当前位置:网站首页>Talking from mlperf: how to lead the next wave of AI accelerator
Talking from mlperf: how to lead the next wave of AI accelerator
2022-07-01 16:02:00 【AI technology base camp】

author | OneFlow Community
source | OneFlow Community
In the history of deep learning , Specialized hardware at least AlexNet and Transformers These two revolutionary moments played a key role , The papers that introduced both architectures emphasized in their abstracts GPU The role of , It also explains in detail how they parallelize the underlying computing to multiple GPU in , To speed up the calculation .
The reason to emphasize this point , Because as early as AlexNet The paper was published 20 Years ago , The deep convolution neural network applied to computer vision has been born ; Again , As early as Transformers Before publication , Applied to naturallanguageprocessing LSTMs、RNNs And self attention mechanism (self-attention mechanism) It already exists , This shows that many algorithm foundations have already existed .
However , By showing how to do large-scale calculations at a reasonable cost , The authors have made further breakthroughs in the above fields . The reason is , They got it AI The revolutionary nature of acceleration : Expand to daily necessities (Scale-to-Commodity).

25 Over the years , Router 、 Wired and wireless network speeds have increased 1000 times
Although improving the performance per unit cost has always been the long-term goal of computer scientists and engineers , But in some cases , Revenue will change the rules of the game , Some things that used to be considered impossible to become daily necessities will become daily necessities .
When the chip performance improves 100 times , It means that you can run a complex model in two hours , In the past, you had to spend a week , You may even need 100 Based on CPU The workstation ( Suppose you can master all these parallelization and pay for expensive electricity ).
In the past 20 year , Due to the increase of Internet bandwidth 1000 Many times , Our lives have changed dramatically . You can imagine , Did people have to wait for hours to finish downloading their favorite TV series ? It's so painful .
In order to maintain AI The revolutionary nature of , We need to consider which models can be commercialized and how to commercialize them .
1
AI The pitfalls of benchmarking
In recent years , We have witnessed MLPerf The rise of , This is a program aimed at AI The performance data reported by hardware and system suppliers are standardized benchmark components . It comes from 70 Many head technology companies ( Ying Wei Da 、 Google 、AMD Intel )、 Multiple startups (SambaNova、Cerebras and Graphcore) And various universities and technical institutions ( Stanford 、 Harvard and Berkeley ) And many industry leaders .
MLPerf Benchmarks include ResNet50 and BERT Such as multiple AI application , And evaluate different sections , Including data center training 、 Data center reasoning, mobile device reasoning, etc . Every few months ,MLPerf You will receive test results submitted by major companies and institutions ( It mainly involves application running time ), Then they will push the results to the corresponding fields . such , The submitters will be able to submit the documents according to MLPerf The competition evaluates their performance , Some potential customers can also choose ones that are more in line with their own needs AI System .
MLPerf There is an ambitious mission statement : Based on real models 、 Open data sets and easy to understand indicators , Provide users with standardized and unbiased performance reasoning methods , To promote AI Application .
With AI Hardware is more popular , We urgently need more industry standards and indicators to understand AI The performance of the hardware . although MLPerf We have done a good job in performance evaluation , But I also want to mention three improvement measures that can expand its influence .
1、 Normalization
AI There are many kinds of accelerators , Different users ( Amateurs 、 Graduate student 、 Large enterprises, etc ) And system ( Mobile devices 、 The workstation 、 Autopilot 、HPC/ Cloud, etc. ) There are also great differences in the needs of .
Besides , There are many ways to build accelerators , Give a computational domain , You can use your imagination and creativity to design hardware and software together ( Of course , You also have to consider the market demand and cost ). because AI Accelerators and systems are diverse , It is not easy to compare different acceleration technologies , Not to mention defining a kind of fairness 、 Unbiased accelerator comparison standard .

IEEE spectrum Once published an article entitled 《AI Training is going beyond Moore's law 》 The article (https://spectrum.ieee.org/ai-training-mlperf), This view is based on MLPerf Published test results . Moore's law holds that , Transistor density every 18 Months will add about 2.2 times , but MLPerf The published data shows that ,AI The results of the training are 18 Improved within months 16-27 times .
therefore , Someone said right away ,“ If we are so much faster than Moore's law , So most of the performance improvement is not because we use better semiconductor technology , But because of the better acceleration method and software technology .” However , Their conclusion is not reliable . Because they don't have standardized standards to measure performance , Therefore, the contribution of hardware to performance optimization is ignored .

ResNet50 The gradual standardization of training results
Let's take a closer look at these figures . With ResNet50 Data center training for ,2018 year ,MLPerf The baseline result is to use 640 individual NVIDIA V100 GPU Achieved 6.2 minute , And in the 2021 year , Time has been reduced to 0.23 minute . In terms of numbers alone , The speed is indeed about 27 times , But this is because of the use of 3456 individual TPU v4 Accelerator , This means that the number of accelerators has increased 5.4 times . therefore , If we apply this standard to every chip , Actual performance will still improve 5 times , It's amazing .
in addition , One V100 GPU There are... On the chip 211 100 million transistors , Although Google is TPU The specification didn't reveal much , But it's with TPUv4 Competitive training chips (NVIDIA A100、SambaNova SN10、Graphcore mk2 IPU etc. ) The number of transistors is 400-600 About 100 million .
therefore , We can reasonably assume that TPUv4 With so many transistors , It can provide per second 275 Peak performance of trillions of floating-point operations , So conservative estimates TPUv4 Yes 400 100 million transistors , So we will conclude that the performance of each transistor has been improved 2.6 About times .
Last ,V100 It's using 12 nanometer CMOS Technology manufacturing , and TPUv4 Probably using 7 nanometer CMOS Technology makes ( Such as TPUv4i).ITRS And other academic studies suggest that ,7 Nano circuits should be better than 12 Nano circuits are fast 1.5 times . therefore , Taking all these factors into account , Include more budget , Faster and better hardware capabilities , The architecture helps to improve performance by only 1.7 About times .
obviously , This is a first order approximation (first-order approximation), Actual performance is determined by many factors other than computational semiconductor technology , For example, memory bandwidth 、 cache 、 Communication bandwidth and topology . More complex systems do need to be managed by a more sophisticated and sophisticated software stack , Increasing the number of chips or transistors does not guarantee an equal multiple improvement in performance . We must have such thinking , To better understand normalization , And performance optimization through transistors .
Why is it so urgent to optimize performance by standardizing transistors ? The main reasons are as follows :
1、 This is the meaning of the accelerator . If one day , Transistor technology will really stop developing as Moore's law says , In the future, we will only realize performance optimization on the premise that silicon-based technology is stagnant ;
2、 If there is no fair comparison method , Grades are just numbers , It's like a race between a cyclist and a person who drives a Lamborghini is meaningless ;
3、 The performance of a chip cannot be improved indefinitely , When the accelerator supplier develops a series of accelerators , They need to evaluate the hardware of each generation of accelerators 、 Software stack , So as to find out the real contribution that the upgrading can make to the performance optimization . meanwhile , Also need to know , Sometimes they will no longer come up with a better solution to the same problem , And we will encounter the diminishing return of chip specialization and collision “ Accelerator wall ”;
4、 Trying to invest a lot of money on an issue to improve performance is not desirable ,MLPerf Only stick to your accelerated vision , And push AI The revival has entered the first stage —— Expand to daily necessities , In order to continue to maintain their own value .
AlexNet and Transformers It opens the door to training complex models using a single system , And led a new round of breakthroughs . We need to pay more attention to standardized performance indicators , Such as unit power performance or single transistor performance . We have made some attempts in unit power performance , But such a job doesn't seem very attractive . Power measurement is troublesome , And making a breakthrough in this area will not cause a sensation like setting a new training time record .
Last , Although it's good to know the absolute performance figures , But ordinary data scientists really care about how to build a billion level system ( Have thousands of processors they can't afford ) Improve the execution time ? This leads to our subsequent discussion .
2. Popularization
MLPerf Benchmark applications involved , Mainly 2012 to 2018 Models mentioned in academic research papers published in , and GPU As the only feasible choice for deep learning at that time , The data in those papers are models in GPU Performance results running on .
and , The characteristics of the underlying architecture involved in this paper 、 Both the super parameters and the scale of the architecture will depend on GPU To configure the , The advantages of the model will be similar to GPU Combined with the architectural advantages of , Of course , The final test results will also be affected GPU Limited by the shortcomings of .
In this way ,MLPerf The competition is actually more similar to “GPU competition ”, Also let GPU Since then, it has become AI A byword for hardware .
Don't get me wrong —— We should all attach importance to GPU, Because it is modern AI The pioneers of . without GPU Mature hardware / Software stack , Will never witness AI The rise of applications . But in addition to GPU, We now have other solutions , We should also explore the properties of native models developed on other types of architectures , They can open up some new fields .
Besides , We probably don't want a single software implementation , Or a single type of architecture , This determines the whole AI Achievements and limitations in application fields . It can be assumed , If in 2010 Years ago TPU and TensorFlow The ecological system , that MLPerf The scope of application will be different .
3. generalization
“When a measure becomes a target, it ceases to be a good measure( When an indicator becomes a goal , It will no longer be a good indicator .)”-Charles Goodhart
MLPerf The last challenge to overcome is the lack of application generalization . About a year ago , I surveyed a leading company in the industry AI Performance evaluation of hardware suppliers . Experience tells me , It is not easy to achieve the expected performance .
So here's what happened , Even in a new Docker All the latest libraries are installed on the image , I have participated in MLPerf The running score of our model is not close to their published score . Only use the model version provided by the supplier from a dedicated Library , And after the manual configuration file overrides the compiler's decision on the model , It is possible to achieve their published scores .
Last , When I replaced the model provided by the supplier with another model ( The number of layers and size of the two models are almost identical ), And after the same configuration , I found that the performance decreased 50% about . I heard that , Other friends have had similar experiences when using some models provided by other suppliers .

Use benchmarking “ Slow moving target ”(slow-moving targets) The above undesirable results will occur , That's not surprising .
at present ,MLPerf The benchmark has used the same set of applications for three consecutive years , Therefore, the supplier only needs to show some unrealistic things to these applications during testing “ Disposable ” performance , Can run a good result ; Most data scientists don't really understand the underlying hardware 、 Compilers and software libraries , So they don't spend weeks tuning , Not to mention creating manual configuration files that override compiler decisions .
AI One of the main challenges is to achieve “ User to hardware expression (user-to-hardware-expressiveness)”.AI The field is developing rapidly , Hundreds of new research papers are published every day , So we need to generalize the stack , So that they can “ Open the box ” Run more use cases with good performance , Instead of still focusing on the applications of a decade ago .
MLPerf We should pay more attention to , What data scientists need is a powerful acceleration stack (acceleration stack), These acceleration stacks can take advantage of the underlying hardware to handle unprecedented workloads .
at present , majority AI Hardware suppliers give priority to customer models and requirements , Instead of MLPerf application . If MLPerf No more common 、 A more popular way , It is bound to meet more competitors , And eventually people will no longer want to see it as an industry benchmark .
2
Rethink hardware acceleration
Hardware acceleration has been the driving force AI One of the key factors for the development of the field , So understand the basic assumptions of hardware acceleration 、 Limitations of existing concepts and new development directions , For pushing AI Further development of the field is crucial .
Across the innovation gap
AI The field is research driven , Therefore, there is a close symbiotic relationship between industry and academia . Cutting edge used in production systems AI The model and its theory are published in NeurIPS、ICML、CVPR and ICLR And other papers at top academic conferences , Include AlexNet、ResNet、YOLO、Transformers、BERT、GPT-3、GANs and Vision Transformers. Besides , Many of these papers were written by academic institutions and Google 、 facebook 、 The results of the cooperation between NVIDIA and research laboratories of Microsoft and other companies .
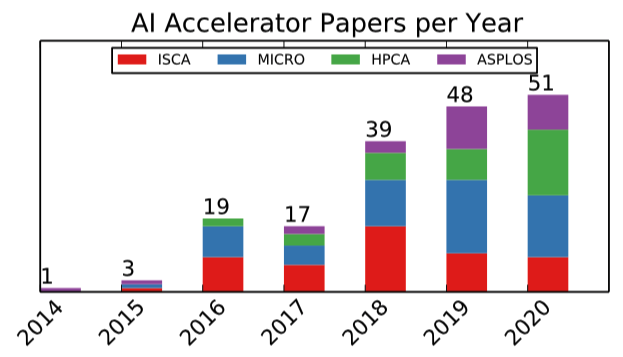
And AI Compared with the application field , Industry is in AI Accelerator field has been lagging behind academia . although ISCA、MICRO、HPCA and ASPLOS Dozens of new papers on accelerators will be published every year at the computer architecture summit , But the core architecture idea of accelerators deployed in production was born decades ago , Including memory processing 、 Data flow calculation 、 Pulse array 、VLIW wait .
We need to accumulate more ideas and innovations , And turn it into a new product . The adoption of new ideas is always slow , This is because it takes years to make chips , and AI There is fierce competition in the hardware field , Adopting new ideas means that it may be costly to change some of the existing functions , It's risky .
However , current AI The accelerator field has matured , Some necessary foundations have been laid , We also know how to do it effectively . therefore , It's time for suppliers to try some new ideas , Drive... Through new discoveries AI Accelerator field development . To believe in ,AI There is still room for innovation in the accelerator field !
Give Way AI Acceleration really works on AI
modern AI Has aroused our interest , It makes us think about the infinite possibilities of the future , And put forward some ideas about philosophy 、 Sociological and ethical issues , The giants in these fields are also discussing intensively :AI What can be done ?AI What is the future direction of development ? however , Before we imagine , Must pay attention to AI Of “ Chicken and egg ” problem : Hardware is the basis of the model , It's hard to imagine a new model deployed on poor performance hardware , in other words , New models require new hardware .
Due to the high cost of manufacturing new hardware , Therefore, it is necessary to have a reasonable reason to get funds to start researching new hardware . But if you don't have the hardware to run these new models in a reasonable time , It is impossible to prove the value of these new models . next , Because the actual performance of the new model was not demonstrated ,AI Innovation will be constrained by existing hardware solutions .

from AI To deep learning : What are we accelerating ?
It is worth mentioning that , Although we call what current hardware does “AI Speed up ”, But it's actually exaggerating . in fact , It's closer to “ Deep learning speeds up ”, Or it is the product of a combination of tensor based deep learning and machine learning algorithms , It can run well on the matrix multiplication engine .
Someone might say ,“ ok , Almost all of us have heard of deep learning , It is the most valuable nowadays ‘ Killer application ’”, But that is the key ——— We mainly study deep learning , Because the algorithm library and hardware are customized for deep learning , Therefore, deep learning is the field we can explore at present , This is what you need to pay attention to when developing accelerated hardware .
We co design algorithms and hardware , It has developed from building general-purpose processors to building various architectures ; However , We optimize the data path length to a fixed size variable , Because there are fixed size algorithm engines and fixed word size memory and connections , And we try to use matrix multiplication , Because it has a simple and predictable control flow . We don't want to over optimize the hardware, resulting in a significant decline in its performance , This prevents you from exploring new features , Thus hindering the progress of the algorithm .
Although I am not a neuroscientist , But I know that the brain has many complex structures , These structures communicate in an irregular way , So we may not be able to use matrix multiplication 、 Fixed width data paths and nonlinear functions to simulate them .
therefore , We need to think , Whether this hardware evolution makes the application hardware co design space converge to local optimization ? Maybe , If we leave the tensor intensive model, we can achieve “AI Speed up 2.0”, welcome AI The next wave of hardware .
At that time ,“AI Speed up 2.0” There is no need to multiply the matrices , But it supports irregular computing mode , And it has flexible representation and arbitrary parallel computing engine . Accelerators with these characteristics ( Or heterogeneous integration of such accelerators ) It will have a wider range of applications , It is also closer to the real AI.
To make a long story short , We need to think : Is attention mechanism all we need ? Convolutional neural networks (CNN) Is it the final answer ? Whatever the answer is , Convolutional neural networks have indeed condensed most of our research results , But maybe AI There are more things that can be extended to daily necessities .
( This document is issued after authorization , original text :
https://medium.com/@adi.fu7/ushering-in-the-next-wave-of-ai-acceleration-a7a14a1803d1)

Looking back
NLP Exploration and practice of class problem modeling scheme
Python Common encryption algorithms in crawlers !
2D Transformation 3D, Look at NVIDIA's AI“ new ” magic !
Get it done Python Several common data structures !
Share
Point collection
A little bit of praise
Click to see 边栏推荐
- [video memory optimization] deep learning video memory optimization method
- Task.Run(), Task.Factory.StartNew() 和 New Task() 的行为不一致分析
- Redis seckill demo
- process. env. NODE_ ENV
- 2022-07-01日报:谷歌新研究:Minerva,用语言模型解决定量推理问题
- Seate中用了shardingjdbc 就不能用全局事务了吗?
- 【开源数据】基于虚拟现实场景的跨模态(磁共振、脑磁图、眼动)人类空间记忆研究开源数据集
- 马来西亚《星报》:在WTO MC12 孙宇晨仍在坚持数字经济梦想
- 电脑屏幕变色了怎么调回来,电脑屏幕颜色怎么改
- What is the forkjoin framework in the concurrent programming series?
猜你喜欢

【Pygame实战】你说神奇不神奇?吃豆人+切水果结合出一款你没玩过的新游戏!(附源码)

#夏日挑战赛# HarmonyOS canvas实现时钟

周少剑,很少见
The newly born robot dog can walk by himself after rolling for an hour. The latest achievement of Wu Enda's eldest disciple
新出生的机器狗,打滚1小时后自己掌握走路,吴恩达开山大弟子最新成果

动作捕捉系统用于苹果采摘机器人
![[PHP graduation design] design and implementation of textbook management system based on php+mysql+apache (graduation thesis + program source code) -- textbook management system](/img/04/11f24f12c52fb1f69e3d6f513d896b.png)
[PHP graduation design] design and implementation of textbook management system based on php+mysql+apache (graduation thesis + program source code) -- textbook management system

Tensorflow team: we haven't been abandoned

2022 Moonriver global hacker song winning project list

Thinkphp内核工单系统源码商业开源版 多用户+多客服+短信+邮件通知
随机推荐
从 MLPerf 谈起:如何引领 AI 加速器的下一波浪潮
Preorder, inorder, follow-up of binary tree (non recursive version)
For the sustainable development of software testing, we must learn to knock code?
Pico, do you want to save or bring consumer VR?
Task. Run(), Task. Factory. Analysis of behavior inconsistency between startnew() and new task()
Crypto Daily:孙宇晨在MC12上倡议用数字化技术解决全球问题
ABAP-调用Restful API
Reading notes of top performance version 2 (V) -- file system monitoring
Introduction to RT thread env tool (learning notes)
Idea start command line is too long problem handling
[IDM] IDM downloader installation
Automatique, intelligent, visuel! Forte conviction des huit conceptions derrière la solution sslo
The picgo shortcut is amazing. This person thinks exactly the same as me
Pico, can we save consumer VR?
二叉树的前序,中序,后续(非递归版本)
Solution to the problem that the keypad light does not light up when starting up
Seata中1.5.1 是否支持mysql8?
Some abilities can't be learned from work. Look at this article, more than 90% of peers
Win11如何設置用戶權限?Win11設置用戶權限的方法
C#/VB.NET 合并PDF文档