当前位置:网站首页>Online service emergency research methodology
Online service emergency research methodology
2022-06-25 12:56:00 【Wenxiaowu】
1 Hain's law and Murphy's law
Hain's law states that :
Behind every serious accident , There must be 29 Minor accidents and 300 Signs of failure and 1000 Potential accidents .
Hain's law emphasizes two points :
(1) The occurrence of accidents is the result of the accumulation of quantity ;
(2) The best technology , Perfect rules , At the practical level , It can't replace people's own quality and sense of responsibility .
According to Hain's law , After a major accident , We should deal with accidents and solve problems at the same time , But also in time for similar problems 「 Signs of accidents 」 and 「 A sign of an accident 」 Check and deal with , To prevent similar problems from happening again , Solve the problem in the bud , This can be used as the guiding ideology of online emergency for Internet enterprises .
Murphy's law states :
If there are two or more ways to do something , And choosing one of them will lead to disaster , Someone must have made that choice .
The default law emphasizes a few points :
(1) Nothing is as simple as it seems
(2) Everything will take longer than you expected
(3) Things that go wrong always go wrong
(4) If you are worried that something will happen , Then it's more likely to happen
Murphy's law is actually a psychological effect , If you are worried that something will happen , Then it is very likely to happen , Over time it will happen .
Murphy's law is a warning to us technologists :
Don't despise any strange phenomena and problems in the production environment , We must thoroughly investigate the reasons behind it .
Hain's law is a warning to us technical people :
Any serious breakdown of the production environment , There are many small problems behind the accumulation of , Accumulating to a certain level will lead to qualitative change , And then there's a more serious breakdown .
therefore , We need online services , Any symptoms of problems that arise , No matter the size of the problem , We need to get to the bottom of it , Be skeptical about any problem , Ask yourself 「 Why does it happen ? What is the cause of this ? How to check and solve ? How to restore service quickly ? How to avoid ?」 wait . You can't ignore the problem because it's not obvious .
2 The goal of online emergency 、 principle 、 Method
The goal of online emergency 、 principle 、 Method :

2.1、 Emergency target
The direction of action should be correctly grasped at the critical time , Don't deviate from the target in the emergency process .
The production environment breaks down , It's a priority to find a way to restore service quickly , Avoid or reduce the loss caused by failure , Reduce the impact on users .
2.2、 Emergency principle
The corresponding emergency principles are summarized as follows :
(1) Recover the system as soon as possible instead of finding out the cause thoroughly to solve the problem , Quick stop loss .
(2) When there is a significant loss of funds , To upgrade in the first place , Quick stop loss . This article is particularly critical in the field of Finance .
(3) If the person in charge of emergency response cannot solve the problem in a short time , You have to upgrade .
(4) In the emergency process, the user experience is not affected , Keep part of the site and data . It is convenient to locate and analyze the cause of the problem after recovery .
2.3、 Emergency methods and procedures
Online emergency response must be organized 、 Go ahead in a planned way .
Online emergency is mainly divided into six stages :
There should be an overall goal for emergency response : Recover the problem as soon as possible , Eliminate influence . Regardless of the emergency stage , The first problem is to restore the system first , Recovery issues do not require immediate positioning of issues , It doesn't have to be a perfect solution .
Generally judged by experience , Start the online problem pre-processing scheme, etc , To achieve the goal of fast read recovery . meanwhile , Pay attention to keep part of the site , It is convenient to locate and solve the problem after the event .
2.3.1、 Find the problem
Usually at the system level , The discovery of the problem must depend on the alarm of the system 、 Automatic monitoring and other mechanisms to achieve , Not by users 、 The business side will tell you that there is something wrong with your system , If so , Problems with your system have been going on for some time .
Monitoring level , Usually at the system level 、 Application level 、 Monitoring at the resource level .
Monitoring at the system level includes : Systematic CPU utilization 、 System load 、 Memory is used 、 The Internet IO load 、 Disk load 、I/O wait for 、 Use of exchange area 、 Monitor the number of threads and open file handles , Once the threshold is exceeded , Just call the police in time .
The monitoring of the application level includes the response time of the service interface 、 throughput 、 Call frequency 、 Interface success rate is the volatility of the interface for monitoring .
Monitoring at the resource level includes database 、 Cache and message queue monitoring . We usually load the database 、 slow SQL、 Monitor the number of connections, etc ; Number of connections to cache 、 Take up memory 、 throughput 、 Response time and so on ; Response time to message queue 、 throughput 、 load 、 Backlog monitoring .
2.3.2、 Location problem
First of all, we should analyze... According to experience , Someone in the emergency team has experience in the corresponding problems , And make sure that it can be restored by some means , It should be restored as soon as possible , And keep the scene , Then position the problem .
The emergency personnel may need to work with the business leader in the process of positioning 、 Technical director 、 Technical personnel 、 Operation and operation and maintenance work together , Analyze the cause of the problem quickly .
The following questions need to be considered :
(1) Question whether the system has been online recently ?
(2) Whether the dependent basic platform and resources are online or upgraded ?
(3) Whether the dependent system has been online recently ?
(4) Has the operation changed in the system ?
(5) Does the network fluctuate , Contact operation and maintenance personnel to assist in troubleshooting ?
(6) Whether the recent business traffic is normal , Whether there is abnormal flow ?
(7) Is there any promotion for the applicable room of the service ?
2.3.3、 solve the problem
The stage of problem solving is sometimes in emergency handling , Sometimes after emergency treatment . Ideally , In case of any problem, the system will start the emergency plan , Each system will design stop loss for various problems 、 The bottom line 、 Strategies such as degraded switches . therefore , In case of serious problems, use these plans to recover the problems , Then we can locate and solve the problem .
Of course, problem solving should be based on positioning problems , The root cause of the problem must be analyzed clearly , Then put forward an effective solution to the problem , Remember before you know why , Don't try to fix the problem using all possible methods , This may not solve the current problem , It may raise another question .
2.3.4、 Eliminate influence
When solving problems , A problem may have been recovered before it was solved , In that case, we need to eliminate the impact of the problem .
2.3.5、 The problem of the resumption
After eliminating the problem , The emergency team and relevant parties are required to review the causes of the accident 、 The rationality of the emergency process , Put forward rectification measures to solve the problems , Focus on a few questions :
(1) What other questions do you not think of ?
(2) What has been done , This accident will not happen ?
(3) What has been done , Even if the accident happened, there would be no loss ?
(4) What has been done , This accident even if the Dharma God comes , It won't cost so much ?
Of course , Review the purpose of the accident and no longer make similar mistakes , Instead of punishing the parties .
2.3.6、 Avoidance measures
Improvement plan and avoidance measures proposed based on review problems , We must conduct unified management in a formal project management way , If there is a project manager role , Then the avoidance measures and improvement measures shall be submitted to the project manager for follow-up ; without , Then please establish a follow-up plan and mechanism for improvement measures and avoidance measures , otherwise , in the course of time , The problem is ignored .
3 Methodology of technological research
Flow chart of technical research :
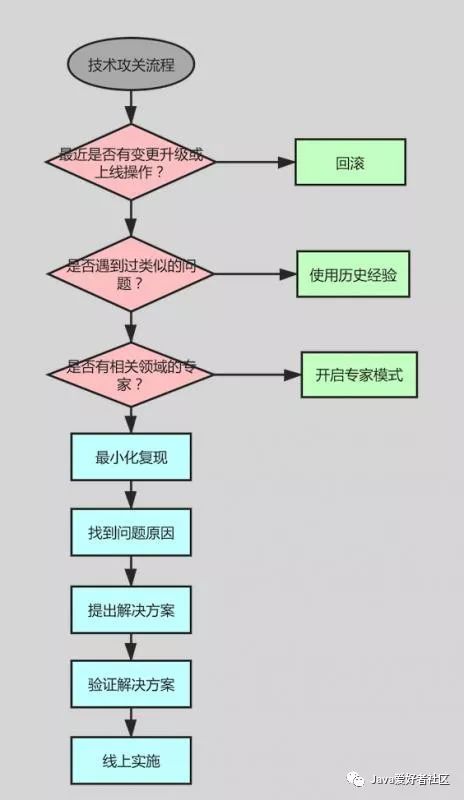
The goal of technical research is to solve problems .
Start with the environment and background of the problem , Priority should be given to the above mentioned problems :
3.1、 Is there any change recently 、 Upgrade or go live ?
Give priority to this one , Especially when the system alarm is received after the completion of online , Relevant problems fed back by users shall be paid attention to in time , If there is a problem due to going online , Roll back processing as soon as possible , Avoid expanding the impact .
meanwhile , Establish and improve the online process and online review mechanism , Every time you go online, you need to have a quick rollback scheme .
3.2、 Have you ever encountered similar problems before ?
Judge whether the system has ever had the same or similar problems based on historical experience , If you have experience in solving similar problems , Can refer to the rapid application of historical experience to solve the problem .
It is required to restart after each failure and summarize the cause of the failure , And give the solution to the problem , To accumulate experience .
3.3、 Whether there are experts in relevant fields ?
Encountered a deeper problem , For example, encounter DDOS attack 、 Performance can't bear 、 Network failure 、 The middleware used frequently alarms and so on . For similar problems, first ask experts in relevant fields , They have accumulated more experience , Or you can understand the reason more deeply and solve the problem quickly .
The above process still can't solve the problem , We need to find a way to tackle the technical problems .
An analysis of any problem , It needs to be analyzed from the following aspects :
abbreviation :5W
When: When did the problem arise ?
What: What's wrong ?
Who: Who discovered the problem at what time ? The question affects who ?
Where: Where is the problem ?
Why: Why is there a problem ?
Based on the above analysis , Help you clear your mind , Make a preliminary judgment on the system , Then from the log of this system 、 data 、 Tools , And combined with code positioning analysis of the causes of the problem .
This also reflects the importance of logs in the system , Good logs can help locate problems quickly and accurately .
You can find a way 「 Minimize recurrence 」 Online problem , Minimizing recurrence is the most digestible set of components on which problems arise , Easy to build , Reduce the scope of using components , Helps to quickly locate the cause of the problem .
If we can reproduce Veneto in a controlled or simulated environment , Or remote debugging can help locate problems .
After locating the cause of the problem , Give solutions .
Assess the impact of the solution on the online , weigh the advantages and disadvantages , Choose the best plan , And give the reasons for the choice .
Submit the problem solution to the superior for review , It will be implemented after passing the review . The solution needs to be in the development environment and QA Environment to verify , It's not just about validating the problems the solution solves , meanwhile , Also avoid having an impact on existing features , Therefore, further regression verification may be needed .
Through such a series of technological research processes , It can guarantee the integrity in the process of technical research 、 The right and efficient way to solve problems .
边栏推荐
猜你喜欢

冷启动的最优解决方案
Module 5 (microblog comments)

It is extraordinary to make a move, which is very Oracle!

C program linking SQLSERVER database: instance failed

Possible problems when idea encounters errors occurred while compiling module (solved)

Baidu search stability analysis story

康威定律,作为架构师还不会灵活运用?
利用cmd(命令提示符)安装mysql&&配置环境

架构师必备的七种能力

GNSS receiver technology and application review
随机推荐
20220620 面试复盘
出手即不凡,这很 Oracle!
Using CMD (command prompt) to install MySQL & configure the environment
Serevlt初识
el-select clear 清空内容时触发事件
Common software numerical filtering methods (I) have been applied
A half search method for sequential tables
You can't specify target table 'xxx' for update in from clause
Slice and slice methods of arrays in JS
GPS receiver design (1)
Match regular with fixed format beginning and fixed end
量化交易之回测篇 - 期货CTA策略策略(TQZFutureRenkoWaveStrategy)
Talk about 11 key techniques of high availability
Embedded software development written examination and interview notes (latest update: February 17, 2022)
Go defer little knowledge
AI assisted paper drawing of PPT drawing
剑指 Offer 第 1 天栈与队列(简单)
Figure explanation of fiborache sequence
Draw the satellite sky map according to the azimuth and elevation of the satellite (QT Implementation)
Why are databases cloud native?