当前位置:网站首页>【软件测试】自动化测试之unittest框架
【软件测试】自动化测试之unittest框架
2022-08-05 02:49:00 【Money、坤】
1.什么是unittest框架
unittest 是python 的单元测试框架,它主要有以下作用:
- 提供用例组织与执行
当你的测试用例只有几条时,可以不必考虑用例的组织,但是,当测试用例达到成百上千条时,大量的测试用例堆砌在一起,就产生了扩展性与维护性等问题,此时需要考虑用例的规范与组织问题了。单元测试框架就是来解决这个问题的。 - 提供丰富的比较方法
在用例执行完之后都需要将实际结果与预期结果进行比较(断言),从而断定用例是否可以顺利通过。单元测试一般会提供丰富的断言方法。例如,判断相等/不相等、包含/不包含、True/False等断言方法。 - 提供丰富的日志
当测试用例执行失败时能抛出清晰的失败原因,当所有用例执行完成后能提供丰富的执行结果。例如,总的执行时间,失败用例数,成功用例数等
2.unittest的简单使用
下面为unittest框架的脚本:
import unittest
from selenium import webdriver
import time
# 定义一个类继承unittest.TestCase
class Baidu1(unittest.TestCase):
# 测试固件
# 环境的初始化
def setUp(self):
print("--setUp--")
# self 定义的是全局变量,否则只能在本方法内部使用
self.driver = webdriver.Chrome()
# 访问的URL
self.url = "https://www.baidu.com"
self.driver.maximize_window()
time.sleep(3)
# 测试环境的还原
def tearDown(self):
print("--tearDown--")
self.driver.quit()
# 测试用例 必须以test_开头 否则不识别,测试用例的执行顺序按照测试方法的字典序升序执行
def test_t1(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_link_text("hao123").click()
driver.implicitly_wait(3)
print(driver.title)
time.sleep(3)
# 注解:忽略测试用例的执行
@unittest.skip("skipping")
def test_t2(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_id("kw").send_keys("胡歌")
driver.find_element_by_id("su").submit()
time.sleep(3)
print(driver.title)
time.sleep(3)
def test_t3(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_id("kw").send_keys("刘浩存")
driver.find_element_by_id("su").submit()
print(driver.title)
time.sleep(3)
# 主方法 测试方法执行入口
if __name__ == "__main__":
unittest.main()
创建步骤
1.定义一个类继承unittest.TestCase;
2.初始化测试固件;
setUp() 和 setDown() 是unittest框架中的测试固件
3.编写测试用例
测试用例的方法均以 test_ 开头,以test_开头命名的方法,是测试方法,在运行整个类的时候会默认执行;
4.编写主方法
unittest提供了全局的main()方法,使用它可以方便地将一个单元测试模块变成可以直接运行的测试脚本。main()方法搜索所有包含在该模块中以”test"命名的测试方法,并自动执行他们。
3.批量执行测试脚本
在上述测试测试脚本中,我们定义了三个测试用例,我们可以依次执行多个测试用例,当我们实际开发环境中针对不同功能在多个类中写了多个测试我们又该怎么一次执行所有测试脚本呢,测试就需要用到测试套件,测试套件可以批量执行多个类中的测试用例,下面演示使用:
- 定义两个测试类
测试1
import unittest
from selenium import webdriver
import time
# 定义一个类继承unittest.TestCase
class Baidu1(unittest.TestCase):
# 测试固件
# 环境的初始化
def setUp(self):
print("--setUp--")
# self 定义的是全局变量,否则只能在本方法内部使用
self.driver = webdriver.Chrome()
# 访问的URL
self.url = "https://www.baidu.com"
self.driver.maximize_window()
time.sleep(3)
# 测试环境的还原
def tearDown(self):
print("--tearDown--")
self.driver.quit()
# 测试用例 必须以test_开头 否则不识别,测试用例的执行顺序按照测试方法的字典序升序执行
def test_t1(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_link_text("hao123").click()
driver.implicitly_wait(3)
print(driver.title)
time.sleep(3)
# 注解:忽略测试用例的执行
@unittest.skip("skipping")
def test_t2(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_id("kw").send_keys("胡歌")
driver.find_element_by_id("su").submit()
time.sleep(3)
print(driver.title)
time.sleep(3)
def test_t3(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_id("kw").send_keys("刘浩存")
driver.find_element_by_id("su").submit()
print(driver.title)
time.sleep(3)
# 主方法 测试方法执行入口
if __name__ == "__main__":
unittest.main()
测试2
import unittest
from selenium import webdriver
import time
# 博客浏览的自动化测试
class Baidu2(unittest.TestCase):
# 测试固件
def setUp(self):
print("--setUp--")
self.driver = webdriver.Chrome()
self.url = "https://blog.csdn.net/qq_57549633"
self.driver.maximize_window()
time.sleep(3)
# 测试环境的还原
def tearDown(self):
print("--tearDown--")
self.driver.quit()
# 测试用例 必须以test_开头 否则不识别
def test_t1(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_xpath("//*[@id='userSkin']/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1]/article/a/div[1]/h4").click()
driver.back()
time.sleep(3)
def test_t2(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_xpath("//*[@id='userSkin']/div[2]/div/div[2]/div[1]/div[2]/div/div/div[7]/article/a/div[1]").click()
driver.back()
time.sleep(3)
print(driver.title)
time.sleep(3)
def test_t3(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_xpath("//*[@id='userSkin']/div[2]/div/div[2]/div[1]/div[2]/div/div/div[13]/article/a/div[1]/h4").click()
driver.back()
print(driver.title)
time.sleep(3)
# 主方法
if __name__ == "__main__":
unittest.main()
- addTest()方法
TestSuite类的addTest()方法可以把不同的测试类中的测试方法组装到测试套件中,但是addTest()一次只能把一个类里面的一个测试方法组装到测试套件中。方式如下:
将testbaidu1.py、testbaidu2.py中的测试方法放到一个测试套件中,在testsuite.py中实现。
import unittest
import TestBaidu1
import TestBaidu2
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("https://www.baidu.com")
# 组织测试套件方法
def creatSuit():
# 1.把不同的测试脚本的类中的需要执行的测试方法放在一个测试套件中
suit=unittest.TestSuite()
suit.addTest(TestBaidu1.Baidu1("test_t1"))
suit.addTest(TestBaidu1.Baidu1("test_t2"))
suit.addTest(TestBaidu2.Baidu2("test_t3"))
return suit
# 主方法加载套件
if __name__=="__main__":
suite = creatSuit()
# verbosity 日志显示级别,分为 0 1 2
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suite)
- makeSuite()和TestLoader()的应用
在unittest 框架中提供了makeSuite() 的方法,makeSuite可以实现把测试用例类内所有的测试case组成的测试套件TestSuite ,unittest 调用makeSuite的时候,只需要把测试类名称传入即可。
TestLoader 用于创建类和模块的测试套件,一般的情况下,使TestLoader().loadTestsFromTestCase(TestClass) 来加载测试类。
import unittest
import TestBaidu1
import TestBaidu2
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("https://www.baidu.com")
# 组织测试套件方法
def creatSuit():
# 2.将一个测试脚本中的类中的所有方法都添加到套件中
suit=unittest.TestSuite()
suit.addTest(unittest.makeSuite(TestBaidu1.Baidu1))
suit.addTest(unittest.makeSuite(TestBaidu2.Baidu2))
# suite1 = unittest.TestLoader().loadTestsFromTestCase(testbaidu1.Baidu1)
# suite2 = unittest.TestLoader().loadTestsFromTestCase(testbaidu2.Baidu2)
# suite = unittest.TestSuite([suite1, suite2])
return suite
# 主方法加载套件
if __name__=="__main__":
suite = creatSuit()
# verbosity 日志显示级别,分为 0 1 2
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suite)
- discover()的应用
discover 是通过递归的方式到其子目录中从指定的目录开始, 找到所有测试模块并返回一个包含它们对象的TestSuite ,然后进行加载与模式匹配唯一的测试文件,discover 参数分别discover(dir,pattern,top_level_dir=None)
import unittest
import TestBaidu1
import TestBaidu2
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("https://www.baidu.com")
# 组织测试套件方法
def creatSuit():
# 3.将整个文件夹下所有的测试脚本的测试用例都添加到套件中
discover=unittest.defaultTestLoader.discover("../Test", pattern="TestBaidu*.py", top_level_dir=None)
return discover
# 主方法加载套件
if __name__=="__main__":
suite = creatSuit()
# verbosity 日志显示级别,分为 0 1 2
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suite)
用例的执行顺序:unittest 框架默认加载测试用例的顺序是根据ASCII 码的顺序,数字与字母的顺序为: 09,AZ,a~z 。
所以, TestAdd 类会优先于TestBdd 类被发现, test_aaa() 方法会优先于test_ccc() 被执行。对于测试
目录与测试文件来说, unittest 框架同样是按照这个规则来加载测试用例。
4.unittest断言
自动化的测试中, 对于每个单独的case来说,一个case的执行结果中, 必然会有期望结果与实际结果, 来判断该case是通过还是失败, 在unittest 的库中提供了大量的实用方法来检查预期值与实际
值, 来验证case的结果。
下面是一些常用的断言: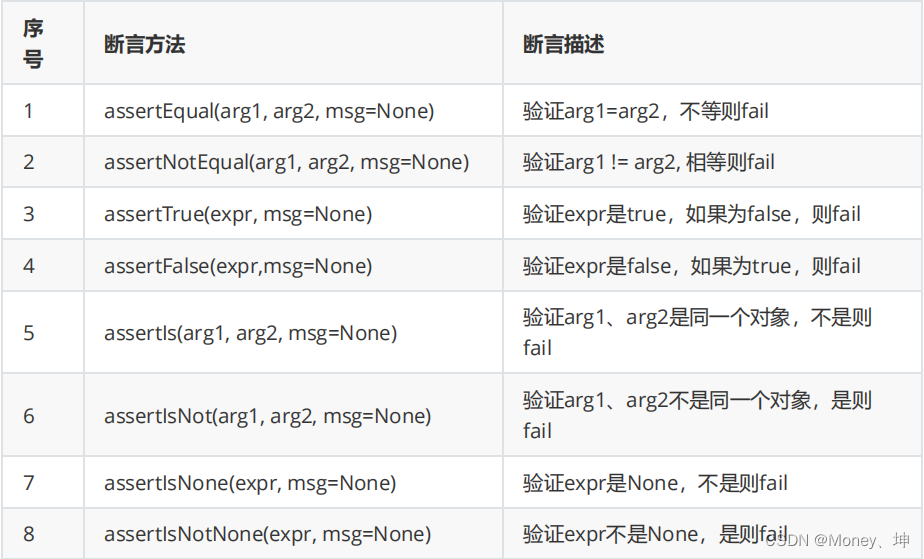
代码演示:
import time
from selenium import webdriver
import unittest
# 定义一个类继承unittest.TestCase
class Test(unittest.TestCase):
# 测试固件
# 环境的初始化
def setUp(self):
print("--setUp--")
# self 定义的是全局变量,否则只能在本方法内部使用
self.driver = webdriver.Chrome()
self.url = "https://www.baidu.com"
self.driver.maximize_window()
time.sleep(3)
# 测试环境的还原
def tearDown(self):
print("--tearDown--")
self.driver.quit()
# 测试用例
def test_t1(self):
driver=self.driver
url=self.url
driver.get(url)
time.sleep(3)
driver.find_element_by_id("kw").send_keys("胡歌")
driver.find_element_by_id("su").click()
driver.implicitly_wait(5)
print(driver.title)
# self.assertEqual("胡歌_百度搜索", driver.title, msg="未打开网页")
self.assertTrue("百度一下,你就知道" == driver.title, msg="内容不相等")
time.sleep(5)
driver.quit()
5.HTML报告生成
脚本执行完毕之后,还需要看到HTML报告,下面我们就通过HTMLTestRunner.py 来生成测试报告。
HTMLTestRunner支持python2.7。python3可以参见http://blog.51cto.com/hzqldjb/1590802来进行修改。
HTMLTestRunner.py 文件,下载地址: http://tungwaiyip.info/software/HTMLTestRunner.html
下载后将其放在testcase目录中去或者放入…\Python27\Lib 目录下(windows)。
import HTMLTestRunner
import sys
import unittest
from selenium import webdriver
import os
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 组织测试套件的方法
def creatSuit():
# Test目录下所有的测试用例
discover=unittest.defaultTestLoader.discover("../Test", pattern="Test*.py", top_level_dir=None)
return discover
if __name__ == "__main__":
# 当前路径、 等同于./
curpath = sys.path[0]
# 取当前时间
now = time.strftime("%Y-%m-%d-%H %M %S", time.localtime(time.time()))
if not os.path.exists(curpath + '/resultreport'):
os.makedirs(curpath + '/resultreport')
# 文件名
filename = curpath + '/resultreport/' + now + 'resultreport.html'
with open(filename, 'wb') as fp:
# 出html报告
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u'测试报告',description=u'用例执行情况',verbosity=2)
suite = creatSuit()
runner.run(suite)
在resultreport目录下生成的测试报告:
测试报告中会详细展示用例的执行情况(我这里测试用例全部通过):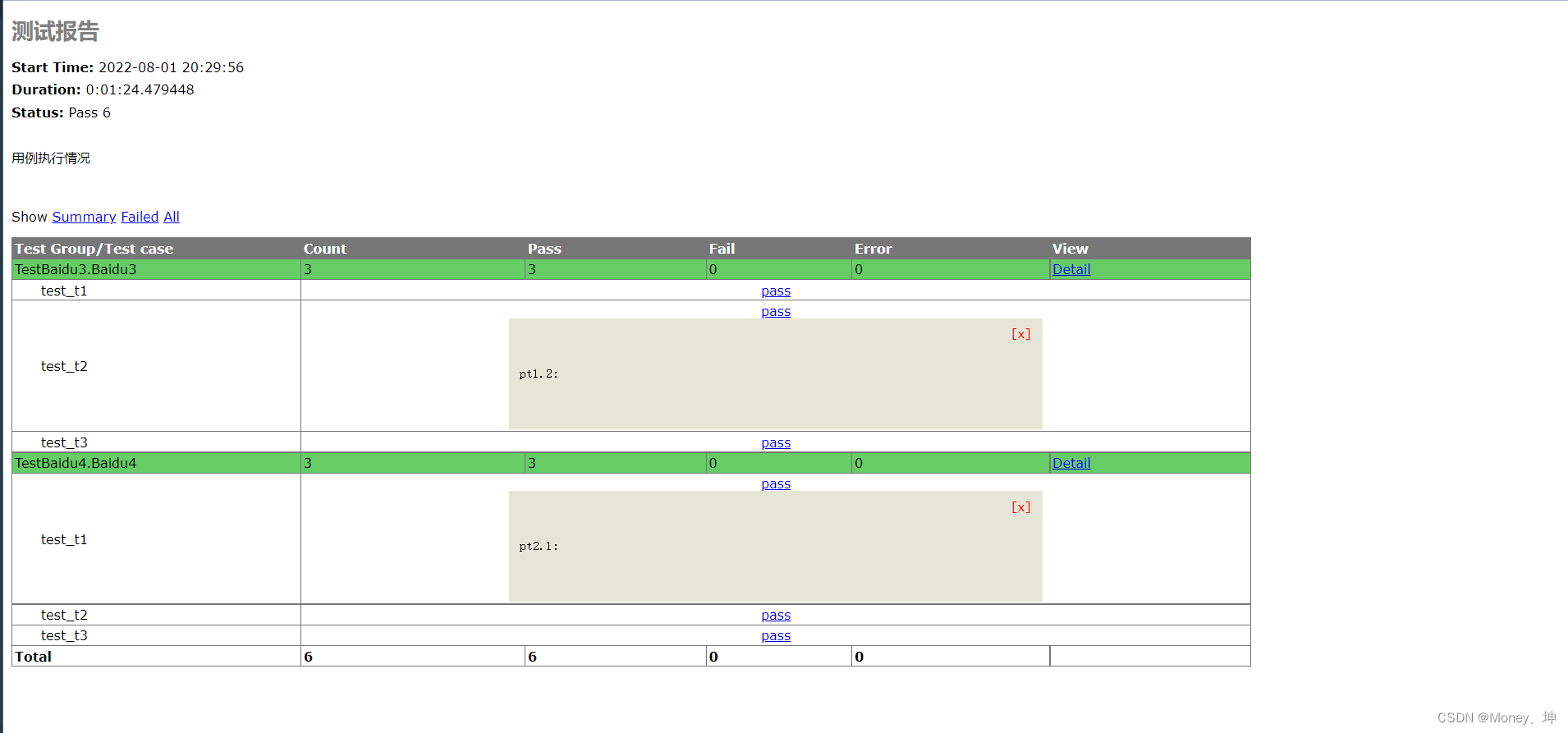
5.异常捕捉与错误截图
用例不可能每一次运行都成功,肯定运行时候有不成功的时候。如果可以捕捉到错误,并且把错误截图保存,这将是一个非常棒的功能,也会给我们错误定位带来方便。
import time
import os
from selenium import webdriver
import unittest
# 定义一个类继承unittest.TestCase
class Test(unittest.TestCase):
# 测试固件
# 环境的初始化
def setUp(self):
print("--setUp--")
# self 定义的是全局变量,否则只能在本方法内部使用
self.driver = webdriver.Chrome()
self.url = "https://www.baidu.com"
self.driver.maximize_window()
time.sleep(3)
# 测试环境的还原
def tearDown(self):
print("--tearDown--")
self.driver.quit()
# 测试用例
def test_t1(self):
driver = self.driver
url = self.url
driver.get(url)
time.sleep(3)
driver.find_element_by_id("kw").send_keys("胡歌")
driver.find_element_by_id("su").click()
driver.implicitly_wait(5)
print(driver.title)
try:
self.assertNotEqual(driver.title, "百度一下,你就知道", msg="内容不一致")
except:
self.sasavescreenshot(driver, "except.png")
time.sleep(5)
# 保存错误截图
def savescreenshot(self, driver, file_name):
if not os.path.exists('./image'):
os.makedirs('./image')
now = time.strftime("%Y%m%d-%H%M%S", time.localtime(time.time()))
# 截图保存
driver.get_screenshot_as_file('./image/' + now + '-' + file_name)
time.sleep(3)
# 主方法
if __name__ == "__main__":
unittest.main()
边栏推荐
- QT语言文件制作
- [LeetCode Brush Questions] - Sum of Numbers topic (more topics to be added)
- 数据增强Mixup原理与代码解读
- Note that Weifang generally needs to pay attention to issuing invoices
- 腾讯云【Hiflow】新时代自动化工具
- post-study program
- [Decryption] Can the NFTs created by OpenSea for free appear in my wallet without being chained?
- ARM Mailbox
- [In-depth study of 4G/5G/6G topic-51]: URLLC-16-"3GPP URLLC related protocols, specifications, and technical principles in-depth interpretation"-11-High reliability technology-2-Link adaptive enhancem
- Study Notes-----Left-biased Tree
猜你喜欢

Countdown to 2 days|Cloud native Meetup Guangzhou Station, waiting for you!
数据增强Mixup原理与代码解读

Is your data safe in this hyperconnected world?
RAID disk array

How to sort multiple fields and multiple values in sql statement
Principle and Technology of Virtual Memory
The linear table lookup

正则表达式,匹配中间的某一段字符串
![[Decryption] Can the NFTs created by OpenSea for free appear in my wallet without being chained?](/img/81/2dcb61fd6c30f726804c73cf2b3384.jpg)
[Decryption] Can the NFTs created by OpenSea for free appear in my wallet without being chained?
Regular expression to match a certain string in the middle
随机推荐
语法基础(变量、输入输出、表达式与顺序语句)
QT: The Magical QVarient
One hundred - day plan -- -- DAY2 brush
dmp (dump) dump file
LeetCode uses the minimum cost to climb the stairs----dp problem
Question about #sql shell#, how to solve it?
Introduction to SDC
Simple description of linked list and simple implementation of code
Common hardware delays
The Tanabata copywriting you want has been sorted out for you!
【 2 】 OpenCV image processing: basic knowledge of OpenCV
Cloud Native (32) | Introduction to Platform Storage System in Kubernetes
【 genius_platform software platform development 】 : seventy-six vs the preprocessor definitions written cow force!!!!!!!!!!(in the other groups conding personnel told so cow force configuration to can
数据增强Mixup原理与代码解读
Principle and Technology of Virtual Memory
shell语句修改txt文件或者sh文件
Images using redis cache Linux master-slave synchronization server hard drive full of moved to the new directory which points to be modified
sql server installation prompts that the username does not exist
QT语言文件制作
mysql没法Execute 大拿们求解