当前位置:网站首页>深度学习基础汇总
深度学习基础汇总
2022-06-28 15:15:00 【右边是我女神】
文章目录
神经网络
模型的发展历程
MP模型是最早的神经网络模型,描述的是一个神经元的工作机制。根据神经元的结构可知:神经元是一个多输入单输出的信息处理单元,并对信息的处理是非线性的。在这个基础上,MP模型应运而生: y = f ( Σ i w i x i + b ) y=f(\Sigma_{i}w_ix_i+b) y=f(Σiwixi+b)
其中, f f f是激活函数。
感知机模型与MP模型十分类似,其 f f f采用了符号函数。
多重感知机模型(MLP)则是神经元的组合与叠加。
前馈神经网络
前馈神经网络是人工神经网络的一种形式,各神经元分层排列,每个神经元只与前一层神经元相连,接收前一层的输出,并输出给下一层,各层间没有反馈。
前馈神经网络又称为全连接神经网络,MLP、BP神经网络就属于常见的前馈神经网络之一。

激活函数
参考这篇文章,包含Sigmoid、Tanh、ReLU、LReLU、ELU、PReLU、Softmax、Swish。总结如下:
| 损失函数 | 优点 | 缺点 |
|---|---|---|
| Sigmoid | 1. 适合于概率预测模型;2. 连续函数,易于求导 | 1. 容易造成梯度消失; 2. 非0均值; 3. 涉及指数运算,计算机计算效率低 |
| Tanh | 1. 0均值 | 1. 容易造成梯度消失; 2. 涉及指数运算,计算机计算效率低 |
| ReLU | 1. 在 x > 0 x\gt0 x>0的区域上,不会出现梯度饱和;2. 计算速度快; | 1. 输入负数时,梯度为0(Dead ReLU);2. 非0均值; |
| LReLU | 1. 解决Dead ReLU问题; 2. 继承ReLU的所有优; | 1. 继承ReLU的其他缺点 |
| ELU | 1. 解决Dead ReLU问题; 2. 接近0均值; 3. 正常梯度接近于自然梯度; 4. 较小输入下趋于饱和,从而对噪声具有鲁棒性 | 1. 计算强度大 |
| PReLU | 1. 继承LReLU的优点; 2. 参数可学习 | 1. 继承LReLU的缺点 |
| Softmax | 1. 适合于多分类的概率预测模型;2. argmax的近似平滑 | 1. 当输入的方差比较大时,会输出一个接近one-hot的形式,进一步造成了梯度弥散问题 |
| Swish | - | - |
Q1:Sigmoid并不是0均值的,为什么这是一个缺点?
可以参考这篇文章。简而言之,所有参数更新方向一致,产生Z型更新现象,使得收敛速度变缓。
Q2:什么是梯度弥散?
源于激活函数的饱和,一旦落入函数的饱和区域,梯度变得非常小。
Q3:Swish的函数形式?
f ( x ) = x ⋅ s i g m o i d ( β x ) f(x)=x\cdot sigmoid(\beta x) f(x)=x⋅sigmoid(βx)
介于线性函数和ReLU函数的平滑函数。
反向传播算法
梯度下降法属于最优化算法,是迭代法的一种,可以用于求解最小二乘问题(线性/非线性)。其公式为: x = x − γ ⋅ ∇ x = x - \gamma\cdot \nabla x=x−γ⋅∇
反向传播算法是一种适合于多层神经元网络的学习算法,建立在梯度下降法的基础上。
前馈神经网络的输入和输出关系实质上是一种映射,其信息处理能力来源于简单非线性函数的多次复合。这是BP算法得以应用的基础。
BP算法由正向传播过程和反向传播过程组成。正向传播过程中,输入信息通过输入层经隐含层,逐层处理并传向输出层。取损失函数作为目标函数,转入反向传播,逐层求出目标函数对各神经元权值的偏导数,构造目标函数对权值向量的梯量,作为修改权值的依据。最后进行权重的更新,误差达到所期望值时,学习结束。
梯量的构造遵循链式求导法则,权重的更新遵循梯度下降法。
反向传播的精髓就是梯度!其中的梯度(反映了该变量的变化对目标函数的影响)也大有学问,详细可以参考这份视频。
BP算法依赖于计算图,其举例如下所示:
也就是说,在实际算法执行过程中,会求出下一结点对当前结点的梯量,在反向传播的过程中执行链式求导法则,进行梯量的相乘与值的代入。
自动微分是一种计算机求导方式,其分为前向模式和反向模式。以函数 f = g ( h ( x ) ) f=g(h(x)) f=g(h(x))为例,其导数为 d f d x = d g d h d h d x \frac{df}{dx}=\frac{dg}{dh}\frac{dh}{dx} dxdf=dhdgdxdh前向模式指的是从右到左地计算导数(计算每一层的状态[函数]和激活值的同时把该结点对变量的偏导数也一并计算),反向模式则相反(与反向传播算法的计算梯度的方式相同:前向计算每一层的状态和激活值;反向计算每一层的参数的偏导数,即目标函数与当前变量的偏导数)。
关于自动微分可以参考这份视频。
这一过程中会构建计算图:静态(构建完成后不再改变)与动态(根据函数结构实时调整)。
模型的训练
数据归一化
归一化的作用:统一模型数量级。
归一化的好处有:便于后续数据处理;加快模型收敛。
这是因为数量级大会带来两个问题:震荡大,模型不稳定;收敛时间长。
常见的方法有:min-max标准化和Z-score。
x ∗ = x − m i n m a x − m i n x^*=\frac{x-min}{max-min} x∗=max−minx−min
x ∗ = x − μ σ x^*=\frac{x-\mu}{\sigma} x∗=σx−μ
这里的归一化是针对初始数据的。
参数初始化
参数初始化的作用在于加快梯度下降收敛的速度。
对称权重问题:如果某一层有K个隐藏单元,其参数矩阵的值都是N,那么这K个映射都是相同的,那么这样一个具有很多隐藏单元的网络结构就是完全多余的表达,最终网络只能学习到一种特征。
解决这一问题的方法为随机初始化。
常见且简单的随机初始化方式有高斯初始化、均匀分布初始化。
这两个初始化方式也有缺陷:
- 方差过小且权重集中在0附近,如果采用Sigmoid函数会造成梯度爆炸的问题;
- 方差过大,如果采用Sigmoid函数会造成梯度消失问题。
总而言之,就是权重随机得不均匀。
相应的解决方案有方差缩放与正交初始化(高斯初始化+奇异值分解)。
损失函数
参考这篇文章的总结。
常见的有:01损失函数、绝对值损失函数、对数损失函数、平方损失函数、指数损失函数、合页损失函数、感知损失函数、交叉熵损失函数、Focal损失函数。
说明:
- 绝对值损失函数和平方损失函数常用于回归问题,但是对噪声敏感、鲁棒性不强;
- 对数损失函数就是将置信度取个对数的负数,用于逻辑回归,对噪声敏感、鲁棒性不强;
- 指数损失函数用于Adaboost,对噪声敏感、鲁棒性不强;
- 合页损失函数用于SVM,其不仅要求分类正确,更要求有一定可信度,对噪声不敏感、鲁棒性强;
- 感知损失函数把1去掉了,弱化了合页损失函数对可信度的要求;
- 谈到交叉熵损失函数,就必须要谈及KL散度,或者说相对熵,其度量了两个分布之间的差距,公式为 D K L ( p ∣ ∣ q ) = ∑ i p ( x i ) log p ( x i ) q ( x i ) D_{KL}(p||q)=\sum_{i}p(x_i)\log\frac{p(x_i)}{q(x_i)} DKL(p∣∣q)=i∑p(xi)logq(xi)p(xi)进一步化简可以得到信息熵与交叉熵之和,交叉熵可以说是体现KL散度的一个简化版本。
- 聚焦损失函数是交叉熵损失函数的增强版本,其目的是自适应地使模型关注困难样本,潜在地解决了正负样本不平衡问题。
模型优化
所谓模型优化,是找到一个参数,使得经验风险/结构风险最小化。
传统机器学习常常面对的是一个凸优化问题。而深度学习所面对的是非凸优化问题。直观来看,两者的区别如下:
优化的难点有:参数多,影响训练;非凸优化求解;梯度消失;参数难以解释。
直观来看,优化的过程是在损失函数的曲面上找到一个最优位置。然而损失函数的曲面通常是很复杂的。可视化来看如下所示。

所谓梯度消失,指的是落入了曲面当中的某一平坦区域。另外,在这一曲面上训练也很容易陷入局部最优的境地。
值得一提的是跳跃连接能够使曲面光滑。
常见的优化算法可以参考这篇文章,主要介绍了BGD、SGD、MBGD、SGD+Momentum、Nesterov加速梯度、AdaGrad、AdaDelta、RMSprop、Adam。
说明:
- BGD、SGD、MBGD都是梯度下降法,不过是计算梯度的依据不一样,分别为全部训练集、某一个样本以及某一堆样本;
- Momentum的更新公式还是梯度下降法,不过那个导数需要加上上一时刻的导数;
- Adagrad、AdaDelta、RMSprop、Adam都是自适应算法,是对梯度的一个动态调整;
- Adagrad只是将梯度除上了 ∑ i = 1 t g t 2 + ϵ \sqrt{\sum_{i=1}^tg_t^2+\epsilon} ∑i=1tgt2+ϵ,好处在于前期分母小,速度快,后期分母大,速度慢;
- AdaDelta不再是简单地求了个梯度的平方和,而是加权的 n t = v × n t − 1 + ( 1 − v ) × g t 2 n_t=v\times n_{t-1}+(1-v)\times g_t^2 nt=v×nt−1+(1−v)×gt2;此外,AdaDelta还把学习率换成了 ρ E [ Δ θ ] t − 2 + ( 1 − ρ ) Δ θ t − 1 2 \rho E[\Delta\theta]_{t-2}+(1-\rho)\Delta\theta_{t-1}^2 ρE[Δθ]t−2+(1−ρ)Δθt−12,这样就没必要考虑学习率了,自己学就完事了。
- RMSprop是AdaDelta的简化版本,保留了原始的学习率;
- Adam就是带有动量项的RMSprop;
数据增广/模型泛化
有助于防止过拟合,增强泛化能力。
常见的手段有:平移、翻转、缩放、旋转、加噪声、聚焦。
模型过拟合是常见的问题,解决手段有两种:数据层面与算法层面。数据层面使用数据增强,算法层面使用正则化、dropout、BN、早期终止、权重衰减等。
卷积神经网络
卷积神经网络的特点是:
- 局部连接;
- 权值共享;
- 平移不变性。
1和2解决了FCN中参数过多的问题;
卷积核
卷积的运算与"*"的操作(翻转、平移、点乘)差不多,但是深度学习中的卷积省略的翻转的操作。
传统卷积的数值是固定的,比如Sobel算子、Gaussian算子等,目的都是为了对图像提取特定的特征或者操作。深度学习中的卷积侧重于特征的提取,不过其值变得可以学习。
接下来我们介绍一下卷积的基本参数和简单的数值计算。
- 卷积核大小k;
- 步长s;
- 填充p;
- 膨胀因子d;
尺寸计算:
W o u t = W i n + 2 p − k s + 1 , H 同 理 W_{out}=\frac{W_{in}+2p-k}{s}+1,H同理 Wout=sWin+2p−k+1,H同理
如果我们引入膨胀因子,那么核的大小为 k ′ = d × ( k − 1 ) + 1 k'=d\times(k-1)+1 k′=d×(k−1)+1;
参数量计算:
N = ( k × k × C i n + 1 ) × C o u t N = (k\times k\times C_{in}+1)\times C_{out} N=(k×k×Cin+1)×Cout
激活层和池化层
激活层就是常见的激活函数;
池化层的话常见的有的最大池化和平均池化。
池化层没有padding一说,所以其尺寸计算公式为 W o u t = W i n − k s + 1 W_out=\frac{W_{in}-k}{s}+1 Wout=sWin−k+1
值得一提的是池化层的参数量为0。
卷积层、激活层、池化层构成了卷积神经网络的基本结构
常见的CNN模型有LeNet、AlexNet、GoogleNet、VGG、ResNet…
循环神经网络
传统的前馈神经网络在处理序列化数据时的缺陷有:
- 输入需要是一个特定大小的数据,输出同理,这样的限制过于严格;
- 记忆性弱,对上下文信息的考虑不足;
RNN

每个时间步的参数是共享的。一方面是为了降低参数量,另一方面也是为了实现序列上的平移不变性。
常见的RNN结构有:
- 音乐生成是One2Many的,每一层的输出还会作为下一层的输入;
- 情感分类是Many2One的,很标准的结构;
- 命名实体识别是Many2Many(2)的,很标准的结构;
- 机器翻译是Many2Many(1)的,其结构如下所示,该模型又称为Seq2Seq/Encoder-Decoder:

BPTT(随时间反向传播)
因为每一时间步用了一样的参数,所以以Many2Many的模型为例,需要对每一时间步下的参数求导并求和。
以第三时间步为例,公式为:

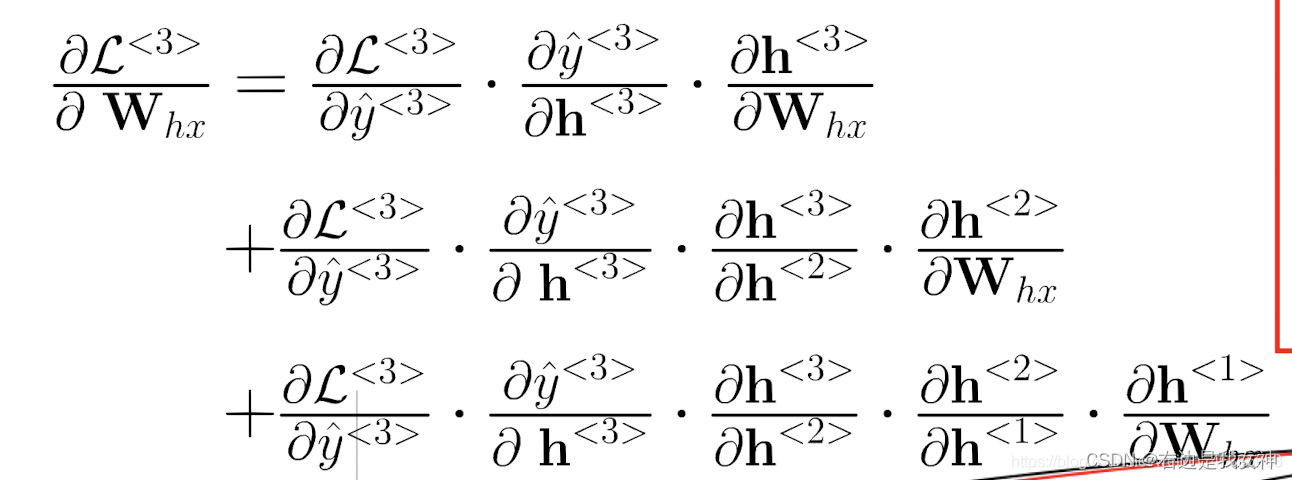
可以看到,无论是对哪一个参数求导,本质上是隐藏层之间的导数的连乘在递增。这很容易会导致梯度的消失或者爆炸。
这就是所谓的长程依赖问题(梯度消失/爆炸),从数学上来看,本质是激活函数处于饱和或者0附近。
我认为梯度消失发生的可能性更大一些,因为每一个神经元中的数是不断累加的,这很容易造成值的增大,进一步导致激活函数处于饱和。直观来看就是记忆达到容量上限。
LSTM
下图应该是One2Many类型的,因为没有额外的输入。
另一种表示方法为:
说明:
- 上一时间步的输入参与到了三个门与当前初始记忆单元的计算当中;
- 来了一个输入之后是先要转化为记忆单元,再与门函数有之后的故事。
为什么LSTM能解决梯度消失的问题?
梯度消失的本质原因是因为记忆单元值太大,使得激活函数趋于饱和。LSTM实现了记忆单元的更新,保证了其不会太大。直观上来理解,是因为记忆会有遗忘。
GRU

可以看到无论是GRU还是LSTM的门的计算都是隐藏状态与输入的共同计算。
候选隐藏状态的计算用到了重置门,控制了上一时刻隐藏状态和这一时刻状态的比例关系;
隐藏状态的计算用到了更新门,是一种对当前时刻状态和候选隐藏状态的折中。
GRU和LSTM的性能差不多,区别在于其参数量稍微小一些。
迁移学习
迁移学习指的是能在一个任务上学习一个模型,然后用其来解决相关的别的任务。
迁移学习在深度学习领域发挥了很大的作用,因为网络往往需要很多的数据,代价很高。
迁移学习的途径有三项:
- 训练一个特征提取模块,文本领域的WordVec、图像领域的ResNet、视频领域的I3D(然后用这些数据做下游任务);
- 在一个相关任务上训练一个模型,然后在另一个任务进行微调。
常见的应用领域有:
- 半监督学习;
- 小样本学习;
- 多任务学习;
相同任务,不同领域;相同领域,不同任务。
CV中存在很多大规模的数据集,我们希望在这些数据上训练出一些模型,将它们的知识拓展到目标任务重,这就是迁移学习要做的事情。
通常而言,神经网络被分为两部分:编码器(特征提取)与解码器(决策)。
常见的手段是预训练模型+微调。
所谓预训练模型就是将在别的地方训练好的数据初始化目前这个模型(解码器部分保持随机初始化,因为label不一致)。
微调就是更新这个模型的一部分参数。我们一般认为初始的结果会是在解的附近,所以一般会限制训练的程度,常见的手段有三种:
- 缩小部分层训练的epoch和learning_rate;
- 将部分层freeze;
- 训练的时候增加一些约束:输出接近/参数接近(保守学习)。
值得一提的是,对于第二种方法,因为神经网络通常是层次化的,最底层学到的是相对底层的特征,上层与语义相关,所以可以考虑下面层直接freeze。
其实迁移学习本质上来说只是能够加快模型的收敛。之所以能提高一点精度,是因为预训练模型中学习到的东西比目前任务用到的小数据集能学习的多,如果目前任务的数据集也比较大的话,精度的提升就不明显了。
边栏推荐
- 雷科防务:4D毫米波雷达产品预计可以在年底量产供货
- 抽奖动画 - 鲤鱼跳龙门
- After QQ was stolen, a large number of users "died"
- 智慧园区数智化供应链管理平台如何优化流程管理,驱动园区发展提速增质?
- Facebook出手!自适应梯度打败人工调参
- sent2vec教程
- What! 一条命令搞定监控?
- C#/VB.NET 将PDF转为Excel
- seata-server 1.5.0 如何支持mysql8.0?
- Oracle11g database uses expdp to back up data every week and upload it to the backup server
猜你喜欢

Express template engine

Power battery is divided up like this

WPF 视频硬解码渲染播放(无空域)(支持4K、8K、高帧率视频)

GCC efficient graph revolution for joint node representationlearning and clustering

What! 一条命令搞定监控?

SAP MTS/ATO/MTO/ETO专题之九:M+M模式前后台操作,策略用50,提前准备原材料和半成品

环保产品“绿色溢价”高?低碳生活方式离人们还有多远

MIPS assembly language learning-01-sum of two numbers, environment configuration and how to run
MIPS assembly language learning-03-cycle

信创操作系统--麒麟Kylin桌面操作系统 (项目十 安全中心)
随机推荐
Facebook! Adaptive gradient defeats manual parameter adjustment
What! 一条命令搞定监控?
当下不做元宇宙,就像20年前没买房!
Validate palindrome string
Technical trendsetter
浪潮网络步步为赢
How can I get the stock account opening discount link? Is it safe to open a mobile account?
How can the digital intelligent supply chain management platform of the smart Park optimize process management and drive the development of the park to increase speed and quality?
Oracle11g database uses expdp to back up data every week and upload it to the backup server
利用MySqlBulkLoader实现批量插入数据的示例详解
开源大咖说 - Linus 与 Jim 对话中国开源
How to solve the following problems in the Seata database?
叮!Techo Day 腾讯技术开放日如约而至!
Facebook出手!自适应梯度打败人工调参
Fleet |「後臺探秘」第 3 期:狀態管理
雷科防务:4D毫米波雷达产品预计可以在年底量产供货
R language ggplot2 visualization: use the patchwork package (directly use the plus sign +) to horizontally combine a ggplot2 visualization result and a plot function visualization result to form a fin
How to solve the following problems in the Seata database?
High "green premium" of environmental protection products? How far is the low-carbon lifestyle from people
字节跳动数据平台技术揭秘:基于 ClickHouse 的复杂查询实现与优化