当前位置:网站首页>Warp matrix functions in CUDA
Warp matrix functions in CUDA
2022-07-02 06:28:00 【Little Heshang sweeping the floor】
Warp matrix functions
C++ warp Matrix operation utilization Tensor Cores To speed up D=A*B+C Formal matrix problem . Ability to calculate 7.0 Mixed precision floating-point data of devices with or higher versions supports these operations . It needs a warp Cooperation of all threads in . Besides , Only if the condition is in the whole warp When the calculation results in are the same , It is allowed to perform these operations in the condition code , Otherwise, code execution may hang .
1. Description
All the following functions and types are in the namespace nvcuda::wmma In the definition of . Sub-byte The operation is considered a preview , That is, their data structure and API May change , And may be incompatible with future versions . This extra function is in nvcuda::wmma::experimental In the namespace .
template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment;
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
void fill_fragment(fragment<...> &a, const T& v);
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);
fragment:
Overloaded classes that contain part of the matrix , Distribution in warp Of all threads in . Matrix elements to fragment The mapping of internal storage is unspecified , And it may change in the future architecture .
Only certain combinations of template parameters are allowed . The first template parameter specifies how the fragment will participate in matrix operations . Acceptable usage values are :
matrix_aWhenfragmentWhen used as the first multiplicand ,Amatrix_bWhenfragmentWhen used as the second multiplicand ,B- When
fragmentUsed as a source or destination accumulator ( Respectively C or D) Time accumulator .
m、n and k Size describes the warp-wide Shape of matrix block . Every tile The size of depends on its function . about matrix_a, The size of the block is m x k; about matrix_b, Dimension is k x n, The accumulator block is m x n.
For the multiplicand , data type T It can be double、float、__half、__nv_bfloat16、char or unsigned char, For accumulators , It can be double、float、int or __half. Such as Element type and matrix size Described in , Support limited combinations of accumulator and multiplicand types . It has to be for matrix_a and matrix_b Fragment assignment Layout Parameters . row_major or col_major They represent the matrix Row or column The elements in are continuous in memory . Of the accumulator matrix Layout The parameter should keep the default value void. Specify row or column layout only when loading or storing accumulators as described below .
load_matrix_sync:
Wait until all warp passageway (lanes) All arrived load_matrix_sync, Then load the matrix fragment from memory a. mptr Must be a 256 Bit aligned pointer , Points to the first element of the matrix in memory . ldm Describe consecutive lines ( For row main sequence ) Or column ( For column main order ) Element span between , about __half The element type must be 8 Multiple , For floating-point elements, the type must be 4 Multiple . ( namely , In both cases 16 Multiple of bytes ). If fragment It's an accumulator , Then the layout parameter must be specified as mem_row_major or mem_col_major. about matrix_a and matrix_b fragment ,Layout It's from fragment Of Layout Inferred from the parameter . a Of mptr、ldm、layout And the values of all template parameters are for warp All threads in must be the same . This function must be warp All threads in call , Otherwise, the result is undefined .
store_matrix_sync:
Wait until all warp All channels arrive store_matrix_sync, Then the matrix fragment a Store in memory . mptr Must be a 256 Bit aligned pointer , Points to the first element of the matrix in memory . ldm Describe consecutive lines ( For row main sequence ) Or column ( For column main order ) Element span between , about __half The element type must be 8 Multiple , For floating-point elements, the type must be 4 Multiple . ( namely , In both cases 16 Multiple of bytes ). The layout of the output matrix must be specified as mem_row_major or mem_col_major. a Of mptr、ldm、layout And the values of all template parameters are for warp All threads in must be the same .
fill_fragment:
Use constant v Fill matrix fragment . Since the mapping of matrix elements to each fragment is not specified , Therefore, this function is usually composed of warp All threads in call , And have common v value .
mma_sync:
Wait until all warp lanes All arrived mma_sync, And then execute warp Synchronous matrix multiplication and accumulation operation D=A*B+C. It also supports in situ (in-place) operation ,C=A*B+C. about warp All threads in , Of each matrix segment satf The values of and template parameters must be the same . Besides , Template parameter m、n and k Must be in segment A、B、C and D The matching between . This function must be defined by warp All threads in call , Otherwise the result is undefined .
If satf( Saturated to a finite value –saturate to finite value) The mode is true , Then the following additional numeric attributes apply to the target accumulator :
- If the element result is +Infinity, Then the corresponding accumulator will contain +MAX_NORM
- If the element result is -Infinity, Then the corresponding accumulator will contain -MAX_NORM
- If the element result is NaN, Then the corresponding accumulator will contain +0
Since the mapping of matrix elements to each thread fragment is not specified , Therefore, it must be called in store_matrix_sync From memory ( Shared or global ) Access a single matrix element . stay warp In the special case that all threads in will uniformly apply element operations to all fragment elements , You can use the following fragment Class members implement direct element access .
enum fragment<Use, m, n, k, T, Layout>::num_elements;
T fragment<Use, m, n, k, T, Layout>::x[num_elements];
for example , The following code reduces the accumulator matrix by half .
wmma::fragment<wmma::accumulator, 16, 16, 16, float> frag;
float alpha = 0.5f; // Same value for all threads in warp
/*...*/
for(int t=0; t<frag.num_elements; t++)
frag.x[t] *= alpha;
2. Alternate Floating Point
Tensor Core Support in having 8.0 And higher computing power devices for alternative types of floating-point operations .
__nv_bfloat16:
This data format is another fp16 Format , Its scope is related to f32 identical , But the accuracy is reduced (7 position ). You can directly compare this data format with cuda_bf16.h Provided in __nv_bfloat16 Type used together . have __nv_bfloat16 Matrix fragments of data type need to be combined with accumulators of floating-point type . Supported shapes and operations are similar to __half identical .
tf32:
This data format is Tensor Cores Special floating point formats supported , The scope and f32 identical , But the accuracy is reduced (>=10 position ). The internal layout of this format is implementation defined . In order to be in WMMA This floating-point format is used in the operation , The input matrix must be manually converted to tf32 precision .
To facilitate conversion , Provides a new inline function __float_to_tf32. Although the input and output parameters of the inline function are floating-point types , But the output will be tf32. This new precision applies only to tensor cores , If mixed with other floating-point operations , The precision and scope of the results will be undefined .
Once the matrix is entered (matrix_a or matrix_b) Converted to tf32 precision , have precision::tf32 Precision segments and load_matrix_sync Of float The combination of data types will take advantage of this new feature . Both accumulator fragments must have a floating-point data type . The only supported matrix size is 16x16x8 (m-n-k).
The elements of the fragment are represented as floating-point numbers , So from element_type<T> To storage_element_type<T> The mapping is :
precision::tf32 -> float
3. Double Precision
Tensor Core Support computing power 8.0 And higher devices . To use this new feature , Must use with double Fragment of type . mma_sync Operation will use .rn( Round to the nearest even number ) The rounding modifier performs .
4. Sub-byte Operations
Sub-byte WMMA Operation provides an access Tensor Core The method of low precision function . They are considered preview functions , That is, their data structure and API May change , And may be incompatible with future versions . This function can be accessed through nvcuda::wmma::experimental Namespace get :
namespace experimental {
namespace precision {
struct u4; // 4-bit unsigned
struct s4; // 4-bit signed
struct b1; // 1-bit
}
enum bmmaBitOp {
bmmaBitOpXOR = 1, // compute_75 minimum
bmmaBitOpAND = 2 // compute_80 minimum
};
enum bmmaAccumulateOp { bmmaAccumulateOpPOPC = 1 };
}
about 4 Bit accuracy , Usable API remain unchanged , But you must specify experimental::precision::u4 or experimental::precision::s4 As fragment data type . Because the elements of the fragment are packed together ,num_storage_elements Will be smaller than the num_elements. Sub-byte Fragment num_elements Variable , Therefore return Sub-byte type element_type<T> The number of elements . The same is true for unit accuracy , under these circumstances , from element_type<T> To storage_element_type<T> The mapping of is as follows :
experimental::precision::u4 -> unsigned (8 elements in 1 storage element)
experimental::precision::s4 -> int (8 elements in 1 storage element)
experimental::precision::b1 -> unsigned (32 elements in 1 storage element)
T -> T //all other types
Sub-byte The allowable layout of fragments is always matrix_a Of row_major and matrix_b Of col_major.
For sub byte operations ,load_matrix_sync in ldm Value of for element type experimental::precision::u4 and Experimental::precision::s4 Should be 32 Multiple , Or for element types experimental::precision::b1 Should be 128 Multiple ( namely , In both cases 16 Multiple of bytes ).
bmma_sync:
Wait until all warp lane Both have been implemented. bmma_sync, And then execute warp Synchronous bit matrix multiplication and accumulation operation D = (A op B) + C, among op By logical operation bmmaBitOp and bmmaAccumulateOp Defined cumulative composition . The available operations are :
bmmaBitOpXOR,matrix_aA line in is related tomatrix_bOf 128 Ranked 128 position XORbmmaBitOpAND,matrix_aA line in is related tomatrix_bOf 128 Ranked 128 position AND, Can be used for computing power 8.0 And later .
The cumulative operation is always bmmaAccumulateOpPOPC, It calculates the number of set bits .
5. Restrictions
For each primary and secondary device architecture ,tensor cores The special format required may be different . Because the thread only holds fragments of the entire matrix ( Opaque architecture specific ABI data structure ), Therefore, developers are not allowed to make assumptions about how to map the parameters to the registers involved in matrix multiplication and accumulation , This makes the situation more complicated .
Because fragments are architecture specific , If the function has been compiled for different link compatible architectures and linked together to become the same device executable , Then remove them from the function A Pass to function B It's not safe . under these circumstances , The size and layout of the fragments will be specific to one architecture , In another architecture WMMA API Will lead to incorrect results or potential damage .
An example of two link compatible architectures with different fragment layouts is sm_70 and sm_75.
fragA.cu: void foo() { wmma::fragment<...> mat_a; bar(&mat_a); }
fragB.cu: void bar(wmma::fragment<...> *mat_a) { // operate on mat_a }
// sm_70 fragment layout
$> nvcc -dc -arch=compute_70 -code=sm_70 fragA.cu -o fragA.o
// sm_75 fragment layout
$> nvcc -dc -arch=compute_75 -code=sm_75 fragB.cu -o fragB.o
// Linking the two together
$> nvcc -dlink -arch=sm_75 fragA.o fragB.o -o frag.o
This undefined behavior may not be detected by tools at compile time and runtime , Therefore, extra care is needed to ensure that the layout of fragments is consistent . When built with a compatible architecture for different links and expected to pass WMMA When linking legacy libraries of fragments , This kind of link danger is most likely to occur .
Please note that , In the case of weak links ( for example ,CUDA C++ Inline function ), The linker may choose any available function definition , This may lead to implicit passing between compilation units .
To avoid such problems , The matrix should always be stored in memory for transmission through external interfaces ( for example wmma::store_matrix_sync(dst, ...);), It can then be safely passed as a pointer type to bar() [ for example float *dst].
Please note that , because sm_70 Can be in sm_75 Up operation , Therefore, the above example sm_75 Code changed to sm_70 And in sm_75 Correct operation on . however , When with others sm_75 When linking binary files compiled separately , It is recommended to include sm_75 Native code .
6. Element Types & Matrix Sizes
Tensor core supports multiple element types and matrix sizes . The following table shows the supported matrix_a、matrix_b and accumulator Various combinations of matrices :
| Matrix A | Matrix B | Accumulator | Matrix Size (m-n-k) |
|---|---|---|---|
| __half | __half | float | 16x16x16 |
| __half | __half | float | 32x8x16 |
| __half | __half | float | 8x32x16 |
| __half | __half | __half | 16x16x16 |
| __half | __half | __half | 32x8x16 |
| __half | __half | __half | 8x32x16 |
| unsigned char | unsigned char | int | 16x16x16 |
| unsigned char | unsigned char | int | 32x8x16 |
| unsigned char | unsigned char | int | 8x32x16 |
| signed char | signed char | int | 16x16x16 |
| signed char | signed char | int | 32x8x16 |
| signed char | signed char | int | 8x32x16 |
Alternate floating point support :
| Matrix A | Matrix B | Accumulator | Matrix Size (m-n-k) |
|---|---|---|---|
| __nv_bfloat16 | __nv_bfloat16 | float | 16x16x16 |
| __nv_bfloat16 | __nv_bfloat16 | float | 32x8x16 |
| __nv_bfloat16 | __nv_bfloat16 | float | 8x32x16 |
| precision::tf32 | precision::tf32 | float | 16x16x8 |
Double fine support :
| Matrix A | Matrix B | Accumulator | Matrix Size (m-n-k) |
|---|---|---|---|
| double | double | double | 8x8x4 |
Yes sub-byte Experimental support for operation :
| Matrix A | Matrix B | Accumulator | Matrix Size (m-n-k) |
|---|---|---|---|
| precision::u4 | precision::u4 | int | 8x8x32 |
| precision::s4 | precision::s4 | int | 8x8x32 |
| precision::b1 | precision::b1 | int | 8x8x128 |
7. Example
The following code is in a single warp To realize 16x16x16 Matrix multiplication :
#include <mma.h>
using namespace nvcuda;
__global__ void wmma_ker(half *a, half *b, float *c) {
// Declare the fragments
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::col_major> a_frag;
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, 16, 16, 16, float> c_frag;
// Initialize the output to zero
wmma::fill_fragment(c_frag, 0.0f);
// Load the inputs
wmma::load_matrix_sync(a_frag, a, 16);
wmma::load_matrix_sync(b_frag, b, 16);
// Perform the matrix multiplication
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
// Store the output
wmma::store_matrix_sync(c, c_frag, 16, wmma::mem_row_major);
}
边栏推荐
猜你喜欢

New version of dedecms collection and release plug-in tutorial tool

Cglib agent - Code enhancement test

Sudo right raising
Idea announced a new default UI, which is too refreshing (including the application link)
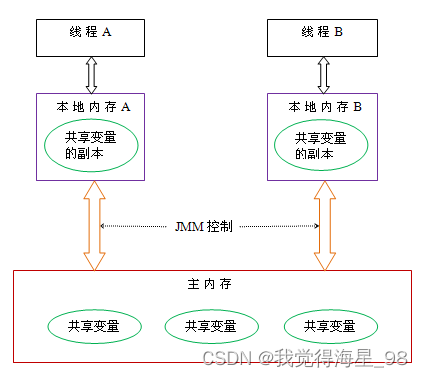
In depth understanding of JUC concurrency (II) concurrency theory

实习生跑路留了一个大坑,搞出2个线上问题,我被坑惨了
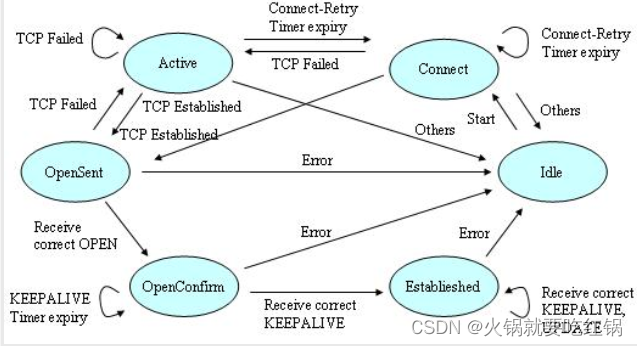
State machine in BGP
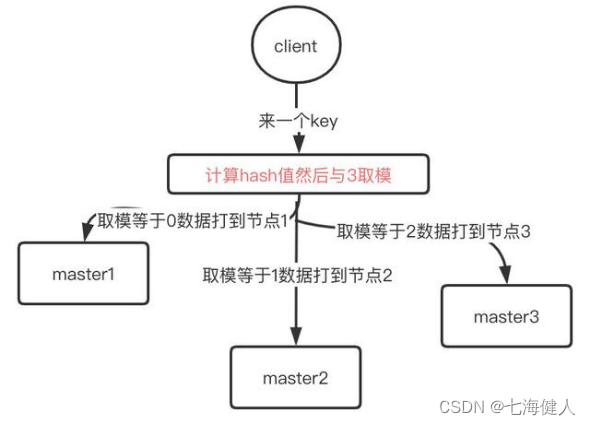
Redis——Cluster数据分布算法&哈希槽
Cglib代理-代码增强测试
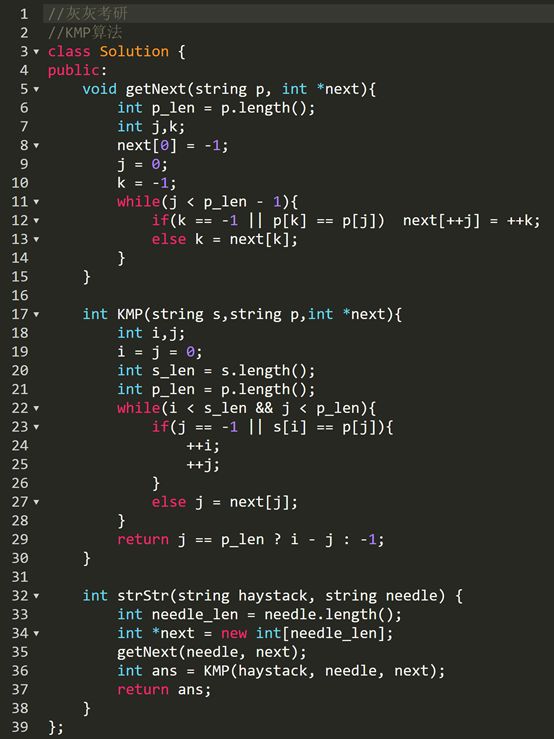
实现strStr() II
随机推荐
浅谈三点建议为所有已经毕业和终将毕业的同学
Sparse array (nonlinear structure)
Redis——Cluster数据分布算法&哈希槽
CUDA and Direct3D consistency
记录一次RDS故障排除--RDS容量徒增
Support new and old imperial CMS collection and warehousing tutorials
LeetCode 90. Subset II
TensorRT的命令行程序
Redis---1.数据结构特点与操作
深入学习JVM底层(二):HotSpot虚拟机对象
实现strStr() II
Sudo right raising
广告业务Bug复盘总结
web自动化切换窗口时报错“list“ object is not callable
栈(线性结构)
Redis - big key problem
CUDA用户对象
Golang -- map capacity expansion mechanism (including source code)
深入了解JUC并发(一)什么是JUC
深入学习JVM底层(三):垃圾回收器与内存分配策略