当前位置:网站首页>[deep learning] (4) decoder mechanism in transformer, complete pytoch code attached
[deep learning] (4) decoder mechanism in transformer, complete pytoch code attached
2022-07-01 04:13:00 【Vertical sir】
Hello everyone , Share with you today Transformer Medium Decoder Some knowledge points involved : Calculation self-attention Two types used in mask.
This article is a supplement to the previous two articles , It is strongly recommended that you take a look at :
1.《Transformer Code reappearance 》:https://blog.csdn.net/dgvv4/article/details/125491693
2.《Transformer Medium Encoder Mechanism 》:https://blog.csdn.net/dgvv4/article/details/125507206
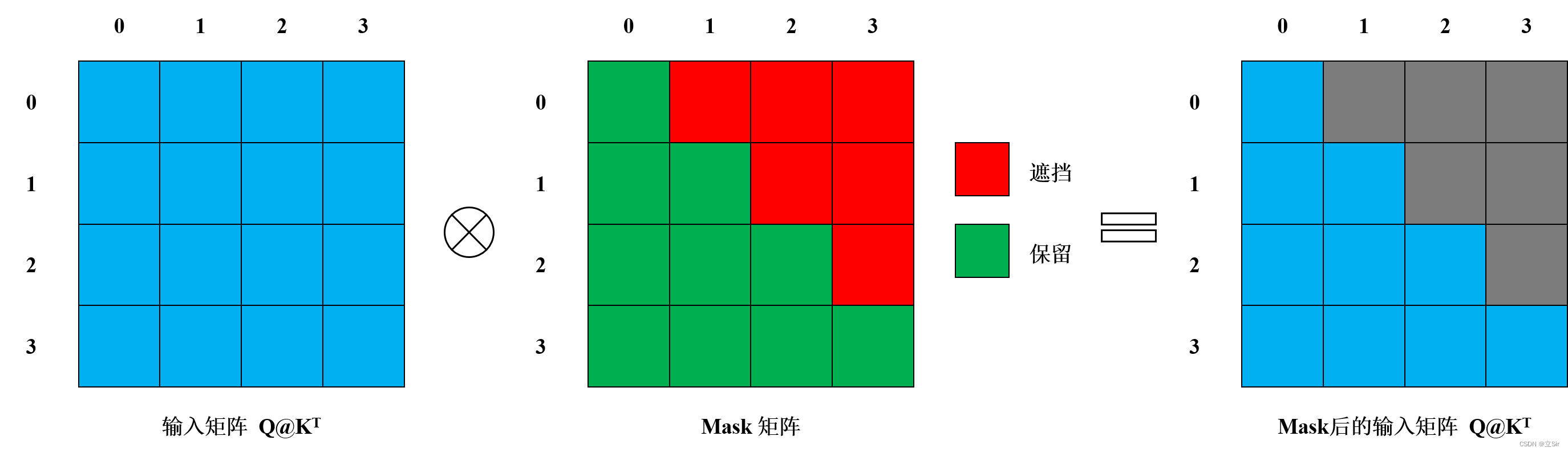
1. Decoder Of self-attention Medium mask
In this section mask Corresponding to the position in the model structure diagram :

Here's the picture ,decoder Of self-attention Used in mask It's a Lower triangular matrix , When decoder When predicting the first word , The input to it is a special character x1, When decoder When predicting the second position , The input to it is a special character x1 And the first word of the target sequence x2

Here's an example :
encoder The input of : i love you
decoder The input of : /f I Love you
At this time decoder By 4 A vector of words ,Mask It's a 4*4 Matrix of size
When decoder Predict the first word ' I ' when , decoder The input of is a special character '/f',mask by [1,0,0,0]
When decoder Predict the second word ' Love ' when , decoder The input of is a special character '/f' And the first word ' I ',mask by [1,1,0,0]
The code is as follows :
import torch
from torch.nn import functional as F
# ------------------------------------------------------ #
#(1) Construct the lower triangular shape mask
# ------------------------------------------------------ #
# There are two sentences in the target sequence , Each contains 3、4 Word
tgt_len = torch.Tensor([3,4]).to(torch.int32)
# Target sequence effective word matrix shape=[3,3], shape=[4,4]
tgt_matrix = [torch.ones(L, L) for L in tgt_len]
# All for each element 1 Sentence matrix constructs a lower triangular matrix
tri_matrix = [torch.tril(mat) for mat in tgt_matrix]
# The length of the first sentence is 3, Generate 3*3 The size and lower triangular area of the element authority 1, The rest are all 0 Matrix
print(tri_matrix) # Every mask Of shape=[seq_len,seq_len]
# Construct a matrix of valid words , adopt padding Adjust the matrix size of each sentence to the same
new_tri_matrix = [] # preservation padding after mask matrix
for seq_len, matrix in zip(tgt_len, tri_matrix): # Traverse each lower triangular matrix mask
matrix = F.pad(matrix, pad=(0,max(tgt_len)-seq_len,0,max(tgt_len)-seq_len)) # Below and to the right of the matrix padding Into the same collision
matrix = torch.unsqueeze(matrix, dim=0) # Dimension expansion [seq_len,seq_len]==>[1,seq_len,seq_len]
new_tri_matrix.append(matrix)
# Change the list type to tensor, The value is 0 The corresponding element represents the need mask fall
valid_tri_matrix = torch.cat(new_tri_matrix, dim=0)
print(' Effective lower triangular matrix mask:', valid_tri_matrix) # shape=[2,4,4]
# Will need mask The elements of are represented by Boolean types ,True Representative needs mask
invalid_tri_matrix = (1 - valid_tri_matrix).to(torch.bool)
print(' Boolean mask:', invalid_tri_matrix)
# ------------------------------------------------------ #
#(2) Yes decoder The input tensor of does mask
# ------------------------------------------------------ #
# Randomly initialize a Q @ K^T Calculated results of [batch, tgt_seq_len, tgt_seq_len]
score = torch.randn(2, max(tgt_len), max(tgt_len))
# take mask in True Elements correspond to score The value in becomes a very small value
masked_score = score.masked_fill(invalid_tri_matrix, value=-1e10)
# take mask The result after softmax, Get the attention matrix
softmax_score = F.softmax(masked_score, dim=-1)
print(' Raw input :', score)
print('mask After the input :', masked_score) And then construct a decoder The input of  , its shape=[batch, seq_len, seq_len], As the third matrix below .
, its shape=[batch, seq_len, seq_len], As the third matrix below .
Will input tensor score China and mask in True The corresponding position of the element becomes a very small number , As shown in the fourth matrix below .
# Effective lower triangular matrix mask:
tensor([[[1., 0., 0., 0.],
[1., 1., 0., 0.],
[1., 1., 1., 0.],
[0., 0., 0., 0.]],
[[1., 0., 0., 0.],
[1., 1., 0., 0.],
[1., 1., 1., 0.],
[1., 1., 1., 1.]]])
# Boolean mask:
tensor([[[False, True, True, True],
[False, False, True, True],
[False, False, False, True],
[ True, True, True, True]],
[[False, True, True, True],
[False, False, True, True],
[False, False, False, True],
[False, False, False, False]]])
# Raw input scorce:
tensor([[[ 0.5266, -0.7873, -0.2481, 0.5554],
[-1.3146, 0.1668, -1.6488, -0.5159],
[-0.1590, -2.1458, 0.0217, 0.4044],
[ 1.0169, 0.8640, -0.9029, 0.5957]],
[[-0.6277, 0.0611, -1.3732, -0.6897],
[-1.3523, 0.6712, 0.0491, 2.2301],
[ 0.4627, 0.1737, 1.0111, -1.4099],
[ 0.1994, 0.2538, 0.5689, -0.2558]]])
# mask After the input :
tensor([[[ 5.2655e-01, -1.0000e+10, -1.0000e+10, -1.0000e+10],
[-1.3146e+00, 1.6676e-01, -1.0000e+10, -1.0000e+10],
[-1.5899e-01, -2.1458e+00, 2.1674e-02, -1.0000e+10],
[-1.0000e+10, -1.0000e+10, -1.0000e+10, -1.0000e+10]],
[[-6.2770e-01, -1.0000e+10, -1.0000e+10, -1.0000e+10],
[-1.3523e+00, 6.7119e-01, -1.0000e+10, -1.0000e+10],
[ 4.6272e-01, 1.7366e-01, 1.0111e+00, -1.0000e+10],
[ 1.9943e-01, 2.5381e-01, 5.6886e-01, -2.5576e-01]]])2. Decoder Between the feature sequence and the target sequence Mask
This part of mask The areas in the structure diagram corresponding to the code are as follows . This part mask It involves target sequence and feature sequence , In the calculation self-attention when , yes Of the target sequence query And characteristic sequences key、value Do calculations . among key and value yes Encoder Output ,query It's the last one DecoderBlock Output .
First Construct a feature sequence and a target sequence respectively , The first sentence in the feature sequence has 2 Word , The second sentence has 4 Word ; The first sentence in the target sequence has 3 Word , The second sentence has 5 Word .
Next, we need to unify the length of feature sequence and target sequence , Fill all sentences of the feature sequence with 4 Word , All sentences in the target sequence are filled with 5 Word . The elements of the valid word area are used 1 To express ,padding The elements of the are 0 To express .
The code is as follows :
# Decoder Partial target sequence vs. characteristic sequence muti-head-attention Medium mask
# The length between the target sequence and the feature sequence is different , You need to neutralize the original sequence with the target sequence padding Element after mask fall
import torch
from torch import nn
from torch.nn import functional as F
# ------------------------------------------------------ #
#(1) Tectonic sequence
# ------------------------------------------------------ #
src_len = torch.Tensor([2,4]).to(torch.int32) # There are two sentences in the feature sequence , Each contains 2、4 Word
tgt_len = torch.Tensor([3,5]).to(torch.int32) # There are two sentences in the target sequence , Each contains 3、5 Word
# Encode the sequence , The elements of valid word positions are 1
valid_src_pos = [torch.ones(L) for L in src_len] # Characteristic sequence [tensor([1., 1.]), tensor([1., 1., 1., 1.])]
valid_tgt_pos = [torch.ones(L) for L in tgt_len] # Target sequence [tensor([1., 1., 1.]), tensor([1., 1., 1., 1., 1.])]
# It is necessary to ensure that the length of the feature sequence is consistent with that of the target sequence , So count the words in each sentence padding In the same length
max_src_len = max(src_len) # Unify the number of words in the feature sequence into 4 individual
max_tgt_len = max(tgt_len) # Unify the number of words in the target sequence into 5 individual
new_valid_pos = [] # preservation padding Feature sequence and target sequence after
for sent in valid_src_pos: # Traverse each characteristic sentence
sent = F.pad(sent, pad=(0, max_src_len - len(sent))) # Fill the length of each sentence to 4
sent = torch.unsqueeze(sent, dim=0) # Dimension expansion [max_src_len]==>[1, max_src_len]
new_valid_pos.append(sent)
for sent in valid_tgt_pos: # Traverse each target sentence
sent = F.pad(sent, pad=(0, max_tgt_len - len(sent))) # Fill the length of each sentence to 5
sent = torch.unsqueeze(sent, dim=0) # Dimension expansion [max_tgt_len]==>[1, max_tgt_len]
new_valid_pos.append(sent)
# The first two sentences belong to the feature sequence , The last two sentences belong to the target sequence . Set the list type to axis=0 Stack on dimensions
valid_src_pos = torch.cat(new_valid_pos[:2], dim=0) # tensor([[1., 1., 0., 0.], [1., 1., 1., 1.]])
valid_tgt_pos = torch.cat(new_valid_pos[2:], dim=0) # tensor([[1., 1., 1., 0., 0.], [1., 1., 1., 1., 1.]])
# ------------------------------------------------------ #
#(2) structure mask
# Q @ K^T Of shape by [batch, tgt_seq_len, src_seq_len]
# therefore mask Of shape Also for the [batch, tgt_seq_len, src_seq_len]
# ------------------------------------------------------ #
# Effective feature sequence [2,4]==>[2,4,1], Valid target sequence [2,5]==>[2,5,1]
valid_src_pos = torch.unsqueeze(valid_src_pos, dim=-1) # The value is 1 The element of represents a valid word , The value is 0 The element of represents padding Rear area
valid_tgt_pos = torch.unsqueeze(valid_tgt_pos, dim=-1)
# Calculate the matrix of the effectiveness relationship between the target sequence and the characteristic sequence , Element is 0 Representative is padding Words after
# [b, tgt_seq_len, 1] @ [b, 1, src_seq_len] = [b, tgt_seq_len, src_seq_len]
valid_cross_pos_matrix = torch.bmm(valid_tgt_pos, valid_src_pos.transpose(1,2))
print(' Effective relation matrix :', valid_cross_pos_matrix) # torch.Size([2, 5, 4])
# Get invalid matrix ,1 Representative needs mask The elements of , Become boolean type ,True Representative needs mask The elements of
invalid_cross_pos_matrix = 1 - valid_cross_pos_matrix
invalid_cross_pos_matrix = invalid_cross_pos_matrix.to(torch.bool)
print('mask matrix :', invalid_cross_pos_matrix) # torch.Size([2, 5, 4])
# ------------------------------------------------------ #
#(3) Do... On the input tensor mask
# ------------------------------------------------------ #
# Randomly initialize a Q @ K^T Calculated results of [batch, tgt_seq_len, src_seq_len]
score = torch.randn(2, 5, 4)
# mask in True Element corresponding score The element value in becomes a very small number
masked_score = torch.masked_fill(score, mask=invalid_cross_pos_matrix, value=-1e10)
print(' Original input :', score)
print(' In the play mask After the input :', masked_score)Next structure mask, its shape Is and [email protected]^T Of the calculated matrix shape identical , namely [batch, tgt_seq_len, src_seq_len], among tgt_seq_len representative Target sequence How many words does each sentence contain ,src_seq_len representative Characteristic sequence How many words does each sentence contain .
Below The first matrix representative Calculate the relation matrix between the target sequence and the characteristic sequence , Element is 1 Represents valid words ,0 The representative is after padding Words obtained after .
Then calculate a Invalid region matrix , Will all padding The obtained pixel value of the word area becomes True, Represents that this element needs to be mask fall . As shown in the second matrix below .
Then construct a and self-attention in [email protected]^T The result of the calculation is shape Same input source, As the third matrix below .
then For input source add to mask, take mask Medium element True Corresponding source Element becomes a very small value , So in the process of gradient back propagation padding The element gradient update of is very small , Reduce padding The influence of region on effective word region . As shown in the fourth matrix below .
# Effective relation matrix :
tensor([[[1., 1., 0., 0.],
[1., 1., 0., 0.],
[1., 1., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
# mask matrix :
tensor([[[False, False, True, True],
[False, False, True, True],
[False, False, True, True],
[ True, True, True, True],
[ True, True, True, True]],
[[False, False, False, False],
[False, False, False, False],
[False, False, False, False],
[False, False, False, False],
[False, False, False, False]]])
# Original input :
tensor([[[ 1.4030, -0.0176, -2.9678, -0.5551],
[ 2.6138, -0.8088, 0.6641, -0.0128],
[-0.0370, -0.3206, -0.6634, 0.3626],
[ 1.1978, 1.9831, -0.3541, -0.8766],
[ 0.0655, 0.4267, -0.3459, 1.8217]],
[[-0.2351, -1.3515, 0.4783, -0.9379],
[ 0.2302, -1.5482, -0.0825, 1.0711],
[-0.3793, -0.9595, 0.9457, -1.5746],
[ 0.3685, 1.1116, -2.3528, -0.3916],
[-1.2416, 0.9410, -0.5407, 0.8035]]])
# In the play mask After the input :
tensor([[[ 1.4030e+00, -1.7624e-02, -1.0000e+10, -1.0000e+10],
[ 2.6138e+00, -8.0884e-01, -1.0000e+10, -1.0000e+10],
[-3.7038e-02, -3.2057e-01, -1.0000e+10, -1.0000e+10],
[-1.0000e+10, -1.0000e+10, -1.0000e+10, -1.0000e+10],
[-1.0000e+10, -1.0000e+10, -1.0000e+10, -1.0000e+10]],
[[-2.3507e-01, -1.3515e+00, 4.7825e-01, -9.3789e-01],
[ 2.3023e-01, -1.5482e+00, -8.2474e-02, 1.0711e+00],
[-3.7931e-01, -9.5949e-01, 9.4568e-01, -1.5746e+00],
[ 3.6855e-01, 1.1116e+00, -2.3528e+00, -3.9157e-01],
[-1.2416e+00, 9.4099e-01, -5.4066e-01, 8.0347e-01]]])边栏推荐
- What does ft mean in the data book table
- How keil displays Chinese annotations (simple with pictures)
- 嵌入式系统开发笔记80:应用Qt Designer进行主界面设计
- Procurement intelligence is about to break out, and Alipay'3+2'system helps enterprises build core competitive advantages
- 208. implement trie (prefix tree)
- Knowledge supplement: basic usage of redis based on docker
- 盘点华为云GaussDB(for Redis)六大秒级能力
- The problem of integrating Alibaba cloud SMS: non static methods cannot be referenced from the static context
- Libevent Library Learning
- [TA frost wolf \u may- hundred people plan] 1.2.1 vector basis
猜你喜欢

MallBook:后疫情时代下,酒店企业如何破局?
![[ta - Frost Wolf May - 100 people plan] 2.3 Introduction aux fonctions communes](/img/be/325f78dee744138a865c13d2c20475.png)
[ta - Frost Wolf May - 100 people plan] 2.3 Introduction aux fonctions communes
![[send email with error] 535 error:authentication failed](/img/58/8cd22fed1557077994cd78fd29f596.png)
[send email with error] 535 error:authentication failed
Go learning --- unit test subtest

283. move zero

“目标检测“+“视觉理解“实现对输入图像的理解

采购数智化爆发在即,支出宝'3+2'体系助力企业打造核心竞争优势

In the innovation community, the "100 cities Tour" of the gold warehouse of the National People's Congress of 2022 was launched

【人话版】WEB3黑暗森林中的隐私博弈
![[TA frost wolf \u may- hundred talents plan] 1.2.2 matrix calculation](/img/49/173b1f1f379faa28c503165a300ce0.png)
[TA frost wolf \u may- hundred talents plan] 1.2.2 matrix calculation
随机推荐
JMeter学习笔记2-图形界面简单介绍
[untitled]
[TA frost wolf \u may - "hundred people plan"] 2.1 color space
The problem of integrating Alibaba cloud SMS: non static methods cannot be referenced from the static context
JMeter login failure, extracting login token, and obtaining token problem solving
Programs and processes, process management, foreground and background processes
Concurrent mode of different performance testing tools
72. edit distance
Analysis and case of pageobject mode
LetCode 1829. Maximum XOR value per query
[EI search] important information conference of the 6th International Conference on materials engineering and advanced manufacturing technology (meamt 2022) in 2022 website: www.meamt Org meeting time
Jenkins automatically cleans up construction history
Redis(七)优化建议
[ta- frost wolf \u may- hundred people plan] 1.1 rendering pipeline
Unity之三维空间多点箭头导航
Class and object finalization
Valid @suppresswarnings warning name
ThreeJS开篇
Huawei simulator ENSP - hcip - Hybrid Experiment 2
[ta- frost wolf \u may- hundred people plan] 2.2 model and material space