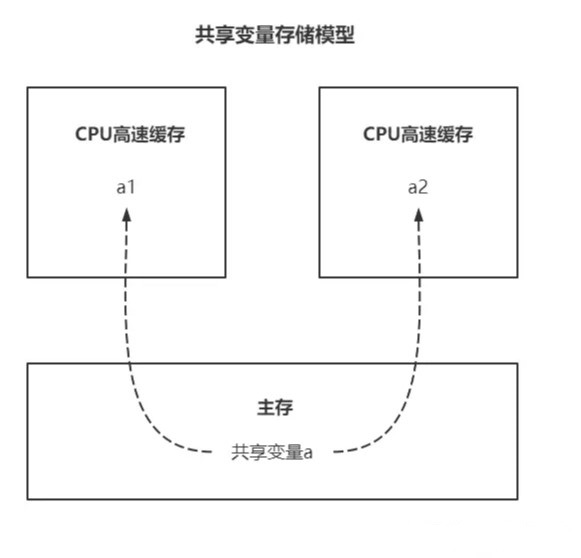
为提高线程运行效率,每个线程在得到 CPU 运行时间片后,都会将主存中变量拷贝到 CPU 高速缓存中(图中 a1,a2 即是 a 的副本),之后对共享变量的运算都在缓存中进行。
若 a 初始值为0,启动线程1和2,a 就新增了两个副本 a1, a2。随后俩线程并发地对 a 执行自增。
线程1执行a1++后 a1 = 1,线程2对线程1的操作一无所知,当它也执行a2++后 a2 = 1。而共享变量正确的值应该是 2。
造成这个错误的原因在于:缓存是相互隔离的,导致线程无法感知对方对共享变量的操作,即 “当前线程对共享变量的操作对其他线程不可见。”
解决方案自然是让其变得 “可见”。
java 的volatile关键词,用于告诉编译器该共享变量在缓存中的副本是“易变的”,线程不该相信它,于是乎:
- 线程写共享变量后,总是应该立刻将最新值同步到主存中。
- 线程读共享变量时,总是应该去主存拿最新值。
就这样通过读写主存,线程间建立了一种通信机制,让它们对共享变量的操作变得“可见”。
为了方便队头出队,队尾入队,得安排两个指针,分别指向一头一尾。
public class MyQueue<E> {
volatile Node<E> head; // 当前链头
volatile Node<E> tail; // 当前链尾
}
同样的道理,链头尾指针在多线程场景下是共享变量,也得使用 volatile 保持它们的可见性。
阶段性总结:
- 每个线程都有自己独立的内存空间(本地内存)
- 多线程能同时访问的变量称为“共享变量”,它在主存中。出于效率的考量,线程会将主存中的共享变量拷贝到本地内存,后续对共享变量的操作都发生在本地内存。
- 线程本地内存相互独立,导致它们无法感知别人对共享变量的操作,即当前线程对共享变量的操作对其他线程不可见。
- volatile 关键词是 java 解决共享变量可见性问题的方案。
- 被声明为 volatile 的变量,就是在告诉编译器该共享变量在线程本地内存中的副本是“易变的”,线程不该相信它。线程写共享变量后,总是应该立刻将最新值同步到主存中。线程读共享变量时,总是应该去主存拿最新值。
- 多线程场景下,队列的头尾指针,即结点的数据域和指针域都需要保证可见性。
出队
基础版
单链表取头结点的算法很简单,特别是已知头结点 head 时:
// 出队版本一
public E poll() {
Node<E> p = head;
E item = p.item; // 暂存头结点数据
head = head.next; // 更新头结点指针
p.item = null; // 老头结点内容置空
p.next = null; // 老头结点后续指针置空
return item;
}
在单线程情况下没什么毛病,但多线程就会出问题。
非阻塞线程安全版
某线程正在读头结点的 item 字段,另一个线程可能已经将其置空。
当然可以使用synchronize将对 head 的操作包裹起来,但这样处理是“有锁的”、“阻塞的”,即同一时间只有一个线程能获取锁,其余竞争者都被挂起等待锁被释放,然后再唤醒。“挂起-唤醒”是耗时的。
性能更好的“非阻塞”方式是CAS,全称为compare and swap,即“比较再交换”。当要更新变量值时,需要提供三个参数:1.当前值,2.期望值,3.新值。只有当前值和期望值相等时,才用新值替换当前值。
其中期望值就是线程被打断执行时暂存的值,当线程恢复执行后,用当前值和当时暂存值比较,如果相等,则表示被打断过程中其他线程没有修改过它,那此时更新它的值是安全的。
CAS 操作,被封装在sun.misc.Unsafe中,结合当前场景再简单封装如下:
private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe();
static <E> boolean casItem(Node<E> node, E cmp, E val) {
// 将 node 结点 item 字段值通过和期望值 cmp 比较,安全地置为 val。
return U.compareAndSwapObject(node, ITEM, cmp, val);
}
casItem()在多线程下将 node.item 通过和预期值cmp字段比较安全地赋予新值val。
除此之外,还需要一个更新头结点的 CAS 操作:
// 头结点脱链并更新头指针
final void updateHead(Node<E> h, Node<E> p) {
if (h != p) {
Node<E> h1 = h; // 暂存当前头指针
casHead(h, p); // 更新头指针到 p 的 CAS 竞争
h1.next = null; // 老头指针 next 置空
}
}
private boolean casHead(Node<E> cmp, Node<E> val) {
// 将头指针 head 通过和预期值 cmp 比较安全地赋予新值 val
return U.compareAndSwapObject(this, HEAD, cmp, val);
}
CAS 通常需配合轮询使用,因为多线程同时修改一个共享变量时,只有一个线程会成功(返回 true),其余失败(返回 false),失败线程通过轮询再次尝试 CAS,直到成功为止。
用这个思路,写一个线程安全的取链头结点算法:
// 出队版本二
public E poll() {
// 轮询
for (;;) {
E item = head.item;// 暂存 item
Node<E> next = head.next; // 暂存次头结点
// 将头结点 item 字段置空的 CAS 竞争
if (casItem(head, item, null)) {
for(;;) {
// 将头结点指向次头结点的 CAS 竞争
if (updateHead(head, next)) return item;
}
}
}
}
死循环修正版
这下修改头结点的 item 字段算是线程安全了,但这个算法还差点东西。若某线程在竞争中失败,另一个线程成功地将头结点 item 字段置空了,因为轮询的存在,失败线程会不停重试,但此时 head.item 的当前值已经变为 null 而不是暂存的 item。所以 CAS 轮询会一直失败,程序陷入死循环。
为了解决死循环,修改逻辑如下:
// 出队版本三
public E poll() {
// 轮询
for (Node<E> h = head, p = h, q;;) {
E item = p.item;// 暂存 item
// 若头结点 item 为空,则不进行 CAS 竞争
if (item != null && casItem(p, item, null)) {
for(;;) {
// 出队结点为 p,p 后续结点是新的头结点
// 但若 p 是尾结点,则头指针还是停留在 p
Node<E> newHead = ((q = p.next) != null) ? q : p;
// 更新头结点的 CAS 竞争
if (updateHead(head, newHead)) return item;
}
}
// q 是 p 后续结点
else if ((q = p.next) == null) {
// 链被掏空,更新头结点指针为最后一个非空结点,返回 null
updateHead(h, p);
return null;
}
// 还有后续结点
else {
p = q; // 工作结点 p 向后寻找第一个 item 非空的结点
}
}
}
新增了三个工作指针:
- p:表示第一个 item 字段不空的结点。
- q:p 的后续结点,用于向后遍历。
- h:暂存进入循环时的链头指针 head。
当某线程在将 item 置空的竞争中失败时,另一个线程成功地将头结点 item 置空。因为轮询的存在,失败线程继续尝试,当下一轮 for 循环执行到条件item != null时会停止竞争,因为当前 p 指向结点的 item 字段已经被其他线程置空。此时 p 借助于 q 的帮助往后遍历寻找第一个 item 不空的结点。若找到则再次发起竞争,若遍历到链尾仍未找到,则表示链已经被掏空,直接返回 null。
ps:空链的表达方式不是 head = null,而是 head 指向一个结点,head.next = null,head.item = null,如下图所示:
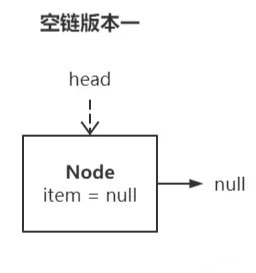
(之所以叫空链版本一,是因为这不是最终形态,这样设计会有问题,详解见下一节)
巧妙脱链哨兵版
offer() 是非阻塞的,它在执行任何一条语句都有被打断的可能,这就不太妙了。
考虑下面这个场景:“线程A正执行出队,刚进入 for 循环,即刚把当前头指针暂存在 h,p 中,此时它被中断了,另一个出队线程得到执行机会,并抢先把头结点出队了。终于又轮到线程A继续执行。。。”
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BoHziBjv-1659596641174)(https://upload-images.jianshu.io/upload_images/25149744-d8899c693f272de9.jpg?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
上图左侧为线程A正准备执行出队操作的初始状态,但它被中断了,另一个线程抢先把头结点 Node1 出队脱链了,并将 next 置空。当线程A恢复执行时,老母鸡变鸭的场景如上图右侧所示。
按照版本三的算法,之前暂存的头结点 p 的 item 字段已被置空,所以会往后遍历以定位到第一个 item 非空的结点。但尴尬的事情来了,因为在将头结点脱链时会将其 next 也置空。当 p 指针往后移动一个结点后就发现是空指针,版本三的算法判定这种情况即是链表被掏空,所以返回了 null。但明明链上还有一个 Node2 结点。。。
所以 “脱链结点” 和 “链尾结点” 的判定得区分开来。修改一下脱链方法:
final void updateHead(Node<E> h, Node<E> p) {
// 若修改头结点 CAS 竞争成功,则将头结点自旋(next域指向自己)
if (h != p && casHead(h, p))
lazySetNext(h, h);
}
// 将 head.next 指向自己
static <E> void lazySetNext(Node<E> node, Node<E> val) {
U.putOrderedObject(node, NEXT, val);
}
头结点脱链操作分为两步:
- 将头指针安全地指向新结点。
- 将头结点自旋,即 next 指针指向自己。 这两步操作的效果如下图所示:
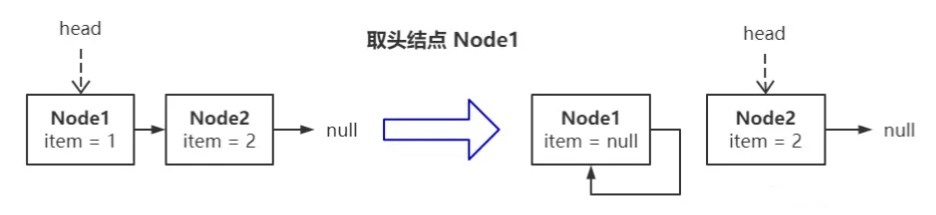
脱链结点 和 链尾结点 的判断条件区分开之后,脱链结点就有 “哨兵” 的效果:
- 脱链结点的判断条件为
p == p.next - 链尾结点的判断条件为
p.next == null相应的修改出队算法:
// 出队版本四
public E poll() {
restartFromHead:
// 第一层轮询
for(;;) {
// 第二层轮询
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// 找到真正的非空链头
if (item != null && casItem(p, item, null)) {
for(;;) {
Node<E> newHead = ((q = p.next) != null) ? q : p;
if (updateHead(head, newHead)) return item;
}
}
// 空链
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
// 哨兵:p 指向结点已经脱链,从新 head 开始重新遍历
else if (p == q)
continue restartFromHead;
// 当还有后续结点
else {
p = q;
}
}
}
}
新增了一个逻辑分支else if (p == q)用于表示当前遍历结点已脱链,脱链即表示头结点 head 已被更新到新位置。所以“从头遍历以寻找第一个 item 非空的结点”这项工作应该从新的 head 出发,即 p 应该被新 head 赋值,为了实现该效果,就不得不用上 goto 这个骚操作,在 java 中用 continue 实现。
性能优化最终版
版本四已经可以正确地在多线程场景下实现出队,但还有一个地方可以被优化。
虽然 CAS 是非阻塞的竞争,但竞争就要耗费 CPU 资源。所以能不竞争就不竞争,在当前算法中“更新链头指针”就是可以缓一缓的竞争。
// 出队版本五
public E poll() {
restartFromHead:
for(;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// 找到真正的非空头结点
if (item != null && casItem(p, item, null)) {
// 有条件地更新头指针
if(p!=h) {
Node<E> newHead = ((q = p.next) != null) ? q : p;
if (updateHead(head, newHead)) return item;
}
return item;
}
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
else if (p == q)
continue restartFromHead;
else {
p = q;
}
}
}
}
为更新头指针增加了条件p!=h,即只有当 head 指针滞后时才更新它。
因为 head 滞后必然造成 p 和 h 指向不同结点。p 的使命是从 head 出发往后定位到第一个 item 不空的结点。若 head 没有滞后,则 p 无需往后遍历,此时 p 必然等于 h。
不及时更新链头指针会导致算法出错吗?不会。因为该算法其实并不相信 head,所以安排了工作指针 p 通过遍历来找到真正的头结点。但不及时更新让竞争的次数直接减半,提高了性能。
阶段性总结:
非阻塞线程安全队列的出队算法总结如下:
- 总是从头指针出发向后寻找真正的头结点(item 非空),若找到,则将头结点 item 域置 null(CAS保证线程安全),表示结点出队,若未找到则返回 null。
- 采用 “自旋” 的方式来实现脱链(结点指针域与链脱钩),即 next 域指向自己(CAS保证线程安全)。自旋形成了哨兵的效果,使得往后遍历寻找真正头结点的过程中可感知到结点脱链。
- 滞后的头指针:“出队”、“脱链”、“更新头指针”不是配对的。理论上每次出队都应该脱链并更新头指针,为了提高性能,两次出队对应一次脱链+更新头指针,造成头结点会间歇性地滞后。
- 因为是非阻塞的,出队操作可能被其他线程打断,若是被入队打断则基本无害,因为队头队尾是两块不同的内存地址,不会有线程安全问题。若是被另一个出队线程打断,就可能发生想出的结点被其他线程抢先出队的情况。通过检测自旋+从头开始来定位到新得头结点解决。
入队
用同样的思路,一步步徒手写一个入队算法。
基础版
入队在链表结构上,即是链尾插入,这个算法很简单,特别是在已知尾指针tail的情况下:
// 入队版本一
public boolean offer(E e) {
Node<E> newNode = createNode(e)// 构建新结点
tail.next = newNode;// 链尾链入新结点
tail = newNode;// 更新链尾指针
return true;
}
非阻塞线程安全版
但在多线程情况下就变得有点复杂,比如在向尾结点插入新结点的同时,另一个线程正在删除这个尾结点。
尾结点tail这个变量是多线程共享的,对它的操作需要考虑线程安全问题。和出队操作一样使用 CAS。
对于链尾插入的场景来说,尾结点 next 指针的期望值是null,若不是 null 则表示尾结点被另一个线程修改了,比如被另一个写线程抢先一步在尾部插入了一个新结点。尾结点 next 指针的新值自然是 newNode。
CAS 的封装如下:
// java.util.concurrent.ConcurrentLinkedQueue
private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe();
static <E> boolean casNext(Node<E> node, Node<E> cmp, Node<E> val) {
return U.compareAndSwapObject(node, NEXT, cmp, val);
}
castNext()即是 CAS 机制的一个实现,它在多线程下将 Node 结点的 next 指针安全地赋予新值。
除此之外,还需要一个casTail():
private boolean casTail(Node<E> cmp, Node<E> val) {
return U.compareAndSwapObject(this, TAIL, cmp, val);
}
它在多线程下将链尾指针安全地赋予新值。
用这个思路,写一个线程安全的入队算法:
// 入队版本二
public boolean offer(E e) {
Node<E> newNode = createNode(e)
// 轮询
for (;;) {
// 尾插入 CAS 竞争
if (casNext(tail, null, newNode)) {
// 若竞争成功,则更新尾指针 CAS 竞争
for(;;){
if (casTail(tail, newNode)) return true;
}
}
}
}
死循环修正版
这下尾插入算是线程安全了,但这个算法还差点东西,假设某线程在 CAS 的竞争中失败,而另一个线程赢得了竞争,成功地在链尾插入了新结点。因为轮询的存在失败线程会继续尝试,但往后一切的尝试都将失败,因为预期值已经不再是 null,程序陷入了死循环。
为了解决死循环,修改逻辑如下:
// 入队版本三
public boolean offer(E e) {
Node<E> newNode = createNode(e)
// 循环之初新增工作指针 p 指向尾结点
for (Node p = tail;;) {
// 工作指针 q 表示 p 的后续结点
Node q = p.next;
// 找到真正的尾结点,进行 CAS 尾插入
if (q == null) {
if (casNext(p, null, newNode)) {
for(;;) {
if (casTail(tail, newNode)) return true;
}
}
} else {
p = q; // p 指针向后移动一个结点
}
}
}
新增了两个工作指针 p 和 q,它们相互配合往后遍历队列,目的是找到真正的链尾结点。
当某线程 CAS 竞争失败,另一个获胜线程成功地在链尾插入了新结点,因为轮询的存在,失败线程会继续走到if (q == null),但此时 q 必然不为 null(因为另一个线程已经成功插入新结点),就会走到 else 分支执行 p 结点后移,即使另一个线程偷偷地插入了 n 个新结点也不要紧,工作指针会一直往后移动,直到找到了新的尾结点,此刻 if (q == null) 再次成立,将再次尝试 CAS 竞争。
失败者窘境优化版
第二个版本的尾插入算法看上去好了很多,但还有可以优化的地方。
考虑下面这个场景,失败者的窘境:若某线程 CAS 竞争失败,另一获胜线程在链尾插入 10 个结点。不巧,失败线程一直没被调度执行,该过程中,其他线程疯狂地往链尾插入了 90 个结点。终于失败线程恢复了执行,难道还要往后遍历 100 个结点才能再次 CAS 竞争吗?在这 100 次遍历过程中又被其他线程抢先插入新结点怎么样?岂不是得无穷无尽地遍历?感觉失败线程将永远得不到机会插入新结点。。。
解决方案是 “抄近路”。竞争失败后,工作指针 p 往后遍历的目的是 “找到真正的尾结点”,既然别的线程已成功插入了新结点,tail 必然已被更新,那直接将 p 指向 tail 不是可以抄近路吗?
// 入队版本三
public boolean offer(E e) {
Node<E> newNode = createNode(e)
// 循环之初新增工作指针 t 保存 tail 的副本
for (Node t = tail, p = t;;) {
Node q = p.next;
if (q == null) {
if (casNext(p, null, newNode)) {
for(;;) {
if (casTail(tail, newNode)) return true;
}
}
} else {
// 性能优化:若其他线程偷偷地插入新结点,则直接指向最新的链尾结点
p = t != (t = tail) ? t : q;
}
}
}
新增了链尾指针 t,它是链尾指针 tail 在当前线程内存中的副本,为啥要保存一份副本?因为 tail 是线程共享变量,当别的线程修改 tail 之后,就可对比 t 和 tail 是否相等来判断链尾是否发生了后移。
这个对比在程序中表现为t != (t = tail),当发生“失败者的窘境”时,tail 和 t 的值必然不相等,此时可直接将工作指针 p 抄近路到最新的链表尾 t。
性能优化版
出队算法采用“滞后的头结点”以减少 CAS 竞争,入队算法也如法炮制“滞后的尾结点”:
// 入队版本四
public boolean offer(E e) {
Node<E> newNode = createNode(e)
for (Node t = tail, p = t;;) {
Node q = p.next;
// 当 p 是尾结点时,进行 CAS 尾插入
if (q == null) {
if (casNext(p, null, newNode)) {
// 只有当 tail 落后于真正链尾时才更新它
if (p!=t)
casTail(t, newNode);
return true;
}
} else {
p = t != (t = tail) ? t : q;
}
}
}
在更新链尾指针外加了一个条件,即 p 和 t 相等的情况下不更新。啥情况下它俩会相等?只有当进入循环时 tail 指向的是真正的链尾时,它俩才会相等。所以该条件可以理解为 “当在链尾插入一个新结点时,发现 tail 指针落后于真正的队尾时,才更新链尾指针。”
更新 tail 的过程如下图所示:
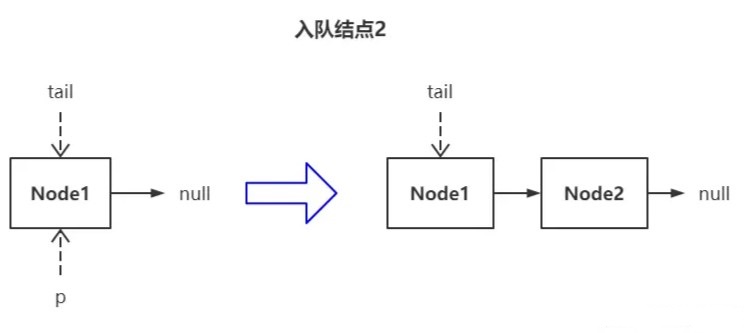
队列当前只有一个结点,所以它是头结点也是尾结点,tail 指针指向它。进入轮询时,工作指针 p 被赋值为 tail。因为此时 tail 指向的已经是真正的尾结点,所以 p 无需继续向后遍历,就地直接插入了新结点,此时 p 的值依然和 tail 相等,该情况下不会更新尾指针。
若在这种场景下继续插入新结点会怎么样?
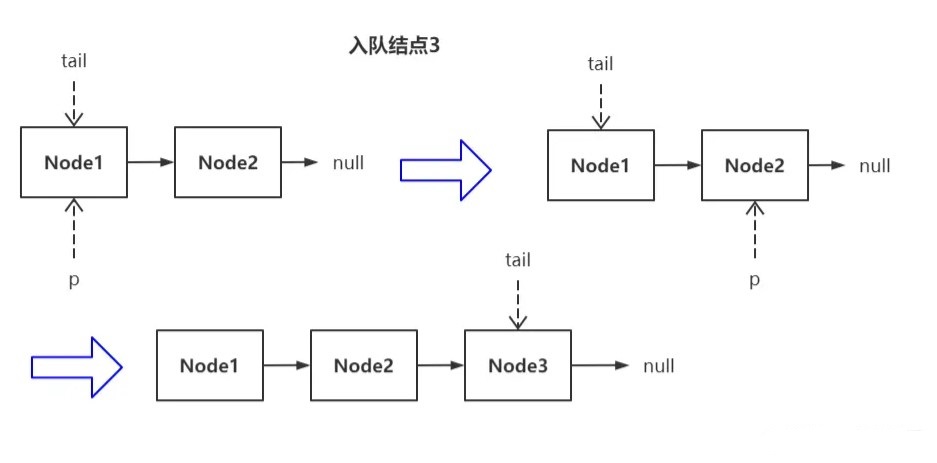
进入轮询时,tail 结点已经滞后了(状态一),所以 p 得向后遍历,最终找到了真正的尾结点 Node2(状态二),执行插入新结点,此时 p 发生了偏移,所以其值必然和 tail 不同,该情况下会更新尾指针(状态三)。
以此类推,每插入两个结点,就会更新一次尾指针。
不及时更新链尾指针会导致算法出错吗?不会。因为该算法其实并不相信 tail,所以安排了工作指针 p 通过遍历来找到真正的链尾。
头脚颠倒修正版
在出入队可以并发的场景下,可能出现头指针越过尾指针的情况,比如: “链当前有 2 个结点,且 tail 指针滞后一个结点,线程 A 正准备往链尾追加新结点,但另一线程的出队操作捷足先登了,它一口气出队 2 个结点,此时线程 A 恢复执行。。。”
这种情况下,线程 A 该如何找到正确的插入位置?
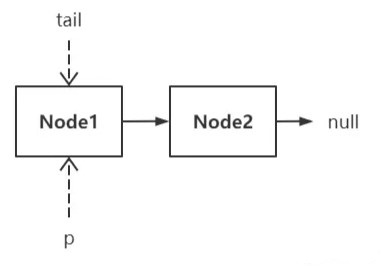
这是线程 A 进入 offer() 轮询时的场景,还没等到往下执行就被另一个线程打断了:
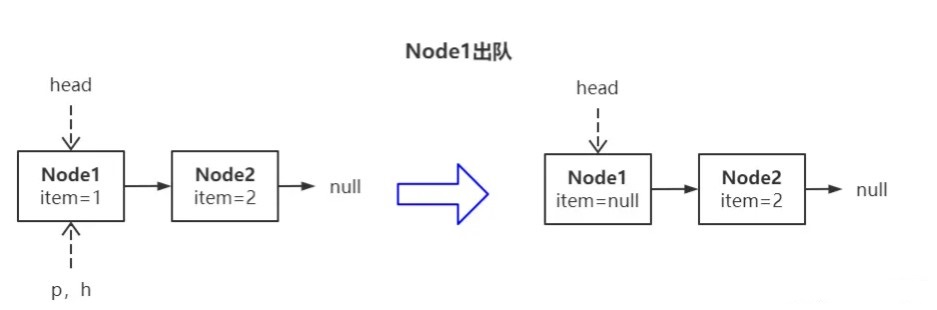
上图左侧是出队线程进入 poll() 轮询时的初始状态,待成功将 Node1 出队后就变成右图所示状态,即 Node1.item 置空,head 指针未更新。
出队线程继续将 Node2 出队会发生什么?
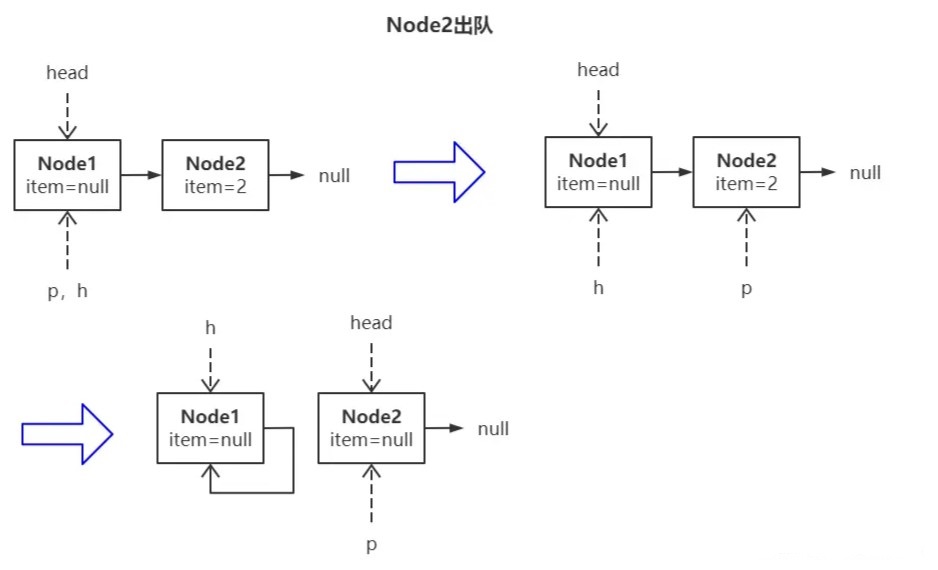
因为此时 head 结点已经滞后(状态一),所以工作指针 p 会往后找到第一个 item 非空结点 Node2(状态二),将 Node2.item 置空后,继续将 Node1 结点置为哨兵结点(状态三)。此时线程 A 恢复执行,它面对的情形如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HpJfdFzr-1659596641176)(https://upload-images.jianshu.io/upload_images/25149744-eaf449d7b05d75ed.jpg?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
因为执行 poll() 方法时并不会更新 tail 指针,导致 head 指针越过了 tail 指针。
用版本四的算法模拟一下这个场景下会发生什么:q 是 p 的后续结点,尴尬的是 p.next 就是 p 本身,所以 q 永远不会为 null,程序就一直自旋,停不下来。
解决办法是,新增一个p == q的条件分支:
// 入队版本五
public boolean offer(E e) {
Node<E> newNode = createNode(e)
for (Node t = tail, p = t;;) {
Node q = p.next;
// 找到尾结点,CAS 竞争尾插入
if (q == null) {
if (casNext(p, null, newNode)) {
if (p!=t) casTail(t, newNode);
return true;
}
}
// 若 head 越过 tail 发生自旋
else if (p == q) {
// 重置 p 到正确的位置
p = (t != (t = tail)) ? t : head;
}
// 一切正常,只是还未找到真正的尾结点
else {
p = t != (t = tail) ? t : q;
}
}
}
当发生自旋时,重置 p 到正确的位置。正确的位置有两种可能。当链尾没有插入新结点时,即 tail 没有发生变化时(t == tail),将 p 重置为 head,这就是上图阐述的场景,后续剧情如下:

当 p 意识到发生了自旋(状态一),就把自己指向 head(状态二),p 的后续结点为空,即找到了真正的链尾,遂在此插入 Node3,因为p!=t,即 tail 指针滞后了,所以同时更新 tail 指向最新的尾结点 Node3(状态3)。
自旋后还可能发生另一种场景,此时得从最新的 tail 开始遍历。
改写下头脚倒置的剧本: “链当前有 2 个结点,且 tail 指针滞后一个结点,线程 A 正准备往链尾追加新结点,但另一线程的出队操作捷足先登了,它一口气出队 2 个结点,紧接着它还进行了一次入队操作,此时线程 A 恢复执行。。。” 恢复执行的线程 A 面临这样的场景:
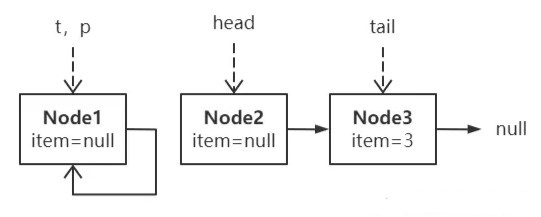
其实就是刚才剧情的续集,此时 p 发现进入了自旋,不同的是,tail 指针发生了变化,所以此时应该直接把 p 指向 tail,这比指向 head 效率要高。
阶段性总结:
非阻塞线程安全队列的入队算法总结如下:
- 总是从尾指针出发往后遍历寻找真正的尾结点(next 为空),任何情况下都能找到,将其 next 域置为新结点(CAS机制保证线程安全)。
- 滞后的尾指针:理论上每次入队都应该更新尾指针,为了提高性能,采用延迟更新策略,即两次入队对应一次更新尾指针。
- 因为是非阻塞的,出队操作可能被其他线程打断:
- 若是被另一个入队线程打断,则可能发生链尾后移若干结点,此时采用 “抄近路” 策略实现快速定位到新链尾。
- 若是被另一个出队线程打断,则可能发生头脚颠倒,即头指针越过尾指针。此时需要基于最新的头或尾指针重新出发往后遍历寻找真正的尾结点再执行入队操作。
坦白
心细的您一定发现,这其实就是ConcurrentLinkedQueue的源码~~ , 这其实是一篇源码分析~~~
我尝试以“从零开始一步步徒手复写”的方式来讲解这个算法,不知能不能降低理解难度?欢迎留言~~
总结
- 每个线程都有自己独立的内存空间(本地内存)
- 多线程能同时访问的变量称为“共享变量”,它在主存中。出于效率的考量,线程会将主存中的共享变量拷贝到本地内存,后续对共享变量的操作都发生在本地内存。
- 线程本地内存相互独立,导致它们无法感知别人对共享变量的操作,即当前线程对共享变量的操作对其他线程不可见。
- volatile 关键词是 java 解决共享变量可见性问题的方案。
- 被声明为 volatile 的变量,就是在告诉编译器该共享变量在线程本地内存中的副本是“易变的”,线程不该相信它。线程写共享变量后,总是应该立刻将最新值同步到主存中。线程读共享变量时,总是应该去主存拿最新值。
- 多线程场景下,队列的头尾指针,即结点的数据域和指针域都需要保证可见性。
CAS是一种保证共享变量线程安全的方式,它是非阻塞的,即不会造成一个线程执行,其他线程阻塞并等待唤醒。它全称为compare and swap,即“比较再交换”。当要更新变量值时,需要提供三个参数:1.当前值,2.期望值,3.新值。只有当前值和期望值相等时,才用新值替换当前值。其中期望值就是线程被打断执行时暂存的值,当线程恢复执行后,用当前值和当时暂存值比较,如果相等,则表示被打断过程中别的线程没有修改过它,那此时更新它的值是安全的。- CAS 通常配合轮询一起使用。多线程同时竞争修改一共享变量值时,只有一个会胜出(返回true),其余失败(返回false),失败线程通常选择轮询,直到成功为止。
非阻塞线程安全队列的出队算法总结如下:
- 总是从头指针出发向后寻找真正的头结点(item 非空),若找到,则将头结点 item 域置 null(CAS保证线程安全),表示结点出队,若未找到则返回 null。
- 采用 “自旋” 的方式来实现脱链(结点指针域与链脱钩),即 next 域指向自己(CAS保证线程安全)。自旋形成了哨兵的效果,使得往后遍历寻找真正头结点的过程中可感知到结点脱链。
- 滞后的头指针:“出队”、“脱链”、“更新头指针”不是配对的。理论上每次出队都应该脱链并更新头指针,为了提高性能,两次出队对应一次脱链+更新头指针,造成头结点会间歇性地滞后。
- 因为是非阻塞的,出队操作可能被其他线程打断,若是被入队打断则基本无害,因为队头队尾是两块不同的内存地址,不会有线程安全问题。若是被另一个出队线程打断,就可能发生想出的结点被其他线程抢先出队的情况。通过检测自旋+从头开始来定位到新得头结点解决。
非阻塞线程安全队列的入队算法总结如下:
- 总是从尾指针出发往后遍历寻找真正的尾结点(next 为空),任何情况下都能找到,将其 next 域置为新结点(CAS机制保证线程安全)。
- 滞后的尾指针:理论上每次入队都应该更新尾指针,为了提高性能,采用延迟更新策略,即两次入队对应一次更新尾指针。
- 因为是非阻塞的,出队操作可能被其他线程打断:
- 若是被另一个入队线程打断,则可能发生链尾后移若干结点,此时采用 “抄近路” 策略实现快速定位到新链尾。
- 若是被另一个出队线程打断,则可能发生头脚颠倒,即头指针越过尾指针。此时需要基于最新的头或尾指针重新出发往后遍历寻找真正的尾结点再执行入队操作。
作者:唐子玄
链接:https://juejin.cn/post/7079949508720721928
最后
如果想要成为架构师或想突破20~30K薪资范畴,那就不要局限在编码,业务,要会选型、扩展,提升编程思维。此外,良好的职业规划也很重要,学习的习惯很重要,但是最重要的还是要能持之以恒,任何不能坚持落实的计划都是空谈。
如果你没有方向,这里给大家分享一套由阿里高级架构师编写的《Android八大模块进阶笔记》,帮大家将杂乱、零散、碎片化的知识进行体系化的整理,让大家系统而高效地掌握Android开发的各个知识点。
相对于我们平时看的碎片化内容,这份笔记的知识点更系统化,更容易理解和记忆,是严格按照知识体系编排的。
一、架构师筑基必备技能
1、深入理解Java泛型
2、注解深入浅出
3、并发编程
4、数据传输与序列化
5、Java虚拟机原理
6、高效IO
……
二、Android百大框架源码解析
1.Retrofit 2.0源码解析
2.Okhttp3源码解析
3.ButterKnife源码解析
4.MPAndroidChart 源码解析
5.Glide源码解析
6.Leakcanary 源码解析
7.Universal-lmage-Loader源码解析
8.EventBus 3.0源码解析
9.zxing源码分析
10.Picasso源码解析
11.LottieAndroid使用详解及源码解析
12.Fresco 源码分析——图片加载流程
三、Android性能优化实战解析
- 腾讯Bugly:对字符串匹配算法的一点理解
- 爱奇艺:安卓APP崩溃捕获方案——xCrash
- 字节跳动:深入理解Gradle框架之一:Plugin, Extension, buildSrc
- 百度APP技术:Android H5首屏优化实践
- 支付宝客户端架构解析:Android 客户端启动速度优化之「垃圾回收」
- 携程:从智行 Android 项目看组件化架构实践
- 网易新闻构建优化:如何让你的构建速度“势如闪电”?
- …
四、高级kotlin强化实战
1、Kotlin入门教程
2、Kotlin 实战避坑指南
3、项目实战《Kotlin Jetpack 实战》
从一个膜拜大神的 Demo 开始
Kotlin 写 Gradle 脚本是一种什么体验?
Kotlin 编程的三重境界
Kotlin 高阶函数
Kotlin 泛型
Kotlin 扩展
Kotlin 委托
协程“不为人知”的调试技巧
图解协程:suspend
五、Android高级UI开源框架进阶解密
1.SmartRefreshLayout的使用
2.Android之PullToRefresh控件源码解析
3.Android-PullToRefresh下拉刷新库基本用法
4.LoadSir-高效易用的加载反馈页管理框架
5.Android通用LoadingView加载框架详解
6.MPAndroidChart实现LineChart(折线图)
7.hellocharts-android使用指南
8.SmartTable使用指南
9.开源项目android-uitableview介绍
10.ExcelPanel 使用指南
11.Android开源项目SlidingMenu深切解析
12.MaterialDrawer使用指南
六、NDK模块开发
1、NDK 模块开发
2、JNI 模块
3、Native 开发工具
4、Linux 编程
5、底层图片处理
6、音视频开发
7、机器学习
七、Flutter技术进阶
1、Flutter跨平台开发概述
2、Windows中Flutter开发环境搭建
3、编写你的第一个Flutter APP
4、Flutter开发环境搭建和调试
5、Dart语法篇之基础语法(一)
6、Dart语法篇之集合的使用与源码解析(二)
7、Dart语法篇之集合操作符函数与源码分析(三)
…
八、微信小程序开发
1、小程序概述及入门
2、小程序UI开发
3、API操作
4、购物商场项目实战……
全套视频资料:
一、面试合集
二、源码解析合集
三、开源框架合集

欢迎大家一键三连支持,若需要文中资料,直接点击文末CSDN官方认证微信卡片免费领取↓↓↓

边栏推荐
- 引领数字医学高地,中山医院探索打造未来医院“新范式”
- Syntax basics (variables, input and output, expressions and sequential statements)
- MRTK3开发Hololens应用-手势拖拽、旋转 、缩放物体实现
- Is your data safe in this hyperconnected world?
- [Solved] Unity Coroutine coroutine is not executed effectively
- ASP.NET application--Hello World
- Use SuperMap iDesktopX data migration tool to migrate map documents and symbols
- Countdown to 2 days|Cloud native Meetup Guangzhou Station, waiting for you!
- 21 Days Learning Challenge (2) Use of Graphical Device Trees
- 2022-08-04T17:50:58.296+0800 ERROR Announcer-3 io.airlift.discovery.client.Announcer appears after successful startup of presto
猜你喜欢
MRTK3开发Hololens应用-手势拖拽、旋转 、缩放物体实现
YYGH-13-客服中心
![[Software testing] unittest framework for automated testing](/img/80/caedd5cf6dd61c9d75475866613cac.png)
[Software testing] unittest framework for automated testing

After the large pixel panorama is completed, what are the promotion methods?

用CH341A烧录外挂Flash (W25Q16JV)
MRTK3 develops Hololens application - gesture drag, rotate, zoom object implementation
【软件测试】自动化测试之unittest框架
A small tool to transfer files using QR code - QFileTrans 1.2.0.1
结构体初解
![Tencent Cloud [Hiflow] New Era Automation Tool](/img/ac/5c61424f22cd9fed74dcd529fdb6a4.png)
Tencent Cloud [Hiflow] New Era Automation Tool
随机推荐
2022.8.4-----leetcode.1403
开发Hololens遇到The type or namespace name ‘HandMeshVertex‘ could not be found..
ffmpeg 枚举decoders, encoders 分析
How to solve the error cannot update secondary snapshot during a parallel operation when the PostgreSQL database uses navicat to open the table structure?
leetcode-每日一题1403. 非递增顺序的最小子序列(贪心)
数学-求和符号的性质
How to find all fields with empty data in sql
基于生长的棋盘格角点检测方法
You may use special comments to disable some warnings. Three ways to report errors
如何在WordPress中添加特定类别的小工具
sql server installation prompts that the username does not exist
通过模拟Vite一起深入其工作原理
Common open source databases under Linux, how many do you know?
The linear table lookup
[Software testing] unittest framework for automated testing
从“能用”到“好用” 国产软件自主可控持续推进
private封装
【滤波跟踪】基于matlab无迹卡尔曼滤波惯性导航+DVL组合导航【含Matlab源码 2019期】
2022高处安装、维护、拆除考试题模拟考试题库及在线模拟考试
Ice Scorpion V4.0 attack, security dog products can be fully detected