当前位置:网站首页>数据增强Mixup原理与代码解读
数据增强Mixup原理与代码解读
2022-08-05 02:32:00 【00000cj】
paper:mixup: Beyond Empirical Risk Minimization
存在的问题
- 经验风险最小化(Empirical Risk Minimization, ERM)允许大型神经网络强行记住训练数据(而不是去学习、泛化),即使加了很强的正则化,或是在随机分配标签的分类问题中,这个问题也依然存在。
- 使用ERM原则训练的神经网络,当在训练样本分布之外的数据上进行评估时,预测结果会发生显著的变化,这被称为对抗性样本。
解决这个问题的一个方法是邻域风险最小化(Vicinal Risk Minimization, VRM),即通过数据增强在原始样本的基础上构造更多的样本,但数据增强中需要人类知识来描述训练数据中每个样本的邻域,比如翻转、缩放等。因此VRM也有两点不足
- 数据增强过程依赖数据集,因此需要专家知识
- 数据增强只建模同一类别之间的邻域关系
Mix-up
针对上述问题,本文提出一种data-agnostic的数据增强方法mixup,
![]()
其中\(x_{i},x_{j}\)是从训练集中随机挑选的两张图像,\(y_{i},y_{j}\)是对应的one-hot标签,通过先验知识:特征向量的线性插值和对应目标的线性插值还是对应的关系,构造了新的样本\((\widetilde{x},\widetilde{y})\)。其中\(\lambda\)通过\(\beta(\alpha, \alpha)\)分布获得,\(\alpha\)是超参。
此外,作者提到了一些通过实验得到的结论
- 通过实验发现三个或三个以上样本的组合不能带来进一步的精度提升,反而会增加计算成本。
- 作者的实现方法是通过一个单独的data loader获得一个batch的数据,然后在random shuffle后对这一个batch内的数据使用mixup,作者发现这种策略的效果很好,同时减少了I/O。
- 只对相同类别的样本进行mixup并不会带来精度的提升。
实现
torchvision版本
这里通过roll方法将batch内的图片向后平移一个,然后与原batch进行mixup,相当于batch内的每张图片都和相邻的一张进行mixup,roll方法详见
class RandomMixup(torch.nn.Module):
"""Randomly apply Mixup to the provided batch and targets.
The class implements the data augmentations as described in the paper
`"mixup: Beyond Empirical Risk Minimization" <https://arxiv.org/abs/1710.09412>`_.
Args:
num_classes (int): number of classes used for one-hot encoding.
p (float): probability of the batch being transformed. Default value is 0.5.
alpha (float): hyperparameter of the Beta distribution used for mixup.
Default value is 1.0.
inplace (bool): boolean to make this transform inplace. Default set to False.
"""
def __init__(self, num_classes: int, p: float = 0.5, alpha: float = 1.0, inplace: bool = False) -> None:
super().__init__()
if num_classes < 1:
raise ValueError(
f"Please provide a valid positive value for the num_classes. Got num_classes={num_classes}"
)
if alpha <= 0:
raise ValueError("Alpha param can't be zero.")
self.num_classes = num_classes
self.p = p
self.alpha = alpha
self.inplace = inplace
def forward(self, batch: Tensor, target: Tensor) -> Tuple[Tensor, Tensor]:
"""
Args:
batch (Tensor): Float tensor of size (B, C, H, W)
target (Tensor): Integer tensor of size (B, )
Returns:
Tensor: Randomly transformed batch.
"""
if batch.ndim != 4:
raise ValueError(f"Batch ndim should be 4. Got {batch.ndim}")
if target.ndim != 1:
raise ValueError(f"Target ndim should be 1. Got {target.ndim}")
if not batch.is_floating_point():
raise TypeError(f"Batch dtype should be a float tensor. Got {batch.dtype}.")
if target.dtype != torch.int64:
raise TypeError(f"Target dtype should be torch.int64. Got {target.dtype}")
if not self.inplace:
batch = batch.clone()
target = target.clone()
if target.ndim == 1:
target = torch.nn.functional.one_hot(target, num_classes=self.num_classes).to(dtype=batch.dtype)
if torch.rand(1).item() >= self.p:
return batch, target
# It's faster to roll the batch by one instead of shuffling it to create image pairs
batch_rolled = batch.roll(1, 0)
target_rolled = target.roll(1, 0)
# Implemented as on mixup paper, page 3.
lambda_param = float(torch._sample_dirichlet(torch.tensor([self.alpha, self.alpha]))[0])
batch_rolled.mul_(1.0 - lambda_param)
batch.mul_(lambda_param).add_(batch_rolled)
target_rolled.mul_(1.0 - lambda_param)
target.mul_(lambda_param).add_(target_rolled)
return batch, target
def __repr__(self) -> str:
s = (
f"{self.__class__.__name__}("
f"num_classes={self.num_classes}"
f", p={self.p}"
f", alpha={self.alpha}"
f", inplace={self.inplace}"
f")"
)
return smmclassification版本
这里是通过randperm将batch内的图片打乱,然后与原batch进行mixup,并且得到\(\lambda\)的方法与torchvision也不一样。
class BatchMixupLayer(BaseMixupLayer):
r"""Mixup layer for a batch of data.
Mixup is a method to reduces the memorization of corrupt labels and
increases the robustness to adversarial examples. It's
proposed in `mixup: Beyond Empirical Risk Minimization
<https://arxiv.org/abs/1710.09412>`
This method simply linearly mix pairs of data and their labels.
Args:
alpha (float): Parameters for Beta distribution to generate the
mixing ratio. It should be a positive number. More details
are in the note.
num_classes (int): The number of classes.
prob (float): The probability to execute mixup. It should be in
range [0, 1]. Default sto 1.0.
Note:
The :math:`\alpha` (``alpha``) determines a random distribution
:math:`Beta(\alpha, \alpha)`. For each batch of data, we sample
a mixing ratio (marked as :math:`\lambda`, ``lam``) from the random
distribution.
"""
def __init__(self, *args, **kwargs):
super(BatchMixupLayer, self).__init__(*args, **kwargs)
def mixup(self, img, gt_label):
one_hot_gt_label = one_hot_encoding(gt_label, self.num_classes)
lam = np.random.beta(self.alpha, self.alpha)
batch_size = img.size(0)
index = torch.randperm(batch_size)
mixed_img = lam * img + (1 - lam) * img[index, :]
mixed_gt_label = lam * one_hot_gt_label + (
1 - lam) * one_hot_gt_label[index, :]
return mixed_img, mixed_gt_label
def __call__(self, img, gt_label):
return self.mixup(img, gt_label)目标检测中的mixup
在文章Bag of Freebies for Training Object Detection Neural Networks 中,对两张图片mixup后只是合并了两张图中的所有gt box,并没有对类别标签进行mixup。但文章提到"weighted loss indicates the overall loss is the summation of multiple objects with ratio 0 to 1 according to image blending ratio they belong to in the original training images",即在计算loss时对每个物体的loss按mixup时的系数进行加权求和。

参考
边栏推荐
- 海量服务实例动态化管理
- 如何模拟后台API调用场景,很细!
- 程序员的七夕浪漫时刻
- Quickly learn chess from zero to one
- Amazon Cloud Technology joins hands with Thundersoft to build an AIoT platform for industry customers
- Access Characteristics of Constructor under Inheritance Relationship
- Using OpenVINO to implement the flying paddle version of the PGNet inference program
- Common hardware delays
- Understand the recommendation system in one article: Recall 06: Two-tower model - model structure, training method, the recall model is a late fusion feature, and the sorting model is an early fusion
- Fragment visibility judgment
猜你喜欢
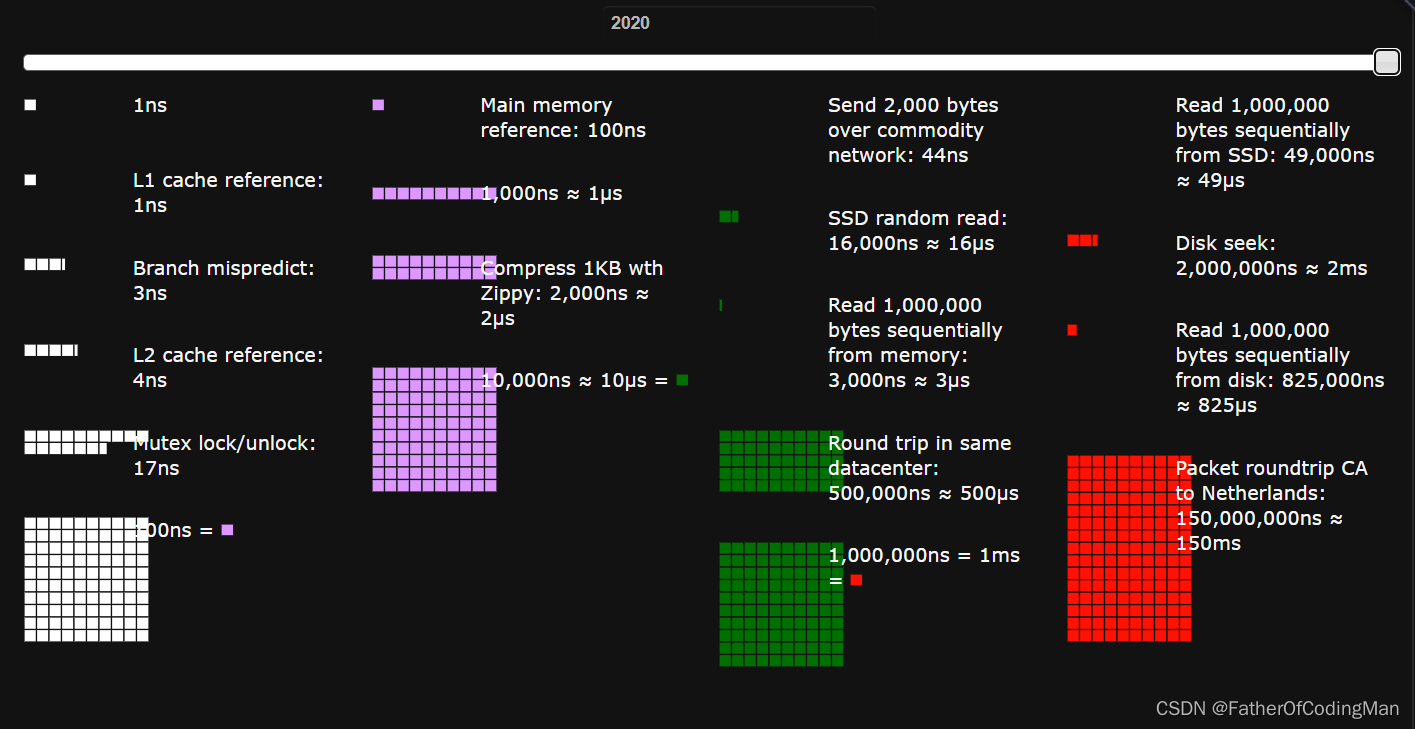
Common hardware delays
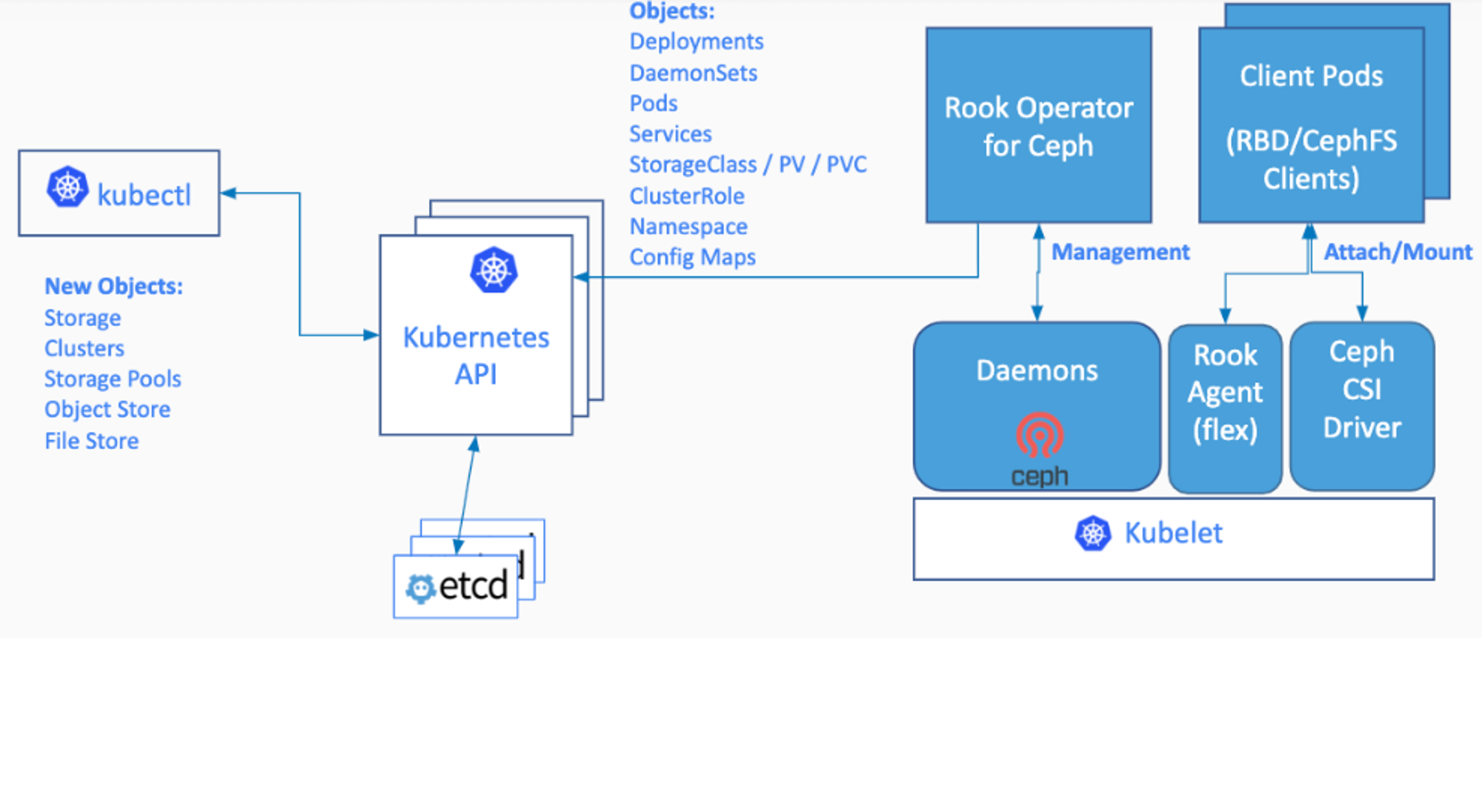
云原生(三十二) | Kubernetes篇之平台存储系统介绍
.Net C# 控制台 使用 Win32 API 创建一个窗口
.Net C# Console Create a window using Win32 API
01 【前言 基础使用 核心概念】
![[Decryption] Can the NFTs created by OpenSea for free appear in my wallet without being chained?](/img/81/2dcb61fd6c30f726804c73cf2b3384.jpg)
[Decryption] Can the NFTs created by OpenSea for free appear in my wallet without being chained?
C language implements a simple number guessing game

sql语句多字段多个值如何进行排序
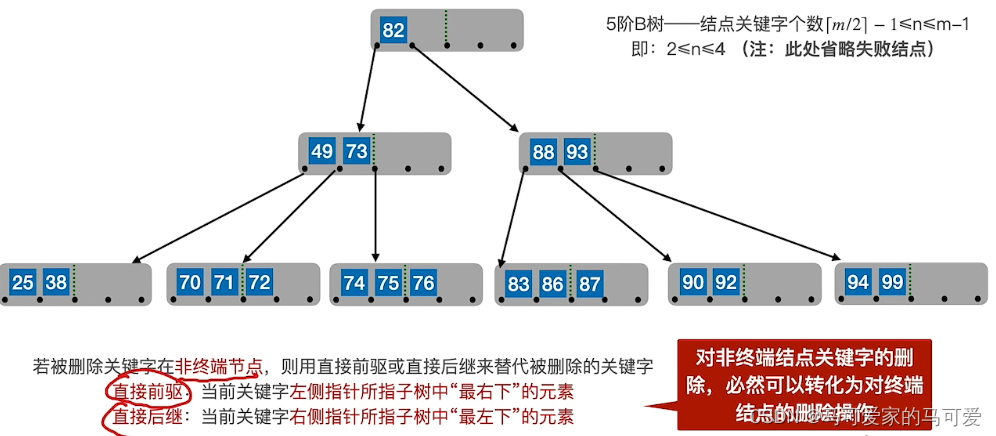
树表的查找
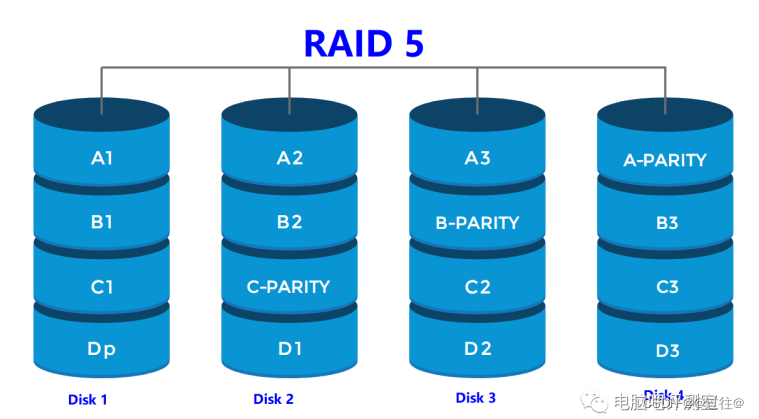
RAID磁盘阵列
随机推荐
[机缘参悟-60]:《兵者,诡道也》-2-孙子兵法解读
[ROS] (10) ROS Communication - Service Communication
DAY22: sqli-labs shooting range clearance wp (Less01~~Less20)
Solve connect: The requested address is not valid in its context
Live preview | 30 minutes started quickly!Look at credible distributed AI chain oar architectural design
C语言实现简单猜数字游戏
leetcode 15
leetcode-另一棵树的子树
LeetCode使用最小花费爬楼梯----dp问题
浅谈数据安全治理与隐私计算
基于左序遍历的数据存储实践
亚马逊云科技 + 英特尔 + 中科创达为行业客户构建 AIoT 平台
Access Characteristics of Constructor under Inheritance Relationship
Unleashing the engine of technological innovation, Intel joins hands with ecological partners to promote the vigorous development of smart retail
ARM Mailbox
js中try...catch和finally的用法
程序员失眠时的数羊列表 | 每日趣闻
解决connect: The requested address is not valid in its context
如何基于OpenVINO POT工具简单实现对模型的量化压缩
线上MySQL的自增id用尽怎么办?