当前位置:网站首页>test3
test3
2022-08-02 14:17:00 【发量不足】
import time
import urllib, time, os, base64, json
import re, sys
import urllib
from lxml import etree
import requests
def getPage(base_url):
try:
page = urllib.request.urlopen(base_url) # 5
content = page.read().decode("utf-8", "ignore").lower()
re_script=re.compile('<\s*script[\S\s]*<\s*/\s*script\s*>',re.I) #Script [\\S\\s]+?
re_style=re.compile('<\s*style[^>]*>[^<]*<\s*/\s*style\s*>',re.I) #style
content=re_script.sub('',content) #去掉SCRIPT
content=re_style.sub('',content)#去掉style
selector = etree.HTML(content.encode("utf-8",'ignore'))
# answer one
# menu_items = selector.xpath("/html/body/header/div/ul[@id='head_nav_list']/li/a") # 5
# for item in menu_items:
# writefile("/home/output/crawler_result.csv", item.attrib.get("href")) # 2
# answer two
menu_items = selector.xpath("/html/body/header/div/ul[@id='head_nav_list']/li/a/@href") # 5
for item in menu_items:
writefile("/home/output/crawler_result.csv", item) # 2
except Exception as e: # 3
print("Failed to read from %s." % base_url)
print(sys.exc_info())
return False
def writefile(filename, content):
try:
fp = open(filename, 'a') # 5
fp.write(content + "\n") # 5
fp.close() # 5
except:
return False
now = time.strftime('%Y-%m-%d %X', time.localtime(time.time()))
try:
# 5
url = '1'
getPage(url)
except Exception as e:
info = '%s\nError: %s' % (now, e)
writefile('Error.log', info)
print (info)
time.sleep(1)边栏推荐
猜你喜欢
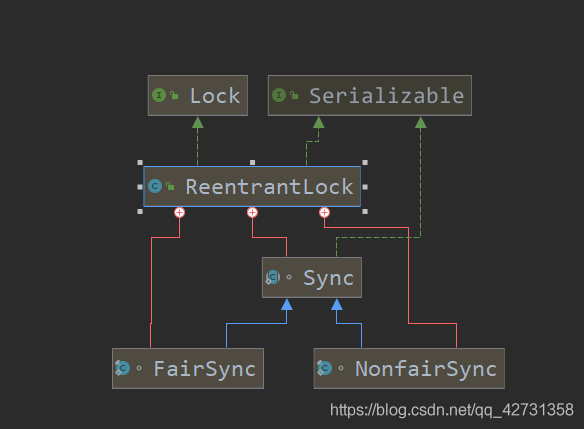
抽象队列同步器AQS应用Lock详解
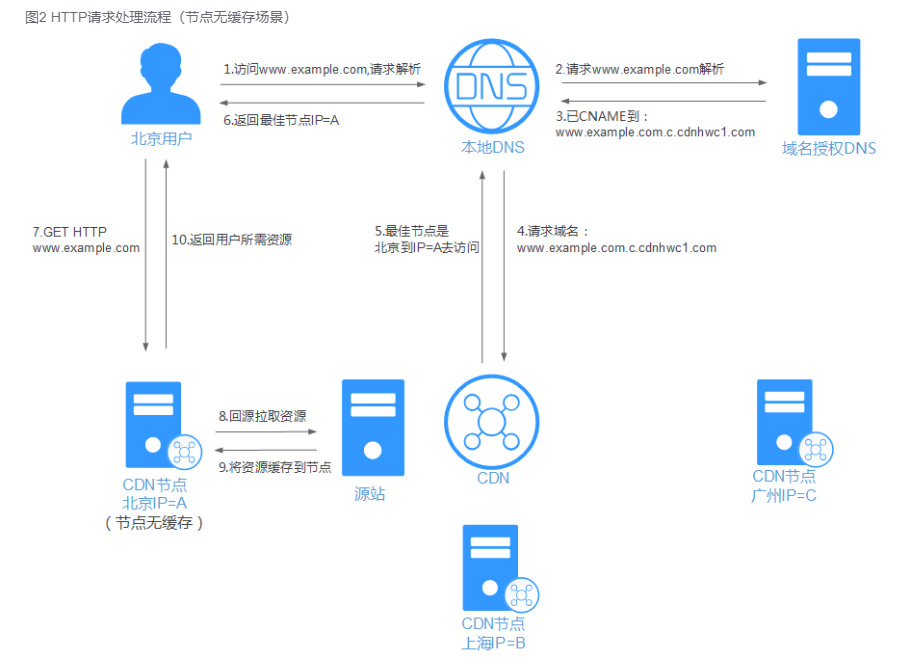
CDN的加速原理是什么?
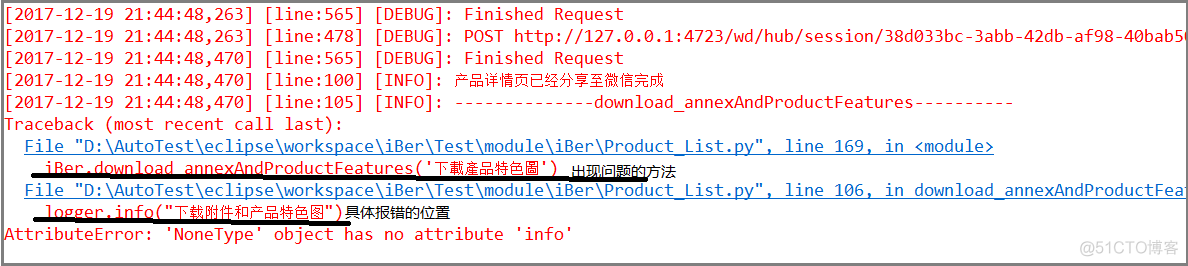
appium 报错:AttributeError:
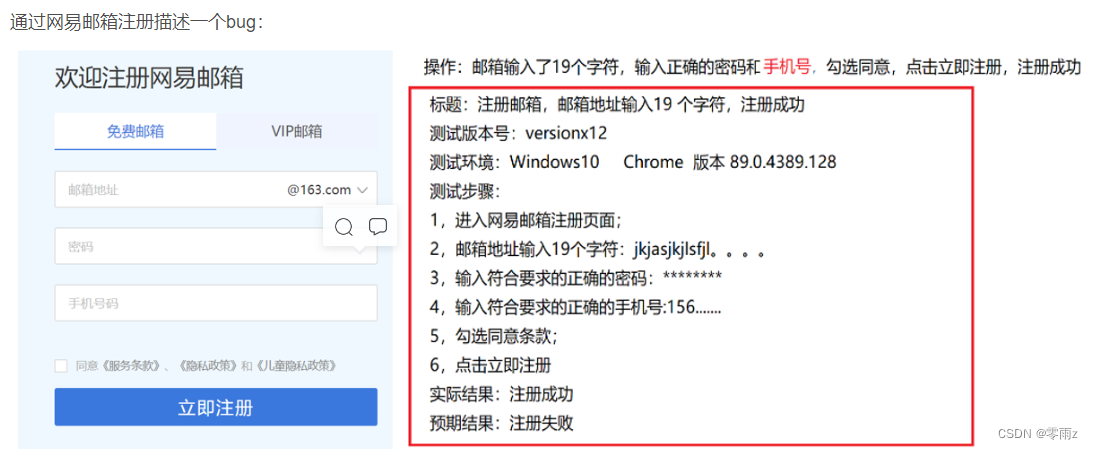
【软件测试】基础篇

MYSQL5.7详细安装步骤
![The relationship between base classes and derived classes [inheritance] / polymorphism and virtual functions / [inheritance and polymorphism] abstract classes and simple factories](/img/c1/c695006706ce91233d9ac8ecb95c50.png)
The relationship between base classes and derived classes [inheritance] / polymorphism and virtual functions / [inheritance and polymorphism] abstract classes and simple factories
VLAN原理

【软件测试】自动化测试selenium3

Mysql删库恢复数据
synchronized详解
随机推荐
【数组】查表法(闰年)
超简单了解三次握手与四次挥手
华为单臂路由配置,实现不同vlan之间的通信
关于机组的部分知识点随笔
打包项目上传到PyPI
网络运维系列:网络出口IP地址查询
Mysql理解MVCC与BufferPool缓存机制
消息队列的技术选型
【进程间通信】:管道通信/有名/无名
Feign Client 超时时间配置不生效
【个人向】线性表复习
How to tick the word box?
排序方法汇总(C语言)
Xrdp 体验优化
双链表(普通迭代器和常性迭代器)
Homebrew的简单介绍
字符数组/字符串数组|数组指针/指针数组/
网络运维系列:远程服务器登录、配置与管理
WEB自动化之键盘、鼠标操作
screen 不间断会话服务