当前位置:网站首页>The principle of redis cache consistency deep analysis
The principle of redis cache consistency deep analysis
2022-06-23 14:39:00 【Liu Java】
Keep creating , Accelerate growth ! This is my participation 「 Nuggets day new plan · 6 Yuegengwen challenge 」 Of the 22 God , Click to see the event details
In detail Redis There are three ways to achieve cache consistency , And their advantages and disadvantages .
First of all, understand , There is no absolute consistency between the cache and the database data , If absolutely consistent , Then you can't use the cache , We can only guarantee the final consistency of the data , And try to keep the cache inconsistency time as short as possible .
in addition , To avoid data inconsistency between the cache and the database caused by extreme conditions , The cache needs to set an expiration time . time out , Cache is automatically cleaned up , Only in this way can the cache and database data be “ Final consistency ”.
If the concurrency is not very high , Whether you choose to delete the cache first or later , It rarely causes problems .
1 Update the database first , Then delete the cache
If the database is successfully updated first , Failed to delete cache , Then there are new data in the database , There is old data in the cache , At this point, data inconsistency will occur .
If you're in a high concurrency scenario , There is also a more extreme case of database and cache data inconsistency :
- The cache just failed ;
- request A Query the database , Get an old value ;
- request B Writes the new value to the database ;
- request B Delete cache ;
- request A Writes the old value found to the cache ;
This leads to inconsistencies . and , If you do not use the cache expiration policy , The data is always dirty , Unless the database data is updated next time .
2 So let's delete the cache , Then update the database
So let's delete the cache , Update the database after , Even if updating the database later fails , Cache is empty , When reading, it will re read from the database , Although they are all old data , But the data are consistent .
If you're in a high concurrency scenario , There is also a more extreme case of database and cache data inconsistency :
- request A Write operation , Delete cache ;
- request B Query found that the buffer does not exist ;
- request B Query the database , Get an old value ;
- request B Writes the old value found to the cache ;
- request A Writes the new value to the database ;
3 Adopt the strategy of delay double deletion
The two methods above , Whether you write the library first , Delete the cache ; Or delete the cache first , Write the library again , There may be data inconsistencies . relatively speaking , The second is safer , therefore , If only these two simple methods , The second is recommended .
A better and better way is to adopt a “ Delay double delete ” The strategy of ! Before and after writing the library redis.del(key) operation , In addition, to avoid updating the database , Other threads cannot read data from the cache and then read the old data and write it to the cache , Just after updating the database , Again sleep A span , Then delete the cache again .
This sleep The time should be longer than another request to read the old data in the database + Write cache time , And if there is redis Master slave synchronization 、 Database sub database sub table , Also consider the time-consuming data synchronization , stay Sleep Then try deleting the cache again ( Whether new or old ). such , Although there is no guarantee that there will be no cache consistency problem , But it can be guaranteed that only sleep Cache inconsistency in time , Reduced cache inconsistency time .
Of course, this strategy needs to sleep for a certain period of time , This undoubtedly increases the time required to write the request , This causes the throughput of server requests to decrease , It's also a problem . So , You can treat the second deletion as an asynchronous deletion . such , Business thread requests don't have to sleep Return after a period of time , Do it , It can increase throughput .
What if deleting the cache fails ? At this time, a retry mechanism is required , At this point, you can use the message queue , Will need to be deleted key To the message queue , Asynchronous consumption messages , Get what needs to be removed key The value of is compared with the value of the database ! Delete if inconsistent , Or if the deletion fails, it will start from new consumption to success , Or when you fail a certain number of times, it's usually Redis There's something wrong with the server !
In fact, after the introduction of message oriented middleware , The problem has become more complicated , We need to ensure that there are no problems with message oriented middleware , For example, the producer sends a message successfully or unsuccessfully . therefore , We can listen to the database binlog Log message queue to delete the cache , The advantage is that you don't have to put messages into the message queue , Listen to the database through a middleware binlog journal , Then automatically put messages into the queue , We no longer need to program producer code , Just write the consumer's code . This kind of monitoring database binlog+ Message queue It is also a popular way at present .
4 Why delete cache
Why do the above methods delete the cache instead of updating the cache ?
If you update the database first , Then update the cache , Then the following may happen : If the database 1 Updated within hours 1000 Time , Then the cache needs to be updated as well 1000 Time , But this cache may be in 1 Only read in hours 1 Time . If it's deleted , Even if the database is updated 1000 Time , So it's just done 1 Second valid cache delete , Subsequent deletion operations will immediately return , Only when the cache is actually read can the database load the cache . This reduces Redis The burden of .
Related articles :
If you need to communicate , Or the article is wrong , Please leave a message directly . In addition, I hope you will like it 、 Collection 、 Focus on , I will keep updating all kinds of Java Learning blog !
边栏推荐
- MySQL 创建和管理表
- AI intelligent robot saves us time and effort
- Go write file permission WriteFile (filename, data, 0644)?
- When did the redo log under InnoDB in mysql start to perform check point disk dropping?
- 用OBS做直播推流简易教程
- [deeply understand tcapulusdb technology] tmonitor background one click installation
- Is flush a stock? Is it safe to open an account online now?
- Qu'est - ce que ça veut dire? Où dois - je m'inscrire?
- Shutter clip clipping component
- Working for 7 years to develop my brother's career transition test: only by running hard can you get what you want~
猜你喜欢
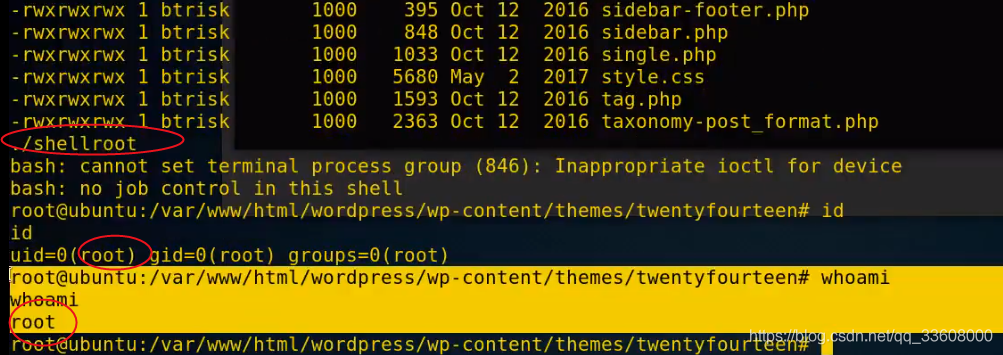
渗透测试-提权专题
![[in depth understanding of tcapulusdb technology] tcapulusdb business data backup](/img/1a/449b123c0f2046217ec60af36344eb.png)
[in depth understanding of tcapulusdb technology] tcapulusdb business data backup
Gold three silver four, busy job hopping? Don't be careless. Figure out these 12 details so that you won't be fooled~
![Web technology sharing | [Gaode map] to realize customized track playback](/img/b2/25677ca08d1fb83290dd825a242f06.png)
Web technology sharing | [Gaode map] to realize customized track playback

Working for 7 years to develop my brother's career transition test: only by running hard can you get what you want~

Use xtradiagram Diagramcontrol for drawing and controlling process graphics

中国矿大团队,开发集成多尺度深度学习模型,用于 RNA 甲基化位点预测
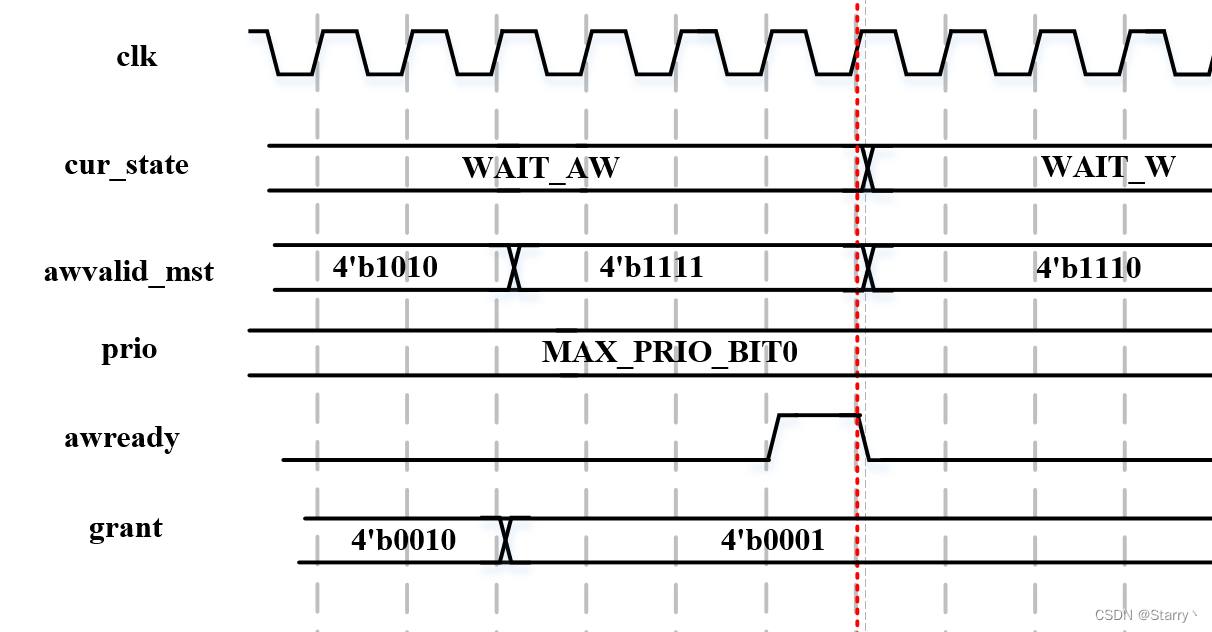
AXI_Round_Robin_Arbiter 设计 - AW、W通道部分

Ks007 realizes personal blog system based on JSP

【深入理解TcaplusDB技术】如何实现Tmonitor单机安装
随机推荐
Penetration test - right raising topic
golang--文件的多个处理场景
Short talk about community: how to build a game community?
微信小程序之下拉菜单场景
Use of pyqt5 tool box
[in depth understanding of tcapulusdb technology] tcapulusdb construction data
Assembly language interrupt and external device operation --06
知名人脸搜索引擎惹众怒:仅需一张照片,几秒钟把你扒得底裤不剩
Oracle进入sqlplus 报错
How to merge tables when exporting excel tables with xlsx
Win10 64位系统如何安装SQL server2008r2的DTS组件?
加快 yarn install 的三个简单技巧
php接收和发送数据
ICML 2022 𞓜 context integrated transformer based auction design neural network
The first public available pytorch version alphafold2 is reproduced, and Columbia University is open source openfold, with more than 1000 stars
【二级等保】过二级等保用哪个堡垒机品牌好?
Ks008 SSM based press release system
同花顺是股票用的么?现在网上开户安全么?
如何使用笔记软件 FlowUs、Notion 进行间隔重复?基于公式模版
Google Earth engine (GEE) -- Comparative Case Analysis of calculating slope with different methods