当前位置:网站首页>4. Data splitting of Flink real-time project
4. Data splitting of Flink real-time project
2022-07-02 15:16:00 【u012804784】
Python Wechat ordering applet course video
https://edu.csdn.net/course/detail/36074
Python Actual quantitative transaction financial management system
https://edu.csdn.net/course/detail/35475
1. Abstract
The log data we collected earlier has been saved to Kafka in , As log data ODS layer , from kafka Of ODS The log data read by the layer is divided into 3 class , Page log 、 Start log and exposure log . Although these three types of data are user behavior data , But it has a completely different data structure , So we need to split it . Write the split logs back to Kafka In different topics , As log DWD layer .
The page log is output to the main stream , The startup log is output to the startup side output stream , The exposure log is output to the exposure side output stream
2. Identify new and old users
The client business itself has the identification of new and old users , But it's not accurate enough , Need to reconfirm with real-time calculation ( Business operations are not involved , Just make a simple status confirmation ).
Data splitting is realized by using side output stream
According to the content of log data , Divide the log data into 3 class : Page log 、 Start log and exposure log . Push the data of different streams to the downstream kafka Different Topic in
3. Code implementation
In the bag app Create flink Mission BaseLogTask.java,
adopt flink consumption kafka The data of , Then record the consumption checkpoint Deposit in hdfs in , Remember to create the path manually , Then give the authority
checkpoint Optional use , You can turn it off during the test .
package com.zhangbao.gmall.realtime.app;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* @author: zhangbao
* @date: 2021/6/18 23:29
* @desc:
**/
public class BaseLogTask {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Set parallelism , namely kafka Partition number
env.setParallelism(4);
// add to checkpoint, Every time 5 Once per second
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY\_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/baseLogAll"));
// Specify which user reads hdfs file
System.setProperty("HADOOP\_USER\_NAME","zhangbao");
// Add data sources
String topic = "ods\_base\_log";
String group = "base\_log\_app\_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, group);
DataStreamSource<String> kafkaDs = env.addSource(kafkaSource);
// Convert the format
SingleOutputStreamOperator<JSONObject> jsonDs = kafkaDs.map(new MapFunction<String, JSONObject>() {
@Override
public JSONObject map(String s) throws Exception {
return JSONObject.parseObject(s);
}
});
jsonDs.print("json >>> --- ");
try {
// perform
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
MyKafkaUtil.java Tool class
package com.zhangbao.gmall.realtime.utils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
/**
* @author: zhangbao
* @date: 2021/6/18 23:41
* @desc:
**/
public class MyKafkaUtil {
private static String kafka_host = "hadoop101:9092,hadoop102:9092,hadoop103:9092";
/**
* kafka consumer
*/
public static FlinkKafkaConsumer<String> getKafkaSource(String topic,String group){
Properties props = new Properties();
props.setProperty(ConsumerConfig.GROUP\_ID\_CONFIG,group);
props.setProperty(ConsumerConfig.BOOTSTRAP\_SERVERS\_CONFIG,kafka_host);
return new FlinkKafkaConsumer<String>(topic, new SimpleStringSchema(),props);
}
}
4. New and old visitor status repair
Rules for identifying new and old customers
Identify new and old visitors , The front end will record the status of new and old customers , Maybe not , Here again , preservation mid State of one day ( Save first visit date as status ), Wait until there is a log in the back equipment , Get the date from the status and compare the log generation date , If the status is not empty , And the status date is not equal to the current date , It means it's a regular visitor , If is_new Mark is 1, Then repair its state .
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @author: zhangbao
* @date: 2021/6/18 23:29
* @desc:
**/
public class BaseLogTask {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Set parallelism , namely kafka Partition number
env.setParallelism(4);
// add to checkpoint, Every time 5 Once per second
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY\_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/baseLogAll"));
// Specify which user reads hdfs file
System.setProperty("HADOOP\_USER\_NAME","zhangbao");
// Add data sources , Come here kafka The data of
String topic = "ods\_base\_log";
String group = "base\_log\_app\_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, group);
DataStreamSource<String> kafkaDs = env.addSource(kafkaSource);
// Convert the format
SingleOutputStreamOperator<JSONObject> jsonDs = kafkaDs.map(new MapFunction<String, JSONObject>() {
@Override
public JSONObject map(String s) throws Exception {
return JSONObject.parseObject(s);
}
});
jsonDs.print("json >>> --- ");
/**
* Identify new and old visitors , The front end will record the status of new and old customers , Maybe not , Here again
* preservation mid State of one day ( Save first visit date as status ), Wait until there is a log in the back equipment , Get the date from the status and compare the log generation date ,
* If the status is not empty , And the status date is not equal to the current date , It means it's a regular visitor , If is\_new Mark is 1, Then repair its state
*/
// according to id Group logs
KeyedStream<JSONObject, String> midKeyedDs = jsonDs.keyBy(data -> data.getJSONObject("common").getString("mid"));
// New and old visitor status repair , States are divided into operator States and keyed states , Here we record the status of a certain device , Using keyed state is more appropriate
SingleOutputStreamOperator<JSONObject> midWithNewFlagDs = midKeyedDs.map(new RichMapFunction<JSONObject, JSONObject>() {
// Definition mid state
private ValueState<String> firstVisitDateState;
// Define date formatting
private SimpleDateFormat sdf;
// Initialization method
@Override
public void open(Configuration parameters) throws Exception {
firstVisitDateState = getRuntimeContext().getState(new ValueStateDescriptor<String>("newMidDateState", String.class));
sdf = new SimpleDateFormat("yyyyMMdd");
}
@Override
public JSONObject map(JSONObject jsonObject) throws Exception {
// Get current mid state
String is_new = jsonObject.getJSONObject("common").getString("is\_new");
// Get the current log timestamp
Long ts = jsonObject.getLong("ts");
if ("1".equals(is_new)) {
// Visitor date status
String stateDate = firstVisitDateState.value();
String nowDate = sdf.format(new Date());
if (stateDate != null && stateDate.length() != 0 && !stateDate.equals(nowDate)) {
// It's an old guest
is_new = "0";
jsonObject.getJSONObject("common").put("is\_new", is_new);
} else {
// New visitors
firstVisitDateState.update(nowDate);
}
}
return jsonObject;
}
});
midWithNewFlagDs.print();
try {
// perform
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
5. Data splitting is realized by using side output stream
After the above new and old customers repair , Then divide the log data into 3 class
Start log label definition :OutputTag startTag = new OutputTag("start"){};
And exposure log label definitions :OutputTag displayTag = new OutputTag("display"){};
The page log is output to the main stream , The startup log is output to the startup side output stream , The exposure log is output to the exposure log side output stream .
The data is split and sent to kafka
- dwd_start_log: start log
- dwd_display_log: Exposure log
- dwd_page_log: Page log
package com.zhangbao.gmall.realtime.app;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @author: zhangbao
* @date: 2021/6/18 23:29
* @desc:
**/
public class BaseLogTask {
private static final String TOPIC\_START = "dwd\_start\_log";
private static final String TOPIC\_DISPLAY = "dwd\_display\_log";
private static final String TOPIC\_PAGE = "dwd\_page\_log";
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Set parallelism , namely kafka Partition number
env.setParallelism(4);
// add to checkpoint, Every time 5 Once per second
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/baseLogAll"));
// Specify which user reads hdfs file
System.setProperty("HADOOP\_USER\_NAME","zhangbao");
// Add data sources , Come here kafka The data of
String topic = "ods\_base\_log";
String group = "base\_log\_app\_group";
FlinkKafkaConsumer kafkaSource = MyKafkaUtil.getKafkaSource(topic, group);
DataStreamSource kafkaDs = env.addSource(kafkaSource);
// Convert the format
SingleOutputStreamOperator jsonDs = kafkaDs.map(new MapFunction() {
@Override
public JSONObject map(String s) throws Exception {
return JSONObject.parseObject(s);
}
});
jsonDs.print("json >>> --- ");
/**
* Identify new and old visitors , The front end will record the status of new and old customers , Maybe not , Here again
* preservation mid State of one day ( Save first visit date as status ), Wait until there is a log in the back equipment , Get the date from the status and compare the log generation date ,
* If the status is not empty , And the status date is not equal to the current date , It means it's a regular visitor , If is\_new Mark is 1, Then repair its state
*/
// according to id Group logs
KeyedStream midKeyedDs = jsonDs.keyBy(data -> data.getJSONObject("common").getString("mid"));
// New and old visitor status repair , States are divided into operator States and keyed states , Here we record the status of a certain device , Using keyed state is more appropriate
SingleOutputStreamOperator midWithNewFlagDs = midKeyedDs.map(new RichMapFunction() {
// Definition mid state
private ValueState firstVisitDateState;
// Define date formatting
private SimpleDateFormat sdf;
// Initialization method
@Override
public void open(Configuration parameters) throws Exception {
firstVisitDateState = getRuntimeContext().getState(new ValueStateDescriptor("newMidDateState", String.class));
sdf = new SimpleDateFormat("yyyyMMdd");
}
@Override
public JSONObject map(JSONObject jsonObject) throws Exception {
// Get current mid state
String is\_new = jsonObject.getJSONObject("common").getString("is\_new");
// Get the current log timestamp
Long ts = jsonObject.getLong("ts");
if ("1".equals(is\_new)) {
// Visitor date status
String stateDate = firstVisitDateState.value();
String nowDate = sdf.format(new Date());
if (stateDate != null && stateDate.length() != 0 && !stateDate.equals(nowDate)) {
// It's an old guest
is\_new = "0";
jsonObject.getJSONObject("common").put("is\_new", is\_new);
} else {
// New visitors
firstVisitDateState.update(nowDate);
}
}
return jsonObject;
}
});
// midWithNewFlagDs.print();
/**
* According to the content of log data , Divide the log data into 3 class , Page log 、 Start log and exposure log . Page log
* Output to the mainstream , The startup log is output to the startup side output stream , The exposure log is output to the exposure log side output stream
* Side output stream :1 Receive late data ,2 shunt
*/
// Define the label of the output stream on the startup side , Open parentheses to generate the corresponding type
OutputTag startTag = new OutputTag("start"){};
// Define the exposure side output stream label
OutputTag displayTag = new OutputTag("display"){};
SingleOutputStreamOperator pageDs = midWithNewFlagDs.process(
new ProcessFunction() {
@Override
public void processElement(JSONObject jsonObject, Context context, Collector collector) throws Exception {
String dataStr = jsonObject.toString();
JSONObject startJson = jsonObject.getJSONObject("start");
// Determine whether to start the log
if (startJson != null && startJson.size() > 0) {
context.output(startTag, dataStr);
} else {
// Determine whether to expose the log
JSONArray jsonArray = jsonObject.getJSONArray("displays");
if (jsonArray != null && jsonArray.size() > 0) {
// Add... To each exposure pageId
String pageId = jsonObject.getJSONObject("page").getString("page\_id");
// Traverse the output exposure log
for (int i = 0; i < jsonArray.size(); i++) {
JSONObject disPlayObj = jsonArray.getJSONObject(i);
disPlayObj.put("page\_id", pageId);
context.output(displayTag, disPlayObj.toString());
}
} else {
// If it's not the exposure log , Page log , Output to the mainstream
collector.collect(dataStr);
}
}
}
}
);
// Get side output stream
DataStream startDs = pageDs.getSideOutput(startTag);
DataStream disPlayDs = pageDs.getSideOutput(displayTag);
// Printout
startDs.print("start>>>");
disPlayDs.print("display>>>");
pageDs.print("page>>>");
/**
* Send the log data of different streams to the specified kafka The theme
*/
startDs.addSink(MyKafkaUtil.getKafkaSink(TOPIC\_START));
disPlayDs.addSink(MyKafkaUtil.getKafkaSink(TOPIC\_DISPLAY));
pageDs.addSink(MyKafkaUtil.getKafkaSink(TOPIC\_PAGE));
try {
// perform
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
边栏推荐
- List set & UML diagram
- LeetCode - 搜索二维矩阵
- AtCoder Beginner Contest 254
- Why can't programmers who can only program become excellent developers?
- C # delay, start the timer in the thread, and obtain the system time
- How to solve the problem of database content output
- MFC console printing, pop-up dialog box
- TiDB混合部署拓扑
- Topology architecture of the minimum deployment of tidb cluster
- Learn the method code of using PHP to realize the conversion of Gregorian calendar and lunar calendar
猜你喜欢

N皇后问题的解决
 [email protected] : The platform “win32“ is incompatible with this module."/>
[email protected] : The platform “win32“ is incompatible with this module."/>info [email protected] : The platform “win32“ is incompatible with this module.

关于网页中的文本选择以及统计选中文本长度
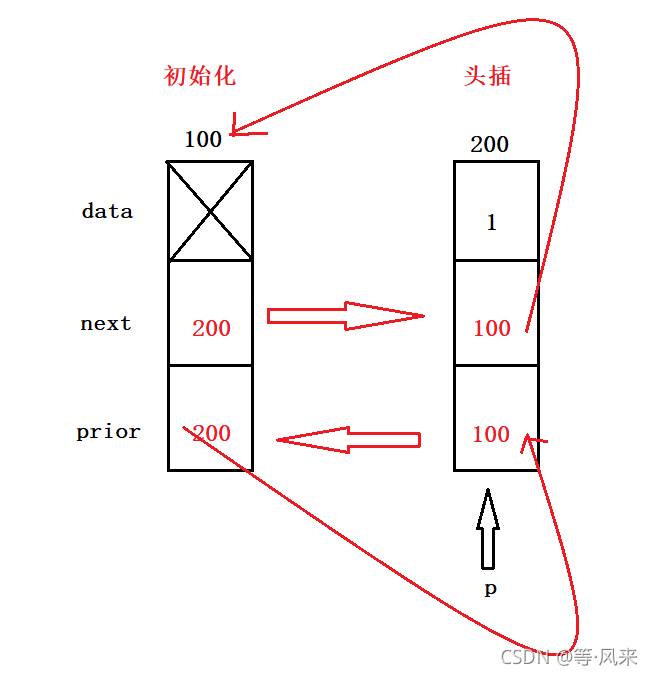
03_ Linear table_ Linked list

MFC timer usage
Dragonfly low code security tool platform development path

forEach的错误用法,你都学废了吗
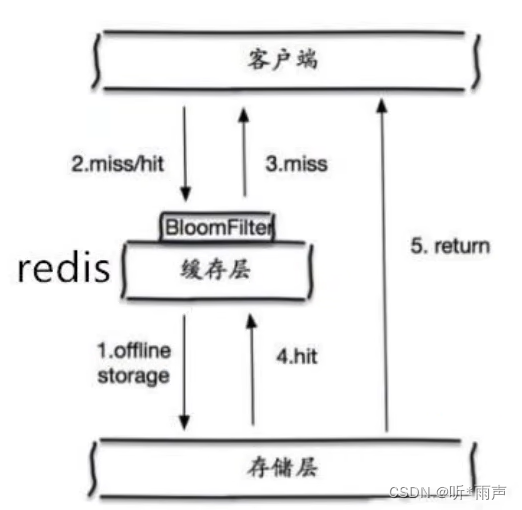
21_Redis_浅析Redis缓存穿透和雪崩

04_ Stack

可视化搭建页面工具的前世今生
随机推荐
TiDB跨数据中心部署拓扑
LeetCode 2310. The number of digits is the sum of integers of K
Printf function and scanf function in C language
Data analysis thinking analysis methods and business knowledge - business indicators
C language exercises - (array)
CodeCraft-22 and Codeforces Round #795 (Div. 2)D,E
Mfc a dialog calls B dialog function and passes parameters
05_ queue
Introduction to C language -- array
Key points of compilation principle examination in 2021-2022 academic year [overseas Chinese University]
[noi simulation] Elis (greedy, simulation)
TiDB 环境与系统配置检查
Dragonfly low code security tool platform development path
21_Redis_浅析Redis缓存穿透和雪崩
[untitled] leetcode 2321 Maximum score of concatenated array
Have you learned the wrong usage of foreach
21_ Redis_ Analysis of redis cache penetration and avalanche
Base64 编码原来还可以这么理解
07_ Hash
Some Chinese character codes in the user privacy agreement are not standardized, which leads to the display of garbled codes on the web page. It needs to be found and handled uniformly