当前位置:网站首页>代码实现MNLM
代码实现MNLM
2022-07-02 10:11:00 【InfoQ】
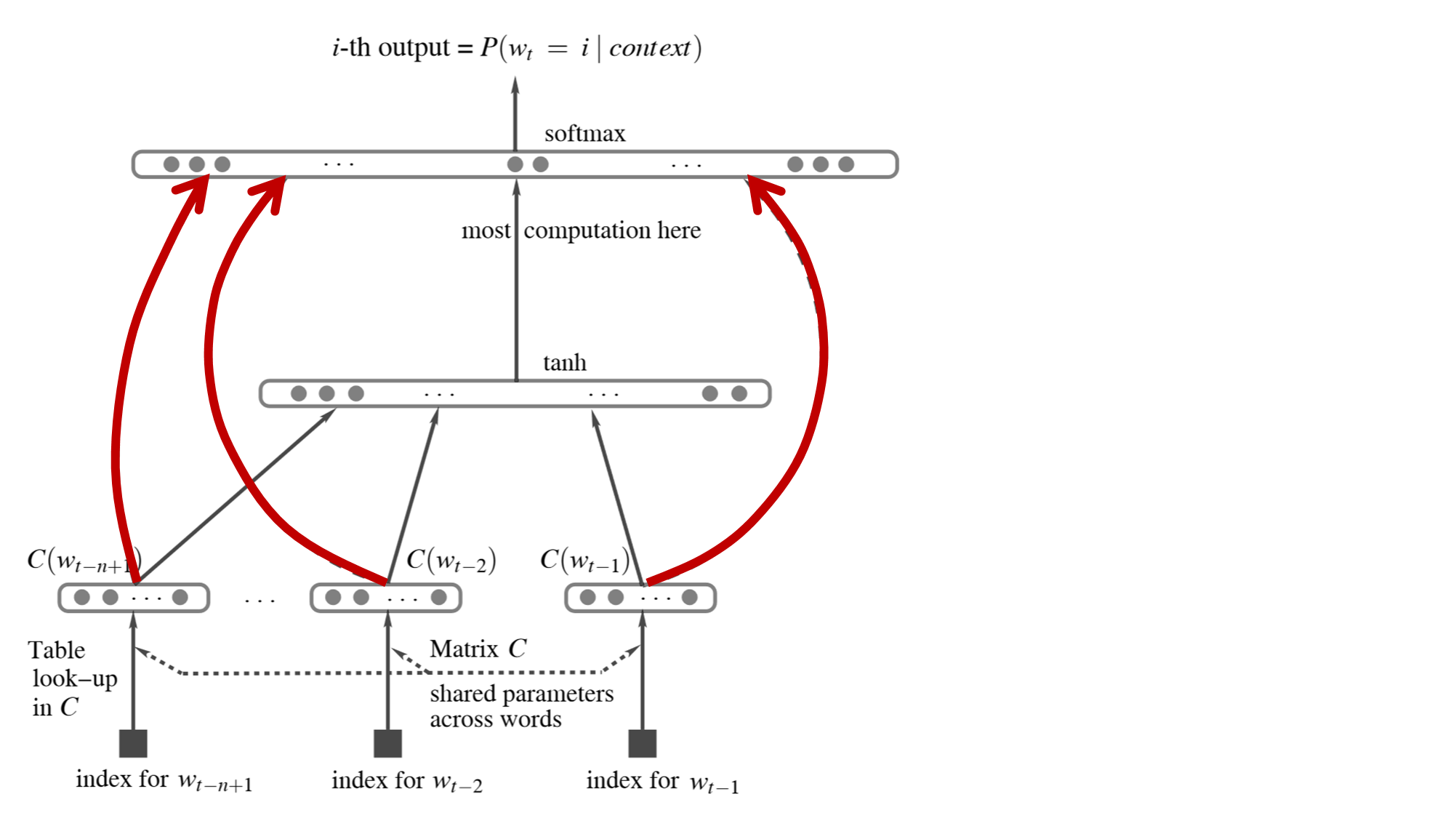
先回顾一下子模型结构

- y 是输出
- x 是输入,之后会转化为图中的C,但是原文公式还用的x表示
- d 是隐藏层的bias
- H 是输入层到隐藏层的权重
- U 是隐藏层到输出层的权重
- W 是c直接到输出层的权重
- b 是输出层的bias
解释一下网络是怎么出来的



代码
模型代码
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Parameter(torch.randn(len_sen * m, n_hidden,requires_grad=True))
self.d = nn.Parameter(torch.randn(n_hidden))
self.U = nn.Parameter(torch.randn(n_hidden, n_class,requires_grad=True))
self.W = nn.Parameter(torch.zeros(len_sen * m, n_class,requires_grad=True))
self.b = nn.Parameter(torch.randn(n_class))
def forward(self, X): # X : [batch_size, len_sen]
X = self.C(X) # X : [batch_size, len_sen, m]
X = X.view(-1, len_sen * m) # [batch_size, len_sen * m]
tanh = torch.tanh(self.d + X @ self.H) # [batch_size, n_hidden]
output = self.b + X @ self.W + tanh @ self.U # [batch_size, n_class]
return output
__init__(self)这部分是上面一些参数量。
self.C是一个embedding操作。
- 其余的就是网络中的参数。提到的W初始化为0矩阵,所以W那里就用
torch.zeros,其余的就使用随机初始化torch.randn。
forward(self, X)就是设置前向传播,
X = self.C(X),先将X进行一个embedding处理,然后再将结果还给X。就对应了我们前面提到的,虽然要经过一个embedding处理,但是原公式中输入还是用X表示的。
Tensor.view函数是修改张量形状的。torch.Tensor.view — PyTorch 1.11.0 documentation。修改维度之后就是将每个句子中每个单词的word embedding向量拼接起来。
self.d + X @ self.H这里是输入层的隐藏层的计算。
tanh = torch.tanh(self.d + X @ self.H)计算结果要经过tanh的激活函数。这里是将tanh激活函数计算之后的结果直接赋值给了一个叫tanh的变量。
output = self.b + X @ self.W + tanh @ self.U然后是输出层计算。这里要注意输出层的结果是有两部分组成的。一部分是隐藏层传过来的结果,一部分是输入层传过来的结果,二者相加之后才是隐藏层的计算。
batch_sizelen_senmn_hiddenn_class- 最开始你的输入是一组句子嘛,所以你的输入X的形状应该是 [batch_size, len_sen]。此时矩阵的每一个元素都是一个单词。

- 经过第一步embedding计算之后,就会将其转化为特征向量表示。此时的X的形状应该是[batch_size, len_sen, m]。因为原来你是一个元素,表示一个词。现在变成了一个词,用一个特征向量来表示。所以就增加了一个维度来表示这个特征向量。现在变成了一个三维矩阵。

- 经过
Tensor.view修改形状。这里是X.view(-1, len_sen * m)修改为二维矩阵,矩阵的第二维是len_sen * m,第一维度自适应(-1是自适应的意思)。意思就是把一个句子中不同单词的表示做一个concate,拼接起来。

tanh这里已经到了隐藏层了。所以输入向量的长度会变成隐藏层的大小。这个隐藏层的大小n_hidden也是需要自己设置的。隐藏层大小决定网络的质量。当然我们这里数据量比较小,所以好不好其实隐藏层大小的影响根本就不大。一般隐藏层的大小遵循以下几个规则。
- 假设:
- 输入层大小为
- 输出层分为类
- 样本数量为
- 一个常数
- 常见的观点有隐藏层数量:
- ……
- 神经网络中如何确定隐藏层的层数和大小_LolitaAnn的技术博客_51CTO博客
- 在这里我们就使用。在我们的代码里输入的长度就是
len_sen * m。分类大小就是单词表的长度n_class。计算之后h的大小为14。
- 此时的
tanh维度为[batch_size, n_hidden]。

- 输出层形状是[batch_size, n_class],输出层要做的对每一个样本计算最终获得一个向量。这向量的长度和单词表的长度一样,以此指出预测结果在单词表中的位置。

数据预处理部分的代码
sentences = ["The cat is walking in the bedroom",
"A dog was running in a room",
"The cat is running in a room",
"A dog is walking in a bedroom",
"The dog was walking in the room"]
word_list = " ".join(sentences).lower().split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
- 第七行代码
word_list是把数据集中的所有句子都用空格拼接起来。然后再将其转化成小写。然后再用空格将其分开,分成不同的词。此时就得到了一个单词列表。但是现在里面会有很多重复的词。
- 第八行的代码
word_list先使用set,把上面得到的那个列表转换成一个集合,去掉重复的词,然后再转换回列表。
- 第九行和第十行代码就是使用枚举创建单词表的词典。
def dataset():
input = []
target = []
for sen in sentences:
word = sen.lower().split() # space tokenizer
i = [word_dict[n] for n in word[:-1]] # create (1~n-1) as input
t = word_dict[word[-1]] # create (n) as target, We usually call this 'casual language model'
input.append(i)
target.append(t)
return input, target

完整代码
import torch
import torch.nn as nn
import torch.optim as optim
def dataset():
input = []
target = []
for sen in sentences:
word = sen.lower().split() # space tokenizer
i = [word_dict[n] for n in word[:-1]] # create (1~n-1) as input
t = word_dict[word[-1]] # create (n) as target, We usually call this 'casual language model'
input.append(i)
target.append(t)
return input, target
# Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Parameter(torch.randn(len_sen * m, n_hidden,requires_grad=True))
self.d = nn.Parameter(torch.randn(n_hidden))
self.U = nn.Parameter(torch.randn(n_hidden, n_class,requires_grad=True))
self.W = nn.Parameter(torch.zeros(len_sen * m, n_class,requires_grad=True))
self.b = nn.Parameter(torch.randn(n_class))
def forward(self, X): # X : [batch_size, len_sen, m]
X = self.C(X) # X : [batch_size, len_sen, m]
X = X.view(-1, len_sen * m) # [batch_size, len_sen * m]
tanh = torch.tanh(self.d + X @ self.H) # [batch_size, n_hidden]
output = self.b + X @ self.W + tanh @ self.U # [batch_size, n_class]
return output
if __name__ == '__main__':
sentences = ["The cat is walking in the bedroom",
"A dog was running in a room",
"The cat is running in a room",
"A dog is walking in a bedroom",
"The dog was walking in the room"]
word_list = " ".join(sentences).lower().split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # number of Vocabulary
len_sen = 6 # number of steps, n-1 in paper
m = 3 # embedding size, m in paper
n_hidden = (int)((len_sen*m*n_class)**0.5) # number of hidden size, h in paper
model = NNLM()
loss = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
input, target = dataset()
input = torch.LongTensor(input)
target = torch.LongTensor(target)
# 训练之前先看一下效果。
predict = model(input).data.max(1, keepdim=True)[1]
print([sen.split()[:6] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
# Training
for epoch in range(5000):
optimizer.zero_grad()
output = model(input)
# output : [batch_size, n_class], target : [batch_size]
Loss = loss(output, target)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(Loss))
Loss.backward()
optimizer.step()
# Predict & test
predict = model(input).data.max(1, keepdim=True)[1]
print([sen.split()[:6] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
边栏推荐
- net share
- 科技的成就(二十七)
- (7) Web security | penetration testing | how does network security determine whether CND exists, and how to bypass CND to find the real IP
- Explanation of 34 common terms on the Internet
- Unity skframework framework (XV), singleton singleton
- OpenApi-Generator:简化RESTful API开发流程
- [cloud native database] what to do when encountering slow SQL (Part 1)?
- We sincerely invite young creators to share with investors and entrepreneurs how to make choices in life in the metauniverse
- Which do you choose between Alibaba P7 with an annual salary of 900000 and deputy department level cadres?
- JS reverse massive creative signature
猜你喜欢

What are eNB, EPC and PGW?

2022零代码/低代码开发白皮书【伙伴云出品】附下载
When tidb meets Flink: tidb efficiently enters the lake "new play" | tilaker team interview

Everyone wants to eat a broken buffet. It's almost cold

de4000h存储安装配置
How to modify the error of easydss on demand service sharing time?

题解《子数整数》、《欢乐地跳》、《开灯》
Don't spend money, spend an hour to build your own blog website
![[OpenGL] notes 29. Advanced lighting (specular highlights)](/img/6e/56bc7237f691a4355f0b7627b3003e.png)
[OpenGL] notes 29. Advanced lighting (specular highlights)

2022 Heilongjiang provincial examination on the writing skills of Application Essays
随机推荐
Japan bet on national luck: Web3.0, anyway, is not the first time to fail!
D如何检查null
Partner cloud form strong upgrade! Pro version, more extraordinary!
[cloud native database] what to do when encountering slow SQL (Part 1)?
ADB basic commands
诚邀青年创作者,一起在元宇宙里与投资人、创业者交流人生如何做选择……...
JS逆向之行行查data解密
How to explain binary search to my sister? This is really difficult, fan!
Unity SKFramework框架(十三)、Question 问题模块
Node.js通过ODBC访问PostgreSQL数据库
Skillfully use SSH to get through the Internet restrictions
Performance optimization of memory function
Lucky numbers in the [leetcode daily question] matrix
Let juicefs help you with "remote backup"
De4000h storage installation configuration
nohup命令
Unity SKFramework框架(十六)、Package Manager 开发工具包管理器
基于ssm+jsp框架实现的学生选课信息管理系统【源码+数据库】
PR usage skills, how to use PR to watermark?
Solution: Compression Technology (original version and sequel version)