当前位置:网站首页>When to write disk IO after one byte of write file
When to write disk IO after one byte of write file
2020-11-08 16:12:00 【Zhang Yanfei Allen】
In the foreword 《read How much disk does a byte of file actually take place on IO?》 After you've written , I wanted to be lazy , Just read to let you know Linux IO Each module of the stack is OK . But many students said that they asked me to write another article about writing operation . Since many people have this need , I'll write it down .
Linux The kernel is really complicated , The number of lines of source code has been changed from 1.0 Tens of thousands of lines in the version , By now, it's a giant of thousands of lines . If you go straight in , It's easy to get lost in all kinds of dazzling calls , I can't drill out any more . I'd like to share with you a way I'm thinking about the kernel . Generally, I think about a problem that I really want to make clear . No matter how you jump around in the code , Always remember your problems , The irrelevant parts should be scattered as little as possible , Just figure out your problem .
Now what I want to understand is , In the most common way , Don't drive O_DIRECT、 Don't drive O_SYNC( There are many ways to write files , Yes sync Pattern 、direct Pattern 、mmap Memory mapping mode ),write How is it written .c The code example of is as follows :
#include <fcntl.h>
int main()
{
char c = 'a';
int out;
out = open("out.txt", O_WRONLY | O_CREAT | O_TRUNC);
write(out,&c,1);
...
}
Further refine my question , After we write a byte to the open question
- write How functions are executed in the kernel ?
- When can the data really be written to the disk ?
In the course of our discussion, it is inevitable to refer to the kernel code , The kernel version I'm using is 3.10.1. If necessary , You can download it here .https://mirrors.edge.kernel.org/pub/linux/kernel/v3.x/.
write Function implementation analysis
I spent a lot of time tracking write writes ext4 File system calls and returns , I sort out an interaction diagram . Of course, to highlight the point , I abandoned a lot of details , such as DIRECT IO、ext4 There's nothing in the log , Only a few calls that I think are critical are extracted .
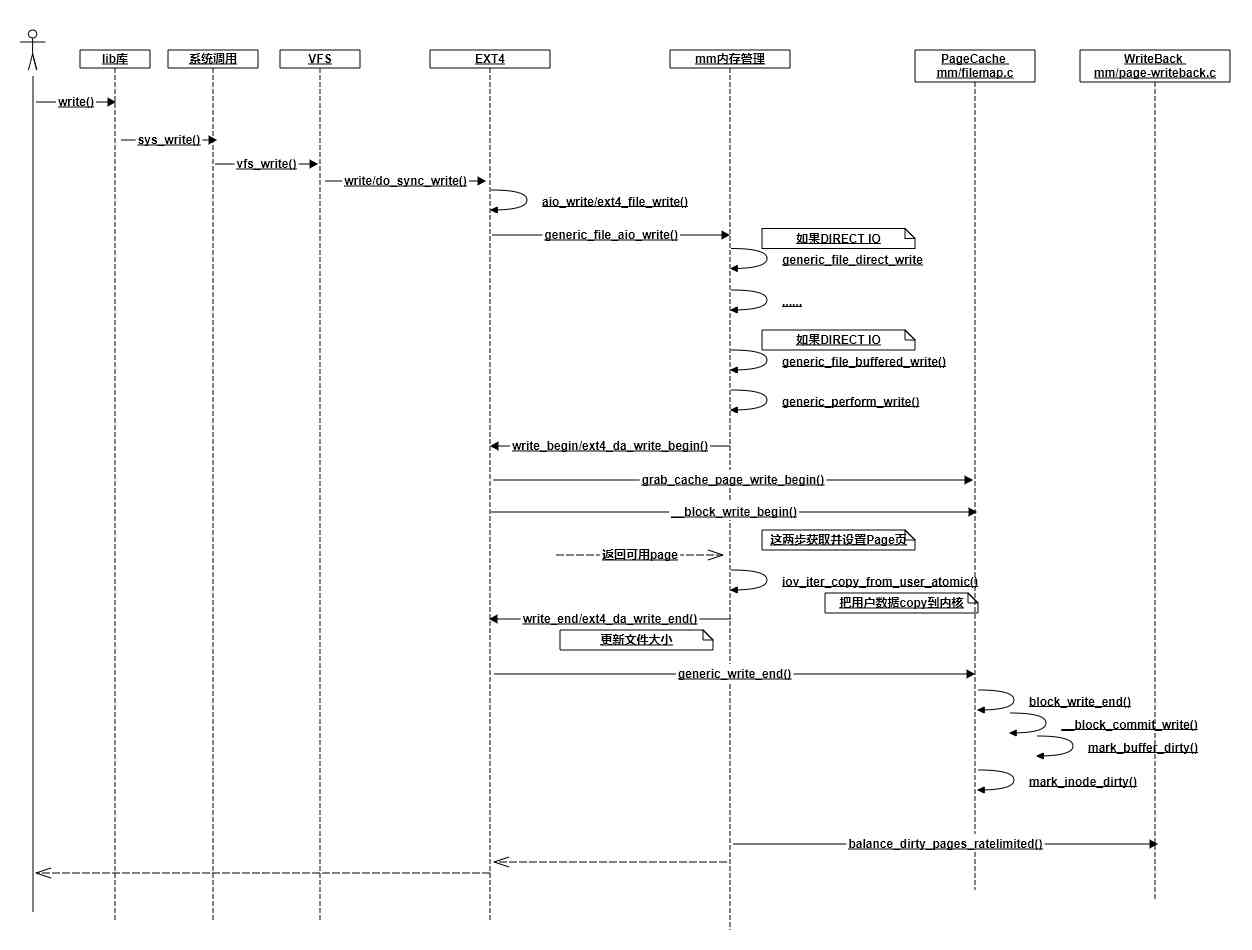
In the flow chart above , Where did all the writing end up ? At the back __block_commit_write in , It's just make dirty. Then most of the time your function call returns ( Later on balance_dirty_pages_ratelimited). The data is still in memory PageCache in , It's not really written to the hard disk .
Why do we have to do this , Don't write to the hard disk directly ? The reason is hard disk, especially mechanical hard disk , The performance is that it's too slow . A server level turntable , The worst-case random access average latency is at the millisecond level , The conversion IOPS Only 100 Not much 200. imagine , If every user in your back-end interface needs a random disk to access IO, No matter how good your server is , Per second 200 Of qps It's going to blow up your hard drive , Believe as a million / Ten million / More than 100 million users provide interface for you , This is something you can't stand .
Linux There are also side effects , If the next server power down , I lost everything in my memory . therefore Linux There's another one “ Patch ”- Delayed writing , Help us alleviate this problem . Pay attention to , I'm talking about relief , It's not completely solved .
Besides, under the balance_dirty_pages_ratelimited, Although most of the time , It's all written directly into Page Cache It's back in . But in one case , The user process must wait for the write to complete before it can return , That's right. balance_dirty_pages_ratelimited If your judgment goes beyond the limit . This function determines whether the current dirty page has exceeded the dirty page upper limit dirty_bytes、dirty_ratio, You have to wait if you exceed it . Only one of these two parameters will take effect , in addition 1 Yes 0. take dirty_ratio Come on , If the setting is 30, It means that if the proportion of dirty pages exceeds that of memory 30%, be write Function calls must wait for the write to complete before returning . It can be under your machine /proc/sys/vm/ Directory to view these two configurations .
# cat /proc/sys/vm/dirty_bytes
0
# cat /proc/sys/vm/dirty_ratio
30
Kernel delay write
When does the kernel actually write data to the hard disk ? In order to get a quick picture of the whole picture , The way I came up with was to use systemtap Tools , Find the kernel and write IO A key function in the process , And then you type the function call stack in it . After looking up the data for a long time , I decided to use it. do_writepages This function .
#!/usr/bin/stap
probe kernel.function("do_writepages")
{
printf("--------------------------------------------------------\n");
print_backtrace();
printf("--------------------------------------------------------\n");
}
systemtab After tracking , The printed information is as follows :
0xffffffff8118efe0 : do_writepages+0x0/0x40 [kernel]
0xffffffff8122d7d0 : __writeback_single_inode+0x40/0x220 [kernel]
0xffffffff8122e414 : writeback_sb_inodes+0x1c4/0x490 [kernel]
0xffffffff8122e77f : __writeback_inodes_wb+0x9f/0xd0 [kernel]
0xffffffff8122efb3 : wb_writeback+0x263/0x2f0 [kernel]
0xffffffff8122f35c : bdi_writeback_workfn+0x1cc/0x460 [kernel]
0xffffffff810a881a : process_one_work+0x17a/0x440 [kernel]
0xffffffff810a94e6 : worker_thread+0x126/0x3c0 [kernel]
0xffffffff810b098f : kthread+0xcf/0xe0 [kernel]
0xffffffff816b4f18 : ret_from_fork+0x58/0x90 [kernel]
From the output above, we can see that , The real file writing process is performed by worker From the kernel thread ( It has nothing to do with our own app process , At this point, our application's write The function call returned long ago ). This worker Thread writebacks are executed periodically , Its cycle depends on the kernel parameters dirty_writeback_centisecs Set up , According to the parameter name, you can probably see that , Its unit is one hundredth of a second .
# cat /proc/sys/vm/dirty_writeback_centisecs
500
I see that my configuration is 500, That is, every 5 The second will do it periodically . Looking back on our questions , When was our most concerned question written in , It's just a lot of divergence around this idea . So we keep tracking along the call stack , Jump , Finally found the following code . In the following code we see , If it is for_background Pattern , And over_bground_thresh Judge success , It will start to write back .
static long wb_writeback(struct bdi_writeback *wb,
struct wb_writeback_work *work)
{
work->older_than_this = &oldest_jif;
...
if (work->for_background && !over_bground_thresh(wb->bdi))
break;
...
if (work->for_kupdate) {
oldest_jif = jiffies -
msecs_to_jiffies(dirty_expire_interval * 10);
} else ...
}
static long wb_check_background_flush(struct bdi_writeback *wb)
{
if (over_bground_thresh(wb->bdi)) {
...
return wb_writeback(wb, &work);
}
}
that over_bground_thresh What does the function judge ? In fact, it is to judge whether the current dirty page exceeds the kernel parameters dirty_background_ratio or dirty_background_bytes Configuration of , If you don't exceed it, you won't write it ( Code is located fs/fs-writeback.c:1440, Limited to space, I will not post ). Only one of these two parameters will actually work , among dirty_background_ratio The configuration is proportional 、dirty_background_bytes The configuration is bytes .
The two parameters on my machine are configured as follows , Indicates that the proportion of dirty pages exceeds 10% I started writing back .
# cat /proc/sys/vm/dirty_background_bytes
0
# cat /proc/sys/vm/dirty_background_ratio
10
So what if the dirty pages don't exceed this percentage all the time , Don't write it ? No, it isn't . Above wb_writeback Function, we see , If it is for_kupdate Pattern , An expiration mark will be recorded to work->older_than_this, In the following code, the page that meets this condition is also written back .dirty_expire_interval Where does this variable come from ? stay kernel/sysctl.c in , We found clues . Oh , It turns out that it came from /proc/sys/vm/dirty_expire_centisecs This configuration .
1158 {
1159 .procname = "dirty_expire_centisecs",
1160 .data = &dirty_expire_interval,
1161 .maxlen = sizeof(dirty_expire_interval),
1162 .mode = 0644,
1163 .proc_handler = proc_dointvec_minmax,
1164 .extra1 = &zero,
1165 },
It's on my machine , Its value is 3000. The unit is one hundredth of a second , So the dirty pages are over 30 Seconds will be thought by the kernel thread to write back to disk .
# cat /proc/sys/vm/dirty_expire_centisecs
3000
Conclusion
We demo Writing in code , In fact, most cases are written to PageCache It's back to , It's not really written to the disk . Our data will be actually initiated to write to disk at the following three times IO request :
- Case one , If write When the system is called , If you find that PageCache There are too many dirty pages , More than the dirty_ratio or dirty_bytes,write You have to wait .
- The second case ,write writes PageCache It's back .worker When kernel threads run asynchronously , Judge the proportion of dirty pages again , If you exceed dirty_background_ratio or dirty_background_bytes, Also initiate a write back request .
- The third case , It's the same time write The call has returned .worker When kernel threads run asynchronously , Although the system visceral page has not exceeded dirty_background_ratio or dirty_background_bytes, But dirty pages stay in memory longer than dirty_expire_centisecs 了 , I can also initiate and write .
If you are not satisfied with the above configuration , You can modify it yourself /etc/sysctl.conf To adjust , Don't forget to carry out the modification sysctl -p.
Finally, we should realize that , This set of write pagecache+ The first goal of the write back mechanism is performance , It's not a guarantee that we won't lose the data we've written . If the power goes off at this time , Dirty pages have not been dirty for more than dirty_expire_centisecs I really lost it . If you're doing a very important business with money , You have to make sure that the drop is complete before you can return , Then you may need to consider using fsync.

Development of hard disk album of internal training :
- 1. Disk opening : Take off the hard coat of the mechanical hard disk !
- 2. Disk partitioning also implies technical skills
- 3. How can we solve the problem that mechanical hard disks are slow and easy to break down ?
- 4. Disassemble the SSD structure
- 5. How much disk space does a new empty file take ?
- 6. Only 1 How much disk space does a byte file actually take up
- 7. When there are too many documents ls Why is the command stuck ?
- 8. Understand the principle of formatting
- 9.read How much disk does a byte of file actually take place on IO?
- 10.write When to write to disk after one byte of file IO?
- 11. Mechanical hard disk random IO Slower than you think
- 12. How much faster is a server equipped with a SSD than a mechanical hard disk ?
My official account is 「 Develop internal skill and practice 」, I'm not just talking about technical theory here , It's not just about practical experience . It's about combining theory with practice , Deepen the understanding of theory with practice 、 Use theory to improve your technical practice ability . Welcome to my official account , Please also share with your friends ~~~
版权声明
本文为[Zhang Yanfei Allen]所创,转载请带上原文链接,感谢
边栏推荐
- 小青台正式踏上不归路的第3天
- RestfulApi 学习笔记——父子资源(四)
- We made a medical version of the MNIST dataset, and found that the common automl algorithm is not so easy to use
- 函数分类大pk!sigmoid和softmax,到底分别怎么用?
- Hello world of rabbitmq
- Don't release resources in finally, unlock a new pose!
- Golang ICMP协议探测存活主机
- Improvement of maintenance mode of laravel8 update
- 使用K3S创建本地开发集群
- Summary of template engine
猜你喜欢
Apache Kylin远程代码执行漏洞复现(CVE-2020-1956)

. net large data concurrency solution
Recurrence of Apache kylin Remote Code Execution Vulnerability (cve-2020-1956)
Millet and oppo continue to soar in the European market, and Xiaomi is even closer to apple
Tips and skills of CSP examination
PHP生成唯一字符串
搭载固态硬盘的服务器究竟比机械硬盘快多少
2020-11-05
Drink soda, a bottle of soda water 1 yuan, two empty bottles can change a bottle of soda, give 20 yuan, how much soda can you
“他,程序猿,35岁,被劝退”:不要只懂代码,会说话,胜过10倍默默努力
随机推荐
漫画:寻找股票买入卖出的最佳时机(整合版)
LiteOS-消息队列
[Python 1-6] Python tutorial 1 -- number
TypeScript(1-2-2)
Tencent: Although Ali's Taichung is good, it is not omnipotent!
数据库连接报错之IO异常(The Network Adapter could not establish the connection)
Arduino IDE搭建ESP8266开发环境,文件下载过慢解决方法 | ESP-01制作WiFi开关教程,改造宿舍灯
Builder pattern
喜获蚂蚁offer,定级p7,面经分享,万字长文带你走完面试全过程
小米、OPPO在欧洲市场继续飙涨,小米更是直逼苹果
前后端分离跨域问题解决方案
write文件一个字节后何时发起写磁盘IO
模板引擎的整理归纳
Google's AI model, which can translate 101 languages, is only one more than Facebook
Blockchain weekly: the development of digital currency is written into the 14th five year plan; Biden invited senior adviser of MIT digital currency program to join the presidential transition team; V
Learn to record and analyze
I used Python to find out all the people who deleted my wechat and deleted them automatically
VIM configuration tutorial + source code
Design by contract (DBC) and its application in C language
Chapter 5 programming