当前位置:网站首页>Clickhouse learning (III) table engine
Clickhouse learning (III) table engine
2022-07-29 08:24:00 【Crying dogs in the sun】
Role of table engine
Watch engine ( That is, the type of the table ) To determine the :
- Decide where and how the table is stored
- What queries are supported and how to support
- Concurrent data access
- Use of index
- Can multithreaded requests be executed
- Copy data
Engine type
MergeTree
The most versatile and powerful table engine for high load tasks . The common feature of these engines is that they can quickly insert data and perform subsequent background data processing . MergeTree The series engine supports data replication ( Use Replicated* The engine version of ), Partitions and some other features that are not supported by other engines .
This type of engine :
- MergeTree
- ReplacingMergeTree
- SummingMergeTree
- AggregatingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- GraphiteMergeTree
journal
Lightweight engine with minimal functionality . When you need to write many small tables quickly ( At most 100 Line ten thousand ) And when reading them as a whole later , This type of engine is the most efficient .
This type of engine :
- TinyLog
- StripeLog
- Log
Integration engine
An engine for integration with other data storage and processing systems .
This type of engine :
- Kafka
- MySQL
- ODBC
- JDBC
- HDFS
Here are some common ones to explain , You need to know that other official documents are very detailed https://clickhouse.tech/docs/zh/engines/table-engines/
MergeTree
Clickhouse The most powerful watch engine among them is MergeTree ( Merge tree ) Engines and the series (*MergeTree) Other engines in , Supports indexing and partitioning .
Test data :
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');



partition by Partition ( Optional )
- Partitions are created through PARTITION BY expr Clause . The partitioning key can be any expression of a column in a table
- The purpose of partitioning is mainly to reduce the scanning range , Optimize query speed
- Path of partition data
/var/lib/clickhouse/data/default/ Table name- If no partition is specified, only one partition will be generated
Generate two partitions by date 
Generate two partition files under the partition path 
Insert new data information again , New partitions will be generated , It has not been merged yet 
Any batch of data writing will generate a temporary partition , Will not include any existing partitions . write in
At some point after ( Probably 10-15 Minutes later ),ClickHouse The merge operation will be performed automatically 
Merge partitions optimize table t_order_mt partition '20200601' final;

The first partition is merged with the third partition , The box represents the number of merges 
primary key Primary key ( Optional )
Provides a primary index of data , But it's not the only constraint . This means that there can be the same primary key Data. .

Its sorting method is to use sparse index , According to the conditions, the full table scan is avoided by performing some form of binary search on the primary key .
order by( Mandatory )
order by yes MergeTree The only required item in , Even better than primary key Also important , Because when the user does not set the primary key , A lot of processing will follow order by To process the fields
Primary key must be order by The prefix field of the field .
Hops ( second level ) Indexes
Hop index refers to the granularity of data fragments ( Specified during table creation index_granularity) Cut into small pieces , Put the above SQL granularity_value A number of small blocks are combined into a large block , Write index information to these blocks , This helps to use where Skip a lot of unnecessary data when filtering , Reduce SELECT Amount of data to be read .
grammar : INDEX index_name expr TYPE type(...) GRANULARITY granularity_value
Case study : INDEX a total_amount TYPE minmax GRANULARITY 5
- minmax
Stores the extreme value of the specified expression ( If the expression is tuple , Then store tuple The extreme value of each element in ), This information is used to skip data blocks , Similar to primary key .
Life cycle
MergeTree It provides the function of managing the life cycle of data tables or columns
The field involving judgment must be Date perhaps Datetime type , It is recommended to use the date field of the partition
Its attribute can be :
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER
- YEAR
The life cycle of the column
Adding the life cycle to the column will automatically clear the data
create table t_order_mt3(
id UInt32,
sku_id String,
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
insert into t_order_mt3 values
(106,'sku_001',1000.00,'2021-07-30 11:07:30'),
(107,'sku_002',2000.00,'2021-07-30 11:08:30'),
(110,'sku_003',600.00,'2021-07-30 11:08:40');

The life cycle of the table
The data will be in create_time after 10 Seconds lost
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;

ReplacingMergeTree
- The engine and MergeTree The difference is that it removes duplicates with the same sort key value .
- Data De duplication will only be performed during data consolidation . The merge will take place in the background at an uncertain time , It is suitable for removing duplicate data in the background to save space , But it doesn't guarantee that there won't be duplicate data .
- De duplication will only be performed within the partition , Cannot perform cross partition de duplication .
create table t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
insert into t_order_rmt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
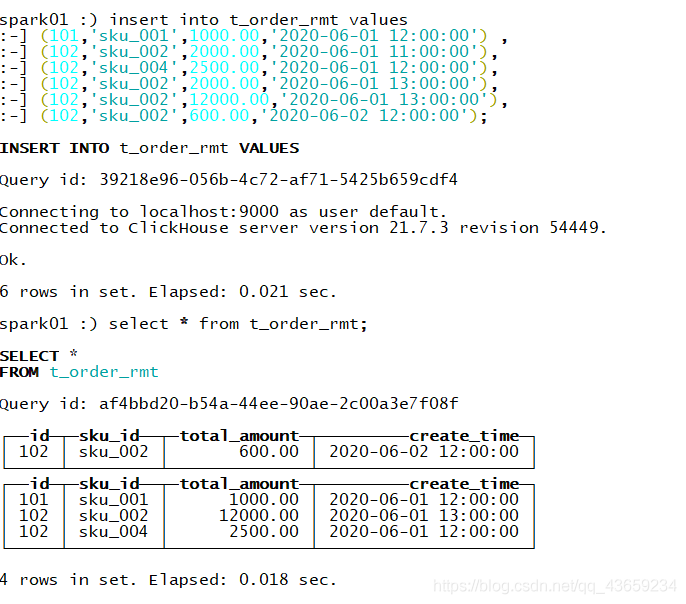
The saved data is the one with the largest version field value , If the version fields are the same, keep the last one in the insertion order .
SummingMergeTree
When merging SummingMergeTree Table data fragment ,ClickHouse All rows with the same primary key will be merged into one row , This row contains the summary values of columns with numeric data types in the merged rows .
- columns
A tuple containing the column names of the columns to be aggregated . Optional parameters .
The selected column must be of numeric type , And cannot be in the primary key .
create table t_order_smt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =SummingMergeTree(total_amount)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id );
insert into t_order_smt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');

Conclusion :
- No longer, the data in a partition will not be aggregated
- You can fill in more than one column, which must be numeric , If you don't fill in , Take all fields that are non dimension columns and numeric columns as summary data columns
- The other columns keep the first row in the insertion order
边栏推荐
- Simplefoc parameter adjustment 3-pid parameter setting strategy
- Background management system platform of new energy charging pile
- Qt/pyqt window type and window flag
- Flask reports an error runtimeerror: the session is unavailable because no secret key was set
- Dp4301-sub-1g highly integrated wireless transceiver chip
- DC motor speed regulation system based on 51 single chip microcomputer (use of L298)
- Week 1 task deep learning and pytorch Foundation
- Product promotion channels and strategies, cosmetics brand promotion methods and steps
- MySQL rownum implementation
- [robomaster] a board receives jy-me01 angle sensor data -- Modbus Protocol & CRC software verification
猜你喜欢

Simplefoc parameter adjustment 3-pid parameter setting strategy

sql判断语句的编写

centos7/8命令行安装Oracle11g

(Video + graphic) machine learning introduction series - Chapter 5 machine learning practice

Day4: the establishment of MySQL database and its simplicity and practicality

What is Amazon self support number and what should sellers do?

BiSeNet v2

New energy shared charging pile management and operation platform

Arduino uno error analysis avrdude: stk500_ recv(): programmer is not responding

Hal learning notes - Advanced timer of 7 timer
随机推荐
【Transformer】SegFormer:Simple and Efficient Design for Semantic Segmentation with Transformers
Solve the problem of MSVC2017 compiler with yellow exclamation mark in kits component of QT
Detailed steps of installing MySQL 5.7 for windows
Domestic application of ft232 replacing gp232rl usb-rs232 converter chip
The computer video pauses and resumes, and the sound suddenly becomes louder
Multifunctional signal generator based on AD9850
Hal learning notes - Advanced timer of 7 timer
Simplefoc+platformio stepping on the path of the pit
Hal library learning notes - 8 concept of serial communication
Temperature acquisition and control system based on WiFi
AES 双向加密解密工具
Solve the problem of MSVC2017 compiler with yellow exclamation mark in kits component of QT
pnpm install出现:ERR_PNPM_PEER_DEP_ISSUES Unmet peer dependencies
数仓分层设计及数据同步问题,,220728,,,,
Nrf52832-qfaa Bluetooth wireless chip
Day15: the file contains the vulnerability range manual (self use file include range)
Usage of torch.tensor.to
STM32 serial port garbled
简易计算器微信小程序项目源码
Day5: PHP simple syntax and usage