当前位置:网站首页>Concurrent programming
Concurrent programming
2022-06-11 09:18:00 【lwj_ 07】
Concurrent programming :
Most concurrent programming theories The actual code is simple
Review of essential knowledge points :
● Computers are also called computers , It's an electrified brain , The computer was invented so that he could work like a man when he was powered on , And it is more efficient than people , Because it can 24 Hours uninterrupted
● Five components of computer
controller
Arithmetic unit
Memory
input device
Output devices
What really works at the heart of the computer is CPU( controller + Arithmetic unit = a central processor )
● If a program wants to be run by a computer , Its code must be read from the hard disk to the memory , after cpu Take the index and execute
Early computers :

Early treatment cpu Utilization method :

upgrade :

Multichannel technology :
Concurrent : What looks like simultaneous execution is called concurrency
parallel : Real simultaneous execution
ps:
1、 Parallelism is definitely concurrency
2、 Single core computers certainly can't achieve parallelism , But concurrency can be achieved !!
Add : We directly assume that a single core is a core , Work alone , Don't think about cpu How many cores are there
Illustration of multichannel technology : ( It saves the total time of running multiple programs )

Key knowledge of multi-channel technology :
1、 Reuse in space
Multiple programs share a set of computer hardware ( such as qq WeChat Share one of my computers )
2、 Time reuse
for example : Wash the clothes 30s , Cooking 50s, Boil water 30s
Single channel technology : Wait for the clothes to be washed before cooking and then boiling
Multichannel technology : Wash clothes and boil water while cooking ( Just complete the most time-consuming tasks )
Switch + Save state :
Switch (cpu) There are two cases :
1、 When a program encounters IO In operation , The operating system will strip the program of CPU Executive authority ( such as qq occupy CPU Then I ordered wechat , Then the operating system will put qq Of CPU Take it back for wechat programs to use , in other words qq It's not shit to occupy the manger )
effect : Improved CPU Utilization ratio , And it does not affect the execution efficiency of the program
2、 When a program takes up for a long time CPU When , The operating system will also deprive the program of CPU Executive authority
effect : Reduce the efficiency of the program reason :( Original time + Switching time + Time to run the program again )
Process theory : ( process == Program )
Essential knowledge :
The difference between procedure and process :
A program is a pile of code lying on the hard disk , yes ‘’ die ‘’ Of
Process represents the process that the program is executing , It's alive. .
Process scheduling :
1、 First come first serve scheduling algorithm
Good for long work , It's not good for short homework
2、 Short job priority scheduling algorithm
It's good for short work , It's not good for long work
3、 Time slice rotation + Multistage feedback queue

Three state diagram of process operation :

Be careful : In the blocking state, if the program stays idle that cpu It will be taken away and used by other programs , The program in the block needs to enter the ready state again and wait for the newly allocated cpu
Demonstrate with code :

Two pairs of important concepts :
1 Synchronous and asynchronous
''' Describes how the task is submitted '''
Sync : After the task is submitted , Wait in place for the return result of the task , Don't do anything while waiting ( To wait )
The feeling at the program level is stuck
asynchronous : After the task is submitted , Don't wait in place for the return result of the task , Just do something else
problem : How to obtain the task results I submitted ?
The returned result of the task will be automatically processed by an asynchronous callback mechanism
2 Blocking non blocking : ( Blocking : For example, we don't input information when we open Baidu We will always stay on the front page of Baidu )
''' Describe the running state of the program '''
Blocking : Blocking state
Non blocking : The ready state + Running state
Ideal state : We should always have our code switch between ready and running
A combination of the above concepts : The most efficient combination is Asynchronous non-blocking
Synchronized code demo :
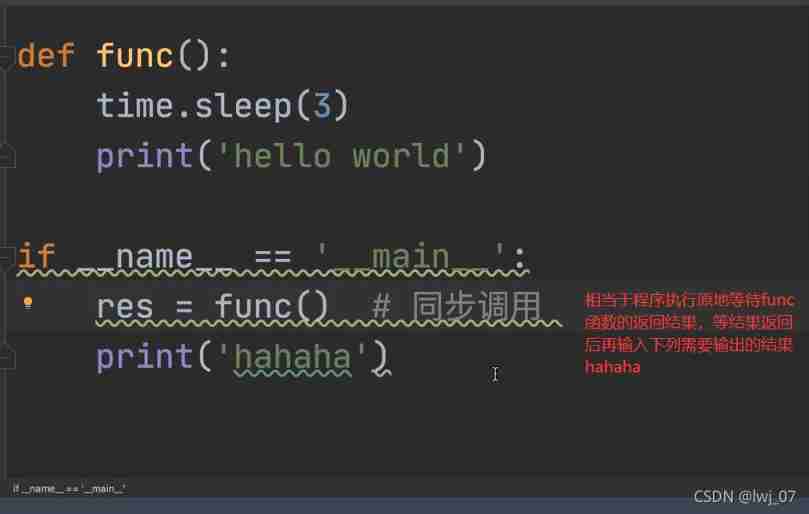
Two ways to start a process :
# The first one is ( Commonly used )
from multiprocessing import Process # Process Is a class
import time
def task(name):
print('%s is running' % name)
time.sleep(3)
print('%s is over' % name)
if __name__ == '__main__':
# 1 Create an object
res = Process(target=task, args=('juson',))
# Be careful : Container type ( Tuples ) Even if there is only 1 Elements Also use commas to separate
# 2 Open thread
res.start() # Tell the operating system to help you create a process asynchronous ( After the task is submitted, the following... Is run directly without waiting for the results x)
print(' Lord ')
'''
windows Under the operating system The creation process must be in main Internal creation ( Prevent a dead cycle )
because windows Creating a process under is similar to the module import method. The code will be executed from top to bottom and the process will be executed again 1,2,3...( Prevent a dead cycle )
linux In the system, the code is copied directly
'''
# The second way : Class inheritance
from multiprocessing import Process
import time
class MyProcess(Process):
def run(self): # Must be run
print('hello bf girl')
time.sleep(1)
print('get out')
if __name__ == '__main__':
# Create an object
res = MyProcess()
res.start()
print(' Lord ')
The order of printing results is as follows : ( Print the master first Re print run The results inside )


summary :
'''The process created is to apply for a piece of memory space in the memory, and the code needs to be thrown in
A process corresponds to an independent memory space in memory
Multiple processes correspond to multiple independent memory spaces in memory
By default, data between processes cannot interact directly , If you want to interact, you can use third-party tools , modular
'''
join Method
How can I print out the main post ?(join Waiting for the p1 Result And then print it ' Lord ' Mission )
from multiprocessing import Process
import time
def task(name):
print('%s is running' % name)
time.sleep(3)
print('%s is over' % name)
if __name__ == '__main__':
p1 = Process(target=task, args=('liu',))
p1.start()
p1.join() # The main process waits for the child process p After the result of the run, continue to execute
print(' Lord ')
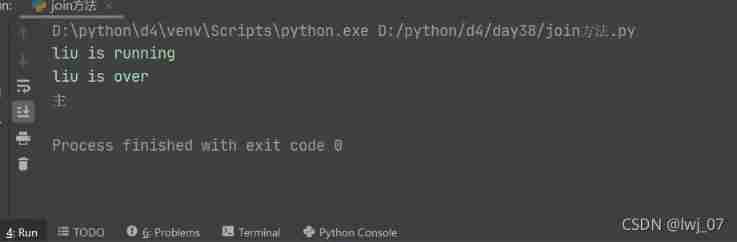
=========================================================================
If the order is different ( Normal phenomenon )
from multiprocessing import Process
import time
def task(name):
print('%s is running' % name)
time.sleep(3)
print('%s is over' % name)
if __name__ == '__main__':
p1 = Process(target=task, args=('liu',))
p2 = Process(target=task, args=('wen',))
p3 = Process(target=task, args=('jun',))
p1.start() # These three codes just tell the operating system to help you create three processes but p1 p2 p3 The sequential operating system does not help you plan the sequence
p2.start() # So sometimes there is a confusion of order
p3.start()
# p1.join()
print(' Lord ')
from multiprocessing import Process
import time
def task(name,n):
print('%s is running' % name)
time.sleep(n)
print('%s is over' % name)
if __name__ == '__main__':
p1 = Process(target=task, args=('liu', 1))
p2 = Process(target=task, args=('wen', 2))
p3 = Process(target=task, args=('jun', 3))
start_time = time.time()
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
print(' Lord ',time.time() - start_time) # The time result is 3s about because p1 p2 p3 Three programs run at the same time Waiting for p1 When p2 p3 Also already
# perform 1s 了 Until the execution of p3 It has been executed by 2s 了 p3 Just wait 1s That's it

for Loop implements concurrent methods :
from multiprocessing import Process
import time
def task(name,i):
print('%s is running' % name)
time.sleep(i)
print('%s is over' % name)
if __name__ == '__main__':
start_time = time.time()
for i in range(1, 4): # Head and tail
p = Process(target=task, args=(' Subprocesses %s' %i ,i))
p.start()
p.join() # because for loop all join Can only wait 1 Wait until the task is over 2 Wait until the task is over 3 Mission So the efficiency will decrease obviously ( Obviously, concurrency is rewritten to serial )
print(' Lord ', time.time() - start_time) 
resolvent :
from multiprocessing import Process
import time
def task(name,i):
print('%s is running' % name)
time.sleep(i)
print('%s is over' % name)
if __name__ == '__main__':
start_time = time.time()
p_list = []
for i in range(1, 4): # Head and tail
p = Process(target=task, args=(' Subprocesses %s' %i ,i))
p.start()
p_list.append(p) # Put the three process objects together first
for p in p_list: # Then take out the process object and join The execution time is about the same as that of the longest process
p.join()
print(' Lord ', time.time() - start_time)
边栏推荐
- 【软件】大企业ERP选型的方法
- Remote office related issues to be considered by enterprises
- 1400. 构造 K 个回文字符串
- Typescript high level feature 1 - merge type (&)
- 1493. the longest subarray with all 1 after deleting an element
- Award winning survey streamnational sponsored 2022 Apache pulsar user questionnaire
- Complexity analysis of matrix inversion operation (complexity analysis of inverse matrix)
- Some learning records I=
- openstack详解(二十一)——Neutron组件安装与配置
- 报错device = depthai.Device(““, False) TypeError: _init_(): incompatible constructor arguments.
猜你喜欢

山东大学项目实训(四)—— 微信小程序扫描web端二维码实现web端登录

Talk about reading the source code
![报错[DetectionNetwork(1)][warning]Network compiled for 6 shaves,maximum available 10,compiling for 5 s](/img/54/f42146ae649836fe7070ac90f2160e.png)
报错[DetectionNetwork(1)][warning]Network compiled for 6 shaves,maximum available 10,compiling for 5 s
![[C language - function stack frame] analyze the whole process of function call from the perspective of disassembly](/img/c5/40ea5571f187e525b2310812ff2af8.png)
[C language - function stack frame] analyze the whole process of function call from the perspective of disassembly

矩阵求逆操作的复杂度分析(逆矩阵的复杂度分析)

报错Output image is bigger(1228800B) than maximum frame size specified in properties(1048576B)

【ROS】noedic-moveit安装与UR5模型导入

ArcGIS 10.9.1 geological and meteorological volume metadata processing and service publishing and calling

Opencv CEO teaches you to use oak (V): anti deception face recognition system based on oak-d and depthai

PD chip ga670-10 for OTG while charging
随机推荐
[C language - data storage] how is data stored in memory?
Design of wrist sphygmomanometer based on sic32f911ret6
Question d'entrevue 02.02. Renvoie l'avant - dernier noeud K
[scheme development] scheme of infrared thermometer
ArcGIS 10.9.1 geological and meteorological volume metadata processing and service publishing and calling
2161. 根据给定数字划分数组
Type-C蓝牙音箱单口可充可OTG方案
Shandong University project training (IV) -- wechat applet scans web QR code to realize web login
Openstack explanation (XXIII) -- other configurations, database initialization and service startup of neutron
Device = depthai Device(““, False) TypeError: _init_(): incompatible constructor arguments.
Exclusive interview with PMC member Liu Yu: female leadership in Apache pulsar community
Award winning survey streamnational sponsored 2022 Apache pulsar user questionnaire
Complexity analysis of matrix inversion operation (complexity analysis of inverse matrix)
203. remove linked list elements
【新手上路常见问答】关于数据可视化
openstack详解(二十二)——Neutron插件配置
[C language - Advanced pointer] mining deeper knowledge of pointer
Type-C Bluetooth speaker single port rechargeable OTG solution
445. adding two numbers II
工厂出产流程中的这些问题,应该怎么处理?